一种单砂体多因素分类评价方法
——以柴达木盆地扎11井区下油砂山组为例
2021-05-14李积永胡光明王军林祁青山
李积永, 张 平, 胡光明, 蒲 勇, 王军林, 祁青山, 吴 涛
(1.中国石油青海油田勘探开发研究院, 敦煌 736202; 2.中国石油勘探开发研究院西北分院, 兰州 730020;3.长江大学地球科学学院, 武汉 430100; 4.中国石油青海油田生产运行处, 敦煌 736202; 5.青海油田采油五厂, 敦煌 736202)
油气勘探开发过程中的储层综合评价涉及两个方面:一是选择什么参数进行评价;二是如何确定各种参数之间的权重,这两个方面是储层综合评价的核心内容[1]。常用的评价参数包括沉积相、成岩阶段、成岩相、物性、储层厚度、砂地比、孔隙类型、孔隙结构、突进系数、变异系数、含油饱和度和储量等[2],也有学者采用动静态参数相结合进行评价[3],选择哪些参数主要取决于具体工区中各种参数对储层的影响程度,一般是优选出对储层影响较大的、相互独立的参数参与综合评价[4]。
评价方法主要包括定性评价、半定量评价和定量评价。其中,定性评价主要是根据经验选出参与评价的参数,并对不同参数进行分级,然后得出综合评价的结论。对于评价对象较少、影响因素较少的储层,这种方法快捷、简便,比较实用,但评价结果容易受到主观因素影响。因此,科研工作者更倾向于采用半定量、定量评价,这也是储层评价的发展趋势。定量评价是采用数学方法筛选出参与综合评价的参数和确定各参数的权重,如应用主成分分析法、Q 型主因子分析法等选出储层分类的主因子参数, 然后采用聚类分析、逐步判别分析等方法进行储层评价[5-6],还有模糊综合评判法[7]、灰色聚类法[8-9]等。这类方法受主观因素影响较小,因而结果比较客观,适用于评价对象较多、控制因素较复杂的工区,但定量评价需要自行构建复杂的数学模型,往往没有现成的软件工具而需要编程,不便于油田工作者使用。因此,借助已有的统计软件探索简单易行的评价方法就显得格外重要了。
1 地质背景
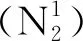
2 单砂体特征
3 单砂体分类评价
单砂体分类评价的目的是划分砂体的优劣,确定不同类型油砂体的开发政策,改善开发效果,提高采收率。如何优选出具有代表性的评价参数,并科学地确定各参数的权重,是进行单砂体分类评价的关键。
3.1 评价参数的选取
用于砂体分类评价的参数很多,但由于不同地区有其自身的特点,在实际应用中不可能取全所有参数,关键是要选出有代表性的参数。在SPSS中,相关性分析可选用皮尔逊相关系数(Pearson correlation coefficient)评价两个变量是否在一条线上面,用它来衡量变量间的线性关系,相关系数的绝对值越大,相关性越强,即相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱[14]。然后通过显著性检验来对参数进行取舍。
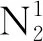
(1)
式(1)中:C为油砂体的周长。
利用SPSS软件进行相关性分析时,发现单砂体阶段产量(P)与砂体储量(N)、含油面积(A)与油砂体地层系数(KH)、长宽比(R)均呈正相关(表1),皮尔逊相关系数分别为0.843、0.826、0.805、0.444,显著性检验sig≤0.05,说明阶段产量与三参数显著相关,而阶段产量(P)与形状因子(S)呈负相关,且sig=0.013,虽然也是小于0.05,但远大于阶段产量(P)与其他参数之间的sig,说明阶段产量(P)与形状因子(S)相关性相对较差。 因此,选取了单砂体储量(N)、含油面积(A)、油砂体地层系数(KH)及长宽比(R) 4 个具有代表性的参数进行单砂体综合评价。
3.2 多元回归分析
多元线性回归是研究一个变量与多个变量间的相关关系一种统计方法,其原理是:①从一组样本数据出发,确定变量之间的数学关系式;②对这些关系式的可信程度进行各种验证;③根据一个或几个变量的观测值,用求得的关系式预测或控制另一特定变量的取值,并给出预测或控制的精度[14]。本文以单砂体阶段产量为因变量,以单砂体特征参数为自变量,利用多元线性回归方法求取单砂体各参数的权重系数及其评价模型。
为了消除各参数的单位影响便于分析,选取的48个单砂体的特征参数进行归一化处理(表2),即参数值除以该参数最大值。其计算公式为
(2)
式(2)中:Xi、Xmax和X分别为某油砂体的某一参数值、该参数的最大值和归一化值。
利用SPSS软件将砂体数据进行多元线性回归分析,定义砂体阶段产量为因变量(dependent variable),其他参数为自变量(independent variable),采用后剔除法(backward)进行分析,分别建立了3个回归模型(表3)。其中,模型1为P与R、KH、N、A的相关模型,模型2为P与KH、A、N的相关模型,模型3为P与KH、N的相关模型,3个模型的相关系数接近且较高,估计标准误差均低,且D-W(Durbin-Watson)统计量在2左右,说明残差是服从正态分布的,模型精度较高。
从3个回归模型的标准化系数来看(表4),单砂体特征参数对阶段产量(P)的重要性顺序依次为单砂体储量(N)、地层系数(KH)、含油面积(A)及油砂体长宽比(R),说明单砂体储量(N)影响最大,单砂体长宽比影响最小。由于单砂体储量与含油面积一定相关系,因此其重要性较小。3个模型的容差(tolerance)均大于0.1,方差膨胀因子(VIF)均小于10,则说明自变量间不存在严重共线性情况,且标准化残差图中的点分布是随机的(图1),没有出现趋势性。因此,回归模型有效。
分析表明模型1参与回归参数多,拟合程度最好,复相关系数R最高,为0.906,样本决定系数为0.820,修正可决系数0.803,估计标准误差为0.084 22,其回归系数分别为0.354、0.149、0.365、0.027,常数项为-0.041,即单砂体品质系数Q=0.354N+0.149A+0.365KH+0.027R-0.041。
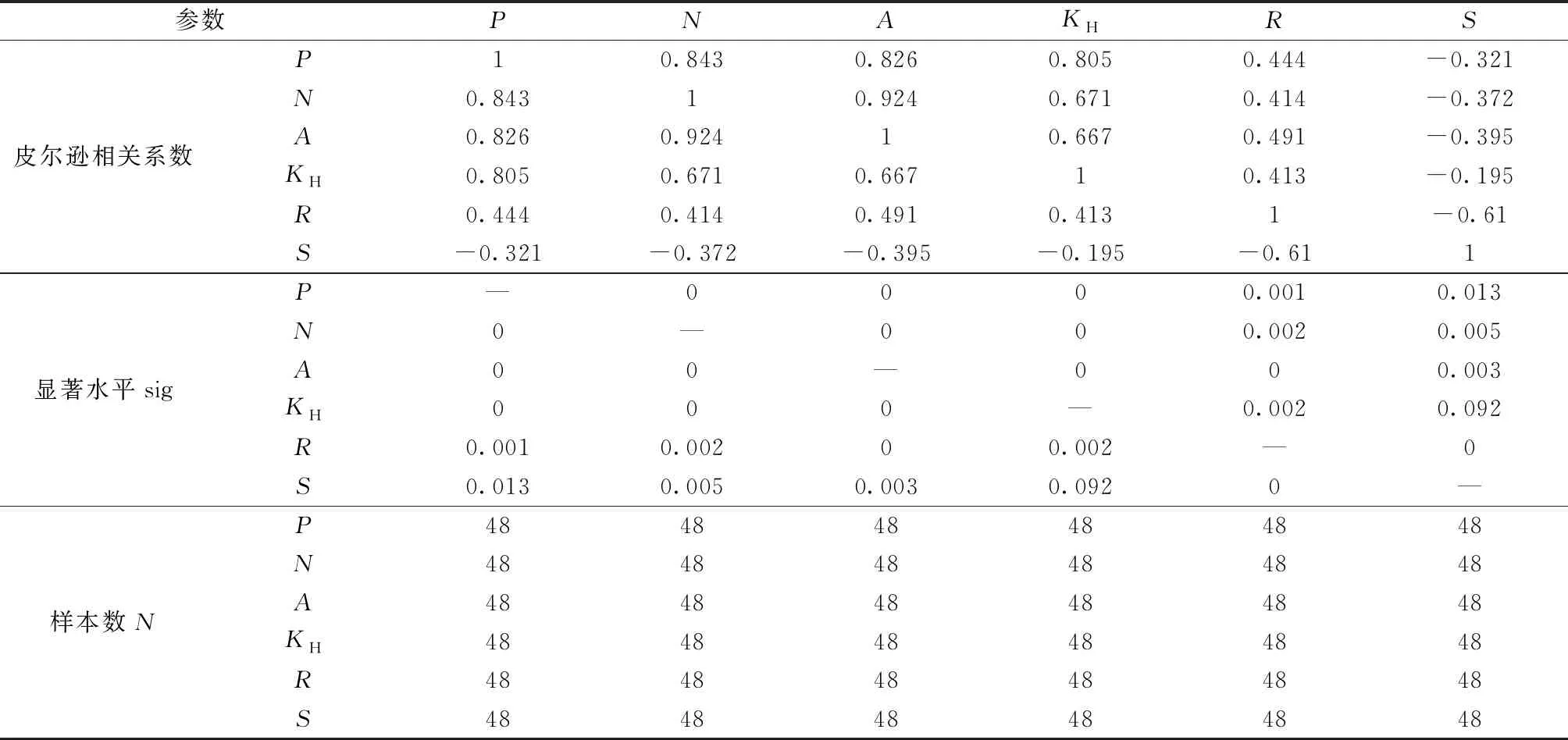
表1 单砂体产量与特征参数相关性分析
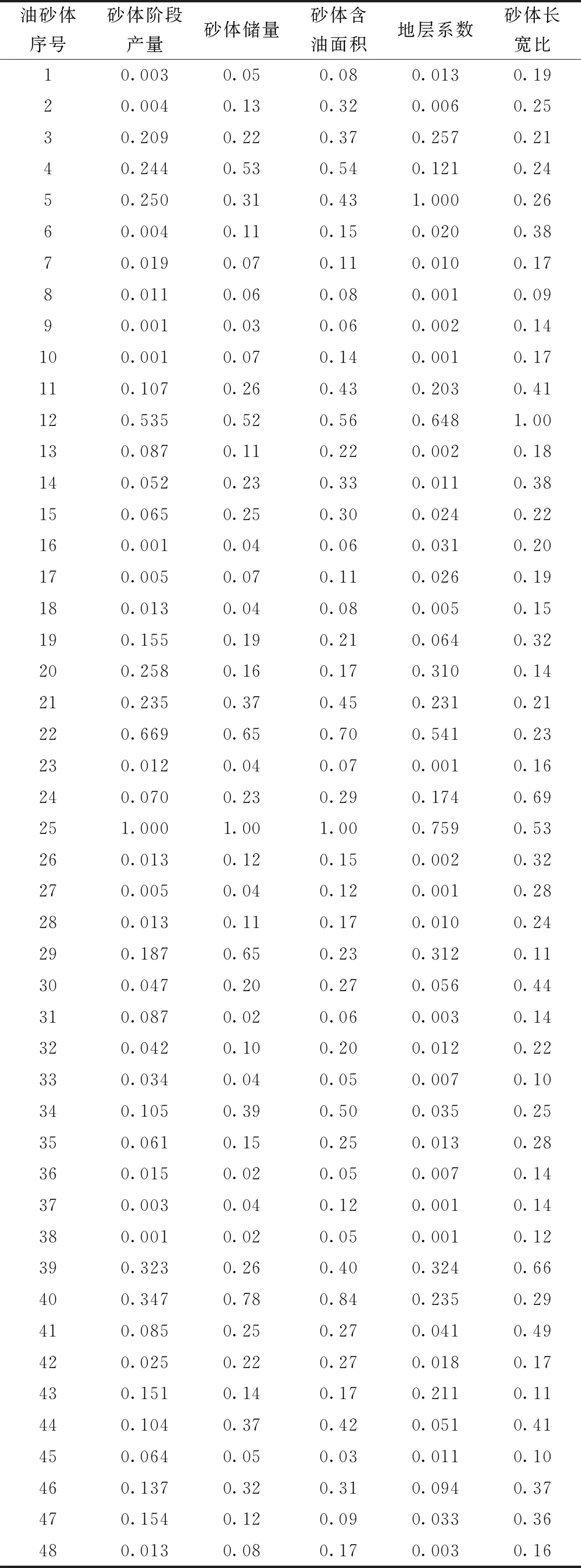
表2 扎哈泉油田扎11井区单砂体归一化参数统计
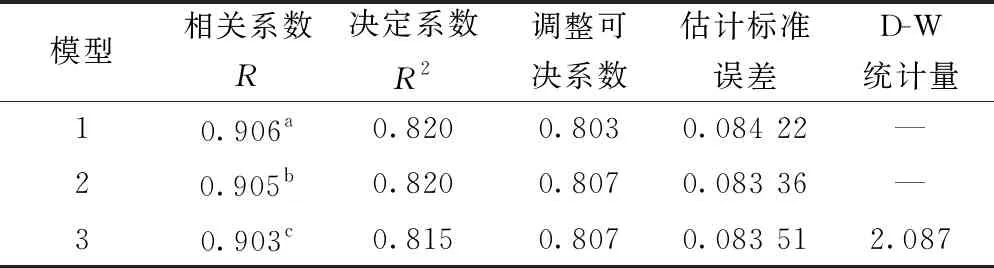
表3 不同回归模型的精度与参数
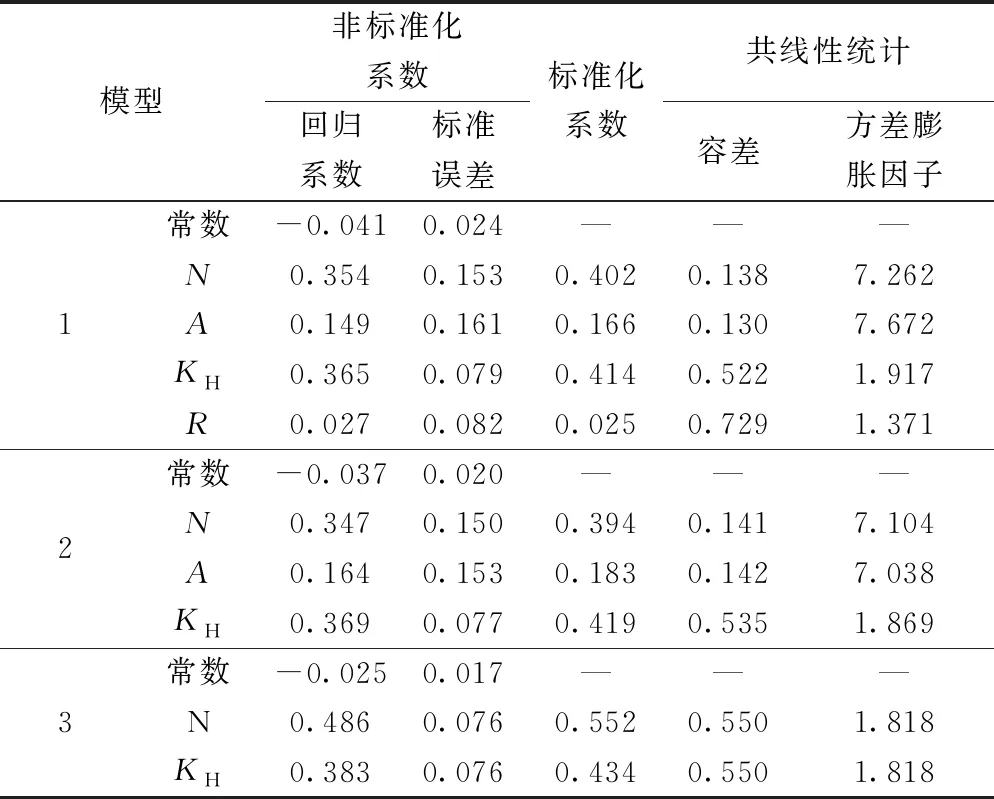
表4 模型回归系数及共线性检验
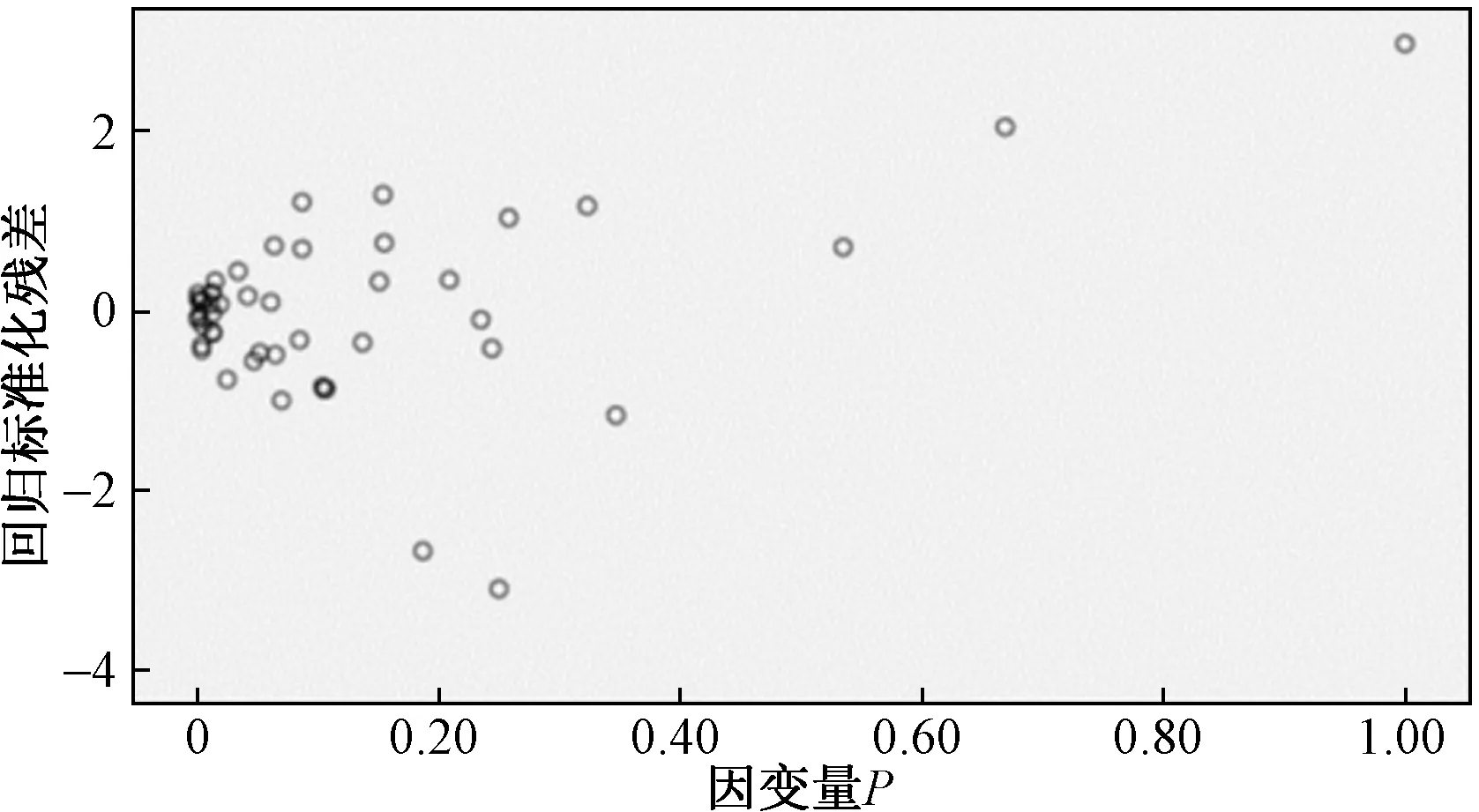
图1 扎哈泉油田扎11井区单砂体评价标准化残差分析图
3.3 生产应用
利用上述回归模型对扎哈泉油田扎11井区379个含油单砂体进行评价,其得分范围为0.186~0.812(图2)。在此基础上并结合油田实际,按其得分将油砂体分为三类(表5)。其中,一类砂体15个,二类砂体34个,三类砂体330个,其储量占比分别为58.5%、21.9%、19.6%。虽然一二类砂体数量较少,但是开发的主体。

图2 扎哈泉油田扎11井区单砂体评价得分分布

表5 扎哈泉油田扎11井区油砂体分类
扎11井区通过该分类成果结合生产现状优选各类潜力砂体67个,开展了老井转注、水井补孔、分层酸化、调驱等工作量为主体的单砂体注采结构调整工作工作量84 井次。通过调整油水井数比由2.6下降至 2.1,水驱储量控制程度由 78.0% 上升到87.5%,水驱储量动用程度由 55.4% 上升至 58.1%;注水见效井增多,注水见效率由 60%上升至 69.2%,油藏自然递减率呈现下降趋势由33.2%下降至23.4%,油藏调整效果初步显现。
4 结论
(1)利用多因素分类评价法可以实现单砂体的分类评价,使砂体分类由单因素半定量分类变为多因素定量评价,并确保分类结果的唯一性,减少人为因素的影响,使之更加客观、科学。
