一种基于面部纹理特征融合的人脸表情识别方法
2021-05-23高婷婷李航殷守林
高婷婷 李航 殷守林


摘 要:针对人脸表情识别领域受噪声和遮挡等因素影响识别率不高的问题,结合局部和全局特征,提出一种基于面部表情的情感分析混合方法。首先,通过将梯度直方图(HOG)与复合局部三元模式(C-LTP)融合来进行特征提取;其次,将HOG和C-LTP提取的特征融合到单个特征向量中;最后,采用多类支持向量机分类器把特征向量进行情感分类;最后,将提出的方法在3个公共表情图像数据库中与现有的表情识别方法进行对比实验。结果表明,提出的方法在MMI,JAFFE,CK+数据库上的正确识别率分别为98.28%,95.75%,99.64%,平均识别率比其他方法高出10%,优于其他现有的方法。提出的表情识别方法,可有效促进人机交互系统的发展和计算机图像理解的研究,对实现人体语言与自然语言的融合,以及语言与表情连接模型的建立与实现具有重要意义。
关键词:模式识别;人脸表情识别;特征融合;HOG;C-LTP;支持向量机
中图分类号:TP957.52 文献标识码:A
doi:10.7535/hbkd.2021yx02004
A facial expression recognition method based on face texture feature fusion
GAO Tingting,LI Hang,YIN Shoulin
(Software College,Shenyang Normal University,Shenyang,Liaoning 110034,China)
Abstract:Aiming at facial expression recognition, the recognition rate is not high due to noise and occlusion. A hybrid approach of facial expression has been presented by combining local and global features. First, feature extraction is performed to fuse the histogram of oriented gradients (HOG) descriptor with the compounded local ternary pattern (C-LTP) descriptor. Second, features extracted by HOG and C-LTP are fused into a single feature vector. Third, the feature vector is sent to a multi-class support vector machine classifier for facial classification. Finally, the proposed method is compared with the existing facial expression recognition methods in three public facial expression image databases, and the results show that the recognition rates of the proposed method in MMI, JAFFE and CK+ databases are 98.28%, 95.75% and 99.64%, respectively. The average recognition rate is 10% higher than other methods, which is better than other existing methods. The results of this study provide a reference for the research of facial expression recognition in many situations. The method of facial expression recognition proposed can effectively promote the development of human-computer interaction system and the study of computer image understanding. It is of great significance to realize the fusion of human language and natural language, as well as the establishment and implementation of the connection model between language and expression.
Keywords:
pattern recognition; facial expression recognition; feature fusion; HOG; C-LTP; support vector machine
面部表情[1]是人際关系中非常重要的交流方式。人脸表情识别在测谎、行为分析、监视系统、运输和机器人技术等多个研究和开发领域中具有多种应用[2-3]。随着机器人的发展,表情识别将有助于在人与机器之间创建智能的视觉界面,从而促进人机交互(HCI)[4]。
此外,在许多现实工作中,例如,驾驶员疲劳检测、教师情绪检测等,都需要高效的人脸表情识别。目前,基于深度学习方法已被用于识别面部表情。李军等[5]提出了一种融合多尺度卷积神经网络和双向长短期记忆的模型,不仅能够增强特征信息间的联系,还可通过不同尺度的卷积核提取到更加丰富的特征信息。张雯婧等[6]针对实际场景中人脸表情识别训练和测试数据因来自不同场景从而导致识别性能显著下降的问题,提出了一种基于稀疏子空间迁移学习的跨域人脸表情识别方法。苏志明等[7]提出了一个基于多尺度双线性池化神经网络的模型,解决了由于人脸表情细微的类间差异和显著的类内变化使得人脸表情识别困难,从而导致识别率低的问题。尹鹏博等[8]为了解决深度学习模型在人脸表情识别研究中存在数据集需求量大、硬件配置要求高等问题,提出了基于卷积注意力的轻量级人脸表情识别方法。但以上方法在特定表情识别情况下,存在识别效率较低的问题。
面部表情识别(FER)[9-10]在预处理步骤中,通过图像增强技术消除噪声,采用各种模糊效果和细节差分来提高输入图像的质量[11],然后在输入图像中检测到脸部及其组成部分(眼睛、眉毛、脸颊、鼻子和嘴巴)。如Viola-Jones人脸检测算法[12-13]。相对于其他最新技术,该算法在实时检测面部及其组件方面提供了更高的准确性。考虑到各种资源(例如计算、存储和传输资源)的可用性,将感兴趣区域(ROI)裁剪并调整为指定的尺寸。
1 改进的表情识别方法
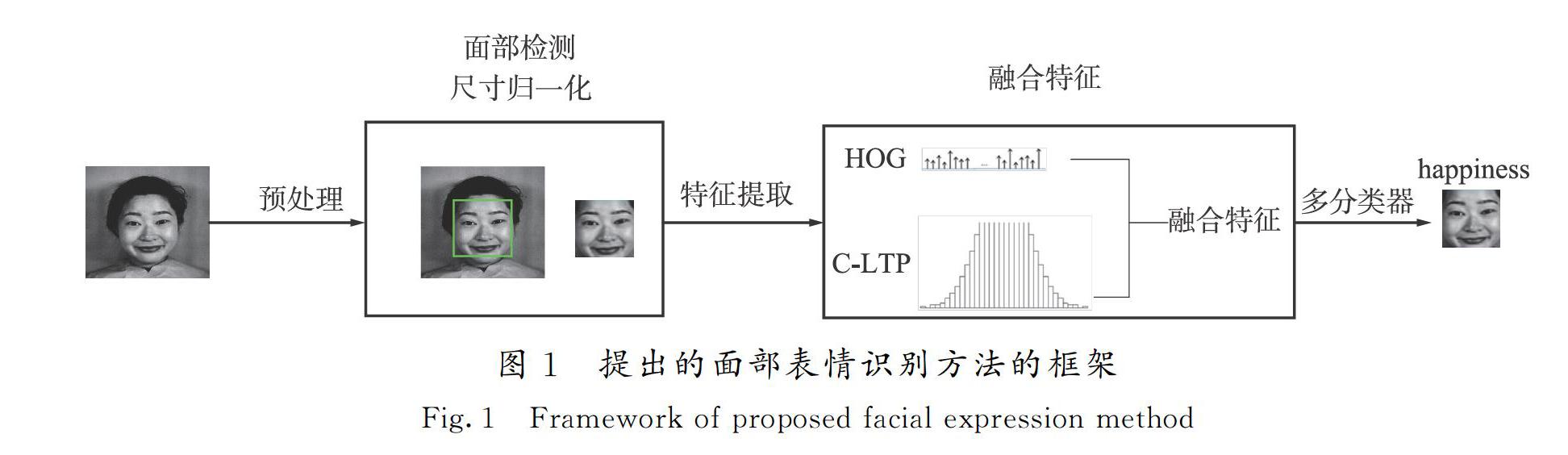
本文提出的改进方法具体是:选择一个数据库,然后将其划分为训练集和测试集。在训练阶段,经过人脸检测后,脸部区域被裁剪成一个图像,并通过采用图像增强技术增强图像的质量,如将SRCNN图像重建来获取高分辨率图像。在特征提取的第一步,使用梯度直方图(HOG)和混合局部三元模式(C-LTP)描述符从裁剪的图像中提取特征到特征向量中,然后将提取的特征融合到单个特征向量中。对提取的特征向量根据其对应的表达式标签进行标记,表示7个标准面部表情。标记的特征向量被反馈送到多分类器中,以有效地训练基础机器。总体框架如图1所示。
1.1 图像预处理
在预处理步骤中,对输入图像进一步处理以提高其质量。最初图像包含噪声或其他类型的模糊元素,可能会降低识别的精度。因此,为了消除噪声数据并保留重要信息,将大小为3×3的中值滤波器应用于输入图像。用中值替换附近的每个像素,有助于消除椒盐噪声,但不会降低输出图像的清晰度。同样,当使用低分辨率或低对比度图像时,识别率也会降低。为此,采用直方图均衡技术增强图像对比度,并对光照效果进行归一化处理。经滤波和直方图均衡后,在图像中检测到人脸。人脸检测后,将图像裁剪并调整为128×128。基于多核图像超分辨率方案人脸检测、ROI的提取和调整,如图2所示。
1.2 特征提取
提出的方法基于外观和形状信息2种类型的特征描述符,被用于从面部图像中提取的主要特征,这些特征融合形成一维特征向量。
1.2.1 梯度直方图(HOG)
HOG用来计算边缘的方向和像素的可见性,即图像的局部切片中有多少像素的边缘沿特定方向通过。HOG是一种强大的特征提取技术,可提取描述基础图像ROI中每个像素的特征。
在梯度计算中,计算每个像素的居中水平和垂直梯度。在水平和垂直方向上应用一维中心离散导数掩膜最方便和有效的方法是
Dx=[-1 0 1],Dy=[-1 0 1]-1 。(1)
每个方向的卷积运算为
IFx=IFDx,IFy=IFDy。(2)
其中:式(1)显示了用于计算x和y导数的掩码;x和y导数通过等式中的卷积掩膜计算得出式(2);代表乘积;IF为包含ROI的预处理图像;IFx和IFy是一个图像的x和y的导数。HOG特征描述符由梯度幅值|M|和边缘方向θ组成,大小和方向梯度分量计算为
M=IFx2+IFy2,(3)
θ=arctanIFyIFx。(4)
使用方向梯度的矩形直方图(R-HOG)[14]提取人脸特征,R-HOG块由正方形网格组成,由3个参数表示:每块的单元数、单元的大小以及该块中每个单元的直方图中的单元数。
在实验评估中不同大小的单元格(例如8×8,12×12和16×16),评估不同大小的块(例如2×2)和具有不同单元的重叠块的大小,如图3所示。以单元大小16×16、块大小2×2为例,通过实验证明了具有50%重叠块的准确性和有效性。
1.2.2 复合的本地三元模式
本地三进制模式(LTP)是本地二进制模式(LBP)的概括[15]。LTP功能比LBP更有效,因为LTP功能对噪声鲁棒性更出色。LTP直方图的维数大,导致直方图具有较大的尺寸。因此,为减少特征尺寸,将LTP代码分为2个LBP:上(正)LBP和下(负)LBP,如图4所示。
由于LTP将小的像素差异编码为一个单独的状态更具弹性,因此,为解决噪声问题,将LTP嵌入HOG以帮助提出的方法在更大程度上对噪声具有鲁棒性。最后,将提取的HOG和C-LTP特征向量融合到单个特征向量中,并为FER系统中的面部表情识别进行标记。
1.3 基于多分类器的表情分类
采用支持向量机作为面部表情分类和识别的分类器,首先将2个类别的训练数据映射到一个较高维的空间,然后构造2类数据之间具有细边界的最优分离超平面。在提出的方法中,采用one versus rest[16]策略。由于具有大量的训练特征,因此在提出的方法中采用了具有线性核的支持向量机。SVM分类器的线性内核ψ可以描述为
ψF⌒HOG+C-LTPi,φi=1/1+eF⌒iHOG+C-LTPTLJ。(5)
给定标记的训练样本F⌒HOG+C-LTPi,Li,其中i = 1,2,3,...m;F⌒(HOG+C-LTP)i∈Rn+1 ;LJ∈。分類可以描述如下:
CF⌒(HOG+C-LTP)i=sign∑ni=1αiLJψF⌒(HOG+C-LTP)i,φi+b,(6)
其中:αi是对偶优化问题的Lagrange乘数;ψ是一个核函数;b是超平面的偏差。
2 实验与结果
本次实验使用了3个数据库,每个数据库都随机分为训练集和测试集。通过改变训练数量进行实验并测试图像。所提方法中用于所有仿真的平台是在具有2.70 GHz CPU速度、4.00 GB RAM和Windows 10 64位版本操作系统的PC。
2.1 JAFFE表情数据库
该数据库[17]由10位日本女性的213张图像组成,所有213张图像均已用于实验中。JAFFE数据库的一些样本图像如图5 a)所示。
2.2 CK+數据库
CK数据库[18]包含来自123个对象的姿势和非姿势表情。图5 b)说明了来自CK+数据库的一些样本图像。实验使用了不同数量的图像。这项研究总共使用了CK+数据库中的630张图像(7个表达式中的每个包含90张图像)。
2.3 MMI数据库
MMI[19]数据库包含20多名男女受试者(44%为女性)。他们的年龄从19岁到62岁不等,来自不同的国家(欧洲、亚洲、南美洲等)。从不同的视频中总共提取273帧图像。图5 c)显示了来自MMI数据库的一些示例图像。
2.4 实验验证
如表1所示,在第1阶段,使用了3个数据库中的少部分图像作为训练集,并使用其余图像进行测试。
在第2阶段,使用了大部分的图像用于培训,其余图像用于测试。在第3阶段,采用10倍交叉验证,根据变化的表达式将数据库随机分为10个相等的段。每次训练10个细分中的9个,剩下10%的图像用于测试。结果显示,提出的方法以高识别率成功地识别出面部表情。
2.5 噪声鲁棒性
在实际环境中,噪声是降低图像质量的主要因素,导致各种计算机视觉和模式识别的性能不佳。为此将不同级别的椒盐噪声随机添加到大小为128×128的测试图像中。图6显示了在不同噪声水平下的示例图像。在3个数据库中评估了提出的方法的鲁棒性,提出的方法对椒盐噪声具有较强的鲁棒性,如表2所示。在改变噪声密度的同时,识别率会发生不同的变化。随着噪声密度的增加,识别率降低,可以看出,噪声密度(P)为0.01时,与CK+相比噪声削弱了JAFFE和MMI数据库的识别率。随着噪声密度增加到0.02,所有数据库的识别率逐渐降低,但与MMI和CK+相比,JAFFE数据库的识别率在某种程度上更好。当噪声密度增加时,与JAFFE和MMI相比,CK+的下降速度更为严重。
2.6 遮挡鲁棒性
遮挡的存在也会影响图像质量并降低面部表情识别系统的性能。将随机大小的块添加到测试图像中以检查遮挡的鲁棒性。块大小从15×15到55×55。这些块随机添加到面部图像上,如图7所示。最终的平均识别率如表3所示。与JAFFE相比,CK+和MMI数据库的识别精度都非常出色。当添加15×15和25×25的块大小时,CK+和MMI的识别率几乎相同,分别为99.2%和96.1%以及99.1%和95.9%;对于15×15和25×25的块大小,JAFFE的识别率几乎相等。与JAFFE和MMI相比,对于上述块大小,提出的CK+数据库系统的整体准确性非常合理,再次显示了提出的方法具有较好的识别准确性。
2.7 与其他方法的比较
将提出的方法与现有的面部表情识别算法的结果准确性进行比较。选择这些方法是因为在相同的数据库上使用类似的测试策略产生了最优的性能。可以看出,所提出的方法优于使用表1中所示的相同数据库的其他现有方法。所提出方法的正确识别率在MMI数据库上为98.28%,在JAFFE上为95.75%,在CK+数据库上为99.64%。表4显示了使用相同的JAFFE,MMI和CK+数据库的提出方法与现有方法之间的性能比较,提出方法在3个数据库都具有较高的识别效果。
提出的方法得到了较为理想的表情识别结果,因为提出的方法同时考虑了局部和全局描述符,以及从包含人脸的图像中提取特征。为此将方向梯度直方图(HOG)描述符与复合局部三元模式(C-LTP)结合使用,以将特征提取到单个特征向量中。使用HOG和C-LTP从整个裁剪的面孔中提取特征,描述了基础面孔的外观、形状和纹理变化,是因为在面部表情分析中,即使脸部的一小部分也可以在表情识别中发挥重要作用。因此,仅从面部单个组成部分提取特征会导致面部表情所涉及的大量信息的丢失。提出的方法的主要贡献是形状、外观分别通过HOG和C-LTP提取其纹理变化,再对其进行特征集成。还可以将局部和全局特征感知为单个实体,从而弥补了局部和全局特征的弱点,同时改善了特征向量的生成。最后将提取的特征向量反馈送到SVM进行分类。考虑到人脸的异质性和表情的多样性,采用了多类支持向量机以生成更准确的FER算法。
本文提出的FER方法的主要优势如下:
1)提出了一种全自动面部表情识别方法,该方法对各种实际环境元素(例如噪声、光照变化以及部分重叠或遮挡)均具有鲁棒性。
2)提出采用HOG与C-LTP结合方式提取更鲁棒的特征,可以从人脸中提取出重要特征,从而提高人脸表情识别的准确性。
3)HOG和C-LTP的组合可将局部和全局特征感知为单个实体,从而弥补了局部和全局特征的弱点,同时改善了更具鲁棒性的特征向量的生成。
3 结 语
本文提出了一种基于面部情感识别的情感知识方法,提取具有C-LTP的定向梯度直方图描述符,以对人脸情绪进行稳定分类。实验结果表明:与其他方法相比,所提出的方法具有最高的识别精度;还证实了所提出的FER方法能够在各种挑战下识别面部表情,例如遮挡物或噪音的存在。尽管噪声会严重影响识别精度,但该方法仍具有较好的性能。
本文所提方法仅针对静态图像的识别精度有所提高,如果存在具有复杂背景及干扰物与目标极为相似的图像,识别效果不太理想,今后将研究更为先进的基于深度学习的方法以及从视频中的静态图像扩展到动态识别中识别面部表情,从而为与面部情感分析有关的各种以视频为中心的问题的解决提供参考。
参考文献/References:
CORNEANU C A,MARC O S,COHN J F,et al.Survey on RGB,3D,thermal,and multimodal approaches for facial expression recognition:history,trends,and affect-related applications[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2016,38(8):1548-1568.
楊晓龙,闫河,张杨.人脸表情识别综述[J].数字技术与应用,2018,36(2):223-224.
YANG Xiaolong,YAN He,ZHANG Yang.Overview of facial expression recognition[J].Digital Technology and application,2018,36(2):223-224.
付喜梅,庄思发.人脸表情识别的概述[J].电脑知识与技术,2018,14(23):211-214.
FU Ximei,ZHUANG Sifa.Overview of facial expression recognition[J].Computer Knowledge and Technology,2018,14(23):211-214.
朱亚忱.基于特权信息的情感识别[D].合肥:中国科学技术大学,2015.
ZHU Yacheng.Emotion Recognition Based on Privileged Information[D].Hefei:University of Science and Technology of China,2015.
李军,李明.融合Multi-scale CNN和Bi-LSTM的人脸表情识别研究[J].北京联合大学学报,2021,35(1):35-39.
LI Jun,LI Ming.Research on facial expression recognition based on the combination of multi-scale CNN and Bi-LSTM[J].Journal of Beijing Union University,2021,35(1):35-39.
张雯婧,宋鹏,陈栋梁等.基于稀疏子空间迁移学习的跨域人脸表情识别[J].数据采集与处理,2021,36(1):113-121.
ZHANG Wenjing,SONG Peng,CHEN Dongliang,et al.Cross-domain facial expression recognition based on sparse subspace transfer learning[J].Journal of Data Acquisition and Processing,2021,36(1):113-121.
苏志明,王烈,蓝峥杰.基于多尺度分层双线性池化网络的细粒度表情识别[J/OL].计算机工程.[2021-02-22].doi:10.19678/j.issn.1000-3428.0060133.
SU Zhiming,WANG Lie,LAN Zhengjie.Fine-grained expression recognition based on multi-scale hierarchical bilinear pooling network[J/OL].Computer Engineering..doi:10.19678/j.issn.1000-3428.0060133.
尹鹏博,潘伟民,张海军.基于卷积注意力的轻量级人脸表情识别方法[J/OL].激光与光电子学进展.[2021-01-09].http://kns.cnki.net/kcms/detail/31.1690.TN.20210107.1716.008.html.
YIN Pengbo,PAN Weimin,ZHANG Haijun.Lightweight facial expression recognition method based on convolutional attention[J/OL].Laser & Optoelectronics Progress.[ 2021-01-09].http://kns.cnki.net/kcms/detail/31.1690.TN.20210107.1716.008.html.
党宏社,王淼,张选德.基于深度学习的面部表情识别方法综述[J].科学技术与工程,2020,20(24):9724-9732.
DANG Hongshe,WANG Miao,ZHANG Xuande.A review of facial expression recognition methods based on deep learning[J].Science,Technology and Engineering,2020,20(24):9724-9732.
KUMAR P,HAPPY S L,ROUTRAY A.A real-time robust facial expression recognition system using HOG features[C]//International Conference on Computing.[S.l.]:IEEE,2017.doi:10.1109/CAST.2016.7914982.
谭小慧,李昭伟,樊亚春.基于多尺度细节增强的面部表情识别方法[J].电子与信息学报2019,41(11):2752-2759.
TAN Xiaohui,LI Zhaowei,FAN Yachun.Facial expression recognition method based on multi-scale detail Enhancement[J].Journal of Electronics and Information,2019,41(11):2752-2759.
戴鑫.移动平台上的实时人脸特征点定位算法研究 [J].信息记录材料,2019,20(12):164-165.
DAI Xin.Research on real-time facial feature point location algorithm on mobile platform[J].Information Recording Materials,2019,20(12):164-165.
ZHANG Y,JI Q.Active and dynamic information fusion for facial expression understanding from image sequences[J].IEEE Trans Pattern Anal Mach Intell,2005,27(5):699-714.
RASHA O M,MAZEN M S,OMAR A M.Fusion time reduction of a feature level based multimodal biometric authentication system[J].International Journal of Sociotechnology and Knowledge Development,2020,12(1):67-83.
WIESLAW C,KATARZYNA S.Using the one-versus-rest strategy with samples balancing to improve pairwise coupling classification[J].International Journal of Applied Mathematics and Computer Science,2016,26(1):191-201.
李艳秋,颜普,高翠云,等.基于表情特征描述与稀疏加权决策的情感识别[J].安徽建筑大学学报,2019,27(4):78-82.
LI Yanqiu,YAN Pu,GAO Cuiyun,et al.Emotion recognition based on expression feature description and sparse weighted decision[J].Journal of Anhui Jianzhu University,2019,27(4):78-82.
付俊妮.基于局部先验约束的极低分辨率面部表情识别[J].电子设计工程,2019,27(9):123-126.
FU Junni.Very low resolution facial expression recognition based on local prior constraints[J].Electronic Design Engineering,2019,27(9):123-126.
夏添.基于深度学习的表情识别算法研究[D].南京:东南大学,2019.
XIA Tian.Study on Facial Expression Recognition Algorithm Based on Deep Learning[D].Nanjing:Southeast University,2019.
钟伟,黄元亮.基于特征融合与决策树技术的表情识别方法[J].计算机工程与科学,2017,39(2):393-398.
ZHONG Wei,HUANG Yuanliang.Facial expression recognition method based on feature fusion and decision tree technology[J].Computer Engineering and Science,2017,39(2):393-398.
鐘志鹏,张立保.基于多核学习特征融合的人脸表情识别[J].计算机应用,2015,35(sup2):245-249.
ZHONG Zhipeng,ZHANG Libao.Facial expression recognition based on multi-core learning feature fusion[J].Computer Application,2015,35(sup2):245-249.
邹元彬,乐思琦,廖清霖等.基于LBP和LPQ的面部表情识别[J].信息技术与信息化,2020(9):199-205.
ZOU Yuanbin,LE Siqi,LIAO Qinglin,et al.Facial expression recognition based on LBP and LPQ[J].Information Technology and Informatization,2020(9):199-205.
SHAN C,GONG S,MCOWAN P W.Facial expression recognition based on local binary patterns:A comprehensive study[J].Image & Vision Computing,2009,27(6):803-816.
文元美,欧阳文,凌永权.一种面向表情识别的ROI区域二级投票机制[J].计算机应用研究,2019,36(9):2861-2865.
WEN Yuanmei,OUYANG Wen,LING Yongquan.A second-level voting mechanism in ROI region for facial expression recognition[J].Computer Application Research,2019,36(9):2861-2865.
