改进的VGG-16卷积神经网络算法在丁腈橡胶片材识别中的应用
2021-05-18李云红谢蓉蓉
何 琛,李云红,谢蓉蓉
(西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
制备某些固体火箭内绝热层时,首先将丁腈橡胶原料混合并碾压,然后通过剪裁等工艺,形成特定规格的片材。传统的视觉识别常采用纹理、形状、颜色[1]、局部二值模式[2]、方向梯度直方图[3]等作为特征分析,进而应用到目标识别。但在特征设计上步骤繁琐,往往需要结合多种特征,以增强识别准确率。当现场环境稍微改变时,如光射强度突然改变、摄像机角度稍微移位等,识别效果不佳。
随着视觉技术与深度学习算法相结合[4-7],设计者只需将采集的图像和类别标签输入深度卷积神经网络,网络经过训练,便可得到图像的特征规律,该规律可用于今后的类别辨识。2014年VGG-16卷积神经网络[8]在ILSVRC比赛[9]中取得了骄人的成绩,从此广泛应用于视觉任务。王羽徽等通过减少卷积核数量、加入批归一化等方法,提高了训练速度和准确率,改进了VGG网络[10]。岳有军等通过向VGG加入批归一化、全局平均池化等,提高了准确率[11]。张建华等通过优化全连接层数、改变分类器标签数量等,优化了VGG网络[12]。上述改进的VGG网络,可概括为通过调参、优化结构完成了识别任务。本文在使用VGG网络识别丁腈橡胶片时,遇到的问题如过拟合[13]、参数量大、准确率不高,在上述文献中并没有给出一个全面的处理方案,且本文的数据集也有所不同,需要具体问题具体解决。因此考虑重建网络结构更适合问题的解决。在控制过拟合方面,SRIVASTAVA等提出随机失活,它主要削弱神经元节点间的连接,从而降低过拟合风险[14]。在降低参数量方面,缩减特征图大小和压缩网络结构都是可行的办法,BOUREAU等给出了关于最大池化和均值池化的具体理论分析,说明了池化的各种特性,其中就包含降低参数量[15]。YU等提出混合池化,不仅巧妙利用池化缩减特征图大小进而降低参数,而且有防过拟合作用[16]。HOWARD等提出分组卷积结构,使参数量降低了一个数量级[17],但训练过程存在特征退化现象。IANDOLA等人提出多分辨率分组卷积结构,分组后使用不同大小的卷积核压缩网络参数[18]。提高识别准确率方面,归一化有一定影响,BA等提出层归一化(layer normalization,LN),主要是抛弃对批量的依赖,让每个样本数据在所有通道中进行归一化[19]。HUANG等提出实例归一化(instance normalization,IN)主要将网络同一卷积层中的每个通道拿出来做归一化[20]。LUO等提出SN归一化,将批归一化(batch normalization,BN),IN,LN相结合,让网络去学习归一化层应该使用那种算法,效果最好[21],此方法可有效提高准确率,但计算量有所增加。针对VGG-16和仅缩减深度的VGG-16识别橡胶片材时,效果不佳。本文在缩减网络深度的基础上,向网络嵌入多分辨率分组卷积、混合池化、SN归一化算法,重新制定了网络层级,改变了VGG-16原有结构。
1 VGG-16网络结构和数据集
1.1 VGG-16网络结构
VGG-16网络结构的优点是网络层数深、卷积层多、结构规整,是后续很多网络设计的基石。但输入的特征图每经过一个池化层,通道数会增加一倍,使得网络参数加大。其结构如图1所示。
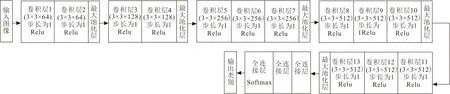
图1 VGG-16卷积神经网络结构Fig.1 Structure of VGG-16 convolutional neural network
该网络由卷积层、池化层、全连接层堆叠而成。卷积核步长都为1,大小都为3×3,最大池化的窗口都为2×2,步长都为1。第1、2卷积层由64个卷积核组成,第3、4卷积层由128个卷积核组成,第5、6、7卷积层由256个卷积核组成,第8、9、10、11、12、13卷积层由512个卷积核组成,最后是3个全连接层。
1.2 数据集
本文收集了500张位置各异的片材图像,包括圆形、方形、同心圆形。使用数据增广技术添加了1 035张样本,合计1 535张样本。增广技术包含图像随机旋转、水平方向上平移、垂直方向上平移、随机错切变换、图像水平翻转。由于片材样本未经允许不得公开,所以本文使用相似图像示意,如图2所示。

图2 相似的数据集
2 改进的网络
2.1 改进网络的结构
本文在训练和验证过程中,通过增加相同层级或者减少相同层级,搭配不同结构和参数,依据运行结果,如准确率升高或降低、参数量增加或减少、训练速度加快或减缓和网络是否稳定为判断,设置了如图3所示的网络结构。
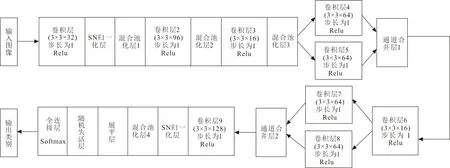
图3 改进的网络结构Fig.3 Improved network structure
网络包含:卷积层1(用C1表示)、卷积层2(用C2表示)、卷积层3(用C3表示)、卷积层4(用C4表示)、卷积层5(用C5表示)、卷积层6(用C6表示)、卷积层7(用C7表示)、卷积层8(用C8表示)、卷积层9(用C9表示)、2个SN归一化层、混合池化层1(用S1表示)、混合池化层2(用S2表示)、混合池化层3(用S3表示)、混合池化层4(用S4表示)、展平层(用F1表示)、随机失活层(用D1表示)、全连接层、第1个通道合并层(用M1表示),第2个合并层(用M2表示)。
相比VGG-16结构,网络缩减了4个卷积层,使用了2组并行结构的多分辨率分组卷积。删除了2个参数最多的全连接层。使用混合池化取代了最大池化。向网络添加了SN归一化层。改进的网络在实验时,已表现出了预期的效果。以改进后的网络结构为模板,分别向网络单独添加或减少一个卷积层、混合池化层、SN归一化层,用于观察网络性能的变化。迭代50次的同等条件下,当增加一个相同层时,卷积层会使网络出现过拟合拐点,混合池化层会使网络参数量下降且验证准确率下降,SN归一化层会使网络准确率无变化;当减少一个相同层时,卷积层会使网络的训练和验证准确率同时降低,混合池化层会使网络参数量上升且训练速度有迟缓迹象,SN归一化层会使网络出现小震荡。可以看出,当目前的网络结构发生改变时,准确率、训练速度、稳定性皆有所改变,网络的性能有下降趋势。可认为改进的网络结构是最优组合之一。
2.2 改进网络的参数
当输入RGB片材图像时,C1层由32个步长为1的3×3卷积核对其卷积;S1、S2、S3和S4以步长为1的2×2窗口对其混合池化;C2由96个步长为1的3×3卷积核组成;C3由16个步长为1的1×1的卷积组成;C4由64个步长为1的1×1的卷积组成;C5由64个步长为1的3×3的卷积组成;M1和M2分别将上一层的2个64通道合并为一个128通道;C6、C7、C8的参数分别与C3、C4、C5相同;C9由128个步长为1的1×1的卷积组成;F1层将三维数据展平至二维;D1层50%的连接被随机切断;全连接层在Softmax的处理下输出3种类别标签。卷积层的激活函数都为Relu,采用的优化器为带动量的SGD,动量大小为0.9,学习率为0.01。相比VGG-16的参数设计,本文将部分卷积核大小改为了1×1,调参后各层卷积核数量也有所改变。C2层在参数设置方面稍有不同,卷积核数量没有遵循常规的32或者64,而是直接增加到了96,原因是使用该参数时,网络整体效果最佳。当卷积核数量为64时,网络稍有不稳定,有两处震荡。C3~C8的参数设定,仿照了fire结构的参数设计,C9设置的原因是M2合并了多分辨率分组卷积的特征,使用C9承接M2的128个输出,再以步长为1的1×1卷积核进行卷积,不会遗漏太多特征图信息。
2.3 SN归一化
片材的特征图,经过卷积层的先乘再加运算,像素值在空间上改变了原始分布。如果不逼近独立分布,识别准确率会有所影响,反之提高。归一化算法可调整卷积后的数据分布,常见的归一化算法有:BN及其变种LN、IN。3种归一化方法的出发点,都是以不同的方式调整数据的空间分布,各有利弊,具体选择上主要根据运算后的数据分布。SN归一化利用该算法中的自变量k,逐一对BN、LN、IN算法进行比较,挑选对片材识别准确率贡献最大的算法,作为网络的归一化算法。算法的数学表达式为
(1)
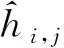
2.4 混合池化策略
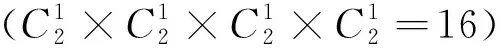
(2)
式中:ye,f为混合池化后的输出特征图;Re,f为池化区域;e,f为输出像素点的位置坐标;am,n为输入的片材特征图;m,n为输入像素点的位置坐标;参数λ取0时网络选用平均池化,取1时网络选用最大池化。
2.5 多分辨率分组卷积降参
卷积神经网络关注参数量大小,降低参数量可提升训练速度。本文已经删除VGG-16参数量占比最大的2个全连接层,因此参数主要来自卷积层。卷积层参数计算可表示为
p=c0(kwkhci+b)
(3)
式中:p代表卷积层参数量;c0为输出通道数;kw为卷积核宽;kh为卷积核高;ci为输入通道数;b为偏移量。本文的多分辨率分组卷积结构,选择添加在网络相对靠后的C3层到M2层。因为随着卷积核数量的增加,越靠后的卷积层,c0和ci越大,当这两个值都比较大时,多分辨率分组卷积可以实现不改变前后通道数的情况下,很大比例的压缩参数。假如不考虑偏移量,网络的这部分使用2个VGG-16的3×3的卷积,参数量为96×3×3×128×2=221 184,使用2组多分辨率分组卷积的参数量为(1×1×96×16+1×1×16×64+3×3×16×64)×2=23 552,参数压缩比约为1/10。
3 实验分析
3.1 训练过程对比
实验的硬件平台为Inter(R) Core(TM) i5-7300HQ处理器 2.5 GHz、DDR4 8 GB、Nvidia GeForce GTX1050Ti显卡4 GB。实验软件环境为Ubuntu18.04系统、Python3.7环境、Keras2.0深度学习框架、TensorFlow1.14。网络构建应用的是Keras提供的API方法。收集的1 535个片材样本,以6∶2∶2划分为训练集(921个)、验证集(307个)、测试集(307个)。
图4为训练和验证时的准确率曲线和损失函数曲线,图4(a)、(b)对应VGG-16,图4(c)、(d)对应删除VGG-16最后4个卷积层与2个全连接层的网络(用VGG-10表示),图4(e)、(f)对应改进后的网络。
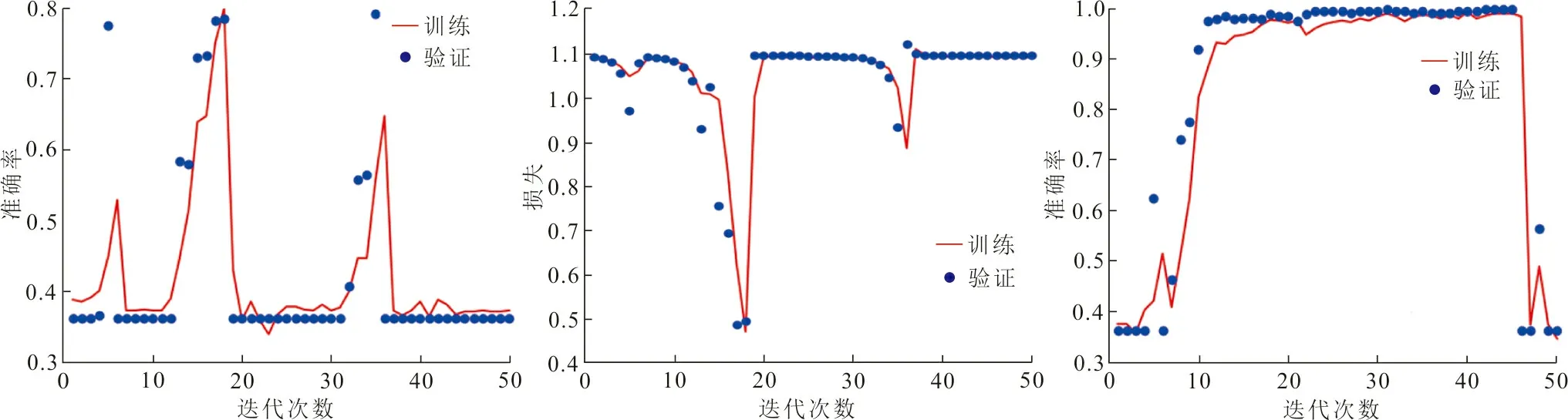
(a)VGG-16训练和验证准确率 (b) VGG-16训练和验证损失 (c)VGG-10训练和验证准确率
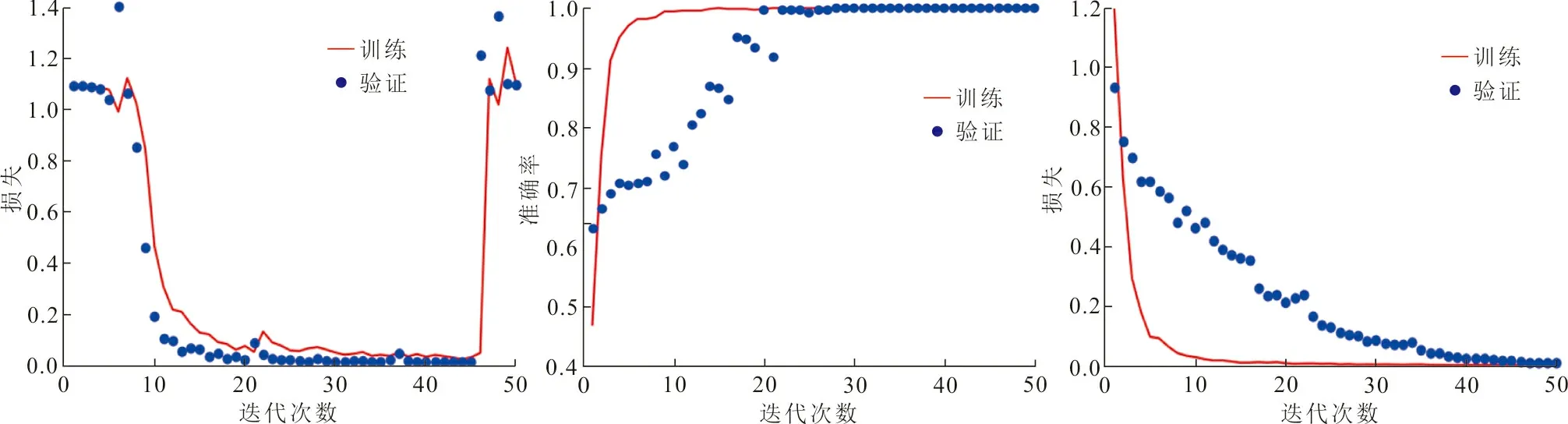
(d)VGG-10训练和验证损失 (e)改进网络的训练和验证准确率 (f)改进网络的训练和验证损失图 4 不同网络下片材训练和验证的准确率和损失曲线Fig.4 Accuracy and loss curves of sheet training and verification under different networks
图4中,3个网络都迭代50次,VGG-16与VGG-10的准确率和损失分别在18次、46次出现最大拐点,即开始过拟合。拐点的准确率分别为78.26%、99.65%。可以看出缩减网络深度后,VGG-10相比VGG-16的准确率有所提高,但依旧存在过拟合的情形。改进后的网络并未过拟合,30次后趋于稳定,训练和验证的准确率保持增长直至100%,中途的波动是由于学习率造成,属于正常现象,训练过程中,验证损失一直跟随训练损失下降,表明反向传播持续更新参数,网络有持续训练能力。
3.2 参数量、训练时间对比
VGG-16、VGG-10、改进网络的参数量、训练时间对比如表1所示。
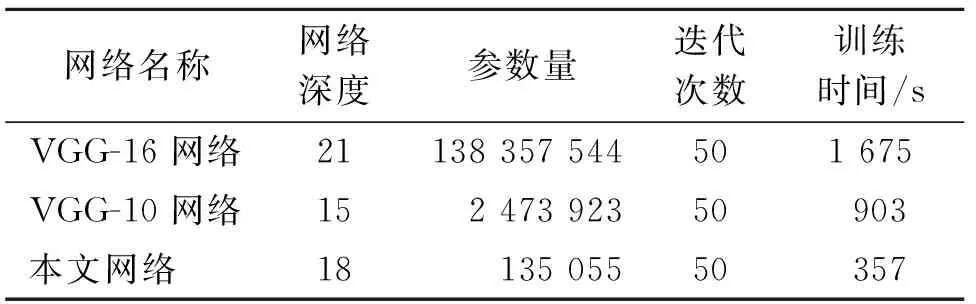
表1 参数、训练时间对比Tab.1 Comparison of parameters and training time
从表1可知,改进的网络深度(层数)共18层,介于VGG-16和VGG-10之间,其中并行结构的C4、C5,C7、C8卷积层在同一层级上,算作2层。本文改进的网络参数量最少,约相当于VGG-16的0.098%。迭代50次的同等条件下,因为参数量最少,所以训练时间最短。
3.3 测试集测试
加载网络训练得到的权重,在测试集测试时,由于VGG-16的训练和验证准确率不高,泛化能力必定不强,所以并没有使用权重测试。而VGG-10的测试准确率为92.83%,训练得到的权重,在测试集测试时,比训练和验证时的准确率有所降低。为了查看VGG-10具体哪些类别被识别错误,使用了混淆矩阵,如图5(a)所示,图5(b)为改进网络的混淆矩阵。
图5中,纵轴为测试集样本的真实类别标签,横轴为网络预测的标签,第a行第b列的数值表示第a类片材图像被识别为第b类的数量。参与测试的总样本有307个,其中标签为0、1、2(分别代表圆、方、同心圆)的样本分别为93、111、103个。从图5(a)可以看出,3个类别均有相互识别错误,其中圆和同心圆相互识别错误最多,说明VGG-10网络的泛化能力还不强。从图5(b)可以看出,数值都集中在对角线上,表明改进的网络没有识别错误,泛化能力更好。
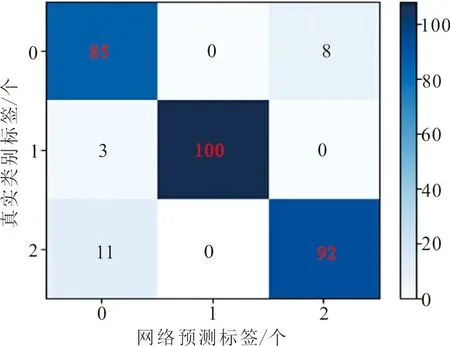
(a) VGG-10的混淆矩阵
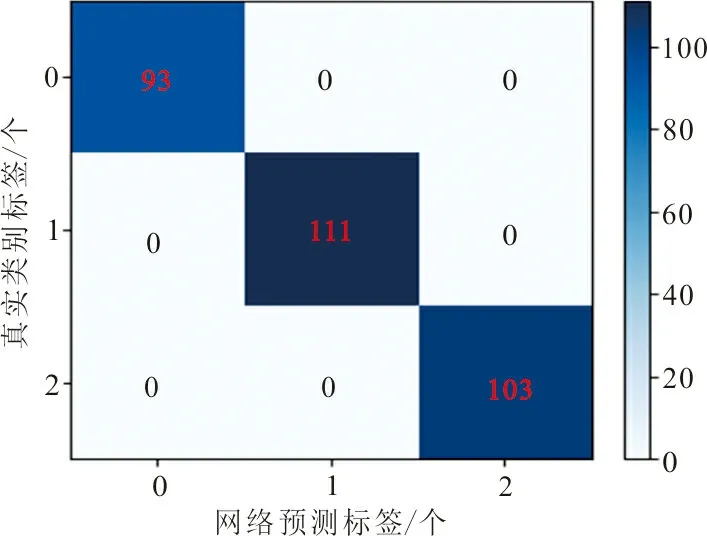
(b) 改进网络的混淆矩阵图 5 不同网络下片材的混淆矩阵Fig.5 Confusion matrix of sheet materialunder different networks
4 结 语
从实验结果来看,本文的小样本数据集不适用于VGG-16的大容量网络,准确率没有达到预期前,容易过拟合。不增加样本数量的情况下,缩减网络深度可降低一定风险的过拟合,准确率有所提高,但网络稳定性依然不佳。向网络添加算法,如SN归一化、混合池化、多分辨率分组卷积,可降低过拟合风险和网络参数,提高识别准确率。通过加载训练获得的权重,在测试集中全部识别正确,证实改进的网络更适合橡胶片材识别,该权重可替代人工特征,可免去分析特征和组合多种特征以增强识别率的繁琐步骤。改进的网络仍有可优化的余地,如当前的结构和参数设计只是最优组合之一,相信经过更多的实验,仍可在确保准确率的基础上,继续降低参数量、继续提高训练速度。
