基于双向特征金字塔和深度学习的图像识别方法
2021-05-21赵升,赵黎
赵 升,赵 黎
(1.昆明医科大学第三附属医院 PET/CT中心,昆明 650118;2.昆明医科大学 基础医学院,昆明 650500)
0 引 言
计算机视觉是一个多学科交叉的领域, 主要研究从静态图像或者视频流中自动提取、分析和理解有价值信息的理论和方法[1]。图像物体识别与检测(图像识别)是指从静态图像或视频流中识别及定位出其中感兴趣的物体,是计算机视觉领域的一个基础性任务。近年来,得益于深度学习理论和方法的长足发展,图像识别也取得了许多新的突破[2-4]。然而,多尺度图像识别依然是一项极具挑战性的任务。一幅图像所包含的物体有大有小,多尺度图像识别旨在可以识别出图像中不同大小的物体。现有的图像识别方法通常对大小适中的物体识别精度较好,对过大或者过小的物体识别精度都较差。多尺度图像识别依然是当前的难点和前沿问题。
当前,基于深度神经网络的物体识别方法可以分为两类:单步骤图像识别方法和双步骤图像识别方法。顾名思义,单步骤图像识别方法只有一个步骤,即通过对位置、比例和纵横比进行常规或密集采样实现物体识别。双步骤图像识别方法分为两个步骤:第一步骤为稀疏物体识别方案集生成模型,第二步骤为方案集中物体识别方法的分类与回归。区别于单步骤图像识别方法,双步骤图像识别方法可输出每个步骤的中间结果以更好地诊断图像识别性能。相较于双步骤图像识别方法,单步骤图像识别方法通常具有较高的计算效率和相对较低的识别精度。在单步骤图像识别方法中,保持图像采集边框尺度和物体大小的一致是提高图像识别精度的关键。因此,高层次的语义特征和密集的尺度覆盖是提高单步骤图像识别方法精度的有效途径。然而,当前大多数深度神经网络对图像边框的大小都是固定不变的,其使得现有大多数基于深度神经网络的方法都无法彻底解决多尺度图像识别。
特征金字塔是解决不同尺度图像语义特征提取的有效途径。近年来,特征金字塔已被应用于现有基于深度神经网络的图像识别方法,以解决多尺度图像识别问题。基于特征金字塔的图像识别方法利用不同尺度特征映射来识别不同尺度的物体。2016年,Liu等[5]提出了基于特征金字塔的多尺度图像识别方法——Single Shot Detector(SSD)。SSD首先根据原始图像生成多个不同尺度的特征图像,而后从多个不同尺度的特征图识别不同尺度的物体。然而,浅层特征映射中的小尺度语义信息限制了SSD的分类和回归能力。为解决该问题,Zhou等[6]提出了Scale-Transferrable Detection Network(STDN)算法。STDN算法在DenseNet的最后环节嵌入尺度转移模块来生成具有大尺度语义信息的高分辨率特征映射。此外,许多研究[7-9]还探索了自上而下的特征金字塔特征融合方法以提升图像识别的精确度。自上而下的特征金字塔融合方式将大尺度特征的语义信息融入小尺度特征,有助于小尺度物体识别。然而,大尺度物体识别依然是一个未解决的问题。因此,如何使用小尺度特征的语义信息丰富大尺度特征,提升大尺度物体识别精确度,是实现多尺度图像识别的关键。
当前,大多数最先进的单阶段图像识别方法大都采用枚举图像锚框(anchor box)的方法;然而,锚框往往需要特别设计。Faster r-cnn[2]采用人工选择锚框,Yolo9000[10]采用统计学方法(如聚类)设定锚框;然而,人工或统计学方法所选择的锚框往往无法适应多尺度图像识别。为解决该问题,Yang等人[11]提出了MetaAnchor方法。MetaAnchor利用权重预测获得动态锚框函数,从而一定程度上解决了图像物体的多尺度问题。为了覆盖图像中不同形状的物体,预定义的锚框往往需要设定多个不同的纵横比。YOLO v3[4]利用每个金字塔特征图上不同长宽比的3个锚盒进行图像识别;RetinaNet[12]则采用9个不同的锚框以实现图像不同尺度和形状物体的密集覆盖。然而,锚框数量越多,锚函数中的参数会急剧增多,特别是物体类别数量大的情况下。RefineDet[14]通过过滤负面锚框,在保证图像识别效率的同时,取得了最新最好的准确率。然而,RefineDet[14]本质上还是基于自上而下的特征金字塔特征融合方法。
在保证图像识别效率的情况下,针对现有单阶段图像识别方法所存在的问题,本文提出一种特征金字塔语义信息双向融合的多尺度图像识别方法(bidirectional feature fusion-based detector,BFFD)。该方法通过特征金字塔中不同尺度特征语义信息的双向融合,提升图像多尺度物体识别的精确度。也即,特征金字塔中小尺度特征语义信息可以融入大尺度特征,且大尺度特征语义信息也可融合进小尺度特征。基于此,本文的主要贡献包括:①提出一种特征金字塔语义信息双向融合方法bidirectional feature fusion(BFF)。BFF通过高分辨率归一化方法实现不同尺度特征的语义信息,为多尺度图像识别建立特征基础。②提出一种基于特征金字塔双向融合的多尺度图像识别方法BFFD。BFFD嵌入特征金字塔语义信息双向融合方法BFF,而后通过嵌入深度神经网络,实现高精度的多尺度图像识别。③验证了所提多尺度图像识别方法的性能。通过大量的对比实验验证了本文所提出的BFFD算法能有效提升现有方法的多尺度图像识别性能。
1 图像特征金字塔双向融合模型及图像识别方法
图1为本文所提出特征金字塔双向融合的多尺度图像识别方法BFFD的总体架构。BFFD首先通过深度神经网络提取不同尺度的特征映射,并作为特征金字塔语义信息双向融合方法BFF的输入。而后,BFF通过语义信息双向融合生成多尺度特征互补语义信息,实现对特征映射的细化。最后,根据学习到的特征图生成分类阈值和边框,并通过非最大值抑制(non-maximum suppression,NMS)得到最终结果。BFF包括特征融合和自适应特征优化两个步骤。特征融合归一化不同尺度图像语义特征,得到超分辨率的特征映射。自适应特征优化通过全连接层实现图像多尺度信息的双向融合,生成每个金字塔级别的特征映射。而后,BFFD分别用分类网络来实现分类预测,用边界回归网络输出边框回归。
多尺度问题是图像物体识别的重要问题之一。现有基于金字塔的方法大多采用自顶向下(自上而下)的方式。图像语义信息单向从大尺度特征单向流转、汇聚到小尺度特征。其使得小尺度特征的物体识别效果较好,而大尺度特征的物体识别效果并无太大改善。显然,大尺度特征映射也同样可以通过小尺度语义信息进行完善,从而解决较大物体的边界模糊问题。为解决该问题,本文提出一种特征金字塔语义信息双向融合BFF算法。BFF算法通过特征语义信息的双向增强,保证小尺度物体识别精确度的基础上提升大尺度物体识别精确度。自顶向下的特征金字塔融合方法和BFF算法之间的比较如图2所示。
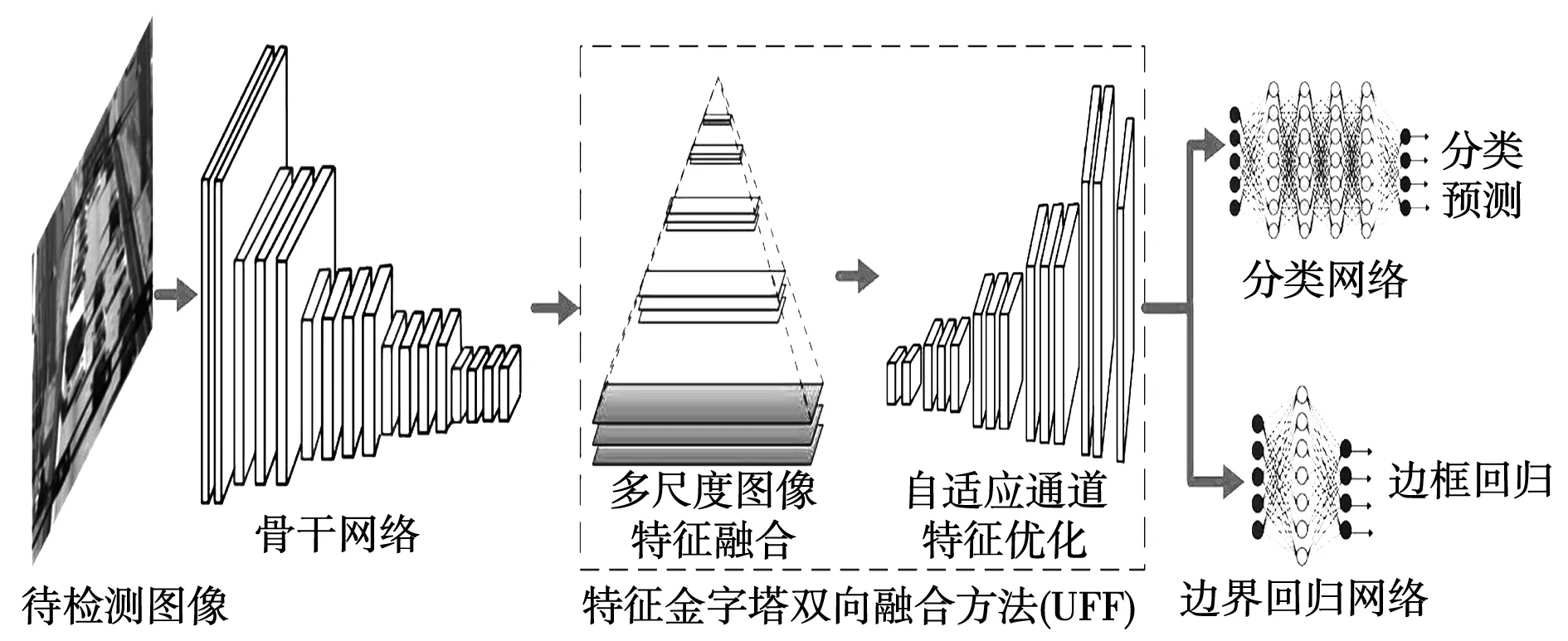
图1 特征金字塔双向融合的多尺度物体 识别方法(BFFD)框架图Fig.1 The framework of Bidirectional Feature Fusion-based Detector(BFFD)

图2 特征金字塔双向融合方法(BFF)与 自顶向下融合方法对比示意图Fig.2 Comparison diagram of Bidirectional Feature Fusion(BFF) and top-down fusion method
本文采用归一化方法将特征金字塔中不同尺度特征映射到统一尺度,实现多尺度图像特征的融合。具体地,本文借鉴超分辨率方法[13],通过不同的抽样因子来实现尺度归一化操作。假设输入图像特征用三维矩阵表示为(D·r2)×H×W,其中r为抽样因子。尺度归一化是在r2通道的同一空间对元素进行周期性重排。故有
L(d,y,x)=S([d/r2],y+[mod(d,r2)/r],x+mod(mod(d,r2),r))
(1)
其中:L为大尺度图像特征;S为小尺度图像特征。显然,输出特征只有原始通道的1/r2倍。本文通过特征向量串联的方式实现归一化后多尺度特征的融合。
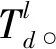
(2)
(3)
(4)
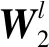
σ(x)=max(0,x)
(5)
(6)

最后,将所提出的BFF算法嵌入到图像识别神经网络,形成一种新的基于特征金字塔语义信息双向融合BFF算法的图像识别方法BFFD。在具体实现上,BFFD通过将所提出的BFF算法嵌入到RefineDet[14]实现。VGG[15]在保证具有相同感知野的条件下,通过提升网络的深度,在一定程度上提升了神经网络的效果。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。相较于VGG19,VGG16具有相对较少的网络层数、较快的运算效率和相当的效果。本文所提出的BFFD算法选用VGG16[15]作为骨干网络。同时,根据RefineDet对VGG16的参数做了一定的采用了修改。首先,通过子采样参数将VGG16的fc6和fc7转换为卷积层convfc6和convfc7。由于conv4-3和conv5-3具有不同的特征尺度,本文使用L2标准化将conv4-3和conv5-3中的特征范数缩放到10和8,然后在反向传播过程中学习尺度。输入大小设置为512×512。为了生成多层次的图像特征,RefineDet的TCB模块替换为本文所提出的BFF算法。
2 实验验证
本部分首先介绍实验设置,包括实验环境、数据集、对比方法和评测指标等。而后,通过与多种对比方法的实验比对,系统验证所提BFFD方法能有效提升多尺度图像识别。
2.1 实验设置
实验环境。实验环境为4个英伟达1080TI GPU,CUDA 8.0和CUDNN 7.0。实验训练的批大小设置为32。在实验中,VGG16采用ImageNet 2012数据集[16]进行预训练。不失一般性,初始状态下的训练学习率设置为2×10-3。在训练到第300和350个周期时,训练学习率分别调整为2×10-4和2×10-5。在训练到第400个周期时,训练结束。
数据集。实验的数据集包括:PASCAL VOC[17]和MS COCO[18]。PASCAL VOC和MS COCO数据集分别包含20和80个物体类别。在PASCAL VOC数据集中,训练数据集为PASCAL VOC的trainval训练数据集,测试数据集为PASCAL VOC的测试数据集。在MS COCO数据集中,训练数据集为trainval35k,其内包含8万张图片;余下为测试数据集。
对比方法。由于BFFD采用VGG16作为骨干网络;因此,对比方法选用同样为VGG16的图像识别方法,包括Faster R-CNN(Faster)[2],ION[19],MR-CNN[20],SSD[5]和RefineDet[14]。
评价指标。本文选用平均精确度AP(average precision)和mAP(mean average precision)平均精度均值作为多尺度物体识别性能的核心指标。AP和mAP的定义如下:
(7)
(8)
其中:R为召回率集合;p(r)为召回率为r时的精确度;I为分类总数;AP(i)为分类i的平均精确度。

表1 PASCAL VOC数据集实验结果(粗体为最佳结果)Tab.1 Experimental results of PASCAL VOC data set (bold is the best result)
2.2 实验结果
表1为PASCAL VOC数据集中20类物体的实验结果。本文所提出的BFFD算法在20类中的自行车、船、瓶子、小汽车、猫、桌子、人、羊和火车等9类物体取得了最好的图像识别准确率;其次是RefineDet512算法(输入512×512的RefineDet算法),其在飞机、公交车、椅子、牛、马和摩托车等6类物体中取得最好的识别准确率。再接着是SSD算法和MR-CNN算法。最后是Faster算法和ION算法。显然,BFFD算法在大多数类别的图像识别中都取得了最好的精确率。BFFD算法在PASCAL VOC数据集上的平均精度均值是80.4%,是所有算法中最好的。RefineDet512、SSD512、SSD300、MR-CNN、ION和Faster的平均精度均值分别为79.7%、79.5%、77.5%、78.2%、75.6%和73.2%。显然,BFFD算法的多尺度图像识别平均精度均值较RefineDet512要高0.7%。
为了进一步验证所提BFFD方法多尺度图像识别的精确度,本部分还在MS COCO数据集上进行了进一步的验证。在实验中,OHEM++和Faster为双步骤图像识别方法,其他方法都为单步骤图像识别方法。在图像识别中,图像越精细,也即原始输入图像大小越大,图像中信息相对较多,则图像识别效果相对较好。在单步骤对照方法中,本文对最新的SSD和RefineDet,以及BFFD算法都设置图像输入大小为512×512,以开展实验结果对比。
表2为MS COCO数据集上的实验结果。其中,FPS(frame per second,帧数)为每秒检测图像的数量,其数值直接采用文[3]的实验结果。显然,在相同输入条件下,BFFD算法较SSD512算法和RefineDet算法都具有较低的FPS值。也即,BFFD算法的运算效率要优于SSD512和RefineDet算法。实验还验证了不同IoU(intersection-over-union,交并比)对图像识别精度的影响。在实验中,IoU分别设置为0.5,0.75和0.95。不难看出,随着IoU数值的增大,所有算法的平均精度值都降低。然而,在3种不同的IoU实验中,BFFD算法都取得了最好的多尺度图像识别平均精度。由于RefineDet是图像识别较好的算法;为此,本部分重点对比本文所提BFFD算法跟RefineDet算法。显然,在IoU分别为0.5、0.75和0.95时,BFFD算法的平均精度分别为58.4%、39.1%和33.8%,比RefineDet算法分别提高3.9%,3.6%和0.8%。最后,实验还验证了在IoU = 0.75时,不同尺度物体的识别精度。从表2可知,BFFD算法对小尺度、中尺度和大尺度物体的识别精度分别为16.6%、37.8%和45.2%,其比RefineDet算法分别提高了0.4%、1.4%和0.8%。实验结果,本文所提BFFD算法能有效提升多尺度物体的识别精度。

表2 MS COCO数据集实验结果(粗体为最佳结果)Tab.2 Experimental results of MS COCO data set (bold is the best result)
3 结 论
引入特征金字塔是解决多尺度物体识别的有效途径之一。然而,现有基于特征金字塔的物体识别方法大多采用自上而下的特征语义信息融合方式,无法有效提升大尺度物体识别精确度。为此,本文提出一种基于特征金字塔语义信双向融合方法BFF。而后,将BFF嵌入深度神经网络,形成一种特征金字塔双向语义信息互补的图像识别方法BFFD。BFFD在保持小尺度物体识别精确度的前提下,提升大尺度物体识别的精确度,从而实现多尺度物体识别精确度。实验结果表明:本文所提方法可以在PASCAL VOC数据集上取得80.4%的平均准确度均值,比现有方法提升了0.7%。本文所提方法在MS-COCO数据上,采用不同的交并比在不同尺度的物体识别上都比现有方法具有更高的平均准确度。实验结果验证了本文所提方法能有效提升图像多尺度物体识别的精确度。
引入图像去噪[21]、去雾等[22]算法,从图像源提升待识别图像的质量也是提升图像识别的有效途径。在未来研究中,将通过引入图像去噪[21]和去雾等[22]方法以进一步提升图像物体识别的效率。
