联合多尺度和注意力机制的遥感影像检测
2021-05-14张朕通单玉刚
张朕通,单玉刚,袁 杰
1.新疆大学 电气工程学院,乌鲁木齐830047
2.湖北文理学院 教育学院,湖北 襄阳441053
遥感影像检测一直是遥感图像领域的热点研究方向。遥感图像中的目标检测对于城市监控、农作物检测、环境探测都有重要意义。遥感影像有其独特的特点,使得遥感目标检测比普通的目标检测更具有挑战性,研究人员针对遥感目标的特殊性提出了许多相应的解决方案。为了解决遥感图像中信息量大,数据非线性的问题,文献[1]使用光谱、纹理、形状等特征从不同角度分析图像,并对多个特征进行线性组合,提高了检测精度。文献[2]提出一种流形学习计算遥感特征信息低维投影矩阵,通过优化最小误差重建输入特征。文献[3]提出了按块低秩分解的方法,将特征降维处理。为了解决遥感影像不同于自然图像的水平视角的问题,文献[4]提出了建立旋转不变性特征的方法。为了解决检测区域内地物突变的情况,文献[5]提出了结合MNF变换和Canny 算子方法。针对遥感影像中同类目标尺度变化大的问题,文献[6]基于相邻区域生长的最小异质性准侧,提出了一种面向对象的多尺度检测算法。文献[7]利用多尺度多方向梯度算子提取遥感图像特征,提高了提取特征的鲁棒性。
近年来,随着人工智能在计算机视觉领域的发展,出现了大量使用深度学习检测目标的相关研究成果。深度学习的检测方法一般分为单阶段和双阶段两种类型,例如文献[8]提出一种双阶段算法,借鉴滑动窗口思想,通过算法产生一系列目标候选框后再进行分类和回归。而文献[9]仅仅使用卷积神经网进行预测,直接对目标位置和所属类别进行回归。两种方法各有利弊,双阶段方法在准确率上有一定优势,单阶段方法则速度比较快。也有研究将传统的目标识别方法和深度学习方法相结合,文献[10]在深度学习的基础上使用马尔科夫随机场锐化领域像素改善检测位置信息丢失的情况,精细化检测结果。文献[11]提出了基于柯西分布的子图像随机剪切方法,将采集到的子图模型送入金字塔池化模块进行训练。文献[12]在目标检测前对数据中各类目标按大小聚类,划分出多组先验框来。深度学习虽然相较传统方法提取特征效果好,但是依然有许多不足,训练推理时间长,需要数据样本多,制约了其在实际工程项目中的应用。针对此问题,本文提出了一种联合多尺度和注意力机制的遥感影像检测算法,并采用了最新优化算法寻优,实验结果表明本文网络在提高速度的同时保证了检测精度。
1 改进网络方法
1.1 多尺度网络设计
本文的主干网络共由8 个卷积层和6 个池化层组成,使用最大池化层下采样,使用3×3 卷积提取目标相关特征,使用1×1 卷积融合通道间特征。在图像领域,目标特征在特征图中数值较大,最大池化的作用就是将领域内数值较大的显著特征保留下来,使得下采样时不会影响识别结果,去除冗余信息,避免模型过拟合。YOLOv3 中采用卷积下采样,假设输入维度为(H,W,M),步长为2不考虑偏置,卷积核大小为(K,K,N),则卷积的参数量为K×K×M×N,最大池化直接输出邻域最大值无需储存参数,卷积的计算量为K×K×H×W×M×N/4,最大池化计算量为H×W×M×3/4 远小于前者,并且最大池化不含超参数不用执行反向传播。综上最大池化能够有效保留目标特征同时降低计算量,加快模型推理速度。本文借鉴了Yolo[12]提出了轻量级目标检测网络(Yolo-3d),加入本文提出的三维注意力机制,适用要求实时性的遥感目标检测例如无人机导航及军事制导,具有一定的可行性。因为遥感影像中目标尺度差异较大并且经常存在小目标,而高层卷积特征中每个像素感受野大包含信息较多,小目标容易和背景信息融合被忽略。而低层特征图尺度大,感受野较小,能够有效捕捉到小目标的特征信息,但是低层特征中多为目标局部特征,目标整体语义信息缺少,所以将中层特征及高层特征上采样与低层特征融合,将目标局部信息和整体信息相结合,可以有效提高遥感影像中小目标物体的检测准确率。本文设计了多条检测支路,在多种尺度的特征图上检测目标,以增加网络对不同大小目标的检测性能。本文设计的网络结构如图1所示。
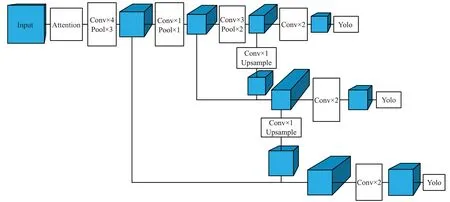
图1 本文网络(Yolo-3d)
本文使用k-means 对数据集中标注的检测框聚类来加速训练和提高准确性。综合考虑到遥感检测的实时性和准确性,本文共设置9个聚类点,得到9组不同大小比例的先验框。图中使用第17 层特征图(13×13)检测较大目标,每个特征点代表原图32×32个像素的特征信息,比较适合检测较大的目标,先验框为(134×132)(264×387)(442×407);使用第15 层特征上采样和第10层特征融合得到特征图(26×26),每个特征点代表原图16×16 个像素的特征信息,用来检测中等大小目标,先验框为(68,62)(88,82)(111,108);使用第15层和第10层融合后的特征上采样与第8 层特征再次融合的特征图(52×52),每个特征点代表8×8个像素的特征信息,用来检测小目标,先验框为(25,22)(39,35)(54,48)。综上所述,本文设计了3 个不同尺度的检测支路,并通过聚类得到9种先验框,将经过拼接和卷积的不同层特征图融合,与先验框匹配检测相应尺度的目标,改进网络能够有效应对数据集中各种尺度遥感目标分布不均的情况,提高检测准确率。每个先验框预测一个十维向量,包含边框坐标,置信度和类别概率。损失函数分为坐标误差,置信度误差和分类误差。本文为了减少训练时间,节约计算成本,使用了迁移学习技术,将预训练过的部分参数作为模型构建的起始点。
1.2 注意力机制设计
深度学习目标检测中的注意力[13]机制本质上是给不同的像素赋予不同的权重,使其能够更加关注有效信息。卷积神经网络除了学习到目标的特征外,还包含了大量无效背景信息,这就会导致在神经元中含有大量背景信息,影响检测性能。另外YOLOv3 中使用Darknet53为主干网含有53个卷积层和11个残差单元,为了保证梯度信息的反向传播,残差单元对于深层的网络是必不可少的,大量的卷积层和残差单元造成了参数量和计算量增加。而本文网络为了保证实时性网络层数较少不会出现梯度消失的现象,所以没有采用残差单元。但是较浅的网络也有弊端,卷积层数少会导致边缘特征信息不易捕捉,学习的特征表现不够好,导致池化时有效特征不够明显影响识别精度。针对这个问题,提出三维注意力机制将目标的位置、边缘等相对重要特征提取出来并赋予较高的权重,对于特征相对不明显的背景,降低其权重,达到抑制目的,从而在池化时保留住目标区域的特征,提高检测性能。
本文设计的注意力机制结构如图2所示,能够从通道、行和列三个维度上给每个像素分配合适的权重。根据模型的首层特征图,获得通道、行和列注意力权重图,然后分别将其和原特征图点乘,得到带有权重的特征图,计算公式如公式(1)所示:

其中,F为原特征图,F′为输出特征图,⊗为矩阵间元素点乘,*为卷积操作,Mc(F)为通道注意力图,Mr(F)为行注意力图,Ml(F)为列注意力图,G为卷积核。
每个注意力模块计算的是除自身外其余两个维度的特征压缩值,使用最大池化和平均池化两种池化操作得到两个不同的矩阵。其中通道维度的两个矩阵首先使用1×1 卷积降维,再进行特征融合升维,最终得到和通道长度一致的一维向量。行和列的矩阵则先使用特征拼接,再使用3×1或1×3卷积聚合特征,同样得到和自身长度一致的一维向量。通过两种池化操作显著和连续的特征被提取出来,后续的卷积操作将相关特征关联起来,最终得到3组权重值,使用sigmod激活函数将权重归一化到0~1 之间。通过神经网络训练更新注意力机制参数,最后将三个维度矩阵相加得到三维权重图,采用矩阵加和操作也可以有效降低计算量。加入注意力机制后,本文设计网络的参数量依然远少于YOLOv3网络,在速度上对比YOLOv3上有明显优势,并且在精度上几乎没有下降。其中通道注意力计算方式如公式(2)所示,行和列注意力计算方式如公式(3)所示。
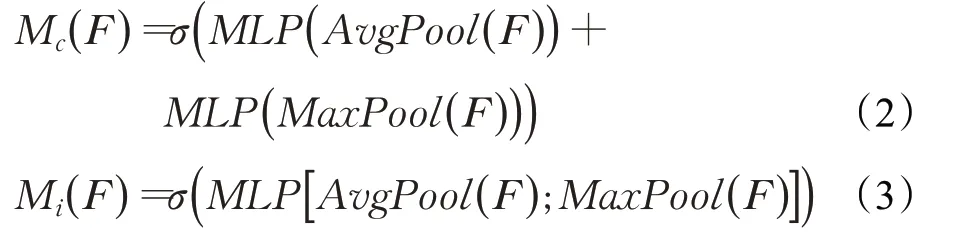
其中F是输入特征图,Mc(F)是通道注意力图,Mi(F)为行或列注意力图,MLP是多层神经网络,σ是激活函数,AvgPool是均值池化,MaxPool是最大池化。
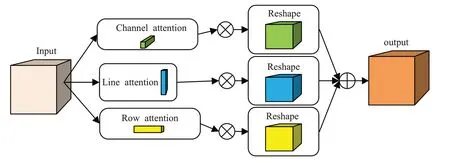
图2 三维注意力机制结构图
1.3 Lookhead优化算法
SGD 优化器因为在各个维度上梯度的缩放是一致的,导致在训练数据分布不均匀的情况下寻优效果不是很理想。而收敛速度较快的自适应优化算法,虽然在训练早期收敛较快,但是最后的表现却不如SGD优化器。为了改善自适应优化算法在训练后期学习率出现极端的情况,本文加入了Lookhead[14]优化算法。Lookhead维护了速率不同的两套权重,内部循环使用了标准优化器。Lookhead计算方法如下:


在内部优化器的快速权重经过k次更新后,Lookahead在权重空间中通过线性插值更新慢速权重,方向为内部优化器最后一次权重方向,可以有效避免模型学习率出现震荡或收敛速度慢的现象。
2 结果分析与讨论
2.1 实验配置与指标
本文使用的遥感数据集是武汉大学团队提供的RSOD-Dataset[15],包含了不同时间、角度和高度拍摄的飞机、操场、立交桥、油桶四类物体,共976张图片,5 383个实例目标,具有一定的代表性。实验环境配置为Intel®Core™i7-4720HQ处理器、8 GB内存条,Nvidia GeForce GTX 950M 显卡,操作系统为Win10,使用深度学习框架Pytorch[16]。
从数据集中随机选取592 张图片作为训练集进行训练,72张图片进行验证,72张图片进行测试。训练时一个批次包含16 张图片,Lookhead 的内部优化器动量设置为0.9。为了防止过拟合,权重衰减设置为0.000 5。采用动态学习率,初始学习率设置为0.005,随着迭代次数增加学习率逐渐降低。
本文使用了查准率(P),查全率(R),MAP@0.5,F1作为实验指标。F1 和MAP@0.5 兼顾了查准率和查全率两个指标。MAP@0.5 是每类AP 的均值,而AP 是对P-R 曲线下方积分计算出的面积。F1 是查准率和查全率的调和平均值,F1计算方式如公式(4):

训练前将所有图片缩放到416×416,共训练了400轮,迭代次数14 800次。改进模型训练的loss曲线如图3所示,可以看出loss值在200轮后值趋于稳定,最终降低到3 左右。MAP@0.5 曲线由图4 可知,MAP@0.5 同样在200 轮左右逐渐稳定,最终收敛到0.93 附近,最高可到0.945。

图3 模型loss曲线
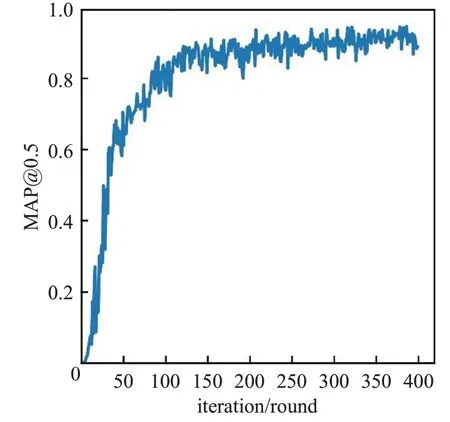
图4 模型MAP@0.5曲线
本文使用了4 种指标Yolo-tiny[17]、Yolo、Yolo-3d 进行了详细的对比。如表1所示,本文模型参数量比Yolotiny 略多,比Yolov3 参数少了一倍,但是最终的各项指标查准率达到了75.2%,查全率达到了96.1%,MAP@0.5 达到了94.5%,F1 达到了84.1%,相较于Yolo-tiny 均有较大提升,性能基本可以和Yolov3持平,在兼顾实时性的情况下保证了检测精度。从表2 可以看出Yolotiny 模型检测飞机和立交桥单类AP 表现较差,是因为飞机目标较小,并且和立交桥一样自身特征信息不明显,而Yolo-3d能够有效改善这些问题,对这两类目标的AP 能够提高3%左右。对于油罐和操场这些在原模型AP 较高的目标,因为它们本身具有独特的特征信息有利于遥感目标的检测,本文模型对于这类目标也能平均提高2%的AP。

表1 不同网络模型指标对比

表2 单个目标在测试集AP对比
2.2 分类结果对比
为了验证本文设计模型在遥感影像目标检测方面的有效性,将Yolo-3d 与Yolo-tiny 检测结果进行对比。部分检测图片对比如图5,(e)为Yolo-tiny 飞机检测结果,对比原图可以看出Yolo-tiny 只检测到了部分目标,(i)中Yolo-3d可以检测到基本所有的飞机目标,证明了本文模型对小目标检测的有效性。如图(f)、(j),因为油罐的特征易于检测,Yolo-tiny和本文模型都可以检测到目标,但是对于具体的目标位置没有改进模型预测的准确,检测框部分有偏差,同时置信度不如本文模型。如图(g)、(h),Yolo-tiny没有预测出应有的立交桥,预测操场出现了数量不符的现象,这是因为Yolo-tiny层数较浅不能很好地提取出目标的必要特征信息,所以出现了位置丢失和回归不准确的现象,而(k)、(l)可以很准确地预测出目标的位置和类别。综上所述,本文提出的Yolo-3d 能很好地识别这些遥感目标。Yolo-3d 推理时间比Yolo-tiny略长,主要是因为层数增多导致模型构建时间变长,但是依然可以满足实时性的要求,在实际工程应用中具备可行性。

图5 多目标检测实验结果
3 结论
本文提出了一种联合多尺度和注意力机制的遥感影像检测算法。采用聚类的先验框匹配多条检测支路,利用低层特征改善小目标检测准确率,能够适应多种尺度的物体。提出了三维注意力机制能够从三个维度上得到特征的自适应权重,有效地提取遥感影像中目标的语义信息。使用迁移学习技术和新的优化算法节省了训练成本,提高了模型的性能。通过实验,比较了不同模型间检测效果的差别,分析了不同模型的利弊。本文提出的算法能够对本文数据集中的4 种遥感目标实现准确识别和检测,同时兼顾实时性,满足实际工程应用中的需求。对于遥感影像目标检测的问题,随着算法的进步,有越来越多的可能应用于各种实时的遥感检测问题,如自然异常检测、城市目标检测、军事目标检测等,为人们的生活带来便利。
