目标丢失判别机制的视觉跟踪算法及应用研究
2021-05-14牟清萍张东波王新杰杨知桥
牟清萍,张 莹,2,张东波,2,王新杰,杨知桥
1.湘潭大学 自动化与电子信息学院,湖南 湘潭411105
2.机器人视觉感知与控制技术国家工程实验室,长沙410082
视觉跟踪以连续视频帧为对象,提取目标特征后,根据视频帧序列的上下文信息,利用特征构建目标外观模型,判断候选样本是否为跟踪目标。跟踪算法按照特征提取方式的不同,通常分为基于传统模型和基于深度学习模型,传统模型通常利用灰度特征、颜色特征、梯度特征以及纹理特征等[1-4]人工特征,单个特征表达单一,跟踪精度不高,融合多个特征之后虽然能够一定程度上提高算法的跟踪精度,但算法对复杂环境下目标出镜头、严重遮挡等情况跟踪效果不佳。
深度学习模型得到的卷积特征具有高层特征更抽象、底层特征更细粒的特点,对目标特征的表达更为丰富[5-6]。近几年基于深度学习模型的目标跟踪算法在OTB[8](Object Tracking Benchmark)、VOT[9](The Visual Object Tracking vot2017 challenge results)等数据集中跟踪精度领先传统模型,深度学习跟踪算法[10](Learning a deep compact image representation for visual tracking,DLT)利用深度堆栈网络获取目标特征,每间隔一定帧数或者置信度小于一定阈值时更新外观模型,但由于训练不充分算法跟踪精度较低;分层卷积特征的视觉跟踪算法[11](Hierarchical convolutional features for visual tracking,CF2)利用卷积网络得到三个对应的置信度图进行加权融合定位目标,但该算法对尺度变化严重的物体跟踪效果不好;全卷积孪生网络算法[11](Fully-convolutional siamese networks for object tracking,SiamFC)由于不在线更新外观模型,当目标出现严重变形和遮挡时就会跟踪失败;相比于其他深度学习算法,实时多域卷积神经网络算法[13](Real-Time MDNet,RT-MDNet)利用历史帧更新模型,精度高速度快,不需要进行参数微调也能达到好的跟踪效果。
在复杂场景中,基于深度学习模型的跟踪算法比基于传统模型的算法跟踪精度更高。但当跟踪对象快速运动、与镜头距离发生变化,会造成跟踪对象在视频中的尺寸改变,或者当跟踪对象被严重遮挡、离开相机视野范围时,基于深度学习模型的算法也会失去正确的目标性判断,并且由于为了适应目标不断变化的模型更新策略的存在使得算法错误更新到背景中,造成跟踪系统跟踪失败。
目标丢失后需要再次搜索并定位。YOLO[14](You Only Look Once)算法将目标分类与定位坐标作为一个回归问题处理,输入图片被分成互不重合的小单元后卷积产生特征图,预测每个小单元中出现目标的概率以及边界框的置信度,全局搜寻目标,但对异常比例目标无法定位、定位准确度低。YOLOv3[15]算法设计了全卷积网络结构和九种尺度先验边界框,提高了检测的实时性、准确性。Attention-YOLO算法[16]对网络中所有的残差连接进行替换,使得残差融合时保留的信息更加有利于训练损失的降低,有利于定位及分类的准确。集成旋转卷积的YOLOv3 算法[17]引入角度预测来实现单阶段的对倾斜边界框的目标检测,将角度惩罚引入模型的多任务损失函数中,使得模型能够学习目标的角度偏移。
为了纠正模型的错误更新,受文献[18]最大化图像和输入边界框候选区域之间的重叠度(Intersection over Union,IoU)定位目标更精确的启发,将RT-MDNet跟踪算法、YOLOv3 检测算法相结合,提出基于目标丢失判别机制的视觉跟踪算法YOLO-RTM,根据IoU设计目标丢失判别机制,当判别跟踪目标丢失时采用YOLOv3进行目标重检测,把捕获得到的目标位置作为当前帧位置,并以此更新RT-MDNet 模型参数,实现目标丢失后重检测并继续跟随的目的。该方法可以克服目标被严重遮挡、目标出镜头等目标丢失后重定位的难题,提高了跟踪算法的稳定性,并且根据YOLO-RTM 算法定位的目标位置完成移动机器人准确跟踪目标的任务。
1 YOLO-RTM算法
RT-MDNet 将一个视频看做一个域,多个视频就组成多个域,其定义外观模型f d如式(1)所示:
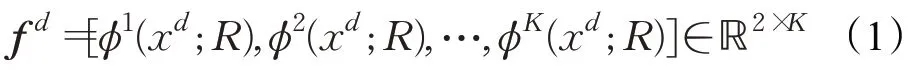
其中输入为第d域的图片xd和边界框R,K是训练数据集总数,φd函数计算第d域最后一层全连接层的前景和背景的二分类得分,得分最高的前景即为当前帧目标边界框的预测值。RT-MDNet 利用OTB 或VOT 视频数据集离线训练网络,为适应目标外观模型的变化,利用长短时更新策略在线微调外观模型,长时更新保留了特征的鲁棒性,短时更新使模型保持一定的适应性。长时更新采用固定步长10 帧更新一次训练样本,此时正样本为最近100帧跟踪成功正样本,负样本为最近20帧跟踪成功负样本,利用新样本库更新模型的最后一层全连接层;当目标得分小于0 时采用短时更新,正负样本均为最近20 帧跟踪成功样本;当目标被严重遮挡或离开相机视野范围时,目标得分往往小于0,短时更新策略使得模型更容易更新到遮挡物或者背景中去,造成算法失去对目标的准确定位,且随着时间的推移,误差累计导致模型无法再次找回目标。

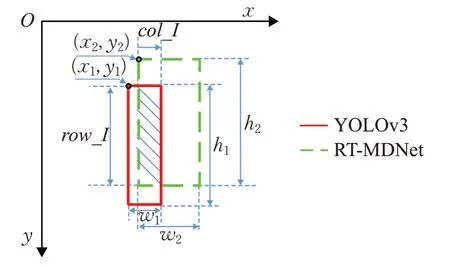
图1 IoU示意图
col_I和row_I计算如式(3)所示,目标丢失判别机制如式(4)所示:
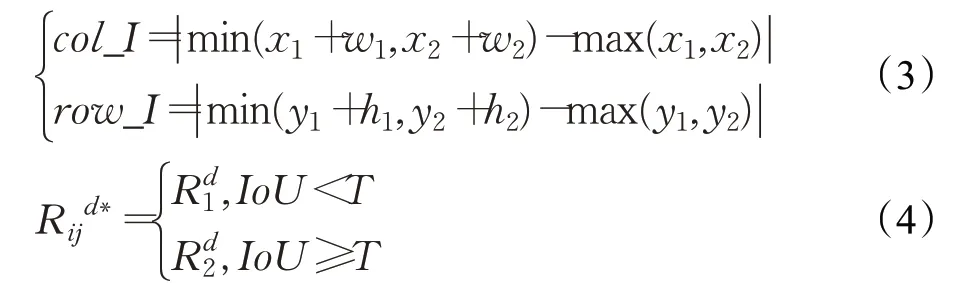
为期望目标边界框,当IoU大于阈值,则采用长短时更新方法更新目标外观模型,若IoU 低于阈值则说明目标丢失,采用检测算法检测得到的更新目标外观模型。
检测跟踪算法整体流程如图2 所示。YOLO-RTM首先采用YOLOv3[14]检测第一帧图像并初始化RTMDNet 算法,然后采用目标丢失判别机制计算IoU,IoU大于阈值T则表明RT-MDNet 算法跟踪结果可信度高,选择作为模型f d的更新输入。当IoU小于阈值T时,当前帧被判别机制判定为目标跟踪失败,为了再次找回目标,将检测器结果作为下一帧跟踪器模型f d输入。
选取10 个被遮挡、出镜头的视频进行实验,不同IoU 阈值(0.3、0.4、0.5)的中心误差图和成功率图如图3所示,图3(a)显示IoU=0.4 时,中心误差最小,即跟踪精度最高;图3(b)横坐标显示算法的预测边界框与人工标注的真实边界框的重叠度,可见IoU=0.4 之后,跟踪成功率急速衰减,当IoU=0.9 时成功率几乎为0。
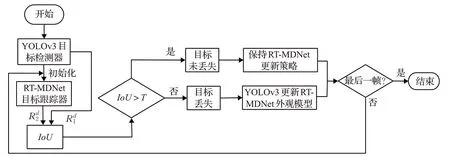
图2 YOLO-RTM跟踪算法整体流程
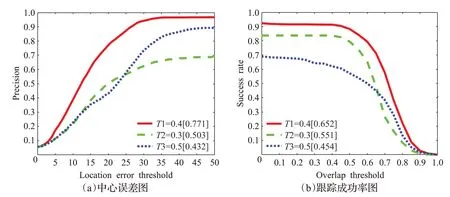
图3 YOLO-RTM算法设置不同阈值比较结果
图4 显示了RT-MDNet 与手工标注Groundtruth、YOLOv3 与Groundtruth、RT-MDNet 与YOLOv3 的三组IoU对比结果,可以看出YOLOv3与Groundtruth的边界框重合度较高,尤其是人在离开镜头之后,再重新回到镜头YOLOv3可以准确找回目标,但RT-MDNet跟踪失败。YOLO-RTM 算法跟踪目标时,YOLOv3 每间隔10帧后检测一次目标,以YOLOv3 与RT-MDNet 算法IoU比较结果判别目标是否丢失,并决定算法采用长短时或是重检测目标更新策略。

图4 不同跟踪算法的IoU参数对比
2 移动机器人跟踪控制系统
Turtlebot2移动机器人视觉跟踪系统分为视觉检测跟踪模块和机器人控制模块。移动机器人在TX2开发板Ubuntu16.04 系统下安装ROS 机器人操作系统,计算机(CPU i7 6700HQ,内存16 GB,显卡GTX1060 6 GHz)利用深度学习框架Pytorch检测跟踪目标,当Kinect-2.0摄像机到地面垂直距离80 cm(如图5 所示)时,跟踪目标恰好位于机器人视野中心。TX2 通过无线局域网与计算机之间实现通信,Kinect-2.0与TX2有线连接。图6是基于ROS(Robot Operating System)机器人视觉控制系统的整体流程图。

图5 视觉跟踪系统组成
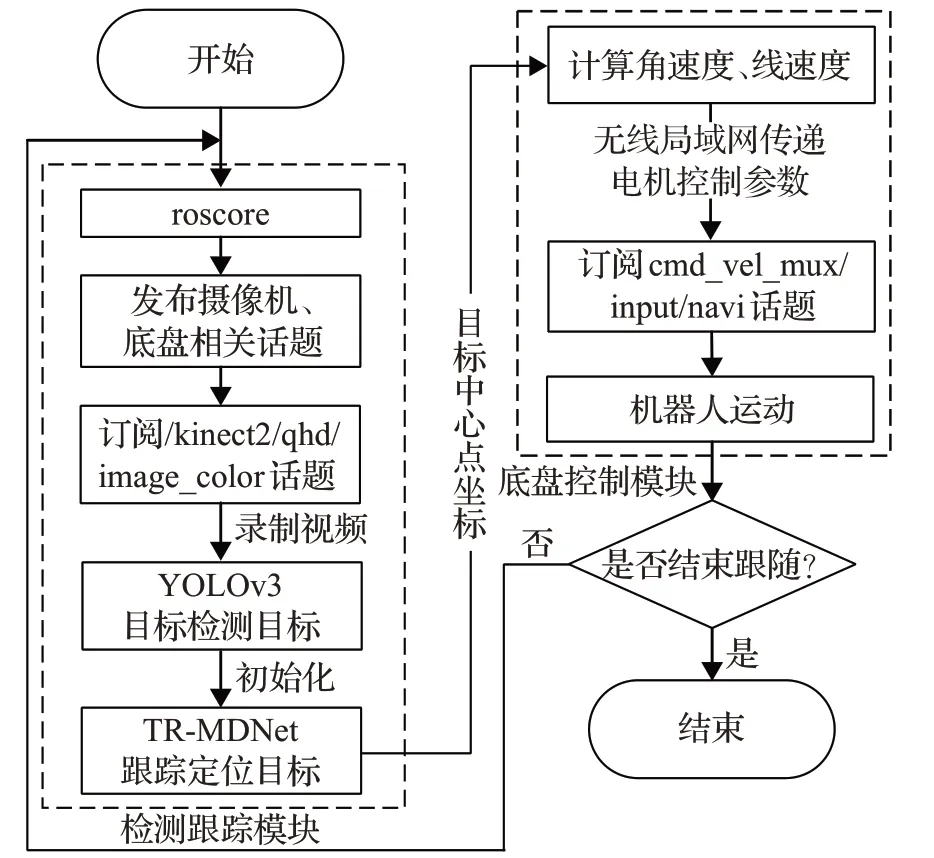
图6 ROS机器人视觉跟踪系统流程图
机器人运动过程中,期望目标一直位于视野中央(如图7 所示),假设目标初始位置在数字1,其坐标为A(xc1,yc1),参考中心坐标为B(xce,yce),第t帧中心坐标为C(xct,yct)。跟踪时机器人最大角速度和最大线速度分别为0.65 m/s和3.14 rad/s,则机器人底盘控制线速度v(t)和角速度ω(t)策略如式(5)所示[4],通过实验整定K1和K2值为:1/435和1/275。

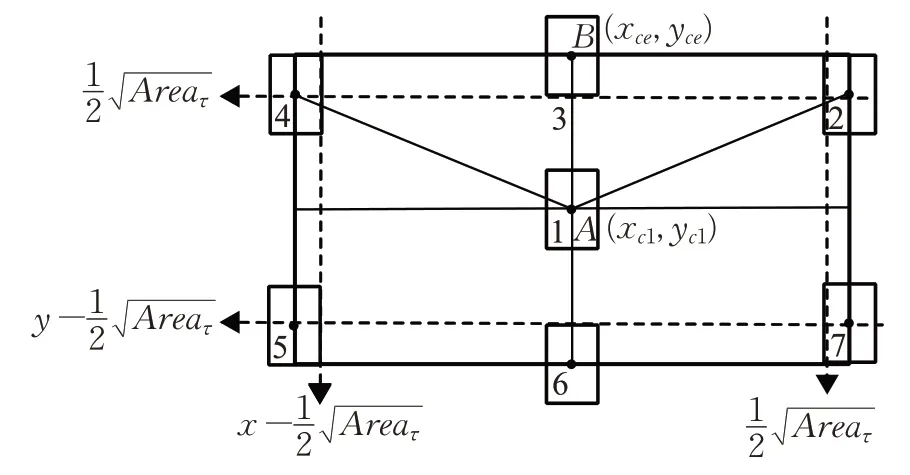
图7 机器人视野与目标在图像中的位置关系
当目标接近图像边缘时,目标边界框会逐渐变小。图7 中数字2~7 表示在机器人视野中,目标前后左右能够到达的最远位置。若目标面积有一半及以上不在图像之内则认为目标丢失,即Area<Areaτ时目标丢失[19],Areaτ为目标中心接近边缘位置的面积阈值,则虚线框以外判定为目标丢失,判定规则如式(6)所示,其中(x,y)为输入图像分辨率。
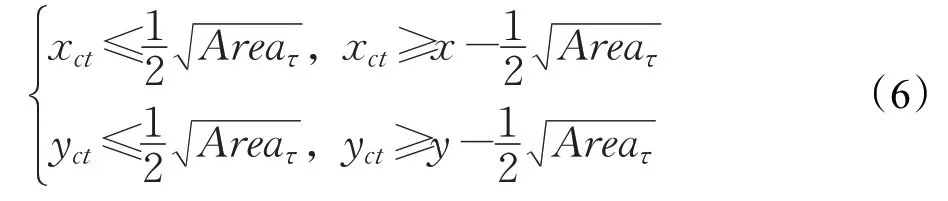
目标丢失时机器人保持丢失目标前的角速度和线速度如式(7)所示,当YOLOv3 算法再次检测到目标时,控制策略切换为式(5)。

3 实验结果及分析
3.1 算法性能测试结果及分析
RT-MDNet、YOLOv3、YOLO-RTM三种算法的模型参数、预测单帧时间比较如表1所示。由于YOLO-RTM算法利用检测算法重检测并找回目标,整个模型速度上略微减慢,模型参数也存在微小程度的增加,但算法跟踪鲁棒性能得到极大提高,尤其在目标出镜头、严重遮挡时可利用YOLOv3重检测后找回目标,对于目标跟踪的实际应用十分重要。
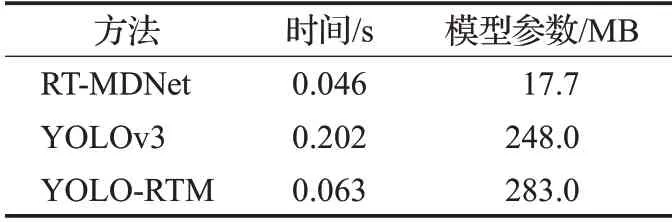
表1 三种算法模型参数、预测时间对比
本文采用OTB100 数据集和Kinect-2.0 录制的目标出镜头后再回镜头20 个视频(采用vatic 标注工具箱标注)作为训练集,另外录制10个视频作为测试集。跟踪算法测试结果的定量分析如图8所示,YOLO-RTM算法精度0.737、成功率0.631,相比其他算法较高。因此,实际应用中,利用检测算法对模型在线更新的策略,有效提高了跟踪算法的可靠性。
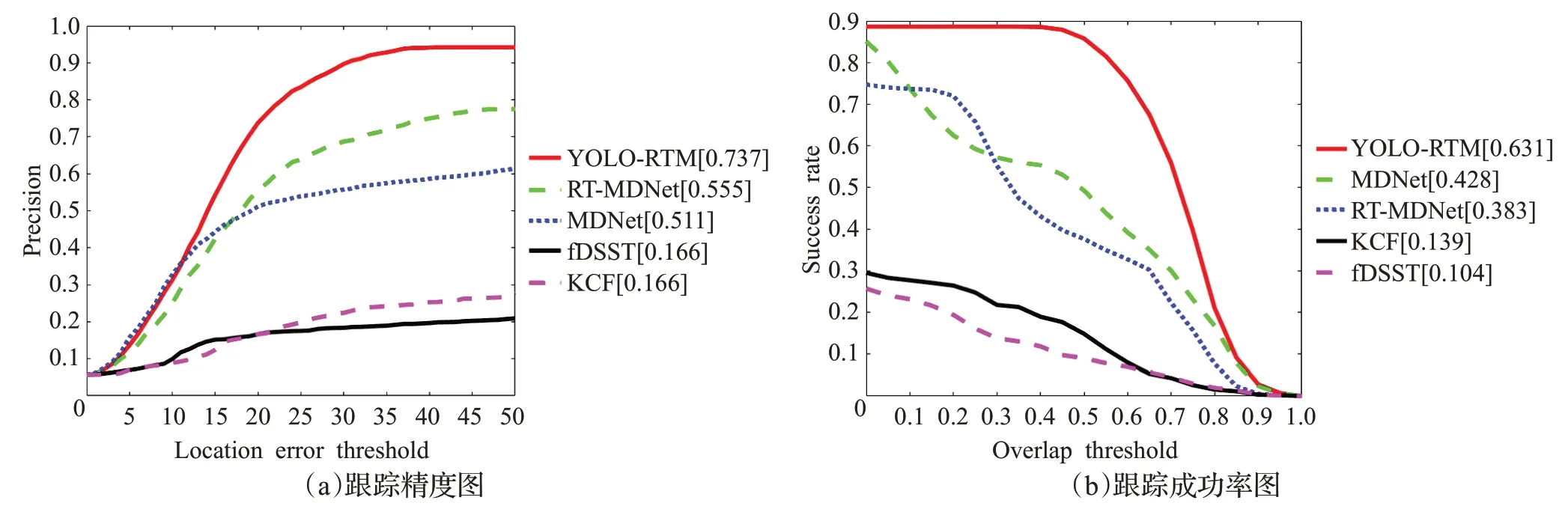
图8 YOLO-RTM算法与其他算法精度图与成功图
3.2 算法移动机器人控制测试结果及分析
为了防止机器人跟踪丢失目标的情况发生,应在目标离开视野范围之前,及时让机器人做出改变。经过多次实验得知,每隔24帧给机器人一个控制指令,机器人可以精确跟踪目标轨迹。Walker1、Walker2、Warlk3 视频内容如表2所示,表3对应跟踪算法的目标丢失情况。
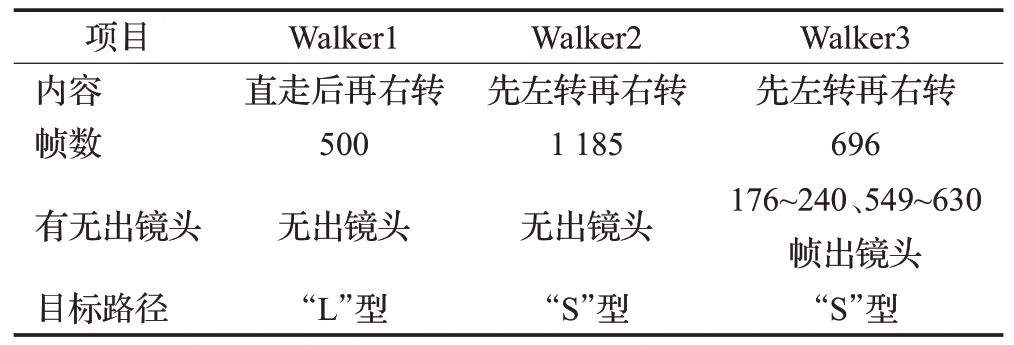
表2 机器人跟踪并录制视频情况一览表
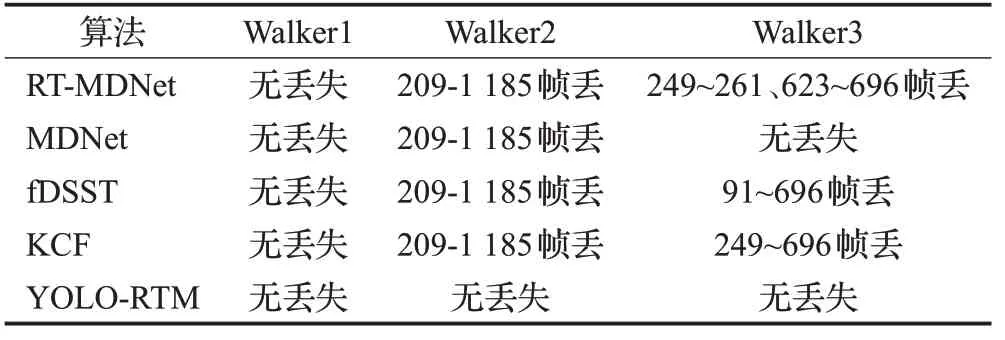
表3 视觉跟踪算法目标丢失情况表

图9 Walker1视频不同算法跟踪结果对比
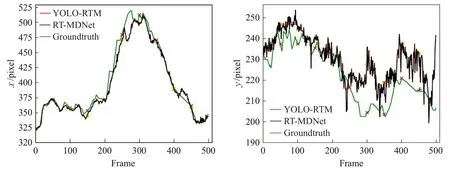
图10 Walker1视频中心点x、y 坐标运动轨迹
3.2.1 Walker1实验结果及分析
Walker1视频无出镜头,跟踪算法的结果如图9所示,可见YOLO-RTM、RT-MDNet[13]、MDNet[20]、KCF[21]、fDSST[22]都能准确跟踪目标,无丢失目标情况。图10显示RT-MDNet和YOLO-RTM 跟踪目标框的图像中心点x、y坐标的轨迹,两种算法结果与Groundtruth接近。图11是YOLOv3和RT-MDNet算法结果与Groundtruth的重叠度散点图,可知两个算法的重叠度均高于目标丢失判别机制阈值,因此YOLO-RTM 算法跟踪结果与RT-MDNet 算法的跟踪结果相同。机器人底盘跟踪的线速度v、角速度ω变化如图12所示,跟踪过程中机器人线速度基本不变,保持在0.5 m/s,当行人在210 帧开始右转,机器人角速度由0 rad/s 变为负值,表明机器人同步右转,机器人运动轨迹和行人的运动轨迹保持一致,满足跟踪要求。
3.2.2 Walker2实验结果及分析
Walker2视频不同算法跟踪结果如图13所示,除了YOLO-RTM 算法外,RT-MDNet[13]、MDNet[20]、KCF[21]、fDSST[22]在208~1 185帧都有目标丢失,不能实现准确跟踪。图14所示,YOLO-RTM算法中心点变化和Groundtruth十分接近。图15 所示RT-MDNet 重叠度低于阈值0.4,RT-MDNet 在208 帧后逐渐丢失目标,甚至在200~400帧时重叠度为0,目标完全丢失,此时YOLO-RTM 采用YOLOv3算法更新外观模型,实现准确跟踪。图16中机器人线速度保持0.5 m/s,行人210帧开始左转、420帧开始右转,机器人角速度同样在210帧、420帧发生显著变化,和视频中行人的运动情况一致,满足跟踪要求。
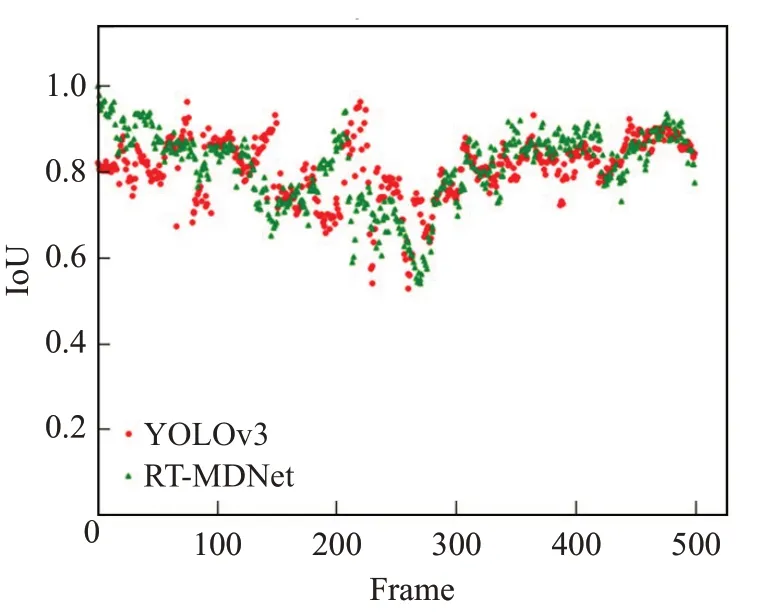
图11 YOLOv3和RT-MDNet的重叠度比较
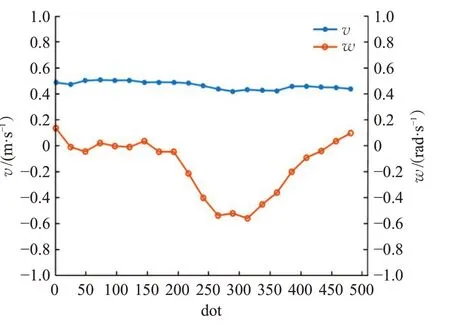
图12 机器人底盘控制结果

图13 Walker2视频不同算法跟踪结果对比
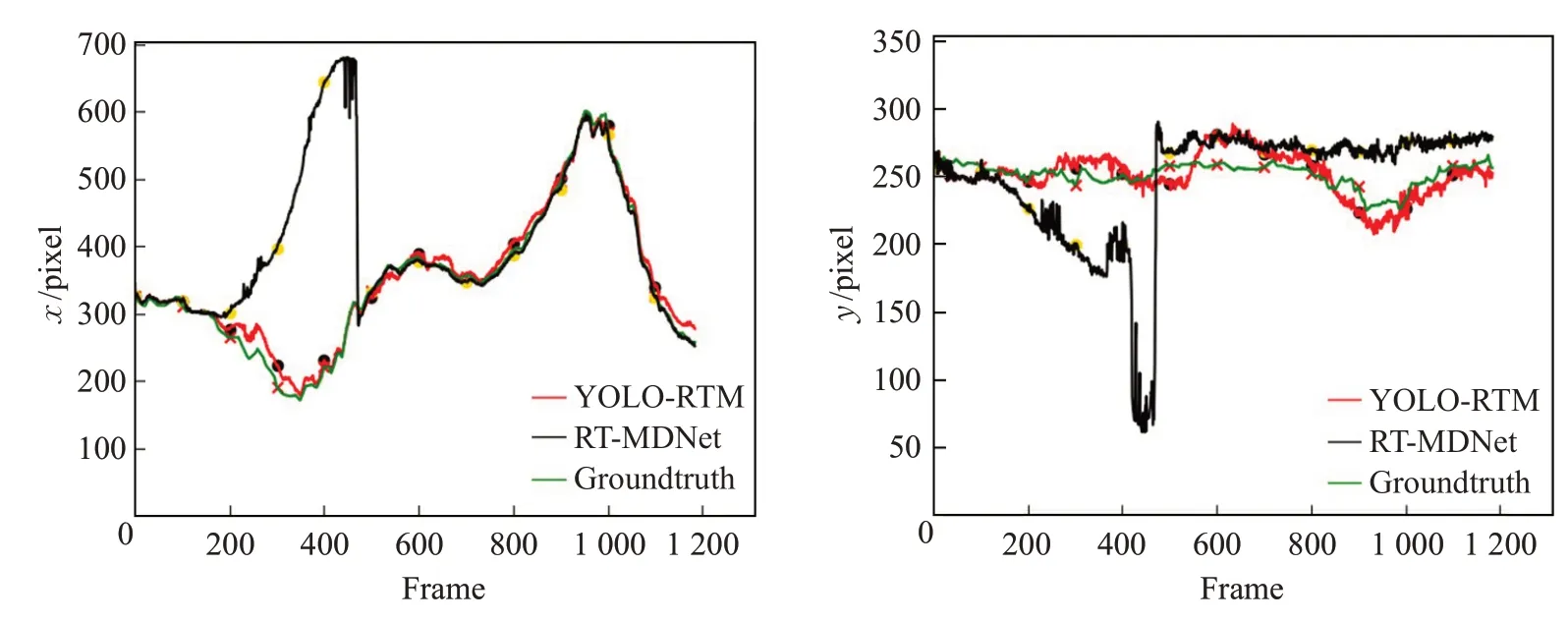
图14 Walker2视频中心点x、y 坐标运动轨迹
3.2.3 Walker3实验结果及分析
Walker3 视频176~240 帧出镜头,不同算法跟踪结果对比如图17 所示,RT-MDNet[13]、fDSST[22]和KCF[21]丢失目标后无法找回,MDNet[20]和YOLO-RTM 算法可以较为准确地跟踪,但MDNet 的跟踪速度较慢。图18 所示,YOLO-RTM 算法比RT-MDNet 中心误差小,与Groundtruth 几乎重合。YOLOv3 和RT-MDNet 重叠度比较如图19 所示,RT-MDNet 在200~680 帧时重叠度低于阈值0.4,此时YOLO-RTM采用YOLOv3更新外观模型,实现准确跟踪。如图20 所示,机器人线速度保持0.5 m/s不变,角速度变化形状是“S”型,和Walker3视频中行人的运动情况一致,满足跟踪要求。
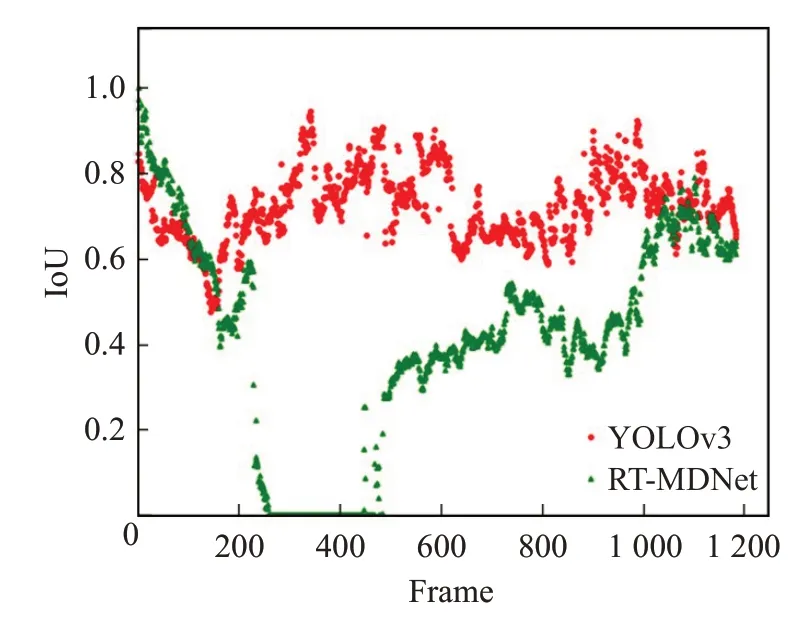
图15 YOLOv3和RT-MDNet的重叠度比较
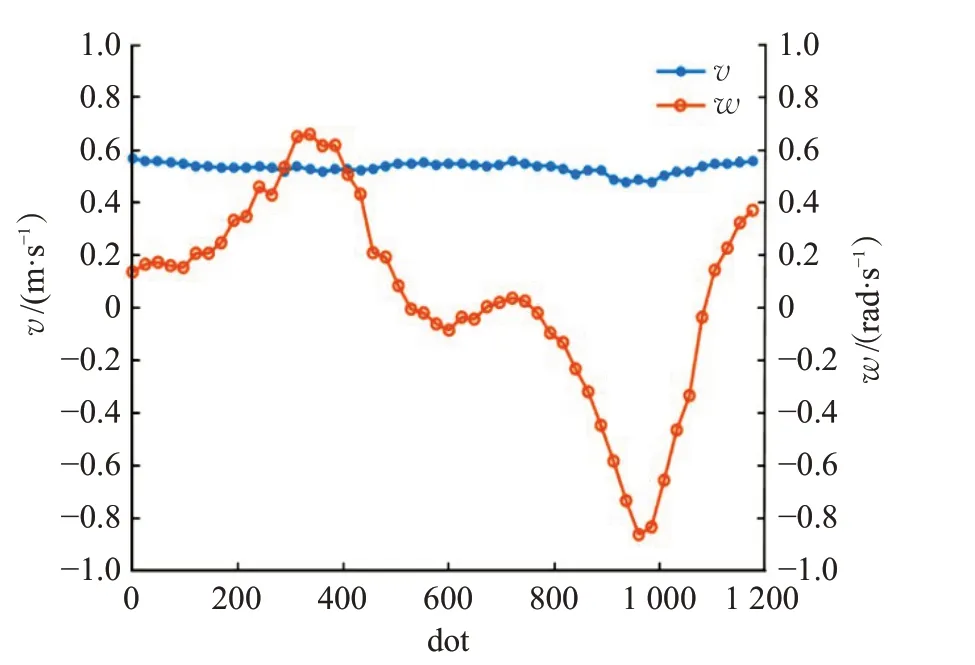
图16 机器人底盘控制结果

图17 Walker3视频不同算法跟踪结果对比
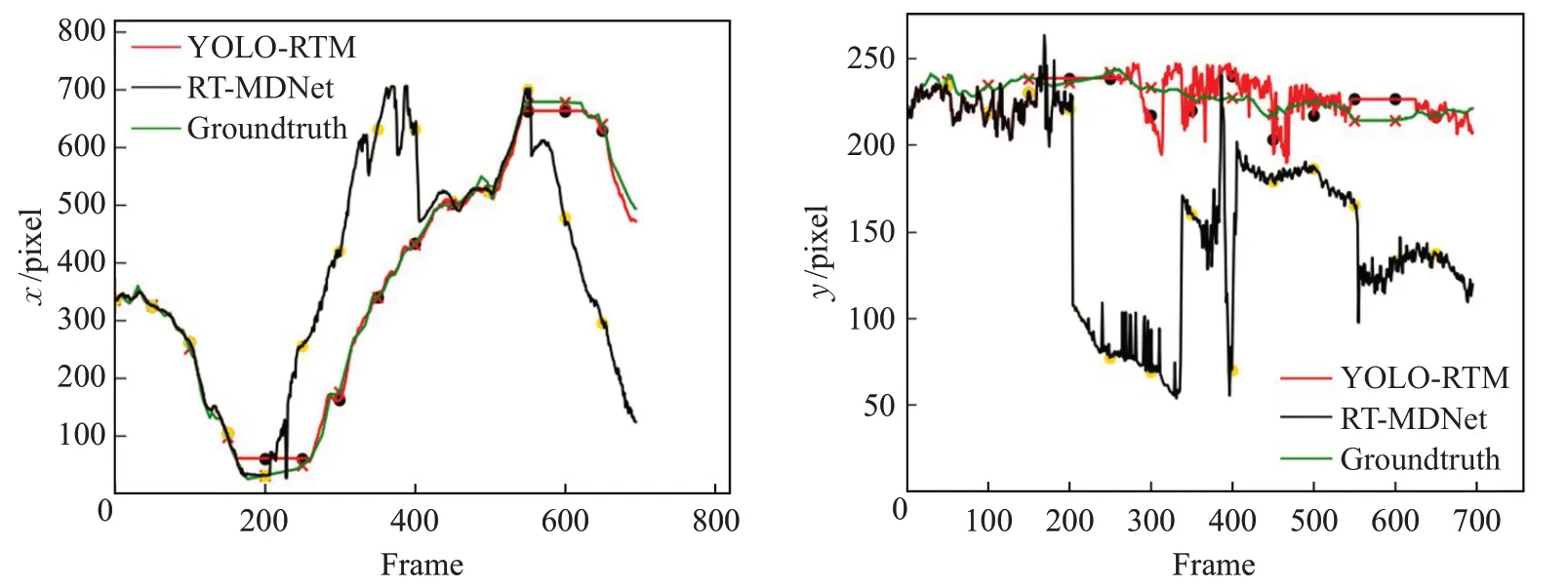
图18 Walker3视频中心点x、y 坐标运动轨迹
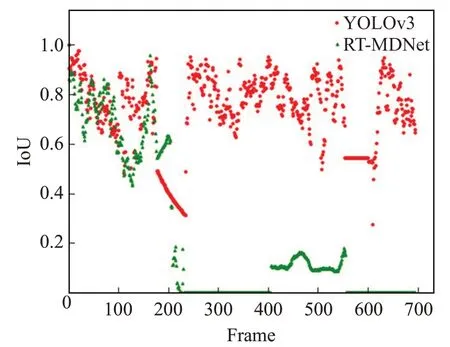
图19 YOLOv3和RT-MDNet与真实值IoU比较
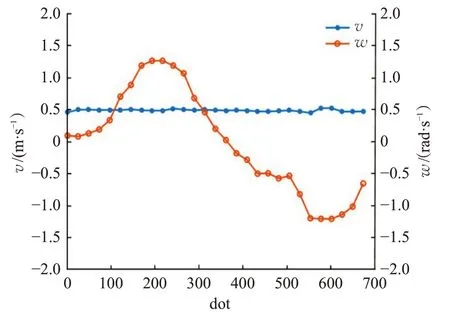
图20 机器人底盘控制结果
4 结论
基于目标丢失判别机制的YOLO-RTM视觉跟踪算法,将YOLOv3 检测算法和RT-MDNet 跟踪算法结合,设定跟踪边界框的重叠度阈值、面积阈值作为目标丢失判别机制,利用YOLOv3 找回丢失的跟踪目标,解决了跟踪过程中目标丢失后找回问题,同时机器人根据目标中心点在图像中的不同位置,采取不同的控制策略,目标被完全遮挡、出镜头等情况下机器人可准确跟踪目标路径,使移动机器人稳定、准确跟踪目标的应用价值得到较大的提高。在跟踪场景更复杂情况下,跟踪精度、跟踪速度依然存在改进空间,下一步将在此方面继续深入研究。
