基于逆类别注意力机制的电商文本分类①
2021-05-21胡慧君刘茂福
王 维,胡慧君,刘茂福
1(武汉科技大学 计算机科学与技术学院,武汉 430065)
2(智能信息处理与实时工业系统湖北省重点实验室,武汉 430081)
随着电子商务的快速发展,电商数据呈指数式增长.这些数据承载了各类消费群体的信息,成为了极有价值的资产,应用大数据正逐渐成为商业竞争的关键.大数据的发展,为企业带来了新的生产革命,带来了一系列的机遇.基于互联网实现电子商务数据收集,大数据分析促进了企业客户服务的差异化,强化了市场营销的针对性,增强了电子商务企业竞争力.而对电商数据的文本分类,是进行一切数据分析的基础.
依靠人力对电商数据进行分类,无法适应如今海量的电商数据且成本过高.传统机器学习难以捕捉有用的人工特征,深度学习可以自动提取特征.近年来,随着深度学习的快速发展,深度学习在自然语言处理领域取得了良好的效果.采用深度学习模型如卷积神经网络(Convolutional Neural Networks,CNN)[1]、循环神经网络(Recurrent Neural Network,RNN)[2]以及长短期记忆神经网络(Long Short-Term Memory,LSTM)[3]等进行文本分类,都取得了比传统机器学习模型更好的结果.
文献[4]中,作者使用深度学习模型对新闻文本进行分类.采用的模型包括BPNN 模型,BiLSTM 模型,TextCNN 模型和BiLSTM+TextCNN 模型,除了BPNN 模型之外,其他模型的F1 值均超过0.9,取得了较好的分类效果[4].这些模型取得的分类成果,足以说明将深度学习模型应用于文本分类,是一个不错的选择.
Attention 机制模拟人类注意力机制,对信息中的关键部分进行着重关注,最早在计算机视觉领域被提出.2014年,Google Mind 团队发表的论文《Recurrent Models of Visual Attention》真正让Attention 机制大火.作者在RNN 模型中引入Attention 机制进行图像分类,取得了良好的分类效果[5].2015年,Bahdanau 等在文献《Neural Machine Translation by Jointly Learning to Align and Translate》中将Attention 机制引入机器翻译中,这是Attention 机制首次在NLP 任务中应用[6].随后,Attention 机制被广泛应用于NLP的各个领域.文献[7]中,作者在BiLSTM 模型中引入Attention 机制对招聘信息进行分类,分类准确率达到93.36%,与其他没有引入Attention 机制的模型相比,提高约2%[7].可见,注意力机制在文本分类中有良好的作用[8].
本文主要针对电商数据的文本分类,分类过程中对上下文有较强依赖,同时,某些关键词对分类结果也有较强影响.BiLSTM 模型在对词语进行编码时,可以充分考虑上下文信息.Tf-idf值则可以衡量一个词语对一个文档的重要性,但忽略了文档的类别信息[9,10].本文由逆文档率idf的概念提出逆类别率icf,评估一个词语对一个类别的重要性,并以此引入注意力机制.将此模型的实验结果与未引入注意力机制的模型和以其他方式引入注意力机制的模型的实验结果进行对比,验证基于逆类别率的注意力机制在电商文本分类中的有效性.
1 数据处理
1.1 文本预处理
本文的数据来源于第9 届中国大学生服务外包创新创业大赛中企业方提供的真实的电商数据,从全部数据集中取部分样本,数量为156 788.一共有24 个类别,且每个类别的样本数量分布不均衡.为了确保模型能够充分学习到每个类别的特征,本文采用分层抽样的方法,将数据集划分为训练集和测试集,样本比例为7:3,划分后的数据集如图1所示.对数据集使用jieba中文分词工具进行分词处理,接着对分词结果进行停用词过滤,停用词表为哈工大停用词表.

图1 样本数量分布
1.2 生成词向量
使用Word2Vec 开源工具的CBOW 模型训练词向量,可以充分考虑到每个词语的上下文信息,训练得到的词向量维度为64.下文中提到的所有深度学习模型都将使用Word2Vec 训练得到的词向量.
2 模型描述与实现
2.1 BiLSTM 模型
双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)是一种时序循环神经网络,是由前向长短期记忆网络(Long Short-Term Memory,LSTM)和反向长短期记忆网络(Long Short-Term Memory,LSTM)组成.LSTM的提出是为了解决循环神经网络(Recurrent Neural Network,RNN)在长距离训练过程中存在的梯度消失和梯度爆炸问题,因此LSTM 在结构设计中引入了门控机制,包含3 种门:遗忘门、输入门、输出门.遗忘门决定上一时刻的细胞状态有多少信息需要被遗忘,输入门决定当前时刻的输入中有多少信息需要被添加,输出门决定当前的细胞状态有多少信息需要被输出.通过这3 种门控机制可以很容易解决RNN 在长距离训练中存在的梯度消失和梯度爆炸的问题.
LSTM 模型的第1 步是通过遗忘门来计算ft,决定上一时刻的细胞状态Ct-1中哪些信息需要被遗忘.具体实现方式是,将ht-1和xt连接,再通过遗忘门的权重矩阵Wf,最后再经过Sigmoid 激活函数σ,得到一个0-1的值,值越小,表示上一时刻的细胞状态Ct-1中需要遗忘的信息越多.

第2 步生成新的细胞状态Ct.首先,与遗忘门的操作类似,将ht-1和xt连接,再通过输入门的权重矩阵Wi,最后再经过Sigmoid 激活函数 σ,求得it来决定更新哪些信息.然后,将ht-1和xt连接,再通过权重矩阵WC,最后经过tanh 激活函数,得到新的细胞候选状态C~t.最后,使用上一时刻的细胞状态Ct-1和新的细胞候选状态来生成新的细胞状态Ct.

第3 步决定细胞状态中哪些信息需要被输出.首先,将ht-1和xt连接,再通过输出门的权重矩阵Wo,最后再经过Sigmoid 激活函数 σ,得到输出门的判断条件ot.最后,将细胞状态Ct经过tanh 层将数值规范化,再与输出门的判断条件ot相乘,得到当前时刻的输出.
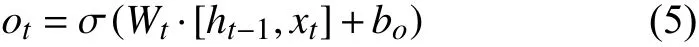

以上,就是LSTM 模型的一次流程,LSTM 可以编码句子中从前到后的信息,但是无法编码从后到前的信息.本文采用的BiLSTM 模型由前向LSTM 模型和后向LSTM 模型构成,因此,既能编码从前到后的信息同时又能编码从后到前的信息,可以更好的捕捉双向的语义依赖.
本文使用PyTorch 实现BiLSTM 模型,模型结构如图2.其中xi表示文本中第i个词语对应的词向量,由Word2Vec 训练得到.经过BiLSTM 模型后,取最后一个词语的两个隐藏层状态进行拼接得到向量h,再将向量h经过Softmax 层求得样本属于每一个类别的概率.

图2 BiLSTM 模型结构图
2.2 注意力机制
近年来注意力机制被广泛应用于深度学习的各个领域,都取得了良好的效果.其模拟人脑中的注意力分配机制,对信息中比较关键的部分进行着重关注.本文以3 种方案对BiLSTM 模型添加注意力机制.
方案一.按照文献[7]中的方式为BiLSTM 添加注意力机制,此模型为BiLSTM+Attention1 模型.计算过程如下:

其中,Ht是t时刻,前向LSTM和后向LSTM的隐藏层状态的拼接而成.Wu,bu以及uw是模型需要学习的参数.at为计算得到的权重值,表示t时刻的隐藏层状态对文本分类的贡献程度.
方案二.t f-id f值可以衡量一个词语对一个文档的重要性,计算文档中每个词语t f-id f值,将计算得到的t f-id f值经过Softmax 函数得到一个文档中每个词语的权重,以此来添加注意力机制,此模型为BiLSTM+Attention2 模型.计算过程如下:

方案三.T f-id f值可以衡量一个词语对一个文档的重要性,但是忽略了一个词语对于一类文档的重要性.因此,在方案二的基础上,提出逆类别率icf的概念,用来衡量一个词语对一类文本的重要性,再经过Softmax 函数计算一个文档中每个词语的权重,并以此来添加注意力机制,此模型为BiLSTM+Attention3模型.计算过程如下:

其中,w1和w2为模型参数,本文中,将w1值设为0.001,w2的值设为1.2 时,模型的分类效果最优.
3 实验结果与分析
3.1 实验结果
本文共有4 组对照实验,训练次数均为15 次,学习率为0.001.模型分别为BiLSTM 模型,BiLSTM+Attention1 模型,BiLSTM+Attention2 模型,BiLSTM+Attention3 模型,实验结果分别见表1至表4.精确率(Precision),召回率(Recall),F1 值(F1-score)的加权平均值对比如图3所示.加权平均值可以很好的反映模型在测试集上的分类效果.4 个模型在每个类别上的预测准确率如图4所示.
4类模型分类的准确率均超过90%.BiLSTM+Attention2 模型和BiLSTM+Attention3 模型均比BiLSTM 模型的分类效果更好,BiLSTM+Attention1 模型的分类效果最差.BiLSTM+Attention3 模型在Precision,Recall 以及F1-score 值上均是最大的,是4 类模型中最优的,但分类准确率的提升并不大.

表1 BiLSTM 分类结果

表2 BiLSTM+Attention1 分类结果

表3 BiLSTM+Attention2 分类结果

图3 4 种方法分类效果对比
3.2 原因分析
取潮流女包类和奢侈品类各5 条数据进行比较,如表5所示.两个类别样本的相关性比较高,甚至存在包含关系,如:潮流女包属于奢侈品.类似关系的还有:童书与中小学教辅,男装与户外鞋服,茶具/咖啡具与水具酒具,内衣与妈妈专区等.Attention 机制为文本中的关键词分配更多的权重,当文本比较相近时,Attention机制起到的效果会有折扣.

表4 BiLSTM+Attention3 分类结果

表5 类别数据对比
4 结论与展望
逆类别率icf可以评估一个词语对一个类别的重要性,基于逆类别率icf引入注意力机制的BiLSTM+Attention3 模型,在4 类模型中分类效果最好,F1 值最大,在电商数据分类问题上表现相对最好.但文章仍然存在不足,逆类别率icf并没有考虑词语的位置信息,词语的位置信息对于文档的语义有一定影响,将在后续的研究中不断完善.

图4 4 类模型在24 个类别上的预测准确率
