深度学习在作物病害图像识别方面应用的研究进展
2021-05-20周惠汝吴波明
周惠汝, 吴波明
(中国农业大学植物保护学院, 北京 100193)
在农作物栽培与管理过程中,病害是制约作物品质提高与产量增长的重要因素,而病害的正确诊断又是有效防控病害的必要前提。传统的病害田间诊断都是由人工完成的,由于作物种植区面积比较大,而近年来植保站基层人员紧缺,农户又多缺乏病害识别的相应知识,因此很难实现病害爆发中心的及时准确定位及病情的精确定量监测,给粮食稳产高产增加了风险。由于大范围培训农户病害识别的专业知识和技能耗时耗力,且田间人工诊断作物病害存在易于疲劳和主观误差大等各种局限性,亟需更加方便快捷准确的作物病害诊断方法,以便及时对症下药防控病害,减轻作物生产管理压力。
随着人工智能技术的崛起,利用计算机视觉对作物病害图像进行自动化识别与诊断成为近年国内外一大研究热点。Dhingra等[1]将病害图像识别方法分为七步,依次是病害图像输入、图像预处理、图像分割、特征提取、特征选择、病害分类及表现评估。其中,特征提取与选择在整个病害图像识别过程中至关重要,能够对最终的诊断结果产生直接影响。根据特征提取与选择方法的不同,可以将作物病害图像自动识别技术分为依赖人工提取特征的传统机器学习算法和基于深度学习的病害图像识别两类。传统机器学习存在着两大局限性:第一,其算法是由人工设计提取特征,需要设计者进行大量试验和拥有足够多的专业知识,从而决定哪些特征的选取对于目标任务来说更为合适[2];第二,其提取的是目标底层视觉特征,未经加工,往往只允许机器利用这些表象特征作为自动检测或分类的依据。而深度学习的出现解决了这两大问题。利用深度学习方法对作物病害图像进行识别的步骤如图1所示。这一方法可通过多层次的网络结构对未加工数据进行底层特征的提取及组合,抽象出更为复杂的非线性高层特征,通过不断筛选特征优化模型,达到自动化识别的效果[3]。较之传统机器学习,深度学习的另一优势是其大数据处理上的优异表现。大数据中往往蕴藏着成千上万的参数,传统机器学习因效率和准确率而受限,而深度学习则能对大数据进行快速而准确的处理,自动提取有用参数进行总结[4]。
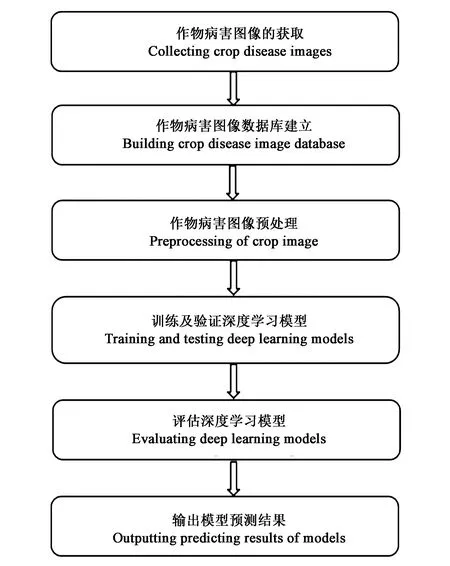
图1 基于深度学习对作物病害进行识别过程
近年来针对深度学习算法的优化及应用不同深层网络模型进行图像识别的研究成果层出不穷,在作物病害诊断方面也取得了一系列进展。本文梳理了深度学习的发展历程, 介绍了在图像识别方面应用最为广泛的卷积神经网络,阐述了深度学习在作物病害诊断方面的研究现状及实践应用中所面临的困难与挑战,并对该领域的应用前景进行了展望。
1 深度学习与图像识别
1.1 深度学习的发展历程
深度学习是机器学习的一个分支,其概念的正式提出要追溯到2006年,Hinton等[5]提出了一种新的深度神经网络模型——深度置信网络(deep belief nets, DBN)。这一模型通过一种快速贪婪算法逐层训练受限玻尔兹曼机以获得较好的参数初始值,再对结果进行微调优化,大幅提升了建模能力,使得训练深层神经网络成为现实。同年,Hinton等[6]提出了用于解决“梯度弥散”问题的方案。自此,深层神经网络取得突破性进展,以“深度学习”之名出现在大众视野。伴随着GPU的出现,计算机处理数据的能力越来越强,此前限制深层网络模型训练速率的参数过多问题在某种程度上得到了解决[7]。ReLU(rectified linear unit)激活函数以及防止训练过拟合的正则化方法Dropout的出现为2012年深度学习在ILSVRC (The ImageNet Large Scale Visual Recognition Challenge )比赛中的优异表现创造了条件。2009年,斯坦福大学教授李飞飞带领其团队建立了来源于互联网的图片数据集“ImageNet”,并创办了ILSVRC比赛用于推动计算机视觉的发展[8]。2012年,由Hinton的学生Krizhevsky提出的AlexNet模型在比赛中远超第二名[9]。自此,深度学习迅速崛起,并连续包揽了2012—2017年ILSVRC比赛的冠军,掀起了深度学习的研究热潮[10]。
1.2 深度学习与浅层神经网络
深度学习是机器学习经历的第二次热潮。机器学习初次兴起是在20世纪80年代中期,Rumelhart等[11]提出了反向传播算法(back propagation, BP),其原理就是利用统计学规律,不断优化整个神经网络中的权值,从输出层往隐含层进行反向传播直到输入层,以梯度下降的方法使输出值与真实值之间的误差不断缩小,反复迭代直至收敛[3,12]。以这一算法为核心提出的典型浅层学习网络就是支持向量机(supported-vector machine, SVM)。其主要思想是通过样本点之间可能的最远距离构造出决定阈值,再上升到一个高维空间,并从中获取最优分类面。它对高维数据表现出很好的鲁棒性及泛化能力[13-15]。在此之后的10年,支持向量机都是最热门的图像识别算法之一。然而,随着分类要求越来越高,所要表示的函数越发复杂,浅层神经网络无法学习时,深度学习成为解决这些问题的另一条途径。较之浅层学习,深度学习有其无法替代的优势:其一,具有多层非线性映射结构,能够完成复杂的函数逼近;其二,可通过逐层学习算法提取输入图像的显著独立特征,在大规模数据集上达到更好的分类效果[16]。
1.3 图像识别与深度学习算法——卷积神经网络
目前深度学习算法大致可分4类:卷积神经网络、限制性玻尔兹曼机、自编码和稀疏编码[17]。其中,在图像识别方面应用最为广泛且实践效果最好的应属卷积神经网络(convolutional neural networks, CNN)[18]。卷积神经网络是在1989年由加拿大多伦多大学的博士后LeCun等[19]提出的。1998年,LeCun等[20]建立了手写数字集MNIST,并开发了历史上第一个真正意义的卷积神经网络图像识别模型——LeNet-5。因其优异的手写数字识别能力,这个模型很快被很多美国银行应用于识别支票上的手写数字。卷积神经网络一般由卷积层、池化层和全连接层三部分组成,其基本结构如图2所示。卷积神经网络不需要进行复杂的前期处理和特征提取环节,可将原始信号(一般为图像)用作数据输入[14]。在输入高分辨率图像时,卷积神经网络较其他神经网络有明显优势,其卷积层取代了标准神经网络中的矩阵乘法,拓扑杠杆空间关系使得参数数量减少,大大降低了网络模型的复杂度,提升了学习效率。而标准反向传播算法的应用则使得学习效果提升[21]。卷积神经网络适合解决图片分类问题,识别准确率往往远超其他神经网络,因此目前作物病害识别领域常用的模型多基于此,如AlexNet[9]、GoogleNet[22]、VGGNet[23]、ResNet[24]、InceptionV3[25]、MobileNet[26]等。

图2 作物病害识别卷积神经网络结构
2 深度学习在作物病害识别方面的应用
2.1 单一作物病害识别
对单一病害进行图像识别一般分2种情况,区分作物是否患该病,或区分同种病害不同症状或患病程度。
黄双萍等[27]将基于深度卷积神经网络GoogleNet的方法用于水稻穗瘟与健康稻穗的分类。该研究利用Inception重复堆叠出GoogleNet的主体网络结构,再利用Softmax函数进行二分类,在对户外拍摄的水稻高光谱图像的识别中取得了92.0%的穗瘟检测精度。Jin 等[28]同样采集了小麦健康麦穗与患赤霉病麦穗的高光谱图像,并将像素光谱数据重构为二维数据输入到CNN模型中,结果表明,二维的CNN模型要优于一维的。在此基础上,还提出一种卷积层与双向循环层相结合的神经网络算法用于训练,在与LSTM、GRU及其他6种组合算法的对比试验中识别结果最好,证实了这一新算法在小麦赤霉病穗识别上的优越性。Dechant等[29]基于卷积神经网络建立了一个能够搭载在空中或地面工具上的自动识别玉米大斑病的田间系统,该系统先使用5种不同的CNN对切割后的图块是否含病斑进行判断,再选择其中的3种CNN分别生成完整图片的热点图,最后利用CNN对图片是否患病进行最终判定,准确率达到了97.8%。Liang等[30]利用移动窗口的方式将稻瘟病图像切割成128×128像素点的小图块,得到含病斑和不含病斑两个图像集,然后分别使用小波变换,局部二进制编码直方图和卷积神经网络对图片特征进行提取,使用五重交叉检验法及构建t-SNE地图对3种特征提取方法的效果进行比对,卷积神经网络有着明显的优势。以上是诊断作物是否患有目标病害的研究案例。
在对同一病害不同类型进行识别方面,张楠等[31]针对稻瘟病急性型、慢性型及白点型3种不同发病类型开发了基于Softmax分类器的病害识别方法,通过10重交叉验证法取得了95.2%的平均识别率。单一作物病害分类在实际应用中适用范围较窄,且难度较低,人工提取特征后使用线性判别或浅层神经网络的方法就能达到非常高的精度。Orillo等[32]利用反向传播算法对水稻白叶枯病进行识别,在仅含134张图片的情况下达到了100%的准确率。袁媛等[33]利用支持向量机的方法对水稻纹枯病进行自动化识别取得了95%的准确率。因此,利用深度学习进行单一作物病害识别的研究较少。
2.2 同种作物上不同病害识别
现阶段国内外研究人员多致力于研究同种作物上不同病害之间的鉴定,且主要集中在几种重要的粮食作物和经济作物上,比如水稻、玉米、番茄、棉花等。
在粮食作物方面, Lu等[34]提出了一种基于深度卷积神经网络的水稻病害识别方法,构建了一个含3个卷积层、3个池化层与2个全连接层的深度网络结构对9种水稻常见病害及健康水稻叶片共10类500张图片进行训练,并利用10重交叉验证法对模型进行了评估。研究结果表明,该模型的准确率可达到95.48%,表现优于传统的机器识别模型SVM、BP和PSO(particle swarm optimization)。张航等[35]为识别小麦常见6种病害构建的卷积神经网络模型具有5个卷积层、4个池化层和1个全连接层,使用500幅小麦病害图片对其进行训练,再利用300幅样本图片进行测试,整个模型平均准确率达99.3%。Zhang等[36]利用改进的GooleNet和Cifar10两个模型实现了玉米9种叶部病害及健康叶片的精准识别,并使模型的参数量达到远少于VGG和AlexNet的水平,从而大幅度提高了训练效率。Oppenheim等[37]则更注重参数数值的选择。在Matlab的平台上对VGG模型的结构进行了微小的改动并对土豆块茎的4种病害进行分类识别,结果表明,训练集与测试集的比例及训练周期会对识别准确率产生影响。
经济作物方面,张建华等[38]建立了一个含棉花6种常见病害共5 510幅图片的不均衡数据集,将VGG16模型的3个全连接层改成2个,然后使用迁移学习获取预训练参数,并进行参数微调,最终获得了89.51%的平均准确率。Rangarajan等[39]利用卷积神经网络对6种番茄病害及健康叶片共一万多张图片进行迁移学习,选用了VGG16和AlexNet两种模型,并对两者的训练准确率、不同尺寸的小批量图片包(minibatch)的执行时间、不同权重与偏重学习速率(different weight and bias learning rate)进行了比较分析,综合来看,AlexNet的表现要优于VGG16。郭小清等[40]提出了番茄叶部病害在不同时期症状不同的问题,对AlexNet进行了去除局部响应归一化,调整卷积核大小,调整全连接层3次改进,使得模型参数大大减小,运行速度加快。最后与其他3种轻量化模型MobileNet、 SquezeeNet和LeNet进行比较。改进后的AlexNet模型,无论是内存大小、运行速度,还是对不同时期病害识别的准确率,都是最优。尽管近几年网络模型层出不穷,但选择哪个模型更适合目标作物的病害识别还需要经过不断的尝试和实用检验。
2.3 多种作物混合病害的识别
对多种作物上不同病害进行识别的难度更高,因为不同作物可能会发生类似病害,正确区分作物对于病害识别有重要意义,而有一个大数据集能够充分发挥深度学习在作物和病害识别上的优势。Ferentinos[41]所进行的混合病害识别研究就是基于一个由25种作物58个类别构成的87 848张图片的较大型数据库。Mohanty等[42]利用AlexNet和GoogleNet对开放式数据库PlantVillage中的54 306张图片进行了分类识别,其中包含14种作物26种病害或健康作物叶片,模型准确率达到了99.35%。
在满足数据库数量基本要求的情况下要想进一步提升识别精度和模型性能,可以对网络架构进行创新与改进。Pardede等[43]利用卷积神经网络在特征提取上的优势,提出了一种基于卷积自编码的无监督特征学习算法来进行植物病害的检测。先利用带有卷积层的自编码器提取图片特征,再使用SVM作为图片分类器。该方法无需标记数据,且性能优于传统的隐藏层较多的自编码器。Sardogan等[44]同样将卷积神经网络用作特征提取器,先对图片进行剪裁后分别输入到三种颜色通道中,再使用卷积层进行特征提取,然后使用LVQ(learning vector quantization )算法对图像进行分类,最后取得了86%的平均准确率。蔡汉明等[45]提出了一种深度可分离卷积与卷积相结合的模型,深度可分离卷积由逐深度卷积和卷积组成,与标准卷积相比可以降低12%的计算量,在保证准确率的前提下降低对硬件的需求。卜翔宇[46]采用小卷积核连续卷积层结合稀疏Maxout激活函数层对水稻、大豆以及玉米的常见病害图片进行了分类识别,取得了91.67%的平均识别率。这些图片并没有经过图像预处理,在复杂图片背景下表现依旧优于同等条件下的传统模式识别方法,再次自证了深度学习在图像识别方面的优势。
除却作物图像数据库的建立和网络结构的搭建,模型的参数选择也是非常重要的一步。Adedoja等[47]选用NASNetMobile对PlantVillage图集进行训练,探讨了批大小、优化函数、周期、学习率等超参数的选择对模型性能及表现的影响,选择最优的超参数组合进行训练最后达到了93.82%的准确率。孙俊等[48]在对多种植物叶片病害进行分类识别的过程中,从卷积核尺寸、全局池化类型、激活函数类型、初始化方式4个方面分别测试了不同的参数选择对训练准确率的影响。在图集大小、模型选择确定的情况下,参数的选择对于精度的进一步提升起着重要作用。
3 问题与挑战
虽然近年来国内外陆续研发出作物病害智能识别的手机软件,用以解决农户不识病、不会治的问题,但这些软件普遍存在识别准确率低,可诊断病害类别少等问题,无法达到理想的应用效果。笔者在查阅了大量文献和实际研究的基础上,总结了现阶段在作物病害图像识别领域应用深度学习技术时存在的几个典型问题。
①实际拍摄的图片背景过于复杂,给目标病害的识别造成了较大干扰。研究人员或选择室内拍摄或用纯色面板作背景,基于此训练出的模型在识别田间照片时准确率会明显降低。也可手动给患病部位做标记,限定识别区域,但这种方法耗时耗力且无法实际应用。较为有效的手段是提前对图片进行病斑与背景的分割或扩充图片数据库。另外,曾伟辉[49]在卷积神经网络的基础上引入自注意力机制用以关注图像重点区域,从特征提取的角度有效解决了复杂背景的干扰问题。
②不能很好地处理图片的阴影斑驳。在病害诊断过程中,病斑的颜色往往是重要的分类依据之一。自然光照条件下,拍摄的角度、高度或者地点可能会导致部分图片中病斑位置的颜色深浅不一,使得病斑特征不明显,从而影响训练精度。在实际应用时,可适当调整拍摄角度、高度,选取合适的拍摄时间进行针对性解决。对图片进行归一化处理能够减轻因品种、拍摄条件不同带来的颜色、亮度的差异[50]。
③同一种作物上若病害同时发生会造成特征紊乱,影响分类结果。某些情况下,同一植物叶片中会出现不同病害的症状,甚至会因为多种病害复合感染而表现为全新的症状。若图片训练样本过少且病害部位并未重叠时,可手动裁剪出含不同病害部位的图片部分。由于目前并没有针对并发症状提出的解决算法,为避免对特征提取产生干扰,建议采集只存在单一病害的照片。
④同种病害的不同发病时期症状不同。发病时前期和后期叶片一般会表现出不完全相同的症状。同时,病原菌可以在作物不同时期进行侵染,发病时又会因作物的品种、生育期和部位表现出不同的症状。以稻瘟病为例,它由稻梨孢侵染造成,病菌可以在各个生长时期侵染水稻,造成苗瘟、叶瘟、穗颈瘟和谷粒瘟。叶瘟又可分为白点型、急性型、褐点型和慢性型病斑[51]。因此,要想实现某种病害的精准识别,收集不同时期不同类型的症状也是必不可少的。
⑤缺乏大型公开的单一作物病害图像数据集。除网络上几个比较流行的植物病害图像共享数据库如PlantVillage和AI Challenge,研究人员多使用自己搜集的图集,图集可能来源于互联网,也可能是自行拍摄的图片。这些图集忽略了品种、地区间病害的差异,也忽略了不同拍摄者可能存在拍摄取向上的差异,因此建立的模型虽然可以达到很高的训练精度,但是泛化能力不强,难以实际应用。如果使用同一公共数据集对不同模型进行训练,能对模型的优缺点有更客观的比较。
⑥小样本问题会造成过拟合现象。简单来说,过拟合指的是在训练过程中,模型在训练数据集上的误差不断下降,在验证数据集上的误差却在不断上升的现象。在对小规模样本的农作物病害图像数据集进行分类时,深层网络过度提取特征就容易造成过拟合现象,并且训练速度和识别速度都会减慢[52]。在没办法增加数据集样本的情况下,可以通过数据增强、迁移学习或者随机抑制神经元即增加dropout层的方式来减轻过拟合现象。
⑦学科交叉对研究人员的专业素质要求更高。由于植物病害的自动化识别与植物病理知识以及计算机编程都紧密相连,而目前从事这一研究的多出自其中一个领域,相应的就会缺乏另一学科的知识。在构建数据集时,非植保专业人员可能对病害图像进行误判。同样地,如果植病研究人员想要结合深度学习对作物病害识别进行研究,又需耗费大量时间学习计算机相关知识,且很难在算法上有所创新或对模型进行深层改良。因此,加强交叉学科人才的培养对于促进作物病害自动化识别有着重要意义。
4 结语
在植物病害图像集的收集及前期处理过程中存在很多问题亟待解决,比如田间图片背景复杂,光线造成阴影斑驳,多重病害交叠,症状随时间变化等。同时,在后期的训练过程中可能会出现数据集样本不典型、过拟合等问题,还需要计算机技术人员和植保专家相互交流合作,或由拥有交叉学科知识背景的研究人员不断探索以加速作物病害图像智能识别的进程。事实上深度学习不止卷积神经网络这一种类型,但是目前在作物病害识别方面该类型的应用最为广泛,研究最为深入,希望未来研究人员能够在其他类型的深度学习网络上做更多的尝试。
2015年是图像识别领域取得突破性进展的年份,因为在这一年计算机人脸识别准确率已经高于人类,这无疑给人工智能领域注射了一剂强心剂。尽管受到人工神经网络的局限,计算机不具备对事物认知的前期知识储备以及达不到人类大脑神经网络的复杂程度,学习能力还无法与人类相提并论。但不容否认的是,深度学习依旧是目前最具潜力的作物病害图像识别的现代化方法。
