基于Mixup算法和卷积神经网络的柑橘黄龙病果实识别研究
2021-05-18陆健强林佳翰黄仲强王卫星邱洪斌杨瑞帆陈平福
陆健强,林佳翰,黄仲强,王卫星,3,邱洪斌,杨瑞帆,陈平福
(1 华南农业大学 电子工程学院/人工智能学院,广东 广州 510642; 2 岭南现代农业科学与技术广东省实验室,广东 广州 510642; 3 广东省农情信息监测工程技术研究中心,广东 广州 510642)
柑橘黄龙病(Huanglongbing, HLB)是目前影响柑橘产业最严重的病害之一,在我国已有近百年历史[1-2]。广东省是柑橘种植的主要省份之一,但受黄龙病的影响,柑橘种植面积开始下降,种植区域向广西转移[3]。多聚酶链反应(Polymerase chain reaction, PCR)是目前应用于柑橘黄龙病识别的一种较为可靠且普遍的技术,但该方法存在的问题是难以实现实时在线检测。深度学习在图像分类和回归方面有较高的准确性,其精度优于目前现有的其他图像处理技术,已广泛应用于农业、医疗等领域。
邓小玲等[4]提出了基于高光谱成像和Fisher判别法的柑橘黄龙病识别方法,柑橘黄龙病病情识别准确率为90%。邓小玲等[5]通过荧光检测技术获取柑橘叶片荧光参数,提出了利用概率神经网络对黄龙病柑橘植株分类建模,诊断准确率为76.93%。马淏等[6]提出了利用高光谱成像技术生成的光谱及纹理特征进行柑橘黄龙病识别,结合最小二乘法和SVM分类器建立分类模型,平均预测准确率为88.5%。王克健[7]提出了采用高光谱检测与无人机技术采集柑橘黄龙病成像的方法,通过柑橘黄龙病的特征光谱建立了柑橘黄龙病识别模型,识别准确率为87%。肖怀春[8]提出一种基于高光谱成像技术的柑橘黄龙病叶片可视化判别模型,通过提取特征波长识别患病叶片的纹理特征,最低误判率为3.12%。戴泽翰等[9]通过深度卷积神经网络建立柑橘黄龙病识别模型,提出4种针对8类柑橘黄龙病症状的分类器,其中最优分类器的识别准确率为93.7%。综上所述,目前针对柑橘黄龙病的无损检测多采用高光谱检测技术,但是该检测技术尚未完善,在成分波长数量较少的情况下,准确率较低[10],而且前期硬件投入成本较高,难以大范围推广。
本研究利用深度学习卷积神经网络,研究柑橘黄龙病的在线无损识别方法,解决传统柑橘黄龙病人工识别困难、智能化程度低的问题。利用卷积神经网络[11-12]自动提取特征的特点,在Inception网络架构基础上,进行深度可分离卷积(Depthwise separable convolution,DSC)设计,提出一种基于卷积神经网络的柑橘黄龙病识别模型−X-ResNeXt模型。该模型在传统数据增强方法基础上,采用Mixup算法建立样本之间的线性关系,增强模型识别数据样本的鲁棒性;通过迁移Xception网络在ImageNet数据集上的先验知识与动量梯度下降优化方法,有效提高模型的准确率与收敛速度。XResNeXt模型在保持不增加网络参数的同时拓宽模型网络结构,在柑橘黄龙病的无损检测方面有一定的可行性和先进性。
1 模型设计
1.1 数据采集
数据采集于2018年11月—2019年1月在广西壮族自治区贺州市昭平县北陀镇柑橘种植园进行。数据采集对象为初期显现病状的成年病树果实以及同期健康果实,采集设备为手持移动设备,采集距离为距柑橘果实1 m处。采集试验结束,共采集 560 张分辨率为1 920×1 080 的柑橘果实图像样本(图1),其中,患病和健康柑橘果实图片分别为224和336张。采用3∶1∶1的比例将数据集划分为训练集(336张)、验证集(112张)和测试集(112张)。为了规范数据集使用,利用中心裁剪法把原始图像分辨率固定为299×299。后期,训练集将对模型进行数据样本拟合,然后利用验证集调整模型超参数以及对模型性能进行初评估;最后将测试集输入已训练完毕的卷积神经网络模型中,得出最终试验结果。
1.2 数据增强
1.2.1 同类数据增强为提高模型训练的鲁棒性和泛化能力,本研究利用Imgaug数据增强库对采集的柑橘黄龙病原始图像数据集进行同类数据增强。增强方法包括水平翻转、垂直翻转、旋转、仿射、添加高斯噪声等[13-14]。利用Fliplr函数、Flipud函数对柑橘图像进行水平和垂直翻转;利用rotate函数对柑橘图像进行45°旋转;利用Affine函数对柑橘图像进行图像仿射。
经增强后的柑橘黄龙病图像数据集图像最终数量为7 168张,图2为部分数据增强结果图。

图 2 部分数据增强结果图Fig.2 Partial output images of data enhancement
1.2.2 Mixup 混类数据增强 同类数据增强方法设定邻域内的样本属于同一类,不对非同类类别的样本做邻域关系的建模,该方法虽然能增强模型的泛化能力,但是严重依赖于原始数据集。本研究采用Mixup[15]混类数据增强方法,以贝塔分布混合多类别数据,线性化处理样本与样本间区域,寻求增强模型预测训练样本以外的数据集的适应性,进一步提升模型对样本识别的鲁棒性以及错误类别的判断能力。图3为不同混合系数(λ)的Mixup算法进行柑橘黄龙病数据集增强的结果示意图。

图 3 不同混合系数(λ)的Mixup算法进行柑橘黄龙病数据集增强的结果示意图Fig.3 Results of enhancing the citrus Huanglongbing data set by the Mixup algorithm with different mixing coefficient (λ)
1.3 X-ResNeXt模型的设计
1.3.1 X-ResNeXt模型网络结构设计 He 等[16]提出了将152层深的ResNet神经网络引入Shortcut结构,以解决极深的神经网络难以训练的问题。Xie等[17]在ResNet神经网络的基础上提出了ResNeXt网络,其核心思想也是通过加深或加宽网络结构以寻求模型准确率的提高。但是随着模型网络结构的加深或者加宽,网络参数将急剧增多,网络计算开销也大大增加。
X-ResNeXt模型核心设计思想是在Inception网络架构基础上,进行深度可分离卷积设计,达到网络参数不增多的情况下拓宽模型网络结构的目的,以实现提高模型识别准确率的同时还具备良好的运算处理性能。该模型的具体网络结构由Xception网络[18]与ResNeXt模块融合构成,具体为:输入层的输入图像尺度为299×299×3;卷积层为深度可分离卷积模块,在1×1卷积之后,对每个通道做3×3的独立卷积;根据迁移学习的思想,冰冻Xception中间层;池化层均采用最大池化,核大小为3×3,滑动步长均为1,填充方式均为SAME;输出层采用全局平均池化层;卷积神经网络激活函数均采用ReLU函数;中间采用权重连接方式,连接上下层;最后采用ResNeXt模块替代Xception中最后一层输出层,实现了模型层数的加深以及特征的融合。图4为X-ResNeXt模型的网络结构图。
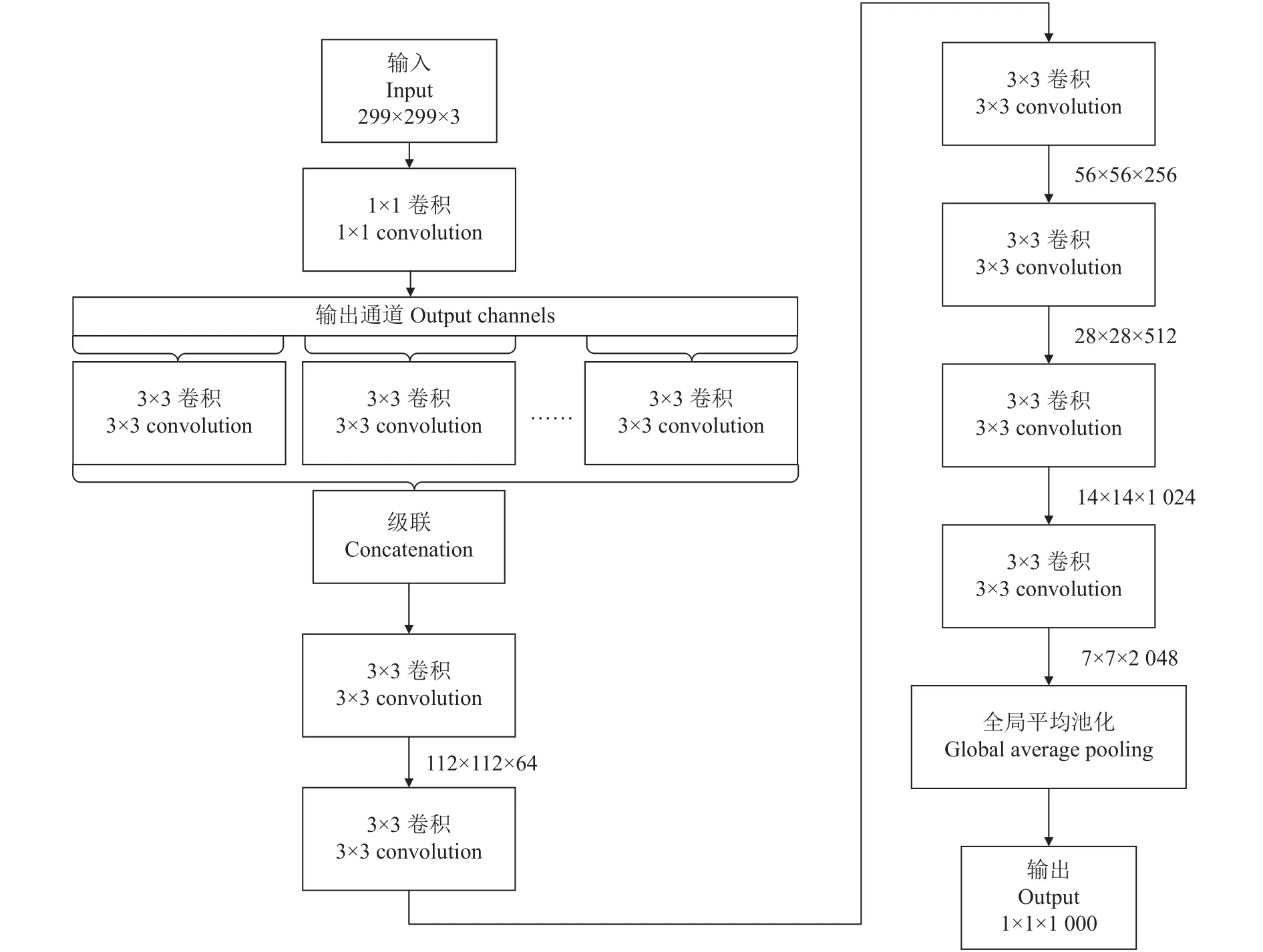
图 4 X-ResNeXt模型的网络结构Fig.4 Network structure of X-ResNeXt model
1.3.2 模型优化为解决 X-ResNeXt模型随着网络深度加深出现一定程度的梯度弥散,进一步提升模型性能,本研究迁移Xception网络[19]在ImageNet数据集[20]上的先验知识,进行模型的微调(Finetune)优化,挖掘领域间共享的潜在特征和结构;采用动量梯度下降法 (Momentum gradient descent,MGD)[21]进行参数更新,降低模型收敛过程的震荡现象,进一步提高识别准确率。
图5为X-ResNeXt模型的训练流程图。首先,由原始图像数据集生成同类增强数据集,再结合Mixup算法对数据集建立线性关系,进行尺寸裁剪。然后,迁移ImageNet数据集上的先验知识对模型进行微调。再而,设置训练数据批次大小为32×2,学习率为0.1,进行X-ResNeXt模型训练。保存最佳权重文件以及模型结构,动量大小设置为0.9,当运行每5个epoch后,模型验证集损失值停止下降时,学习率设置为原来的一半。最后,权重参数收敛后,即可得到最优的X-ResNeXt柑橘黄龙病识别模型。

图 5 X-ResNeXt模型训练流程图Fig.5 Training flow chart of X-ResNeXt model
迁移学习是一类复用跨领域学习知识,弱化样本数据特征提取不足,改进目标领域或任务学习效果的机器学习方法。ImageNet是目前图像识别最大的数据库,超过了1 400万张图像。本研究保留已训练完毕的Xception模块中所有卷积层参数,并将其冰冻;利用迁移学习方法,在最后一层全连接层借鉴模型在ImageNet数据集上优化训练所得的先验知识,更新最后一层的权重参数,以期提高模型训练速度与准确率。
模型使用梯度下降法不断逼近损失函数最优化点时,有可能会越过最低点,产生在最低点来回震荡的现象。为了提高模型参数更新的稳定性,本研究提出MGD进行参数的优化更新。动量梯度下降法的设计思想是调整函数在纵轴下降的速度,从横轴方向趋向最低点。实际操作是通过计算梯度的指数加权平均数进行权重参数的更新,在横轴给予横向速度逼近最优点。动量梯度下降法缓解了随机梯度下降法 (Stochastic gradient descent, SGD)和批量随机梯度下降法的震荡问题,减弱了模型收敛过程的震荡影响。
1.4 试验方法
1.4.1 总体试验方案 本研究首先评估数据集进行图像预处理对模型性能的影响,即决定是否对数据集进行预处理。然后进行数据同类增强对模型性能影响的测试试验,获取图像数据集经同类数据增强前后,模型性能的变化结果,以证明对图像数据集进行同类数据增强的必要性。最后,X-ResNeXt模型通过迁徙学习试验、Mixup混类数据增强试验和梯度下降优化对比试验寻求模型的最佳性能指标,从而获得最优收敛模型。通过与经典识别模型的对比试验,最终验证模型的先进性和优越性。
1.4.2 图像预处理对模型性能影响的评估试验由于光线、拍摄角度和光在传播时经过雾、霾等介质以及粒子的散射作用,图像传感器实际作业所采集的图像信息经常发生降质现象[22]。另外,果实和树叶之间相互遮挡,导致柑橘果实图像表面发生模糊和亮度不足的现象。为提高果实的识别率,研究一般采用直方图均衡化和图像锐化操作,进行柑橘图像的轮廓补偿[23],增强图像边缘位置颜色的对比度,以提高图像的清晰度。但是,本研究的目的是柑橘黄龙病的识别,直方图均衡化和图像锐化预处理方法,很容易造成原始图片的对比度过分增强,图片色彩失真,如图6所示,从而造成柑橘果实黄龙病表型特征的严重丢失,对模型训练产生误导作用。因此,应进行图像预处理对模型性能影响的评估试验,以决定是否对图像数据集进行预处理。

图 6 原图与预处理后图像对比Fig.6 Comparison of original image and preprocessed image
2 模型性能影响相关试验与结果
试验基于TensorFlow后端的Keras框架进行,计算机硬件环境如下:处理器为Intel 6800k CPU,内存为32 G,GPU为GTX 1080Ti ×2;软件操作系统为Centos7系统。评估结果采用准确率、召回率、F1值、损失值作为主要评价指标。
2.1 图像预处理对模型性能影响的评估试验
分别采用无预处理、直方均衡化预处理和图像锐化预处理的原始数据集训练X-ResNeXt柑橘黄龙病识别模型。图像数据集未作预处理时,模型的可信度为63.12%,数据集利用直方图均衡化和图像锐化分别进行预处理操作后,模型的可信度分别降低了7.91%和10.29%。可见,针对本研究的柑橘果实黄龙病识别任务,对图像数据集进行图像直方均衡化和锐化预处理操作将会对结果产生负面影响,因此本研究后续试验未对图像数据集进行预处理。
2.2 数据同类增强对模型性能的影响
分别采用原始数据集和经数据同类增强的数据集训练X-ResNeXt柑橘黄龙病识别模型,并对比2组模型的性能指标。数据集进行数据同类增强,后训练所得的模型性能指标准确率为91.38%,召回率为90.42%,F1值为0.909,与原始数据集训练所得的模型相关指标相比,分别提高了5.85%、5.96%和0.059。试验结果表明,对训练集进行数据同类增强,可在原始数据基础上增加样本特征的多样性,提高模型训练结果的准确率,体现了神经网络模型性能与训练样本数呈线性正相关的关系。从另一个角度,也说明后期随着柑橘黄龙病果实样本数的增加,模型的识别性能也将有进一步的提升。
2.3 迁移学习
利用迁移学习对X-ResNeXt模型进行微调优化,将ImageNet数据集上训练所得的权重知识迁移到柑橘黄龙病识别分类任务上。设置Dropout参数为0.5,学习率为0.1,mini-batch为32×2=64。由迁移学习的试验结果可见,模型在ImageNet数据集训练得到的权重和偏置参数经验基础上进行训练,模型训练时间由 5 220 s减少为4 788 s,表明相同条件下,迁移学习提高了柑橘黄龙病识别模型的训练速度。与无迁移学习训练的模型相比,迁移学习的识别准确率、召回率分别提高了0.61%和0.34%,F1值提高了0.006。表明在柑橘黄龙病数据集规模较小的情况下,迁移学习可加快模型收敛速度,获取局部更优化权重值,有助于提升柑橘黄龙病识别任务的相关指标。
2.4 Mixup混类数据增强对模型性能的影响
在迁移学习和L2正则化等优化策略基础上,进行不同超参数条件下的Mixup混类数据增强对模型性能影响的试验。设置Dropout参数为0.5,mini-batch为32×2=64,正则化系数为0.02,学习率为0.1,混合系数 λ 分别设置为1.0、0.8、0.4、0.2 和0。由表1可知,当λ为0.4时,X-ResNeXt模型表现最优,模型的准确率、召回率、F1值分别为93.74%、92.58%和0.932。在传统数据增强和迁移学习的基础上,这3个指标分别上升了1.77%、1.82%和0.018。试验表明,Mixup混类数据增强方法有利于提高模型识别图像样本的适应性,提升模型判别柑橘黄龙病病果的能力。

表 1 Mixup混类数据增强对模型性能的影响Table 1 Effects of Mixup mixed data enhancement on model performance
2.5 动量梯度下降优化试验
为验证X-ResNeXt模型动量梯度下降优化方法的有效性,模型分别采用MGD和SGD进行识别对比试验。设置学习率为0.1,L2正则化系数为0.01,Dropout参数默认为0.5,mini-batch为32×2=64,λ取 0.4,MGD 的动量值分别取 0、0.5和0.9。由表2可见,模型采用MGD 动量值取0.9时,识别准确率、召回率和F1值最高。表明模型经MGD优化后,参数更接近于局部最优值,模型能更有效地收敛,从而实现模型对柑橘黄龙病病果识别能力的进一步提升。

表 2 模型梯度下降优化方法对比试验Table 2 Comparison test of model optimization methods based on gradient descent
2.6 算法对比试验
选择同等条件下训练所得的Inception-V3和Xception模型进行测试试验,与X-ResNeXt模型测试结果进行比较。X-ResNeXt模型最终收敛的准确率 (94.29%)优于Xception模型(92.78%)和Inception-V3模型 (90.31%);X-ResNeXt模型最终收敛的召回率(93.69%)也优于Xception模型(91.89%)和Inception-V3模型(89.23%)。结果表明,与Inception-V3和Xception模型相比,XResNeXt模型加深了网络的深度,拓宽了网络结构的宽度,表达柑橘黄龙病的果实特征更加全面,模型泛化程度更高。
3 结论
柑橘出现红鼻子果是柑橘患黄龙病的初期症状,对该时期的柑橘黄龙病果实进行快速准确识别将进一步提高柑橘园区的产量和产品质量。本研究以柑橘黄龙病初期患病果实作为研究对象,应用卷积神经网络设计和构建一种基于Inception网络架构的柑橘黄龙病果实识别模型:X-ResNeXt模型,试验结论如下:
1)在数据量较少情况下,降低模型复杂度并迁移已有先验知识,有助于模型性能提升,说明正则化、迁移学习等模型优化策略可为柑橘黄龙病果实识别与分类模型提供高效的训练途径,可解决深度学习网络模型训练成本大、耗费资源多的问题。
2) Mixup混类数据增强方法有利于提高模型识别柑橘黄龙病果实图像样本的适应性,提升柑橘黄龙病识别模型性能,表明该新型数据增强方法在扩充数据集的同时,也提高了神经网络的泛化能力。本文将Mixup方法应用到农业智能化系统领域,并实现了对模型的优化,该结合方法可推广到未来的智慧农业研究中,进一步提升对农情监测的时效性。
3) 在准确率与召回率指标上X-ResNeXt模型优于经典识别模型,充分表明利用深度学习方法对柑橘黄龙病果实进行识别是判断柑橘植株是否患病的一种可行且可靠的方式,可为柑橘黄龙病的高精度、快速无损识别提供有益参考。
