激光诱导荧光结合AdaBoost 算法的食用油分类
2021-05-20周孟然赵晋级来文豪
周孟然,赵晋级,王 煜,胡 锋,来文豪,卞 凯
(1.安徽理工大学 电气与信息工程学院,安徽 淮南 232000;2.南京四方亿能电力自动化有限公司,江苏 南京 211111)
0 引言
随着国民经济水平的提高,食用油在日常生活中发挥着不可替代的作用,快速、准确地识别食用油的种类对于安全使用食用油具有重大意义。当前食用油分类多以化学分析方法为主,例如气相色谱法、液相色谱法、电子鼻法[1]等,这些传统的方法存在分析速度慢和设备昂贵等缺点。一些研究者近些年常采用光谱法对食用油进行识别,如傅里叶变换光谱法[2]、近红外光谱法等,这些光谱方法相对于传统的化学分析方法速度快,但分类准确率却不是很高。
基于以上提出的问题,文中提出一种激光诱导荧光(Laser Induced Fluorescence,LIF)技术和AdaBoost 算法结合的食用油快速、准确识别方法。
激光诱导荧光光谱技术具有分析速度快、灵敏度好、准确率高和抗干扰能力强等优点[3],在化工、医疗、生物和环境[4]等诸多领域中有广泛的应用[5⁃6]。文献[7]根据LIF 技术快速性的特点,将LIF 技术用于矿井突水种类的检测,文献[8]将LIF 技术应用于土壤中多环芳烃的检测,文献[9]将LIF 技术应用于假酒的识别。文献[10]将LIF 技术结合KNN 算法用于初榨橄榄油的定量分析,该文利用K⁃近邻方法(KNN)对处理过的光谱数据建立模型,这种处理方法可以实现快速对初榨橄榄油的定量分析,但准确率却很低。
本文提出的AdaBoost⁃KNN 算法是在KNN 算法的基础上进行集成,集成之后的分类准确率更高,泛化性能更好,且不需要对光谱数据截取、去噪和降维,节省了大量时间。AdaBoost 算法现已广泛应用于模式识别和图像识别等诸多领域[11⁃13],但目前,还未看到有文献将AdaBoost 算法应用于植物食用油的分类。
1 理 论
1.1 激光诱导荧光
本文将LIF 技术应用于食用油的分类检测,实验中使用的激光器为405 nm 蓝紫光半导体激光器(北京华源拓达激光技术有限公司),USB2000+光谱仪(美国Ocean Optics)可以接收340~1020 nm 的激光,分辨率为2048。根据激光诱导荧光检测的原理,搭建的激光诱导荧光检测食用油模型如图1 所示。

图1 激光诱导荧光实验系统图
1.2 算法描述
AdaBoost 算法的学习过程实质是在不停学习中改变样本的权值,直到学习的结果误差为0 或者学习器个数达到预设值,然后把所有弱分类器学习的结果按权值综合,输出最终结果。算法流程如下:
输入:训练数据集T=({x1,y1),(x2,y2),…,(xn,yn)},
其中,xi∈X,yi∈Y={1,2,3,…},迭代次数为M。
1)初始化训练样本的权值分布
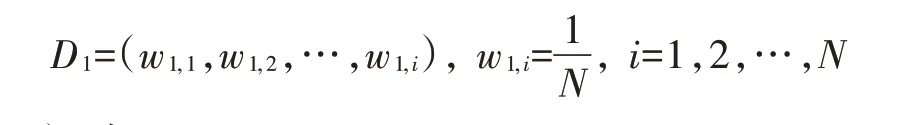
2)对于m=1,2,…,M
①使用具有权值分布Dm的训练数据集进行学习得到弱分类器Gm(x);
②计算Gm(x)在训练数据集上的分类误差:

③计算Gm(x)在强分类器中所占的权重:
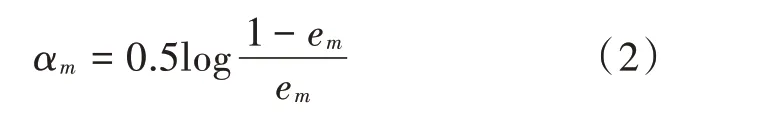
④更新训练数据集的权值分布:
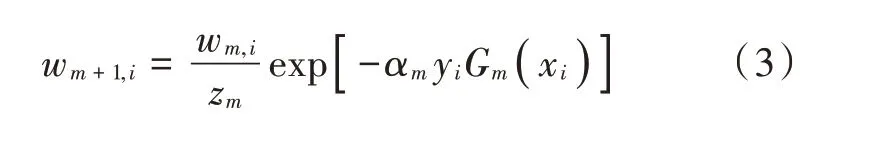
式中zm为归一化因子。
1.3 实验材料
本实验采用的实验材料为5 种植物食用油,分别命名为油样A,B,C,D,E;5 种实验样本的特性如表1 所示。为了尽可能减少环境因素对实验的影响,油样的光谱采集在无光且温度相对恒定的环境中进行,实验中每种油样采集150 组荧光光谱,即5 种油样共采集750 组光谱数据。
原始荧光光谱图如图2 所示。

图2 原始荧光光谱图
由图2 五种油样的荧光光谱可知,不同油样的荧光强度差异主要在400~600 nm 之间。图3 为同一品牌不同食用油的荧光光谱。
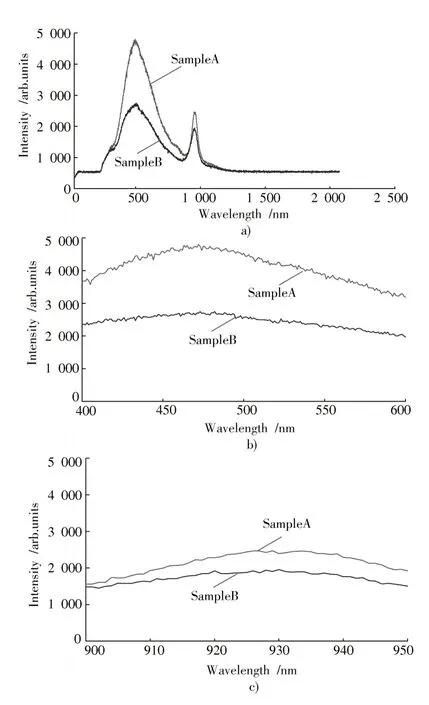
图3 同一品牌不同食用油的荧光光谱

表1 实验材料
2 结果分析
2.1 BP 神经网络建模
算法实现平台为Matlab R2017b,BP 算法的学习率设置为0.1,目标设置为0.00004,迭代次数设置为100,随机选择750 组光谱数据中的600 组作为训练集建模,然后通过测试集测试该模型的分类效果。为了减小实验误差,实验100 次取平均值,手动设置隐含层个数,不同隐含层个数下的分类准确率如表2 所示。

表2 不同隐含层个数BP 分类准确率 %
由表2 可以看出,当隐含层个数增加时BP 算法对油样光谱数据的分类效果有所提升,当隐含层个数为5时,该模型对油样光谱数据的分类准确率最好可以达到92.69%。
2.2 AdaBoost⁃BP 算法建模
用AdaBoost⁃BP 对所有的光谱数据随机选择600 组作为训练集进行建模,剩下的150 组作为测试集测试分类效果。首先初始化权重D,迭代次数T设置为100,模型训练过程中,误差曲线如图4 所示。

图4 训练误差曲线
由图4 可知,AdaBoost 算法在油样光谱识别中,训练误差收敛速度很快,在训练迭代3 次之后训练误差已经降为0,表明由原始高维的油样光谱数据训练好的AdaBoost 模型可以用于油样激光诱导荧光光谱识别。AdaBoost 模型的测试结果的分类准确率如表3 所示。

表3 不同隐含层个数AdaBoost⁃BP 的分类准确率 %
由表3 可知,当作为弱分类器BP 隐含层个数为5时,AdaBoost⁃BP 模型对训练集的分类准确率为100%,对测试集的分类准确率为97.14%。由图5 可以明显看出AdaBoost 算法对弱分类器的分类准确率有很明显的提升。
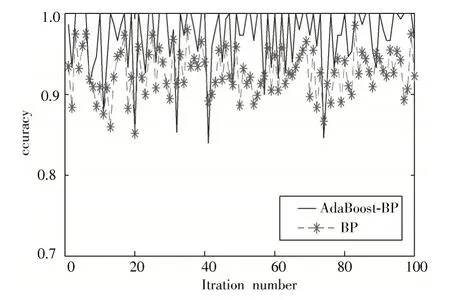
图5 BP 算法与Adaboost⁃BP 算法准确率
2.3 AdaBoost⁃tree 算法建模
初始化样本权重D(x),迭代次数T设置为100。通过结果分析可知,AdaBoost⁃tree 算法在迭代100 次之后对训练集的分类准确率可以达到100%,对测试集的分类准确率为98.89%。AdaBoost⁃Tree 分类器得到的训练周期上的替换损失如图6 所示,AdaBoost⁃Tree 在训练周期上的泛化误差如图7 所示,由图6 和图7 可以看出替换损失在第4 周期时为0,不断迭代100 次后泛化误差为0.038,具有很强的泛化性能和稳定性。

图6 AdaBoost⁃Tree 在训练周期上的替换损失
2.4 AdaBoost⁃KNN 算法建模
为了得到更高的分类准确率和更好的泛化性能,使用K⁃近邻算法(KNN)作为新的弱分类器对光谱数据建模。使用AdaBoost⁃KNN 算法对随机选择的600 组光谱数据建模。初始化样本权重D()x,迭代次数设置为T=100。AdaBoost⁃KNN 算法在迭代100 次之后对训练集和测试集的分类准确率可以达到100%,AdaBoost⁃KNN 分类器得到的训练周期上的替换损失如图8 所示,AdaBoost⁃KNN 在训练周期上的泛化误差如图7 所示。由图8 可以看出,替换损失在第19 周期时为0,此时的泛化误差也为0。AdaBoost⁃KNN 算法相比于AdaBoost⁃tree 算法分类准确率由98.89%提高到100%,且泛化性能和稳定性更好,更具有实际应用价值。

图7 AdaBoost⁃Tree 与AdaBoost⁃KNN在训练周期上的泛化误差

图8 AdaBoost⁃KNN 在训练周期上的替换损失
3 结 论
选取5 种食用油为实验对象,分别选取4 种算法针对油样的激光诱导荧光光谱的分类进行建模,先比较BP 与AdaBoost⁃BP 模型,得出AdaBoost 集成算法对弱分类器的分类准确率有很明显的提升。然后通过比较AdaBoost ⁃ Tree 模 型 和AdaBoost ⁃ KNN 模 型,得 到AdaBoost⁃KNN 模型对食用油光谱数据的分类效果最好。
