基于SSD模型的巢门蜜蜂检测
2021-05-20吕纯阳刘升平郭秀明肖顺夫刘大众杨菲菲李路华
吕纯阳, 刘升平, 郭秀明, 肖顺夫, 刘大众, 杨菲菲, 李路华
(中国农业科学院农业信息研究所, 北京 100081)
蜂业在现代农业中发挥着重要作用,是人类生活环境和经济的重要组成部分,全球有三分之一以上的粮食生产依赖蜜蜂传粉[1],同时通过蜂产品获取直接经济效益。蜜蜂养殖是蜂业的基础和关键环节,维护蜂群的健康稳定是蜂业生产正常运转的基本条件。传统蜜蜂养殖方法多依赖人力和经验,如手动打开蜂箱检查巢脾、了解蜂群状况及凭经验判断蜂群的状态等,耗时耗力。随着计算机和传感器等技术发展,基于无线网络的监测技术广泛应用于各个行业和领域,其中包括对蜂群自动化监测和控制[2],能帮助养殖人员实现对蜂群高效远程监控、降低开箱频次、减少对蜂群的影响,开创科技养蜂、智能养蜂的新局面[3]。
在低成本、高便捷度、易维护性等需求下,巢外蜂群监测逐渐受到关注。已有一些研究采用传统图像处理方法实现对蜂巢口蜜蜂监测,处理流程包括蜜蜂检测与蜜蜂数量统计两步。 蜜蜂检测方法有轮廓检测法[4]、像素分离法[4-6]、背景减除法[7-9];蜜蜂数量统计使用方法有平均像素法[4-6]、HARR波峰法[10]、信噪比估计法[7-8]、模板匹配法[9]等。
传统方法依赖一定先验知识提取图片中目标,主要缺陷有:①滑动窗口策略在进行区域选择时针对性不强,增加了时间复杂度和窗口冗余;②人工选取的特征对目标多样性缺乏很好的鲁棒性[11]。蜂巢口环境复杂、光线变化快,蜜蜂本身也存在阴影、遮挡等复杂状况,传统算法普适性差,不能应对复杂场景变化,且当蜜蜂密度较大时,准确率不高。
近年来,卷积神经网络(convolutional neural networks,CNN)和深度学习对目标检测模型进行了革新,检测精度和鲁棒性都得到提升,在人脸识别、无人驾驶等许多领域取得了突出成果。基于深度学习的目标检测主要分为两类:一类是基于区域候选方法,首先对检测区域提取候选区域,然后对候选区域进行特征提取和分类,典型的模型有R-CNN[12]、SPP-net[13]、Fast R-CNN[14]、Faster R-CNN[15]、R-FCN[16]。另一类是基于回归思想,按照一定方式划定默认框,建立预测框、默认框和真值(ground truth)框的关系进行训练,代表模型有YOLO[17]和SSD[18]。前者具有较高准确率,但其目标定位与分类分两步进行导致速度较慢,基于回归方法直接在图片中回归出目标位置及种类,实现了端到端处理,速度大大加快。SSD结合faster R-CNN的anchor机制,获得优于YOLO方法的较高精度。综合巢门区域蜜蜂的监测需求,兼顾蜜蜂检测准确率和效率,在上述两类目标检测方法中选择SSD作为本文使用方法。
1 材料与方法
1.1 数据
1.1.1数据来源数据采集地点在中国农业科学院蜜蜂研究所中关村蜜蜂养殖基地。采集时间从蜜蜂春繁开始的3月底持续到留蜜期7月,间隔为一周,共16个采集时间节点,并根据当天具体状况进行小幅度调整。采集设备为单反相机(Cannon Eos 5DsR),像素分辨率为1 920×1 080、帧率为30 fps的mp4视频。
相机架分别置于蜂箱巢门上方20、35、50 cm高度。将光照、时间段、蜂群数量、天气等变量进行多组合视频信息采集。采集控制条件如表2所示,其中光照条件(针对晴天)有正常光照、阴暗;采集时间为07:00—19:00,间隔4 h,动态选择3个时间点;针对群势不同,各挑选3个具代表性的蜂箱;天气区分为晴天和阴天(雨天蜜蜂一般不外出)。不同组合中,每一种录制3 min。根据采集方案,每天获取视频约2 h,全时期约30 h数据量。

表1 数据采集控制条件
1.1.2数据筛选和标记根据深度学习目标检测与采用方法的数据需求,将原始视频数据制作为PASCAL VOC格式数据集。首先进行视频分帧和图片筛选剪切,然后用labelImg工具进行目标标记,筛选图库和标记如图1。综合考虑光照、数量等因素,从原始图片中共选择剪切1 000张。

图1 蜜蜂样本筛选和标记
1.1.3构建数据集采用随机选取的方式,按照trainval集:test集=4∶1进行分配,其中trainval按照4∶1比例分为train和val,便于在训练中考察模型的拟合状况。
为丰富数据集中训练数据,减少过拟合,对训练数据进行增强处理。考虑光照对图片的重要性,策略是对图片颜色随机调整饱和度、对比度、亮度。增强处理后,剔除一些质量太差图片,训练集扩增600张。
1.2 模型和方法
1.2.1SSD模型SSD模型框架分成两部分: 第一部分为调整后VGG网络,去除VGG-16网络的dropout、FC8 和softmax层,将FC6 和FC7 替换为卷积层 Conv6和 Conv7;第二部分是位于后端的特征检测网络,添加了 Conv8、Conv9、Conv10、Conv11四组卷积层,与Conv4、Conv7共同组成多尺度的特征金字塔结构卷积网络(图2)。
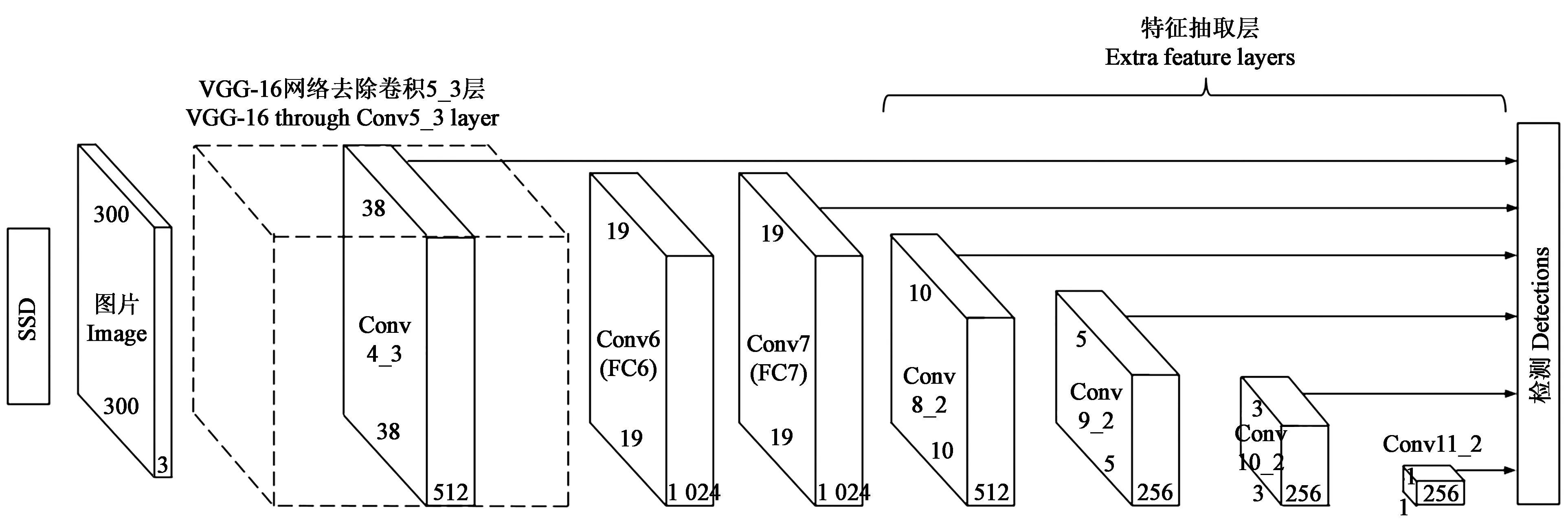
图2 SSD模型
SSD 模型输入图像的尺寸固定,图像大小分为 300×300 和 512×512 两种,基于检测实时性考虑,本文采用300×300的模式进行试验。SSD算法检测的核心是在多尺度特征图上采用卷积核来预测一系列默认框类别和坐标偏移(图3),在不同特征图的每个特征点位置划分K(4或6)个默认检测框检测目标,在SSD300中共产生8 732个检测框。针对每个检测框,根据预测得分结合非极大值抑制(non-maximum suppression, NMS)方法对检测结果进行过滤,保留最佳的一个。

注:Conv—卷积层;AP—平均池化;DB—每格默认框数;DC—检测和分类
1.2.2SSD训练策略SSD网络训练从网络构建、权重和参数设置及读入数据开始,中间需要一系列处理策略,以实现端对端的损失函数计算和反向传播计算,具体流程如图4所示。
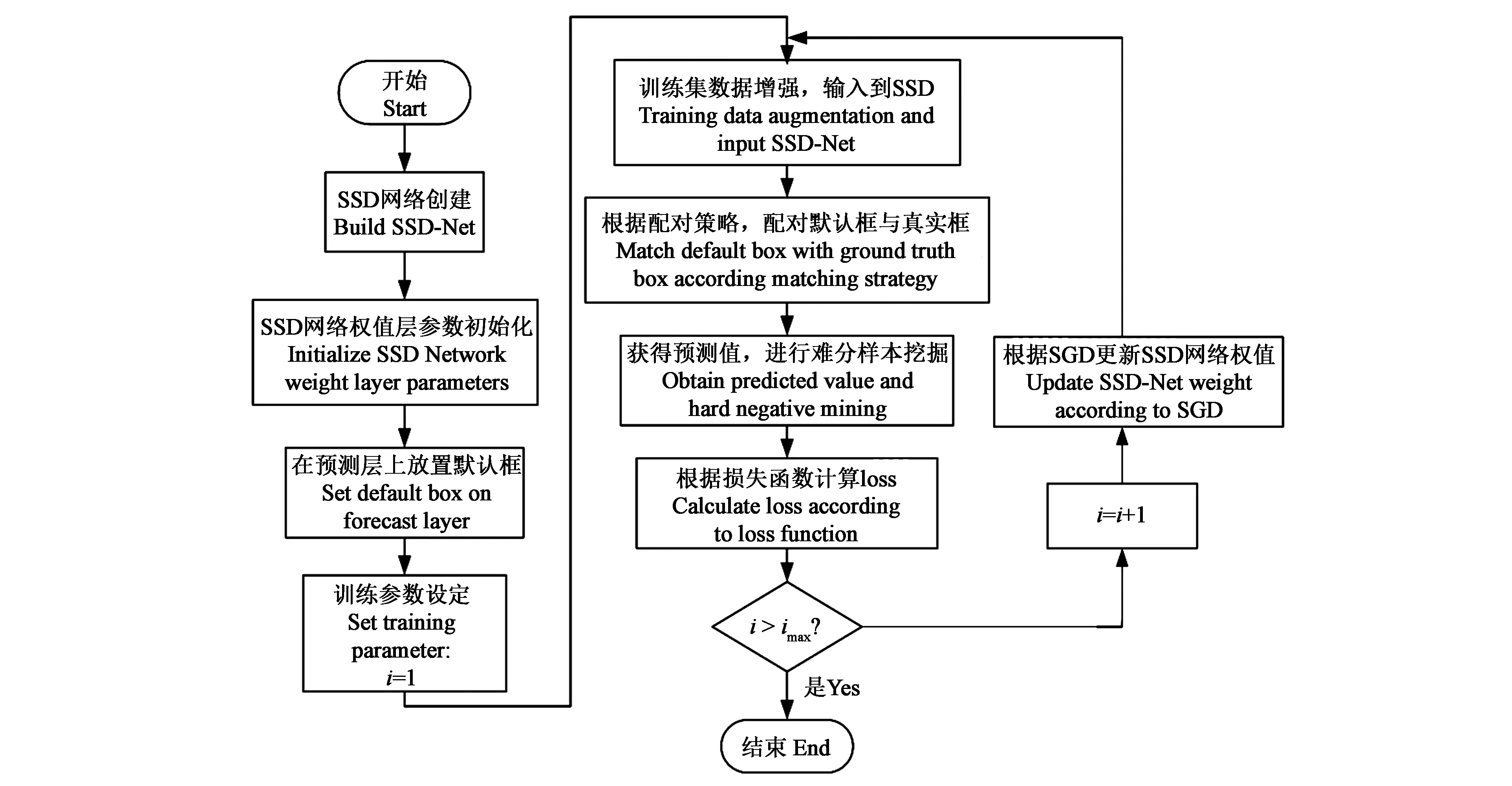
注:i表示当前训练次数,imax表示最大训练次数。
默认框设置:SSD 采用多尺度方法得到多个不同尺寸的特征图,假设模型检测时采用m层特征图,则第k个特征图的默认框比例计算公式如下。
(1)

(2)
(3)
配对策略:首先,寻找与每一个真值框(ground truth box)有最大的交并比(intersection-over-union, IoU)(公式4)的默认框(default box),保证每一个真值框与唯一的一个默认框对应起来。然后,将剩余还没有配对的默认框与任意一个真实框尝试配对,若两者之间的IoU>阈值(SSD 300 阈值为0.5)则认为match,配对到真值框的默认框就是候选正样本集,没有配对到真值框的就是候选负样本集。
(4)
难例样本挖掘:生成prior boxes后,不符合真实框的预测框(negative boxes)很多,而且远多于符合真实框的预测框(positive boxes),这样会造成正负样本之间不均衡,导致loss不稳定。因此,将特征图上每一个位置对应是负样本的预测框(预测框与真实框之间的IoU<0.5为负,反之为正)按照置信度大小排序,选择最高的几个,保证最后正负样本的比例在1∶3。
目标函数: SSD 训练同时对位置和目标种类进行回归,其目标损失函数是置信损失和位置损失之和,其表达式如下。
(5)
式中,N为与ground truth物体框匹配的默认框个数;Lconf(z,c)为置信损失;Lloc(z,l,g)为位置损失,这里采用的是Smooth L1 Loss;z为默认框与不同类别的ground truth 物体框的匹配结果;c为预测物体框的置信度;l为预测物体框的位置信息;g为ground truth物体框的位置信息;α为权衡置信损失和位置损失的参数,一般设置为1。
1.2.3模型验证模型效果的验证一方面对蜜蜂数据集中测试集进行测试,另一方面由于SSD的 resize设置使输入图片形变,考虑实际应用场景,为验证模型的泛化性能,在数据集合外选择部分1 920×1 080图片对模型测试。模型外测试图片基于蜜蜂数量分为少(n≤15)、中(15
1.2.4试验环境和参数硬件配置为Intel(R) Xeon(R) Gold6132 CPU@2.60 GHz处理器、NVIDIA-Tesla P100(16GB)显卡;软件环境为Linux系统、CUDA、OpenCV、Pytorch深度学习框架。
训练参数设置为使用随机梯度下降法(stochastic gradient descent, SGD),设定初始学习率为0.001,动量为0.9,权重衰减值为0.005,批大小为64。为了提高算法的准确性,对不同大小的数据集分别进行了训练,分别采用200、500、850、1 600张样本,包含的目标数量为5 000、12 000、21 000、38 000,每次实验训练5 000次。试验重复三次。
迭代次数对于模型训练非常重要,本研究用0.001的学习率迭代训练数据2 000次,然后用0.000 1的学习率迭代2 000次,最后用0.000 01的学习率迭代1 000次。
1.2.5评价指标根据侧重点不同,目标检测中有许多评价指标,如检测精确度、检测速度、定位准确度等。考虑在实际场景中的应用,本文侧重于目标检测的精度和速度。
平均精度(average precision, AP)是同时衡量召回率、精确率的指标,为P-R曲线下面积,用来分析单个类别的检测效果,计算如公式(6)。
(6)
式中,T为数据集中含有所需检测类别的所有图像数目,k表示数据集中目标对象的总数量。若第n个目标是所检测目标对象,则Mn为1,反之则Mn为0。Tn表示为前n张图像中所含检测目标对象的个数,分类器越好,AP值越高[19]。
此外,衡量检验模型的泛化能力、以后在实际应用场景下蜜蜂检测的准确性,采用准确率(Pr)、误检率(Pw)、漏检率(Pm)三项指标对不同数量层次的检测效果进行评价,计算公式如下。
(7)
(8)
(9)
式中,Nt为分类器检测结果中正确目标的数量,Nw为结果中非目标的数量,Lm为未被检测出来的目标数量,n是真实目标的总数量。
检测速度的衡量指标为FPS(frame per second),为每秒处理图片帧的数量。
2 结果与分析
2.1 样本库大小影响
测试数据集验证结果表明,第一次试验AP为0.467 9,基本能对较显著蜜蜂进行检测。第二次将数据扩大为500张,AP为0.782 1,对不完整的目标能进行检测。第三次AP为0.880 2,对中等数量及以下情况能实现准确检测,对数量较多情况漏检较多。第四次AP为0.921 0,改善了较多数量条件的漏检问题。如表2所示,随着数量的增加,准确率会快速提高。且每一次训练中,随着迭代次数增加,准确率会与显著上升,说明充分的迭代对模型准确率比较关键,但是需要避免过分的迭代造成过拟合,降低了模型的泛化性能。

表2 不同样本数量训练结果
2.2 不同数量层级准确率
考察模型泛化性能,采用上述数据集合外的300张图片统计不同数量层级的正确率、误检率和漏检率,检测结果如图5所示。从左至右为数量少、中等和较多三种情况,每种的正确率、误检率和漏检率评价指标如表3所示。数量较少时,能高准确率的对蜜蜂实现检测工作,达到96.34%;中等数量时,出现遮挡情况增多,导致漏检率和误检率提升,准确率为92.52%;当蜂群进入流蜜期,活动量与蜂群规模会大量增加,巢门区域蜜蜂数量随之增加,遮挡情况高频出现使蜜蜂堆叠不可避免,该情况下准确率为88.06%,依旧保持较好检测效果。
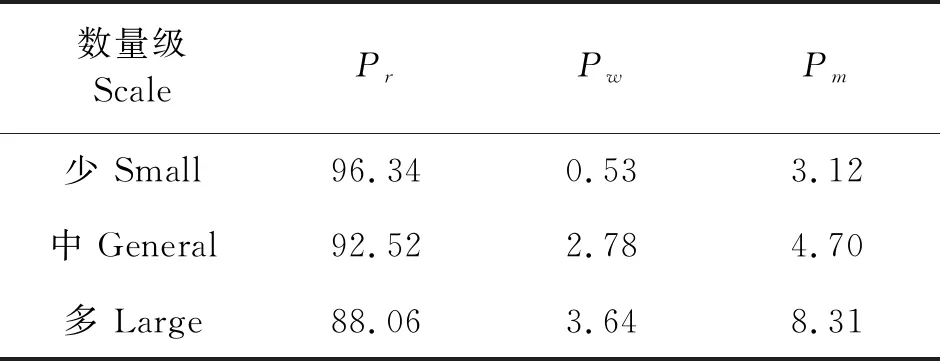
表3 不同数量层次检测效果

图5 不同数量级
2.3 检测效果比较分析
以前对巢门区域蜜蜂检测多是采用传统图像处理,图6比较了前人和本文方法的检测结果。前人研究采用了不同颜色的巢门,并使用轮廓检测、像素分离等方法对蜜蜂进行检测和数量统计。其中白色背景的检测效果较好,在使用白色背景的多个研究中,准确率结果如表4所示,从小到大依次为85.5%、73.0%、63.0%。本文亦采用了像素分离法结合平均像素法对蜜蜂数量进行统计,部分实验图片如图6。不同颜色下每个数量级分别采用50张照片进行了检测,其中白色背景结果最好,数量级从小到大准确率依次为78.2%、69.5%、56.0%,准确率高于传统方法。
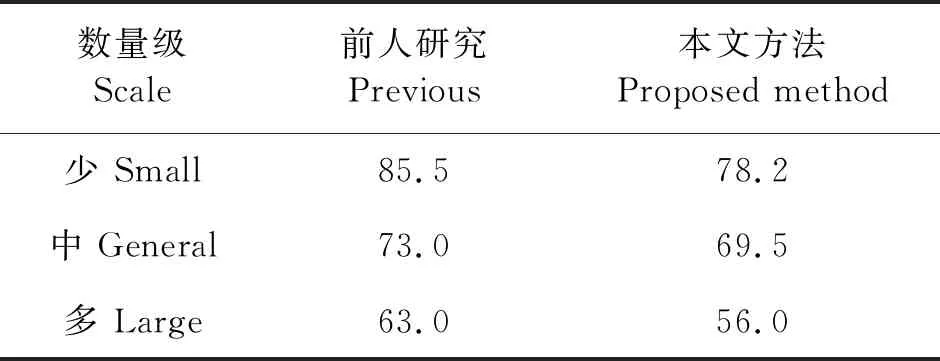
表4 传统方法准确率

图6 传统方法和本文方法检测比较
2.4 多条件适应性
针对不同应用条件,如不同光照、天气阴晴、拍摄的距离等,本文采用方法均具有较强适应性,结果如图7所示。在不同条件中的适用,给该方法进行巢门区域蜜蜂数量监测的实际应用提供了依据。

注: La、Lb、Lc、Ld分别为强光、弱光、强光遮挡、弱光遮挡;Oa、Ob、Oc分别为晴天、多云、阴天;Da、Db、Dc分别为不同拍摄距离。
2.5 复杂目标检测效果分析
传统图像处理方法的检测中,蜜蜂投影去除是研究的重点和难点,SSD模型能对图片中蜜蜂投影实现滤除;数据采集过程中,设备晃动或蜜蜂快速移动,都难以避免使图片中蜜蜂不清晰,该情况下蜜蜂的准确检测能提高整体检测准确率,SSD能实现对虚化状态蜜蜂的检测;进入花期后,蜂群的规模和活动量增加,巢门附近区域蜜蜂逐渐增多,蜜蜂间遮挡成为常态,这个问题在以往的研究中多是采用昂贵的蜂箱改造技术,限制遮挡来进行处理,本研究对大部分遮挡情况实现了检测,结果如图8所示。

图8 蜜蜂复杂状况
2.6 不同设备检测速度
为进一步验证该方法在实际应用中的可能性,分别在NVIDIA-Tesla-P100、NVIDIA-GeForce MX150和CPU-intel i78565U三种不同硬件上对算法检测速度进行测试,结果分别为68、14和8 FPS。随着硬件设备的快速发展,处理能力越来越强、价格越来越便宜,对巢门区域蜜蜂数量的检测会达到实时处理,在实际生产养殖中得到应用。
3 讨论
目前,蜂箱巢门区域蜜蜂检测计数多采用传统的图像处理方法,此类方法依赖经验,在精度不高且复杂场景下适应性低。单向多框检测器(SSD)[18]是目标检测主要框架之一,速度方面借鉴了YOLO方法中回归的思想,可直接在图像中回归目标位置及其类别,大大加快了检测速度;另一方面,结合Faster R-CNN的区域推荐网络(region proposal network, RPN),提高了检测的准确率,因此相比较Faster-RCNN来说,该算法具有显著的速度优势,对比YOLO方法又具有明显的平均准确率(mean average precision, mAP)优势。本文采用深度学习的目标检测SSD模型使用便捷,适应多种应用场景并且有效的提高了检测统计的准确率。
当前,传统方法对蜂箱巢门区域蜜蜂的统计分为两步进行。首先提取图片中蜜蜂区域,然后采用平均像素等方法处理蜜蜂区域实现计数,两步产生的误差叠加使得准确率低下。从表4可以看出,前人研究和本文方法中,均在蜜蜂数量较少的情况下准确率最高,分别为85.5%、78.2%。本文采用SSD方法同时完成检测与计数,依赖卷积神经网络强大的特征提取能力,检测计数准确率在蜜蜂少量、一般数量、较多数量情况中分别提升到了96.34%、92.52%、88.06%。
在训练过程中,通过减小损失函数值可以确保在提升预测框类别置信度的同时,也提高预测框的位置可信度,通过多次结果优化,不断提高模型的目标检测性能,从而训练出性能较好的预测模型。SSD模型对不同场景表现出良好的适应性。从检测效果上说,深度学习SSD模型对复杂目标情况的识别能力比传统方法蜜蜂检测更具有优势性。蜜蜂的阴影、虚化和互相遮挡问题是上述蜜蜂区域提取环节准确率不高的结症,本文方法对其达到很好的抑制效果,如图8,同时传统方法对图片获取场景具有特殊要求性,光照、拍摄距离等变化使检测效果大幅度下降。
传统方法一方面在蜜蜂检测阶段对漏检、阴影去除方面都有所欠缺,另一方面数量统计阶段进一步产生误差,与本文采用SSD方法相比,准确率低,且算法应用场景单一、鲁棒性差,不能够满足多环境、多条件应用。本文为深度学习在蜂群自动化监测中的应用提供了可行性和验证,一方面提高了巢门蜜蜂检测的效果,也为后期蜂箱蜜蜂进出量统计研究中的蜜蜂跟踪奠定了基础。本文仍需要进一步扩增数据集合数量、从SSD特征图特征融合角度改进算法,进一步提高模型的鲁棒性和准确率。同时基于检测计数结果对蜜蜂进行识别跟踪是下一步研究内容。
