一种基于结构相似性的Android公用库检测方法
2021-05-18慕志颖李智虎李晓宇
慕志颖, 李智虎, 李晓宇
(1.西北工业大学 网络安全学院, 陕西 西安 710072; 2.中国电力科学研究院有限公司, 北京 100192)
近年来,移动应用需求增长迅速,移动操作系统市场获得了快速增长。Android的市场份额日渐提高,已占据移动操作系统过半市场份额[1]。但Android平台的应用安全问题也越来越严重,用户隐私窃取、设备吸费等安全事件层出不穷,恶意应用程序泛滥。
为达到运行时用户无感知的目的,大部分Android恶意应用程序通过重打包方式(即将恶意代码加入反编译的正常应用程序后重新组装并签名)实现恶意功能隐藏。普通用户下载并安装该类“正常”应用后可能会在完全不知情的情况下泄漏隐私信息或遭受经济损失。因此,Android应用程序重打包检测已成为Android应用安全领域的一个研究热点[2-3]。
基于多种目的(提高开发效率、提供广告等),大量Android应用会在开发过程中使用公用代码库。绝大部分重打包检测方法[4-5]在检测前尝试排除公用代码,降低这部分代码对检测结果的影响。但在当前应用程序不断涌现、公用代码库总量不断提高的背景下,现有公用库检测方法的效率已无法满足检测的需求。
针对现有方法的不足,本文提出一种基于结构相似性的公用代码库检测方法,结合粗粒度的应用程序安装包结构分析与细粒度的代码特征比较,对应用程序安装包进行检测,快速分析并定位应用中使用的公用代码库,降低对后续重打包检测过程中的干扰。
1 相关工作
现有Android应用重打包检测方法的基本原理是将反编译后的应用安装包模块解耦,分析并提取部分模块进行下一步检测。由于需要执行成对比较,整个检测过程的开销(耗时、计算资源占用)随检测对象模块数量上升而呈指数级增长。同时,非相关模块的存在会劣化检测效果。Android应用中大量存在并使用的公用代码库对这些方法造成了严重影响。
已有一些方法[4-5]使用白名单的方式将应用中的公用代码文件过滤排除,由此提升了检测效率与效果。但该方式存在2点不足:①更新不及时,需要大量人工参与;②使用包名作为过滤条件,恶意应用可通过修改包名轻易规避。
针对这种情况,部分学者提出了一些改进方案。文献[6]反编译应用程序后从AndroidManifest.xml配置文件中获取权限等特征,通过这些提取的特征检测应用程序是否重打包。但该方法提取的特征相对比较粗粒度,容易出现较高的误判。SimiDroid提取基于方法、应用程序组件、资源文件的特征,通过这些特征不仅分析应用程序之间的相似度,还对检测结果进行了分析,取得了较好的检测效果[7]。文献[8]提取应用程序调用的关键APIs,利用图神经网络和聚类算法对图结构数据进行处理,为Android第三方库的聚类分析提供了一种新的思路。
2 基于结构相似性的公用库检测
公用库检测的核心评估指标主要为:①检出率,准确发现应用中的公用库;②速度,快速检测百万量级应用。本文提出的检测方法面向大规模量级应用环境,考虑Android应用安装包的特性,分析代码包的目录与文件分布结构,过滤结构不相似的代码包,使用代码文件的API特征进行细粒度比较,完成公用库包的分类。
如图1所示,检测过程主要包括5个步骤:预处理,将Android应用安装包解压缩并反编译;弱关联子包提取,利用PDG[9]解析各个代码子包,抽取与主包群关联性较弱的子包作为公用库候选;包结构相似度计算,基于子包目录与文件分布结构,与比较对象进行粗粒度的相似度计算;代码结构相似度计算,提取代码文件的API调用信息,生成包结构特征码并计算结构相似度;公用库分类,利用结构相似度分类至所属公用库。
2.1 预处理
本文使用apktool工具[10]反编译Android应用程序安装包,获得该应用程序的所有构成内容,包括Androidmanifest.xml、资源文件与以包形式分布的smali代码文件。
2.2 弱关联子包提取
正常应用中包括两类代码包:主包群与公用库包。主包群包含应用程序入口所在包及与入口包存在较强调用关系的代码包。公用库代码的用途主要是广告和部分功能的实现,主包群不会与公用库包存在频繁交互。同时,主包群与公用库往往都是单向调用关系。因此,与主包群之间调用次数较少或有向调用关系较弱的代码包可视为候选公用库包。将主包群与公用库包有效分离可以减少后续相似度计算消耗,提高速度。
如图2所示,本文使用PDG方法分离应用中的主包群和潜在公用库包。利用预处理后的smali文件,在代码包之间生成具有权重(调用次数)的图。结合确定的应用入口所在包,形成主包群与候选公用库包。
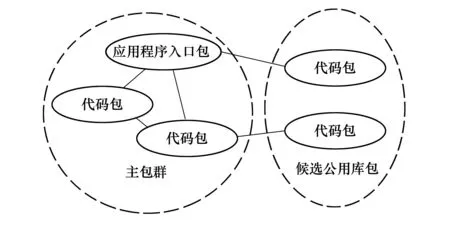
图2 子包解耦分离
2.3 包结构相似度计算
包结构主要指代码包中,文件目录与代码文件的分布情况。Android代码包结构与操作系统文件系统高度相似,可使用树状结构表示。如图3所示,包结构包括根节点(顶级包)、目录节点(子包)、代码文件节点及相应的深度信息。
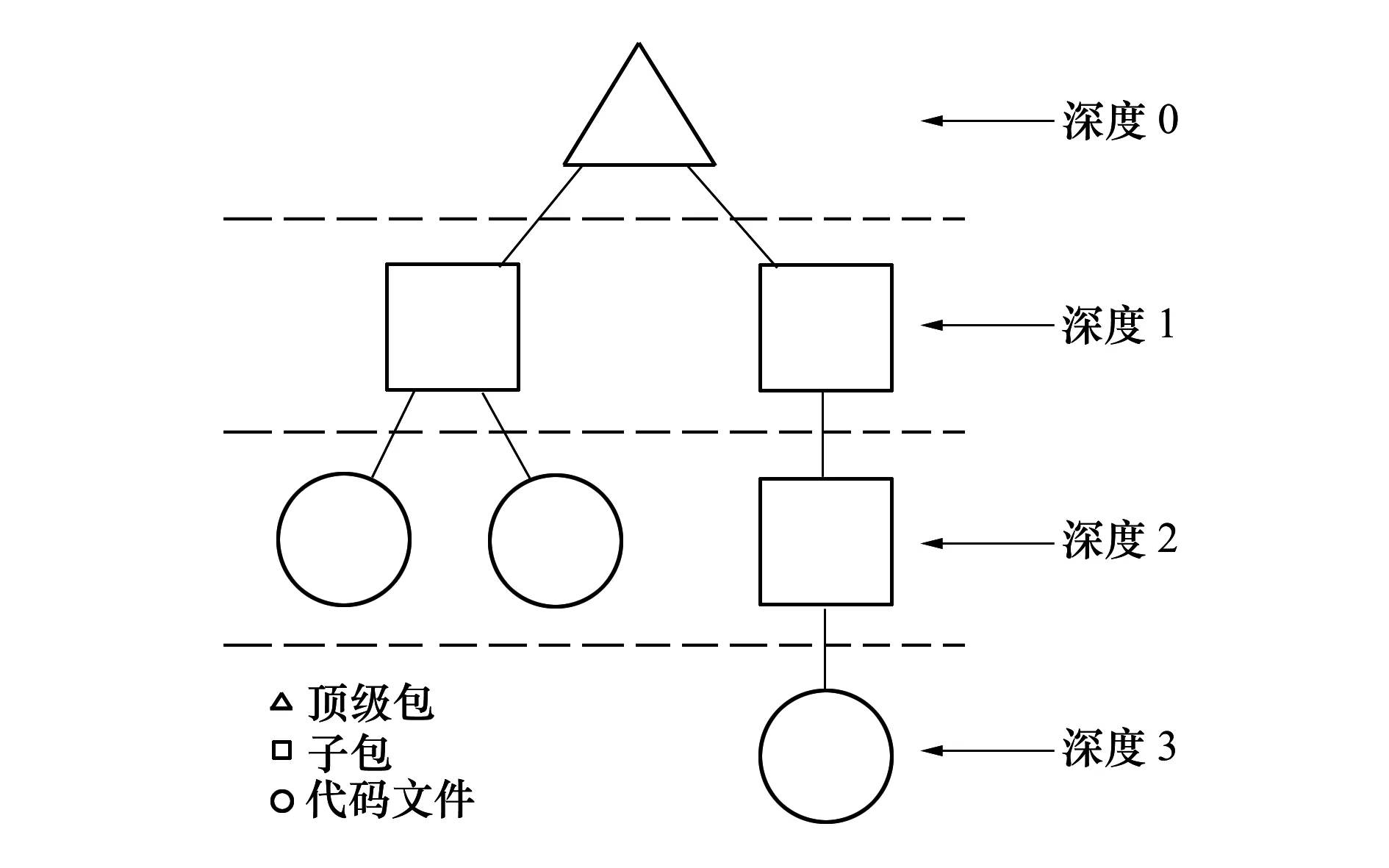
图3 代码包结构示例
公用库的目的是被应用程序调用,为确保稳定性,连续版本之间的包结构不会出现大量变化。同时,正常情况下,不同作者公用库之间的包结构不会出现高度相似的情况。基于上述分析,在代码包比较过程中,可计算比较对象之间的包结构相似度,以粗粒度剔除包结构相似度不高的情况。
2个代码包Pa,Pb的包结构相似度范围为[0,1],定义为
Psim(Pa,Pb)=
(1)
式中:PsimP(Pa,Pb)为包目录分布相似度;PsimF(Pa,Pb)为代码文件分布相似度。α与β调整2类分布相似度权重,范围为[0,1],且α+β=1。
包目录分布相似度使用代码包内所有目录的分布情况,计算2个比较对象同一深度级别的目录数量差值与总和比值,获得该深度级别的相似度。通过累加各个深度的相似度,获得最终的包目录分布相似度,定义为

(2)
式中:DP为2个比较对象中目录深度级别的较大值;Mai与Mbi分别为2个比较对象该深度级别的目录数量。
与包目录分布相似度相似,代码文件分布相似度为2个比较对象同一深度级别smali文件的数量差值与总和比值,定义为
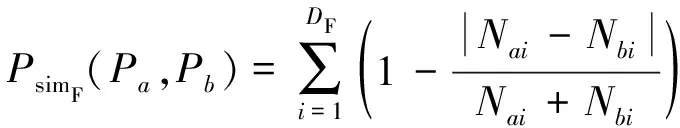
(3)
DF为2个比较对象中代码文件深度级别的较大值。Nai与Nbi为2个比较对象该深度级别的代码文件数量。
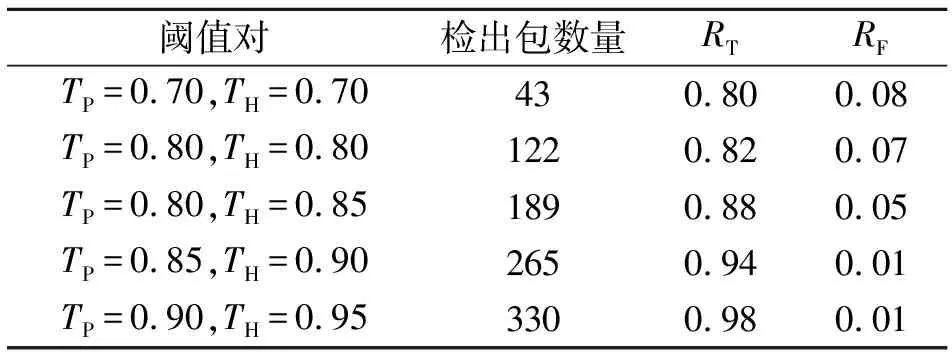
建立阈值TP(范围为[0,1]),过滤包结构相似度不高(Psim((Pa,Pb) 该步骤面向smali代码文件级相似度计算,用于细粒度的精确文件匹配,主要包括代码文件特征计算及代码包相似度计算。前者基于smali文件代码生成文件特征,后者在此基础上进行结构相似度计算,最终生成2个比较对象的相似度结果。 考虑代码文件相似度计算与文档去重操作的同质性,本文使用Simhash算法[11]、结合Android代码结构生成代码文件特征。具体的生成规则如下: 1) 读取smali文件,统计选定的32个Android API调用次数作为权重; 2) 分别生成所有API的64位哈希值,转换为二进制位串; 3) 哈希值所有位串计算:若该位为0,则转换为权重负值,若为1则为权重正值; 4) 按位累加所有32个位串的计算结果; 5) 按位转换上一步计算结果:若该位为负值,转换为0,正值转为1。 完成上述特征计算操作后,本文获得了代码包内所有smali文件的64位二进制特征码。 代码包相似度计算过程以树状包目录分布为基础,递归计算各个深度级别的包目录相似度与代码文件相似度。本文使用简化的SimRank[12]计算过程。各级深度的包目录相似度定义为 (4) 式中:C为阻尼系数;Spa与Spb为2个比较对象的同一级别子包(目录);k为当前深度级别,范围为0至2个比较对象包的最大深度;Oa与Ob分别为与当前子包有父子关系的下级子包及下级代码文件总数,若Oa和Ob为0,Fsimk(Spa,Spb)为0;Vai与Vbi需同时为下级子包(Spai,Spbj)或下级代码文件(Fai,Fbi),即Fsimk+1(Spai,Fbj)=0,Fsimk+1(Fai,Spbj)=0。 同时,下级代码文件对的相似度为 Fsimk+1(Fai,Fbj)=HAM(Fai,Fbj) (5) 式中,HAM(Fai,Fbj)表示hamming距离,即文件对的相似度为64位二进制特征码的汉明距离。 各级子包相似度递归计算,最终2个比较对象(顶级代码目录)之间的相似度为 Fsim(Pa,Pb)=Fsim0(Spa,Spb) (6) 最后,本文使用代码结构相似度Fsim(Pa,Pb)与经过粗粒度筛选的数据库中公用库包比较。设置2个阈值TH及TL,范围均为[0,1]。分类规则如下: 1)Fsim(Pa,Pb)大于等于TH的比较对象对加入备选列表:若列表内无元素,直接执行下一步;只有一个元素,直接分类为对应的公用库;若列表元素数量大于1,分类为Fsim(Pa,Pb)最大的公用库; 2) 若Fsim(Pa,Pb)大于等于TL的数量大于等于1,认为该包有较大可能为其他公用库包的更新版或修改版,记录信息后新建存储为公用库包; 3) 若上述条件均不满足,标记为临时公用库包,参与后续分类比较。经额定周期,如依然没有高度相似包,则删除该包,否则升级为公用库包。 实验分为两部分:小规模验证评估本文提出检测方法的相关性能;大规模测试分析市场中应用程序使用公用库的现实情况及大量级检测样本下的性能(速度指标)。实验运行环境为一台联想ThinkServer服务器(Intel Xeon E3、64 GB内存、1 TB硬盘)。对应该实验设置,实验数据集分为2组。 小规模验证使用人工下载的数据集,共包含200个APK安装包。经过人工挑选与验证,共出现368次公用库包使用,包含332个SHA1哈希计算结果不同的包,共出现44个不同包名。 使用自己开发的分布式应用抓取器搜索并下载大规模测试数据集。数据集抓取时间为2016年3月至4月,来源为国内5个主流应用市场,共抓取存储105 985个APK安装包,占用392 GB存储空间。所有安装包均经过解压验证,剔除了非正常APK安装包和较复杂的应用(例如微信)。需要指出的是,考虑游戏应用程序普遍体积较大的情况,本文的数据集中没有包含游戏,均为普通应用程序。 本文使用检出率(true positive rate,TPR)与误报率(false positive rate,FPR)作为评价所提出方法的指标。表1定义参与2个评价指标计算的参数。需要指出,具有同一包名但存在代码差异的代码包无法定性分类,所以仍然依赖包名进行人工分类。 表1 评价参数定义 检出率定义为 (7) 误报率定义为 (8) 使用小规模验证数据集,设置固定参数包括:α,β,C,TL使用5对阈值(TP和TH)进行实验。 表2 不同阈值对下的检测结果 实验结果如表2所示。随着2项阈值的提高,检出包的数量也不断增加。TP=0.70且TH=0.70时检出包基本匹配包名数量(44),但有1个包可能与其他包混淆,未能检出。同时,TP=0.90且TH=0.95时,检出包数量接近非哈希相同包数量(332)。在阈值较低时,RT和RF均不理想。随着阈值提高,2项数据逐渐提高。 不合理的高阈值提高了检测性能,但会导致过度分类,修改较小、主观上可以归为一类的代码包(例如小版本升级)实际运行中会分成2类,造成空间(特征存储)和时间(后续包分类)开销增大,不适合在大规模样本环境中使用。此外,实验结果与样本集有较强关联。 一个APK文件的检测平均耗时如表3所示。预处理与弱关联子包提取操作耗时较长,但对数据集规模不敏感。包结构相似度计算只统计比较目录与文件分布结构,速度较快,且在大规模数据集处理中速度下降幅度不大。详细分析代码结构相似度计算过程,发现耗时主要发生在特征计算部分,相似度计算耗时较短且没有随数据集规模增大而严重下降,证明该方法具有较好的可伸缩性。最后的公用库分类操作较简单,耗时基本可以忽略。 表3 检测过程平均耗时 s 最后,本文统计了大规模测试中排名前十的公用库出现次数,如图4所示。可以看出,在实验数据集中,除了部分工具库,大部分还是广告平台。 图4 公用库统计次数 实验结果证明,本文提出的检测方法能保证公用库的检出率与误报率,具有较高的检测速度与可伸缩性,适合在大规模数据环境中应用。但实验也说明该方法在部分计算过程中存在效率问题,需要进行优化(例如使用并行计算提高特征计算速度)。 本文提出了一种基于结构相似性的Android公用代码库检测方法,整合应用安装包结构比较与代码文件特征计算,实现不同粒度的代码分析与定位。实验结果显示,该方法可快速、有效定位并分类现实应用程序中的公用代码库。 考虑该方法与重打包检测的原理通用性,下一步的主要工作是优化该方法,适配大规模应用市场中的重打包应用程序检测与家族化分类。2.4 代码结构相似度计算
2.5 公用库分类
3 实验与结果
3.1 实验设置与数据集
3.2 评价指标

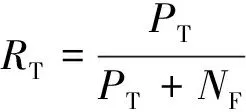

3.3 结果分析


4 结 论
