大数据在粮库信息化中的应用
2021-05-20刘廷凤吴建军
刘廷凤,吴建军
(河南工业大学 信息科学与工程学院,河南 郑州 450001)
0 引言
从字面上讲,大数据意味着大量的数据。大数据的关键在于它所包含的信息,这些信息可以帮助人们洞察过去,甚至预测未来。大数据的意义不仅在于数据本身,而在基于它之上所进行的一系列的分析活动,比如分类汇总、趋势预测、数据挖掘等,从而产生有价值的数据来帮助人们发掘潜在信息。我国“十三五”规划纲要提出实施国家大数据战略,建立国家安全体系,提高粮食等方面风险防控能力[1⁃2]。构建和处理粮食大数据,对于保障粮食安全、建立粮情信息云平台、信息发布工作和完善粮情检测预警体系有重要意义。
1 我国粮食大数据发展现状
当前我国粮食库存充裕、供应充足、市场稳定,尚不存在“粮食安全”问题,但从长远来看,粮食生产环境约束增强、存放方式难以为继、发达国家新兴技术的应用和生物质能源发展等一系列因素导致了粮食供需不稳定和粮食产业格局的改变。目前我国逐渐大力推进粮库智能化建设以适应发展现状。粮食行业是大数据产生和发挥作用的重要领域。粮库中各种传感器和测量仪器检测到的温度、水分、气体浓度、害虫种类等粮情数据呈指数级生长且各个粮储公司也积累了庞大的数据[3],但是这些数据仍存在大量问题:
1)数据冗杂,量多不全。长年积累的粮食历史数据和实时数据较多,但仍有些重要的数据没有采集或收集很少。例如粮食行业的信访问题、安全操作隐患点及整改情况、粮库人员变更信息等,这些数据表现出短期无效性,但从长远来看,恰恰是当前多发,易发问题或代表发展趋势问题的数据资料。
2)数据孤岛,互不联通。数据条块分割严重,没有联系。具体表现在:粮食行业内部数据统计都是纵向的,没有横向联系,形成一张涵盖粮食全部统计的数据表[4]。
3)数据浅显,缺乏分析。对粮食数据没有深入的认识分析,缺乏探索数据规律的意识,数据整合分析能力薄弱。
2 粮食大数据应用中的关键技术
处理粮食大数据的关键技术一般包括大数据采集、大数据预处理、大数据存储与管理、大数据分析及挖掘、大数据展现和应用[5]。粮食大数据包括历史数据和实时数据,整理、清洗数据,从而生成新的数据集,为后续的数据查询分析提供统一的数据视图。大数据预处理后将数据存储并管理,对大规模结构化数据采用新型数据库集群,用Hadoop 实现对半结构化和非结构化数据的存储与管理。大数据分析最为流行的便是机器学习算法,机器学习的迭代性、容错性和参数收敛的非均匀性比传统的数据分析处理技术有明显的优势。最后通过大数据分析建模建立粮食大数据预警模型,为粮食安全提供有力支持。物联网、云计算是粮食大数据应用中的基础。物联网的布设是为了更便捷高效地采集粮食大数据、云平台存储大数据,并用云计算技术对大数据进行处理。粮食大数据应用路线图如图1 所示。
2.1 粮食大数据挖掘算法
以粮食温度为例,根据粮食贮藏实践经验,禾谷类粮食的温度一般在5~20 ℃,不会发生问题。现在有粮食温度数据,这些数据中粮食温度大部分在5~15 ℃,但是有一部分偏高或偏低,甚至有-20 ℃,70 ℃这些异常数据。根据这些数据可以推测粮食现在或者即将出现什么问题以及为什么会出现这些问题。首先需要对粮食温度数据进行预处理,包括数据筛选、数据变量转换、坏数据处理、数据标准化、主成分分析、属性选择等[6]。通过数据预处理可以提高数据挖掘分析结论的有效性和准确性。经过数据预处理得到可以直接建模的数据,用聚类分析算法对粮食温度数据进行建模。聚类分析是按照样本特征将其分类,数据相似度高的样本归为一类,不同的类差异较大。聚类模型可以不依赖于标记数据或预先定义的类,是一种非监督学习算法。
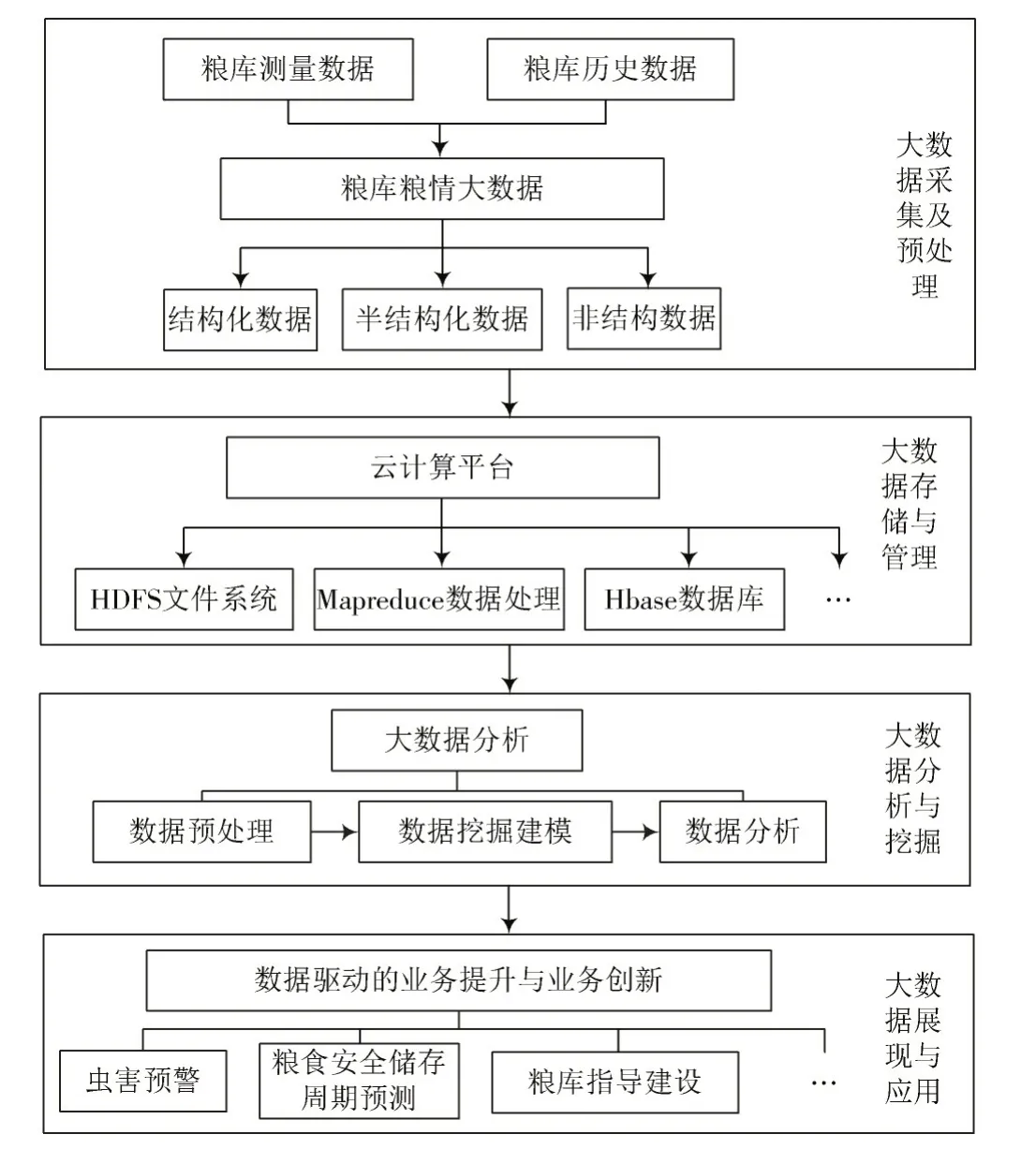
图1 粮食大数据应用路线图
K⁃means 算法是一种基于距离的聚类算法,在最小化误差函数的基础上将数据划分为预定的K类,该算法原理简单并便于处理大量数据。K⁃means 算法原理是首先为每个质心定义一个集群,ci∈C,C为质心集合,然后每个数据点根据如下公式被分配到一个集群:

式中dist(·)是标准欧氏距离。
重新计算质心,通过获取分配给质心集群的所有数据点的平均值来完成,公式如下:
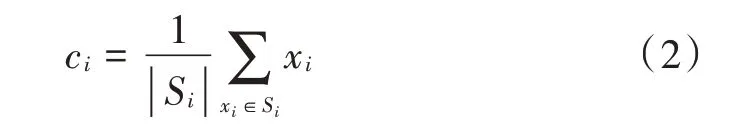
式中Si为指向第i个集群质心的数据点集合。K⁃means算法在式(1),式(2)之间迭代直到满足停止条件。
K⁃means 算法过程[6]为:
1)从N个样本数据中随机选取K个对象作为初始的聚类中心。
2)分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中。
3)所有对象分配完成后,重新计算K个聚类的中心。
4)与前一次计算得到的K个聚类中心比较,如果聚类中心发生变化,转过程2),否则转过程5)。
5)当质心不发生变化时停止并输出聚类结果。
算法的损失函数是平方误差:
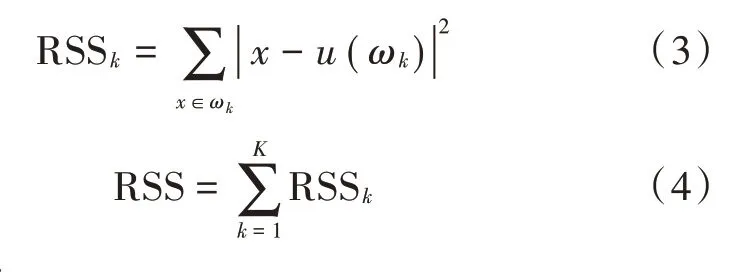
式中:ωk表示第k个簇;u(ωk)表示第k个簇的中心点;RSSk是第k个簇的损失函数;RSS 表示整体的损失函数。
以小麦在同一时间r点和f点位置测得的粮堆温度数据为例,如表1 所示,对温度特征采用K⁃means 聚类算法,设定聚类个数为3,最大迭代次数为500 次,距离函数取欧氏距离。聚类温度特征分群效果图如图2 所示。通过分群密度图分析分群特点,如图3~图5 所示。
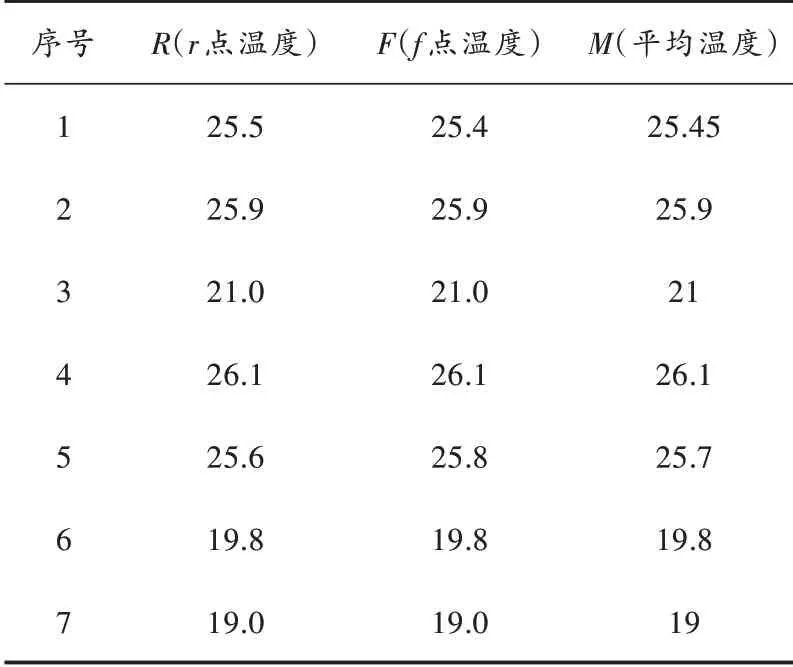
表1 粮堆温度特征数据 ℃
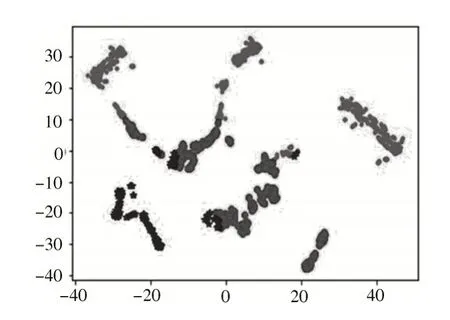
图2 K⁃means 算法聚类温度特征分群效果图
图中:红色代表分群1;绿色代表分群2;蓝色代表分群3。
分群1 特点:r点粮堆温度集中在26~28 ℃;f点粮堆温度主要集中在25~27.5 ℃;平均温度集中在26.5 ℃。
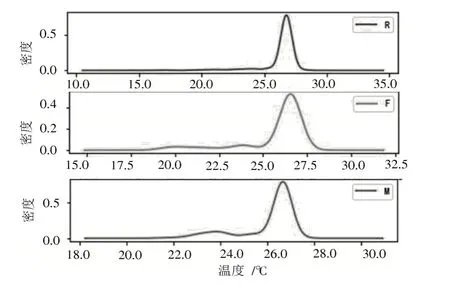
图3 分群1 概率密度函数图
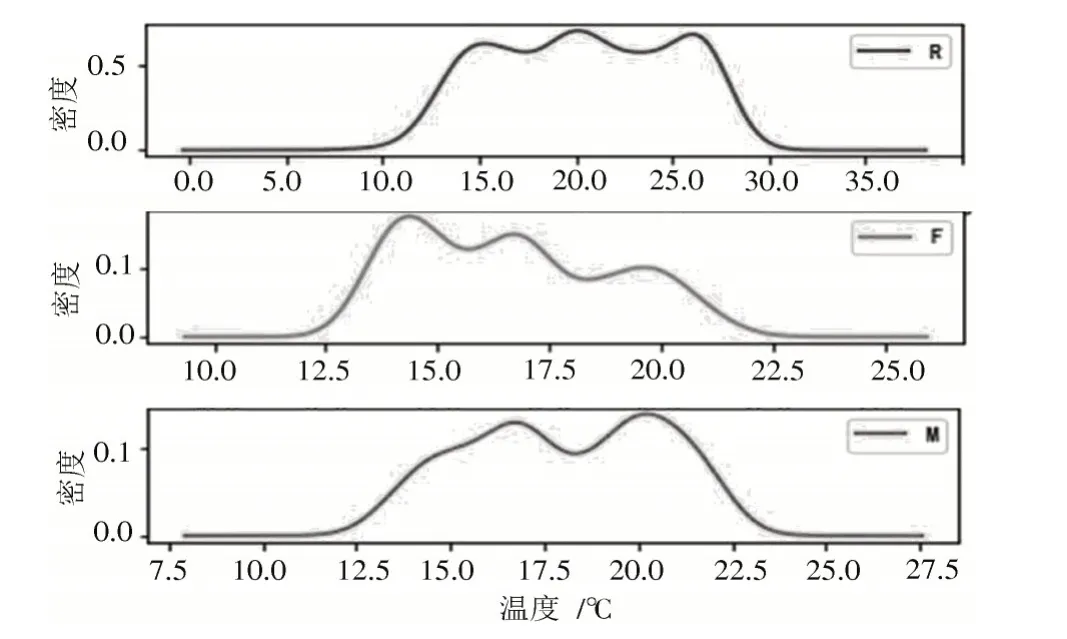
图4 分群2 概率密度函数图
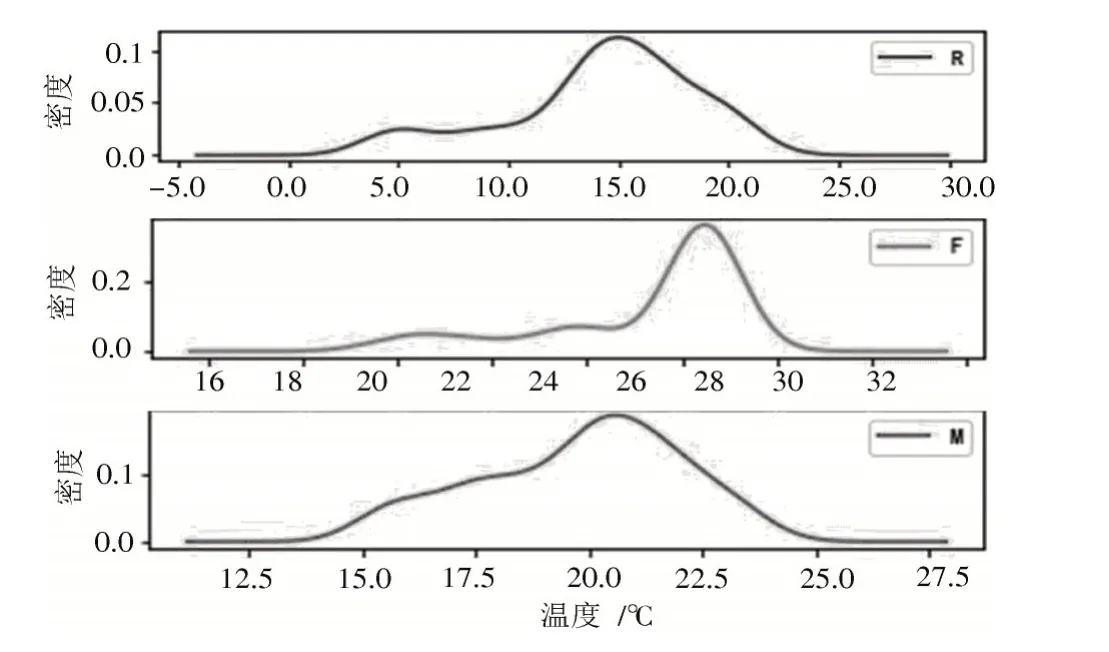
图5 分群3 概率密度函数图
分群2 特点:r点粮堆温度集中在10~30 ℃;f点粮堆温度集中在12.5~22.5 ℃;平均温度在15~21 ℃。
分群3 特点:r点粮堆温度集中在0~23 ℃;f点粮堆温度集中在25~27.5 ℃。
对比分析,不同位置的粮堆温度差异较大,分群1粮温变化较小,温度在26 ℃左右;分群2 粮温变化范围较大,较分群1 温度值低;分群3 粮温变化范围相对分群2 小,但比分群1 大。
通过对粮温数据的分析,可以获取很多信息,比如,分群1 中粮温变化小但整体温度较高,为了保证储粮安全,需要进行通风降温处理以免生虫霉变。
2.2 大数据在粮情预警中的应用
大数据的发展使得信息获取更加全面和准确,基于大数据开展粮食监测预警,获取的往往是局部最优解而不是全局最优解,但是随着Hadoop、Spark 等数据分析平台的建立,大数据分析将变得更加高效,从粮食检测到预警的过程将会变得快速准确[7⁃10],使得大数据在粮情预警中起到不可比拟的作用:
1)虫害预警。粮仓是一个生态系统,粮食的温度、水分和外界环境的异常都会唤醒粮食的“生命力”,造成粮食虫害霉变。利用粮食大数据进行数据挖掘,建立模型分析数据,发现异常,从而达到预警的目的。
2)设备故障预警。从粮食大数据的异常值中发现离群点,从而分析是否是设备故障或储粮异常,设备测量故障可以直接从数据反映出来。
3 结语
构建粮食大数据体系有两点建议:
1)建立统一完善的数据采集标准、存储标准、分析标准,让数据共通共联共享;
2)粮食大数据的来源除了传统的传感器检测获得的数据外,还包括实时交易数据、行为数据、遥感数据,让粮食大数据更加完善准确,让粮食大数据从粮仓“走出去”,为粮食市场、粮食产业安全预测预警提供支持。粮食大数据将往更加智能化、精细化、全面化的方向发展,更加精准地预测粮情,为粮食安全做好坚实的后盾。
