WKAG:一种针对不平衡医保数据的欺诈检测方法
2021-05-14吴文龙王保全
吴文龙,周 喜,王 轶,王保全
1.中国科学院 新疆理化技术研究所,乌鲁木齐830011
2.中国科学院大学,北京100049
3.新疆民族语音语言信息处理实验室,乌鲁木齐830011
我国对人民生命健康的保障制度日益完善,医疗保险参保人数已超过13 亿,但是,医疗保险普及的同时,也引发了很多医保诈骗行为,每年造成的经济损失高达数亿元[1]。对医保欺诈进行有效检测成为一项迫切且富有意义的研究工作。
2017年,中国社会保险学会联合人社部信息中心等部门,指导举办了“全国社会保险大数据应用创新大赛”,其中就包括对医保欺诈违规行为的检测识别。竞赛成绩较好的队伍主要采取在构造大量特征的基础上,结合机器学习的方法对医保欺诈数据进行检测,但是由于受限于业务背景知识的掌握,构造的特征会出现重叠或者无效的情况。
医保欺诈检测实际上属于二分类问题,把数据分为正常数据和欺诈数据,然后选择合适的算法模型对欺诈记录数据进行检测发现[2]。在医疗保险数据中,欺诈人数占比很小,欺诈数据量和正常数据量差别较大,数据不平衡问题极大地影响了很多已有欺诈识别方法的效果。当前虽然有欠采样(Under-Sampling)或者过采样(Over-Sampling)方法用于改善这种数据不平衡问题,但是欠采样方法容易丢失重要的数据,而过采样方法容易导致模型过拟合[3]。合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)在一定程度上避免了信息损失和过拟合的问题,但是会增加数据中不同类之间重叠的可能性,容易出现过度泛化的问题[4]。
针对上述对现有问题的分析,本文提出了一种针对不平衡医保数据的欺诈检测方法——WKAG。首先,不同于传统的采样方法,本文基于现有欺诈数据使用生成模型生成高置信度的仿真欺诈数据,避免出现信息损失以及过拟合问题。其中,通过使用核密度估计(Kernel Density Estimation,KDE)[5]改变Wasserstein Generative Adversarial Network(WGAN)[6]噪声数据的构成,以此来进一步提高网络生成数据的质量,对不平衡数据进行重新构建。在数据特征表示方面,本文针对特征构造困难的问题,使用Auto-Encoder[7]来对数据进行自编码特征表示,最后使用构建表示后的数据对Gradient Boosted Decision Tree(GBDT)[8]分类预测模型进行训练,并将训练完成的模型应用于原始的不平衡医保数据集上,对欺诈数据进行检测发现。
1 相关工作
目前中西方学者主要从数据挖掘的角度来开展欺诈检测的相关研究工作[9]。
Liou等人[10]针对台湾的健康保险系统数据,使用了逻辑回归、决策树和神经网络三种数据挖掘技术来进行数据异常的检测发现。Bauder 等人[11]使用欠采样以及过采样方法在无监督学习、有监督学习以及混合机器学习方法上进行医保欺诈检测实验,结果表明欠采样方法表现优于过采样方法。Fiore 等人[12]在信用卡不平衡数据集上使用对抗生成网络(Generative Adversarial Network,GAN)[13]来对少量的异常样本进行扩充,实验证明,相比于SMOTE,GAN 对不平衡样本的处理效果更好。GAN虽然可以通过生成新的数据来改善数据不平衡问题,但是模型在训练时容易出现模式崩溃的现象,无法保证生成数据的多样性,而WGAN 则可以避免这一问题[14]。Sethia等人[15]使用WGAN结合人工神经网络模型来对信用卡欺诈数据进行检测发现。曹鲁慧等人[16]针对医保数据不平衡问题和时间分布不均问题,使用TLSTM 方法对用户欺诈的可能性进行判断,这种方法要求数据要保证具有较长的时间跨度,不适用于时间周期较短或者不连续的数据。
数据特征表示对最终的欺诈检测效果影响很大。Gao等人[17]通过对历史数据统计分析并选择相关特征对用户进行分组,从而避免医疗保险理赔数据中个人数据稀疏的问题。Herland等人[18]通过人工选择医保数据集中的某些特定特征,并采用计算平均值、总和、中位数等聚合方式增加新特征。Pouramirarsalani 等人[19]提出了一种基于混合特征选择和遗传算法的欺诈检测方法,在电子银行欺诈检测方面取得了不错的效果。Li 等人[20]提出了一种构建欺诈检测模型的方法,该方法在人工特征工程的基础上,结合GBDT 和Gate Recurrent Unit(GRU)对特征进行优化,最后使用随机森林分类模型进行训练预测。
虽然目前关于欺诈检测的研究已经取得了一定进展,但是对于欺诈检测中数据不平衡问题并没有很好地解决方案,而且对数据的特征构造过于依赖人工以及和业务知识相关的先验经验。因此本文考虑使用生成仿真数据的方式对数据不平衡问题进行改善,结合深度学习模型基于数据本身进行特征表示并由此提出一种针对不平衡医保数据的检测方法。
2 欺诈检测方法
本文提出的医保欺诈检测方法WKAG主要包括以下三方面内容:(1)WGAN-KDE数据构建;(2)自编码特征增强表示;(3)GBDT欺诈分类检测。图1为本文欺诈检测方法的总体流程。
2.1 数据的构建方法
针对医保数据中欺诈数据和正常数据不平衡问题,本文使用WGAN-KDE 在现有欺诈数据的基础上进行仿真数据生成,对不平衡数据重新构建。
2.1.1 生成式对抗网络
GAN模型包括生成器(G,Generator Model)和判别器(D,Discriminative Model)。生成器最大化生成和真实数据相似的样本,判别器则对生成样本和真实数据加以判别,当判别器无法正确区分生成样本和真实数据时,此时的生成样本就和真实数据高度相似。对抗神经网络模型的计算过程如图2所示。虽然GAN利用零和博弈理论定义了新的生成模型,但是在训练时会存在梯度消失和模型崩溃的问题。针对这一问题,WGAN 使用了Wasserstein Distance 作为距离度量并将其转化为优化问题,彻底解决了模型训练不稳定的问题,同时也基本避免了崩溃模式的发生,保证生成数据的多样性。生成式对抗网络作为一种生成模型,可以用于仿真数据的生成,弥补数据不足的问题。
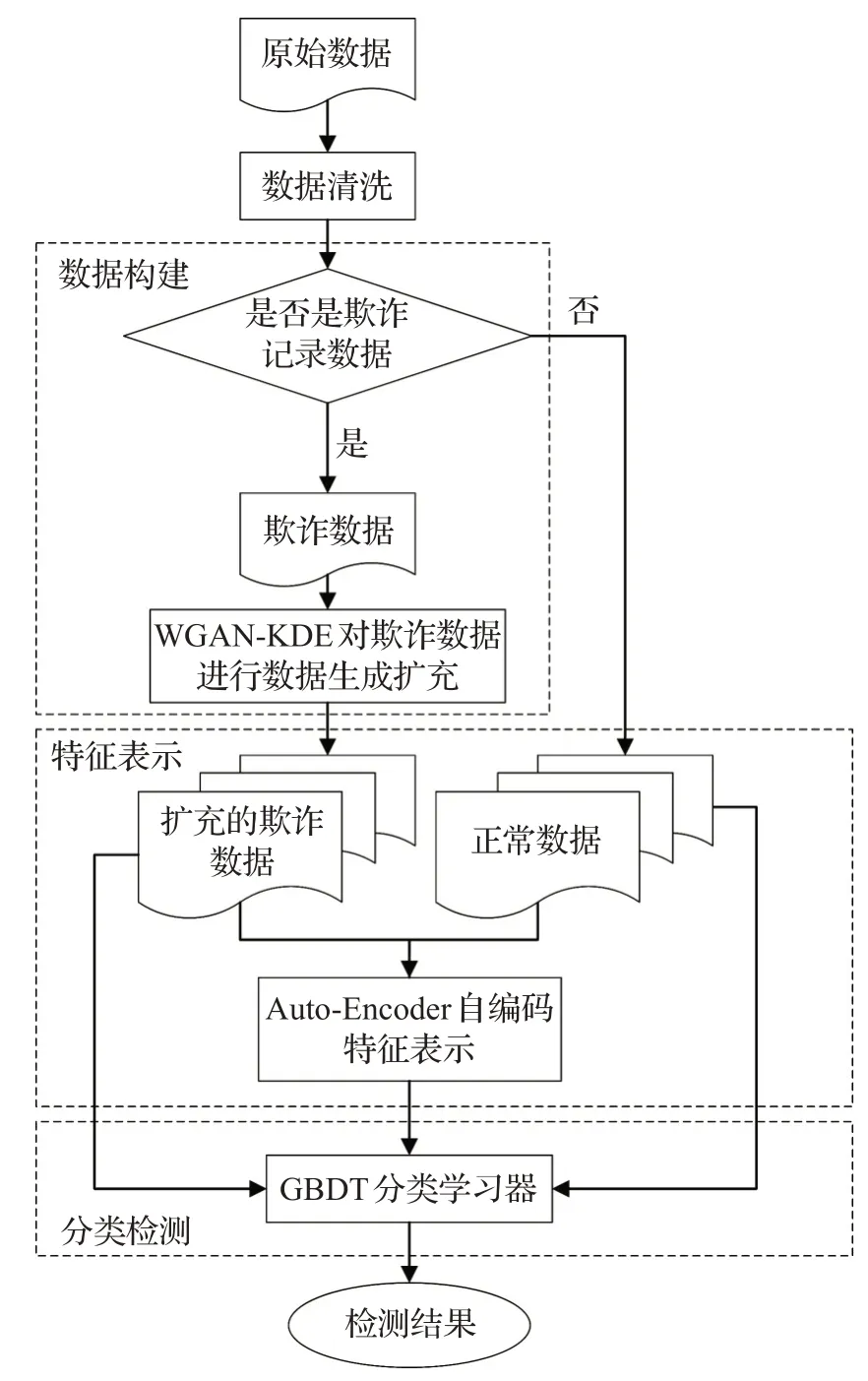
图1 WKAG方法总体流程
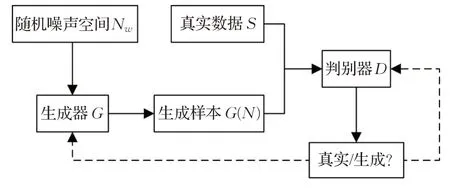
图2 GAN计算过程
2.1.2 非参数核密度估计
KDE 是一种非参数检验方法,可以基于数据本身的分布特点,在对数据分布没有预先作出假设的情况下,进行拟合预估。假设同分布数据x1,x2,…,xn,对于任意样本x处的总体概率密度函数fh(x) 可以表示为:
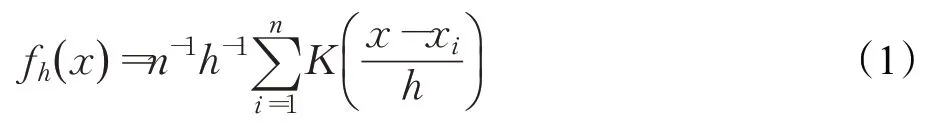
其中,n代表样本数据量个数,h代表平滑系数,K(·)是核函数。
2.1.3 WGAN-KDE
GAN 中随机噪声数据可以提高网络的泛化性能,避免模型出现过拟合问题,但是没有考虑到真实样本的分布状态,对数据的生成效果难以控制。在此基础上,本文考虑基于医保数据的数据分布来引入噪声数据。
获取数据分布可以使用参数方法和非参数方法。目前常用的参数方法往往是根据先验知识,对数据的总体分布作出一个合理的假设(例如:正态分布、高斯分布等),但是实际情况下往往不能保证数据的实际分布符合假设的情况。核密度估计作为一种非参数方法,几乎不需要对数据的总体作出任何的假设条件,可以适用于多种类型的数据。因此可以使用KDE对数据分布进行估计。
(1)核密度估计噪声
对欺诈样本S={x1,x2,…,xn} ,使用KDE构建S的概率密度模型,考虑到本文关注的是欺诈样本总体的分布情况,而高斯核可以使得估计的分布更加平滑,因此选用高斯核作为核函数。fh(x)可以进一步表示为:
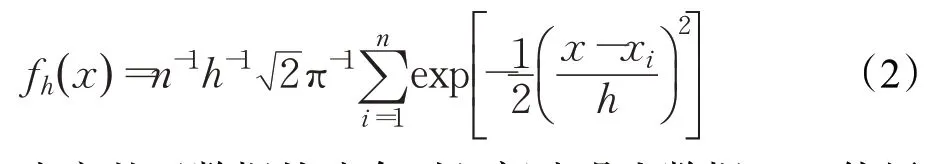
本文基于数据的分布引入部分噪声数据Nk,使用WGAN-KDE 用于少数类数据生成扩充,模型的计算过程如图3所示。
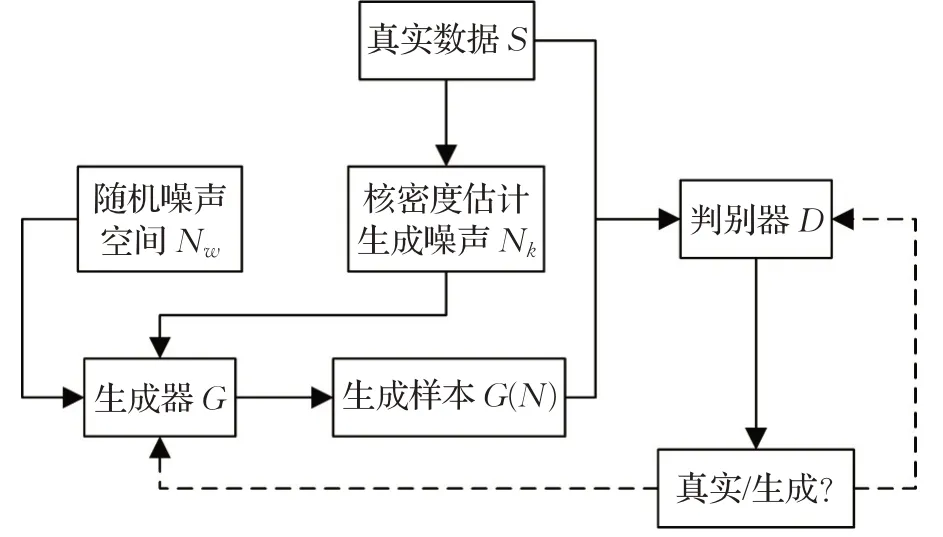
图3 WGAN-KDE计算过程
(2)数据生成质量控制
WGAN中Nw可以保证算法的泛化性能,但是无法兼顾数据实际分布特点。Nk虽然兼顾实际数据的分布,但是过多地引入会引起模型的过拟合问题。合理结合使用Nw和Nk对最终的数据生成质量影响很大。
一方面,为了对仿真数据的生成效果进行评估,计算仿真数据和真实数据之间的相似程度,本文具体方法如下:对真实数据S添加标签0,对生成的仿真数据G(N)添加标签1。使用GBDT分类器对真实数据S和生成的仿真数据G(N)进行分类。理想情况下,生成的仿真数据和真实数据高度一致,这样分类器无法正确区分,此时分类效果应为0.5。
另一方面,对数据多样性的保证也至关重要。使用分类器可以量化评估仿真数据和真实数据的相似度,但可能会出现在较为理想的分类效果下,仿真数据只学习了少部分真实数据的问题。数据生成的多样性可以更为全面地表现原有的欺诈数据,对不平衡数据的重新构建结果有极大影响。所以本文针对这一问题,对真实数据和仿真数据进行可视化展示,直观地观察仿真数据生成的效果。
本文综合考虑分类器的量化指标以及可视化结果,对生成的仿真数据进行选择。考虑到实际情况下很难达到0.5的分类效果,因此本文设置一个控制区间Δ,选择分类效果区间在0.5±Δ之间的仿真数据,结合其数据分布效果图,选择数据多样性较高的仿真数据用于对欺诈数据的扩充。
定义仿真数据和真实欺诈数据的相似距离E:

(3)WGAN-KDE算法
综合以上对数据生成质量控制的分析,设定一个噪声融合比例λ,表示Nk和Nw之间的比例关系,最后融合的噪声N可以表示为:
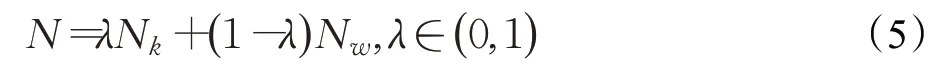
本文使用医保欺诈样本数据对WGAN-KDE 网络进行训练,最终得到高置信度的仿真欺诈数据并且将这些仿真数据加入到原始医保数据中,平衡数据分布,克服数据不平衡对模型训练的影响,提高训练效果。WGAN-KDE的详细步骤如下所示:
输入:欺诈样本数据S={x1,x2,…,xn} ,分类控制区间ΔForλ=0 to 1
(1)使用KDE获取S的数据分布Distrubution(S)
(2)Distrubution(S)生成噪声数据Nk
(3)将Nk以λ的比例加入到WGAN 的原有随机噪声数据中,生成新的噪声数据N
(4)G接受噪声数据N,生成仿真数据G(N)
(5)D对G生成的仿真数据G(N)和真实数据S进行判别
(6)若D无法正确区分仿真数据G(N)和真实数据S,算法终止,返回仿真数据;否则,重复步骤(2)至(5)
(7)计算仿真数据和欺诈数据距离E
(8)λ=λ+step,其中step为更新步长
End for
(9)选择数据分类区间pre(G(N),S)在win的数据,结合数据分布可视化图形,选择合适λ值,记为λ*
(10)在λ*的比例噪声下,重复步骤2至5,进行仿真数据G(N)的生成
输出:仿真数据G(N)
2.2 数据特征增强表示
在医保欺诈数据的分类检测任务中,数据的特征处理对最终的检测效果影响很大。对数据进行有效特征的构造是一项十分耗时的工作,而且受限于对业务背景知识的掌握以及现有的分析方法,通常也无法保证所构造特征的有效性。
自编码器是一种无监督的深度学习模型,模型经过训练后,可以学习到数据中有效的新特征,自编码器的结构如图4所示,包括编码过程和解码过程。在编码阶段,通过将输入层的数据映射到隐藏层进行维度压缩;在解码阶段,将隐藏层的数据映射恢复到输出层。所以可以通过对隐藏层的编码数据进行提取,获取到原数据的自编码特征,文献[21]表明自编码特征可以有效加强对数据特征的表示效果。
图4 自编码器网络结构
本文在对数据重新构建后,使用自编码器来获取原数据的自编码特征,然后将提取到的自编码特征与原有特征结合,对数据特征增强表示。
对构建后的平衡数据集D={x1,x2,…,xq} ,训练自编码网络:

其中,z是输入层到隐藏层的映射数据,sig是sigmoid激活函数,y是解码后的数据,w和w′为权重矩阵,b和b′为偏置向量。

其中,Ω为网络参数,Ω=w,w′,b,b′。
采用梯度下降法训练,迭代更新直至参数Ω收敛。
2.3 分类检测
GBDT 是一种集成学习的方法,采用Boosting 的方式将一系列决策树作为弱分类器进行训练组合,通过梯度上升对模型不断进行迭代优化,模型最终的预测结果由多个决策树预测值加权结合得到。图5 为GBDT 训练过程。
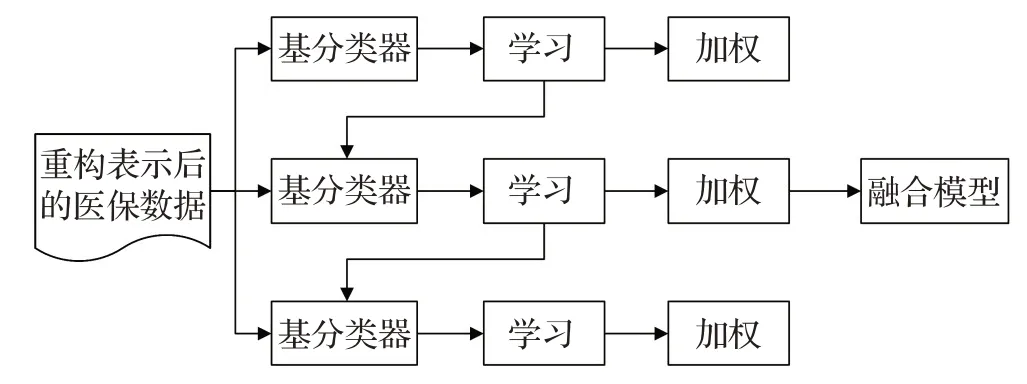
图5 GBDT训练过程
当前GBDT以其良好的性能表现被用于解决分类、回归以及排序等问题,在学术界以及工业界得到了充分的认可。本文在解决医保数据不平衡以及特征表示问题后,将重构表示后的数据用于GBDT 模型的训练,对医保欺诈数据进行检测。
3 实验与结果分析
3.1 实验数据与设计
本文使用的医保数据集来自2017 年“全国社会保险大数据应用大赛”官方数据,该数据样本为部分地区以往年度的医疗保险就医结算脱敏数据,包含20 000人将近两百万条记录信息,其中欺诈人员有1 000 人,数据包含69个特征。另外,为了验证本文方法WGANKDE 在改善不平衡数据分类方面的普遍适用性,选取了Kaggle信用卡欺诈数据和KEEL[22]的2个不平衡数据集进行了实验验证。表1 描述了实验所用数据集相关信息。
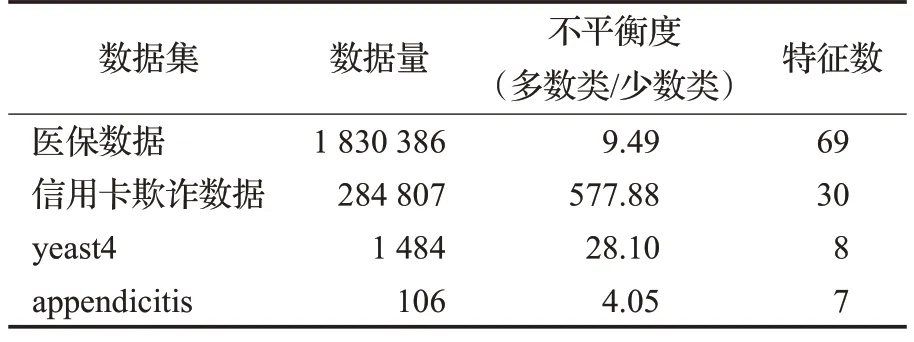
表1 数据集信息
本文将WGAN-KDE与随机欠采样(Random Under-Sampling,RUS)、SMOTE 等传统方法以及WGAN 相比较,基于LR、AdaBoost 和GBDT 等不同的分类模型,在使用不同方法平衡后的数据上对模型进行训练,然后基于原有的不平衡数据测试集进行分类检测。最后,在医保数据集进一步使用Auto-Encoder 对数据进行自编码特征增强表示,使用GBDT 算法进行欺诈数据的检测发现。
为了全面对不同方法做出评价,本文使用召回率(Recall)、精确率(Precision)、F1、准确率(Accuracy)以及AUC等多个评价指标。
3.2 WGAN-KDE有效性的实验验证
首先,本文基于Kaggle信用卡欺诈数据集和KEEL的2 个不平衡数据对WGAN-KDE 方法进行实验验证。为了更为直观地展示本文使用WGAN-KDE 生成仿真数据的效果,在每个数据集上各选取两个特征对真实数据和仿真数据进行可视化展示,横纵坐标分别表示经过数据处理后的特征信息,不是属性的真实值。图6~图8为各数据集的仿真数据生成效果图。
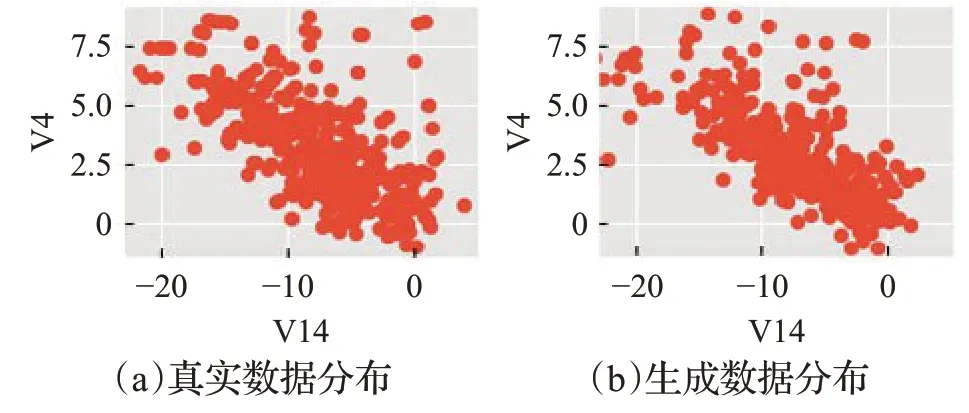
图6 信用卡数据集数据生成效果
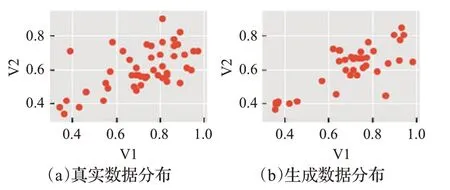
图7 yeast4数据集数据生成效果
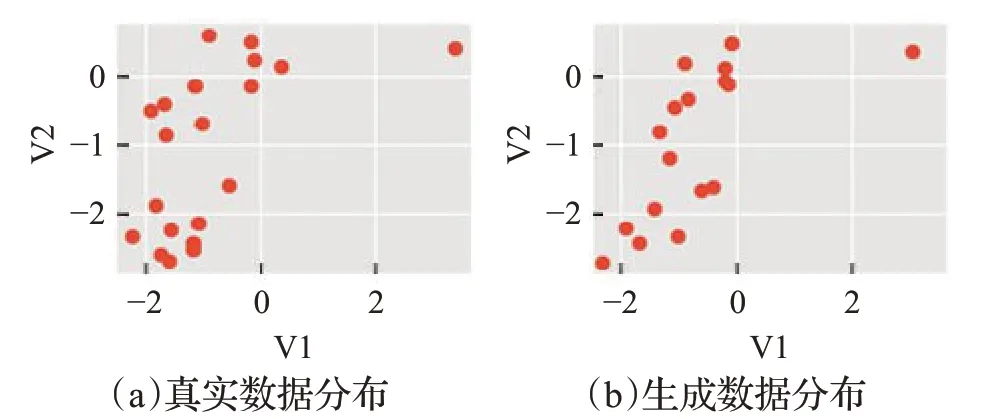
图8 appendicitis数据集数据生成效果
根据在信用卡、yeast4 以及appendicitis 三个公开数据集上的数据生成效果图,对各数据集的真实数据分布和生成数据分布进行比较。从总体分布来看,使用WGAN-KDE生成的数据较好地还原了原本真实数据的分布特点和规律;从个别数据分布来看,虽然生成数据和真实数据分布基本一致,但是又不完全相同。这样就避免了随机欠采样引起的关键信息丢失和SMOTE过采样方法导致的样本重叠问题。因此,可以考虑使用WGAN-KDE针对不平衡数据样本中的少数类来进行仿真数据生成,达到平衡数据分布的目的。但是,直观的可视化表示还不足以证明WGAN-KDE方法的有效性,下面本文使用RUS、SMOTE、WGAN和WGAN-KDE等不同的方法来平衡数据分布,基于不同的分类器模型进行训练比较。表2~表4 分别为基于信用卡欺诈数据、yeast4、appendicitis数据集上的实验结果。
实验使用五个指标对不同的数据不平衡处理方法进行全面评价。从信用卡欺诈数据、yeast4、appendicitis等3 个不平衡数据集上的实验结果可以看出,WGANKDE 相比于RUS、SMOTE 以及WGAN 等方法,在F1、Accuracy、AUC等综合评价指标上表现优异。特别是在F1和Accuracy方面,WGAN-KDE在不同的分类器模型上基本都达到了最好的效果。在AUC 评价指标上,虽然WGAN-KDE无法保证最优值,但是差距在可接受范围内,总体有着较好的表现。
Recall和Precision体现了对所关注数据类查找的完整性和精确性。相比于RUS 和SMOTE 方法,WGANKDE 在Recall 指标上有所降低。这是由于抽样方法本身特性所导致的。无论是随机欠采样还是SOMTE过采样方法,都是最大化保留了原有数据中少数类的数据信息,通过减少多数类数据的样本量或者重复现有少数类数据的样本量来平衡数据分布,这就造成多数类部分数据信息丢失或者过大化地表示少数类数据信息的问题,最终导致分类器在训练时对少数类数据较为敏感,从而表现为高召回率。
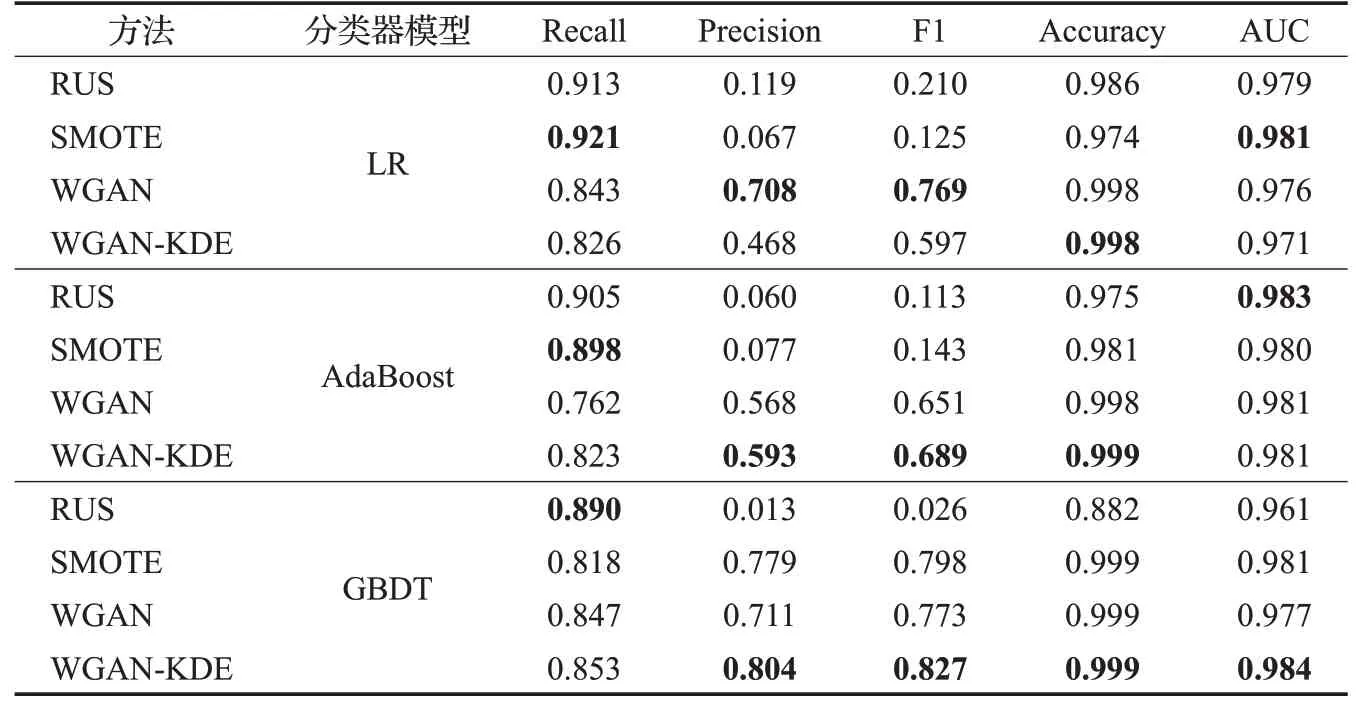
表2 信用卡欺诈数据集上使用不同方法的实验结果
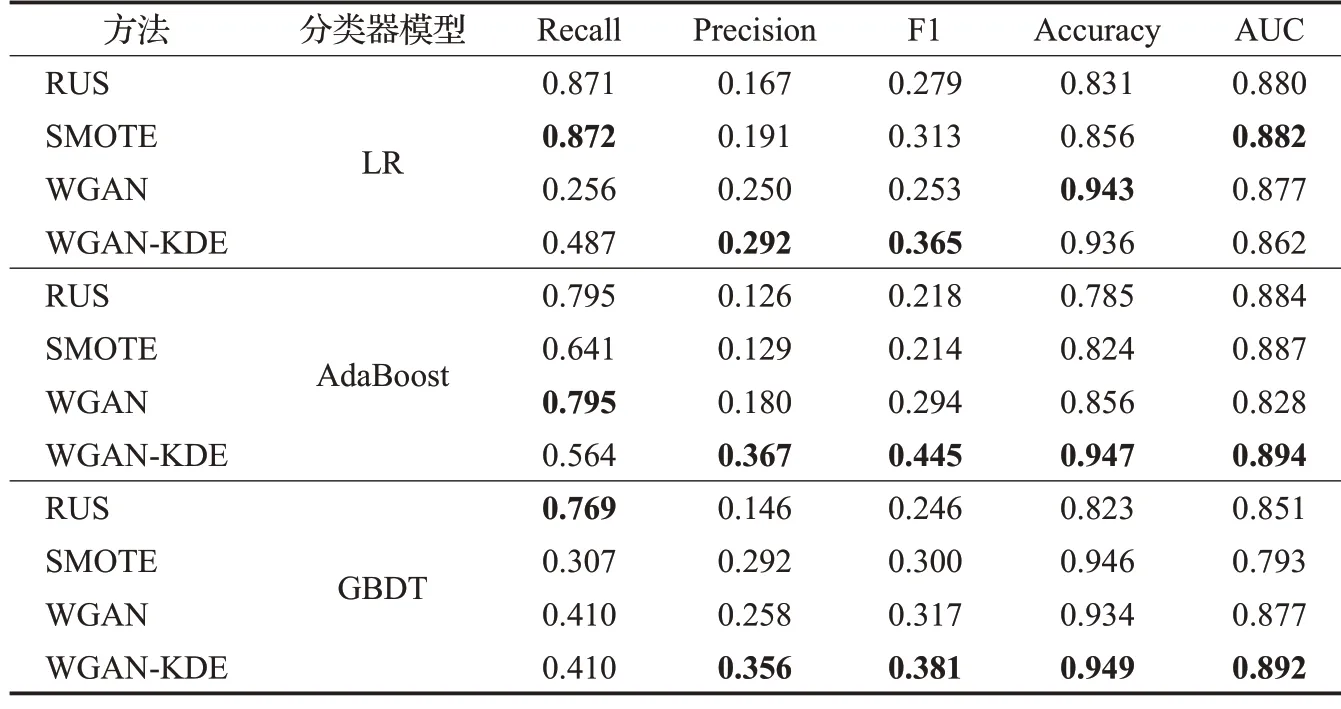
表3 yeast4数据集上使用不同方法的实验结果

表4 appendicitis数据集上使用不同方法的实验结果
但是随机欠采样和SMOTE过采样方法在保证高召回率的同时,在精确率指标上表现较差。在欺诈检测工作中,算法模型对数据记录作出检测后,还需要进一步地人工核实,这是一项十分耗时且不容忽视的工作,而低精确度会导致大量无效工作的投入,造成资源浪费。因此,寻找召回率和精确率之间的平衡尤为关键,WGAN-KDE相比于RUS、SMOTE和WGAN方法,更好地同时兼顾了召回率和精确率,在保证有效召回率的同时,精确率也有着较好的表现,因此在欺诈检测工作中有较高的应用价值。
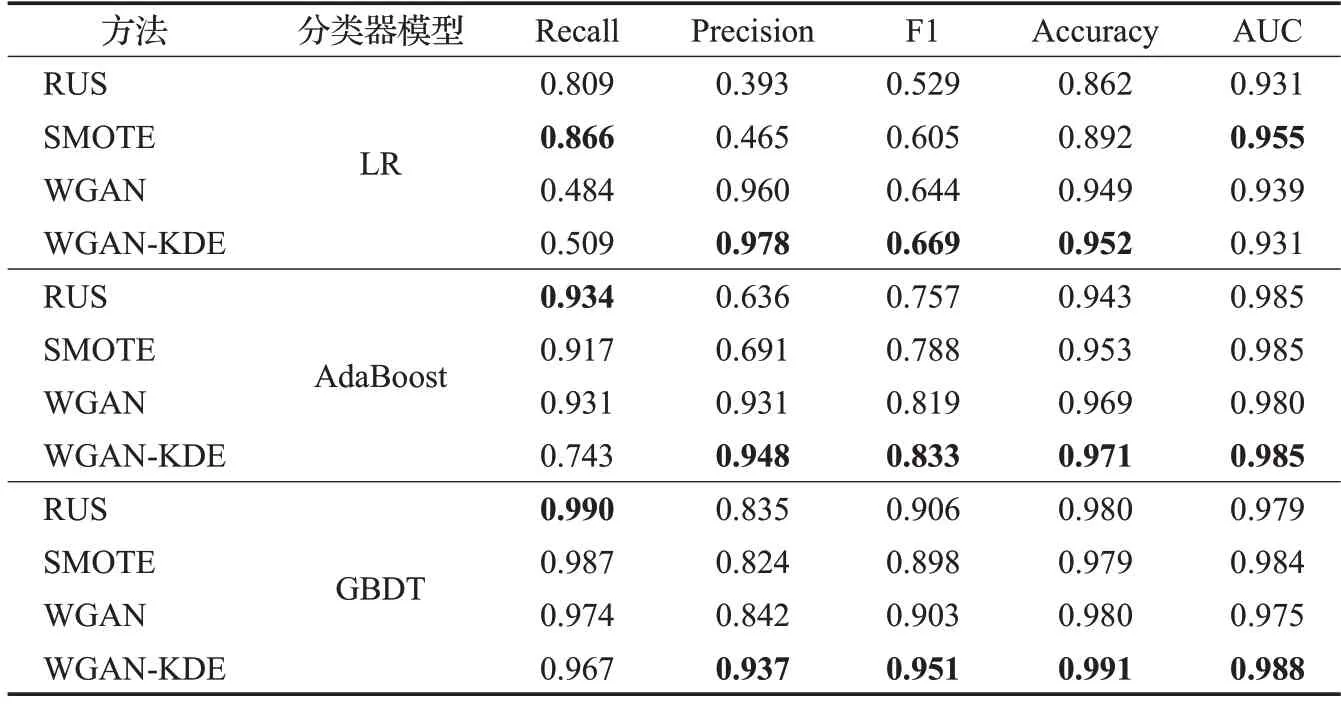
表5 医保数据集上使用不同方法的实验结果

表6 医保数据使用自编码表示后的实验结果
3.3 医保数据集的实验结果
在对WGAN-KDE有效性进行验证后,本文在医保数据集上使用WGAN-KDE 对不平衡数据进行重新构建。表5 为在医保数据集上使用不同方法平衡数据分布后的实验结果,表6 为使用Auto-Encoder 对数据进行自编码特征表示后,使用GBDT方法在医保数据上欺诈检测的实验结果。
从表5的实验结果可以看出,基于医保数据集在不同的分类器模型下,使用不同的数据平衡方法,WGANKDE 在可接受范围内牺牲了召回率,但是和RUS、SMOTE、WGAN 方法相比,精确率、F1、准确率以及AUC等评价指标基本都达到了最优。在不同的分类器模型比较中,GBDT方法在各评价指标的表现都优于其他分类器模型。而且,在GBDT模型下,WGAN-KDE相比于RUS,召回率降低了0.023,精确率提高了0.102;相比于SMOTE,召回率降低了0.02,精确率提高了0.113;相比于WGAN,召回率降低了0.007,精确率提高了0.095。证明了WGAN-KDE方法在医保欺诈检测工作中,可以很好地同时兼顾召回率和精确率。
为了验证自编码特征表示在医保欺诈检测中的效果,表6 进一步进行实验验证。考虑到表5 中WGANKDE+GBDT 表现最好,因此在使用WGAN-KDE 对医保不平衡数据进行重新构建后,基于构建后的平衡数据集,进一步使用Auto-Encoder对数据进行自编码特征表示,最后使用GBDT进行分类检测。从表6的实验结果可以看出,对数据进行自编码表示后,Recall、Precision、F1、Accuracy和AUC等评价指标全面提升,提高了对欺诈数据的检测效果,而且,通过自编码器提取自编码特征,可以减少传统人工特征工程中对专业业务背景知识的依赖以及特征挑选和构造所消耗的时间。
根据表1的实验数据集信息,通过比较不同数据集的数据规模可以看出,医保数据集的数据不平衡度为9.49,远低于信用卡欺诈数据577.88 的数据不平衡度。而且,综合比较基于不同数据集的实验结果可以看出,数据集的不平衡度越高,过采样和欠采样方法对召回率和精确率之间的兼顾性越差,WGAN-KDE 方法的优异性越突出。从文献[23]中可以得知,现实中医保欺诈率远低于实验所使用的医保数据,数据不平衡度极高,一个具有高可用性的欺诈检测方法应当在保证召回率的同时,要同时兼顾到精确率,这样可以提高对医保欺诈行为检测工作的效率。由此可以得出,本文方法WKAG可以作为解决不平衡医保数据欺诈检测问题的有效方法。
4 结束语
本文针对不平衡医保数据的欺诈检测问题,提出了一种解决方法——WKAG。首先,对于数据的不平衡问题,传统的欠采样和过采样方法只是简单地对原有数据进行增减从而构建为平衡数据,但是这种方式无法同时兼顾召回率和精确率。本文提出了一种新的解决方法WGAN-KDE 来对数据进行重新构建,根据在医保数据集、信用卡欺诈数据集以及KEEL 的2 个不平衡数据集上的实验结果,验证了WGAN-KDE方法可以较好地同时兼顾到召回率和精确率,而且在其他综合评价指标上也表现优异。其次,针对医保数据中的特征表示困难的问题,本文使用Auto-Encoder方法减少对人工以及经验的依赖,对数据进行自编码特征表示,实验结果说明,自编码特征表示可以更进一步地提高模型对欺诈数据的检测效果。综合基于各数据集的实验结果表明,本文方法WKAG在解决不平衡医保欺诈检测问题中具有较高的可用性。
