基于关系型数据库的网络流数据预处理方法
2021-05-14朱金奇花季伟乔增顺
王 盛 朱金奇 花季伟 乔增顺
(天津师范大学计算机与信息工程学院 天津 300387)
0 引 言
据报道,到2020年将有超过200亿的IoT设备连入互联网[1],这些设备将在网络中产生海量数据流,面对如此巨大的网络流量,如何管理和识别流量数据,并从中准确提取不同设备的分类特征,成为研究挑战,同时也是有效管理IoT设备的关键。准确的流量划分是设备正确分类的前提,设备的正确分类则是网络管理和网络安全的基础保障。
近年来,研究者提出了不同的设备分类预处理方法。文献[2]组合使用tcptrace[3]、C语言和Perl脚本来提取网络流量特征。文献[4]提出了一种IoT设备流量分类与识别工具的构造原型。文献[5]提出在路由器或网关中部署网络包采集器(如wireshark[6]﹑tcpdump[7]),其可以发现网络中所有设备所产生的流量并生成相应的记录输出给上层的预处理程序,同时提供了一种pcap文件流提取工具。文献[8]阐述了一种将全部pcap文件数据转换为ARFF(Attribute-Relation File Format)文件格式的流程方法。然而,文献[2,4-5]仅提出了一种处理方法架构,却没有提供详尽的实现过程。此外,文献[5]的采集方案中没有充分考虑路由器等嵌入式设备的存储容量问题以及运算资源占用过高等限制性因素。文献[8]所生成的ARFF格式文件并不适用于主流机器学习框架Tensorflow[9]等,仅是数据格式的转换,没有网络流统计特征的提取过程。
不同的流量分类需求,会有相应不同的流量统计特征。如设备分类场景的流量特征有固定时段内数据包峰值﹑数据包长度平均值﹑传输协议种类数量等;在网络安全分类场景的流量特征一般会有服务类型﹑一段范围内的连接请求数﹑连接持续时间及登录尝试失败数等。在UCI[10]网站上,公开了许多预处理后的标准数据集,其中包括经典的KDD Cup99流量分类数据集,一个经典的数据集需要对原始pcap流量数据进行相当多的预处理工作,包括从海量数据中去除无效记录(噪声)﹑填补空值﹑计算统计值等,良好的预处理效果是能够准确分类的前提。虽然KDD Cup99是一种可供公开下载的数据集,但并没有公开任何文档或资料来阐述该数据集的构造实现过程。这就造成如果要使用自采集的pcap流量文件训练机器学习模型,必须首先自己实现一套流量特征提取方法,但该方法也只对应于该自采集流量文件的分类场景,从而造成不同分类场景下的自采集流量文件预处理过程的重复性开发,缺少一种可复用的公开实现方法。
针对上述问题,本文主要工作如下:1) 实现了一种通用性的网络流量数据集构造方法,对于常用流量统计特征进行了模块化抽象,对于不同的流量分类场景可以模块化拼装统计特征,从而快速完成特征提取任务,极大提升了流量预处理工作的提取效率,填补了原始pcap采集文件至Tensorflow模型训练输入文件(CSV)之间的衔接处理过程;2) 提出了一种特征提取库的模块化思想方法,通过构建特征提取库可以不断完善和积累不同分类场景下的流量统计特征,这一构建思想可以不断提升本文方法的通用性和健壮性。通过在公开的pcap原始数据集上的实验,实现了针对该数据集统计特征提取的预处理需求。实验结果表明,本文处理流程和方法能够有效解决pcap网络流统计特征的提取,进而完成设备流量数据集的预处理工作。与现有方法相比,本文完整阐述了整个预处理流程并公布了核心代码。
1 相关工作
目前主流网络流量分类方法有三种,分别是基于应用端口号的分类方法、基于包载荷的深层包检测(DPI)技术[11]分类方法、基于流统计的分类方法[12-13]。
基于端口的分类方法是根据IANA[14]上所列出的全部公开使用的端口号与流量包头中的端口号进行比对,从而判断流量所属的应用类型。例如,HTTP协议的Web应用使用固定的80端口,DNS域名解析服务使用53端口等。文献[15]提出了一种基于端口连接模式与并发连接数量的流量分类方法。文献[16]提出了一种使用端口号对UDP流量进行分类的方法。随着网络应用的不断增多,这种通过简单比对固定端口号的方式,已经很难满足流量分类需要,尤其是P2P应用普遍采用动态端口的方式以及端口伪装技术[17]的出现,造成基于端口识别的方法的准确性不高。
基于深层包检测(DPI)技术的分类方法是使用数据包中的全部载荷内容(payload)来对流量进行识别和分类,通过检查包中所含有的一些特定字符或模式,来判定其所属的流量类别。该方法仅需对组成网络流的前面若干个数据包进行检测就可以完成识别任务,因此可以在流量产生早期就完成分类。文献[18]使用一种随机森林算法与内容包检测技术相结合的分类方法,并且使用了文献[4]中所提出的一种支持物联网流量分类的监控体系结构作为统计特征提取工具。文献[19]简要介绍了DPI中的挑战和一些设计目标,综述了DPI技术的算法实现及相关应用。文献[20-21]提出了一种基于DPI技术的网络管理和分类系统。深度包检测方法由于要对包中数据信息逐一进行比对,当数据量较大时需要花费较长时间,伴随网络通信加密技术的普及,对于包载荷内容的获取也变得越发困难。
基于统计的分类方法是利用不同应用流量之间的特性不同而加以区分,一般使用机器学习算法或神经网络模型对流量特征数据进行训练,经过训练的模型可以捕获到不同应用流量的特征区别从而完成分类。文献[12]对于机器学习在流分类领域的应用进行了详细汇总,讨论了在IP流分类中应用机器学习分类器的关键需求。文献[13]提出了一种统计流量分类的新模式,通过监督和非监督相结合的机器学习技术来发现之前未知的流量应用。文献[22]介绍了一种基于卷积和循环神经网络模型的网络流量分类器。由于基于统计的分类方法仅依赖于网络数据包头信息,如传输字节数﹑网络协议﹑TCP窗口尺寸等,无论从数据可靠性还是获取便利性上,基于统计的流分类方法都是更好的选择。实际上,为获得快速准确的分类效果,不仅取决于深度学习模型及其参数配置,所选取进行训练的流量统计特征也具有重要作用。由于使用的是特征数据,如何在众多的流量特征中根据具体的流分类应用场景(如:IoT设备类型分类﹑恶意流检测[23]分类等)来细粒度地选择和提取出最有效﹑区分度最高的特征集合,往往需要进行大量排列组合的特征工程[24]提取实验,即从原始流量文件(pcap格式)中提取出模型训练所需要使用的统计特征数据(CSV格式),这也是本文预处理过程须解决的问题。
2 方法设计
2.1 流程描述
基于统计的流分类方法较其他两种分类方法有可靠性高﹑不依赖载荷内容的优点,下面介绍了预处理方法针对流分类领域研究较多的包和流这两个不同流量粒度进行统计特征的提取。
流量数据特征一般可分为包特征和流特征。网络流量数据按照划分粒度不同,可以分为包(网络消息传输划分的最小数据块)数据﹑流(具有相同五元组:源IP、源端口、目的IP、目的端口、传输协议的所有包)数据以及会话(包含双向流的所有包)数据,划分粒度依次递增。在流量特征选择和提取过程中会根据具体的流分类应用场景单一使用某种流量数据或组合使用不同粒度的流量数据。
1) 包(Packet)表示为:
P={P1,P2,…,Pi,…}
Pi=(xi1,xi2,…,xij,…)
(1)
式中:P表示流量数据中所有包集合;Pi表示第i个包记录;xij表示第i个包中的第j个属性值(如包长度﹑收发时间﹑传输协议等)。
2) 流(Flow)表示为:
F={F1|t1,F2|t2,…,Fk|tk,…}
Fk={P1|P1∈Fk,P2|P2∈Fk,…,Pn|Pn∈Fk,…}
Pn=(xn1,xn2,…,xnj,…)
P1.xg=P2.xg=…=Pn.xg=…
(2)
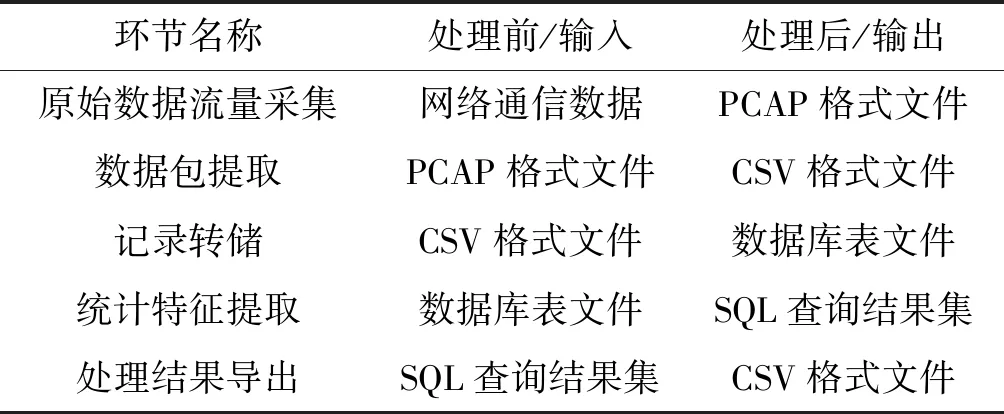
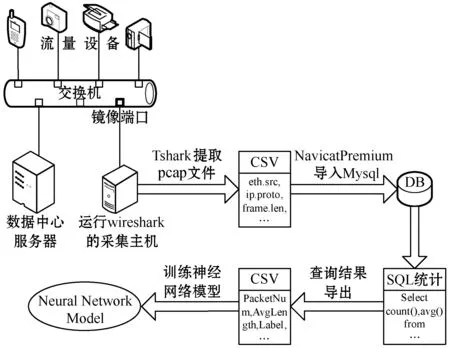
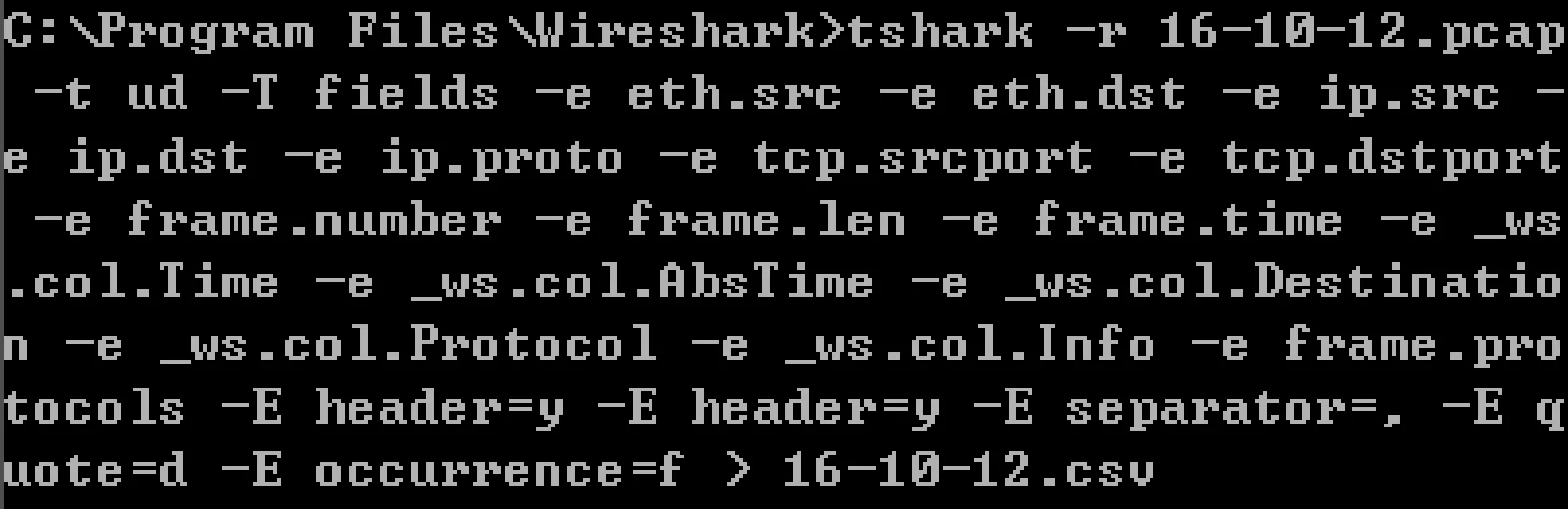
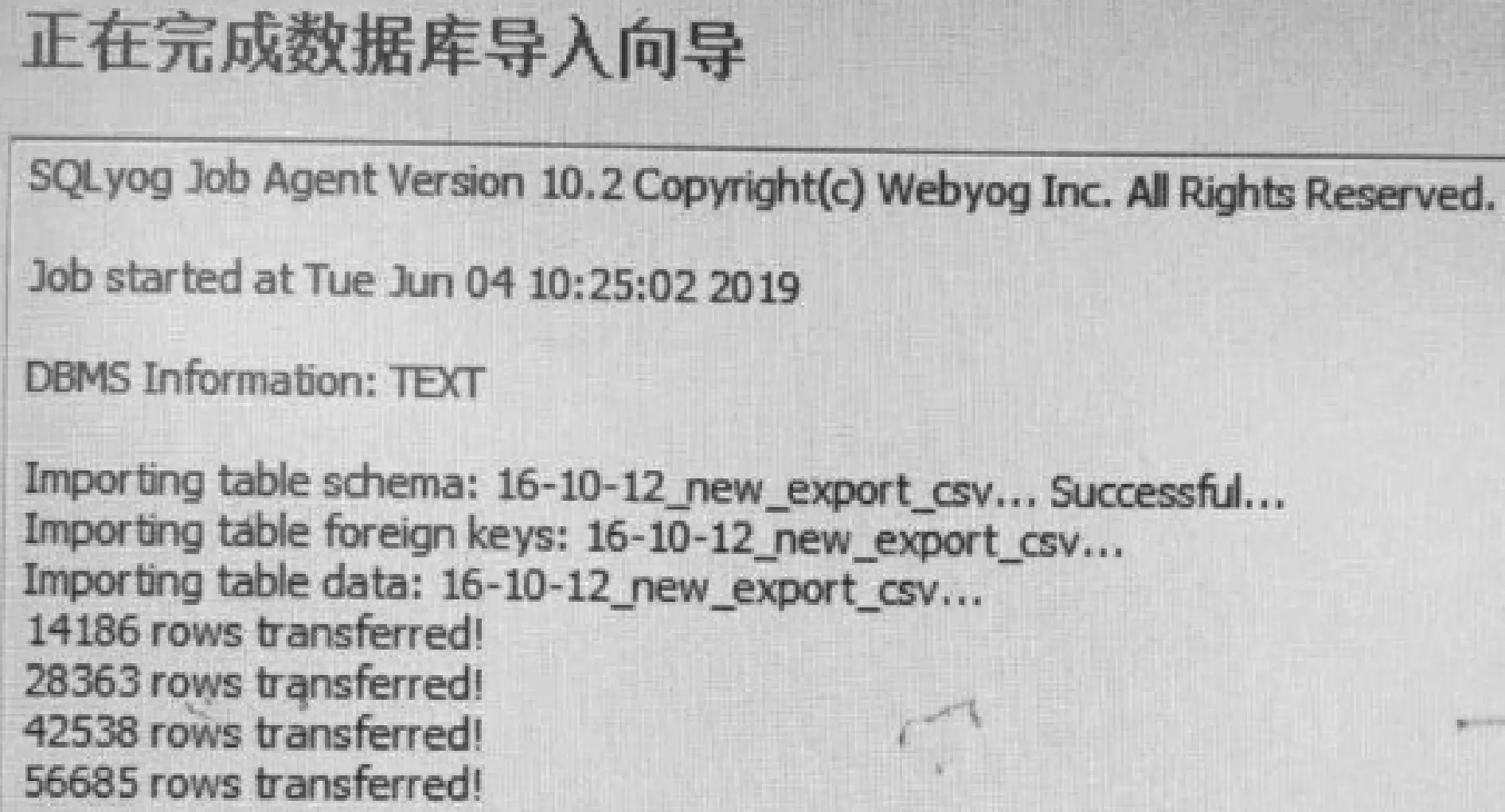
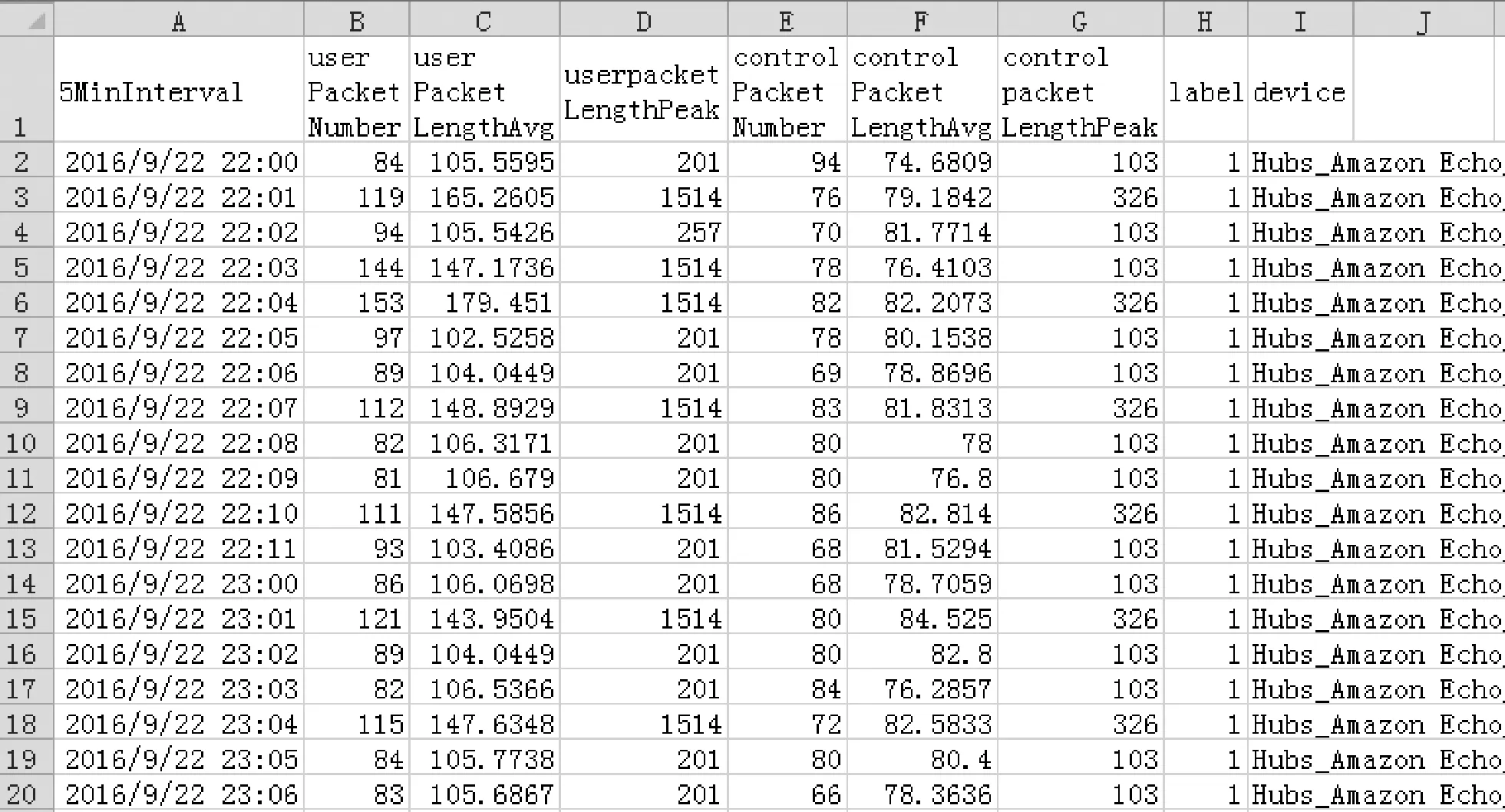
式中:F表示流量数据中划分出的所有流集合;Fk表示组成一个流的所有包的集合;tk表示第k个流中首个包的开始时间(t1 3) 会话(Session)表示和流表示类似,一个会话是由一个流的两个传输方向(五元组中的源和目的互换)所构成,发送流和接收流形成的完整闭环称为会话。若发送流的五元组值为xg={xsrcIP,xsrcPort,xdstIP,xdstPort,xprotocol},则接收流的五元组值即为xg-={xdstIP,xdstPort,xsrcIP,xsrcPort,xprotocol}。 本文预处理过程主要由五个处理环节构成,分别是原始数据流量采集﹑数据包提取﹑记录转储﹑统计特征提取﹑处理结果导出。其总体思想是对统计特征进行规则抽象并与SQL语言进行细粒度绑定,绑定后即形成统计特征提取库,该提取库会随着新的流量分类需求而不断扩充,在实际使用中可以模块化地选取并组合使用特征提取库中的方法。图1描述了特征提取库的构建过程及使用方式,通过不断实现流分类领域的统计特征,每实现一种新的统计特征,就会把该实现方式添加到预处理特征提取库。当进行自采集的pcap流量特征提取时,就可以从预处理特征库中选取已实现的提取方法直接拼装使用,从而高效提取出所需特征。常用的基于流的统计特征有流中所含包个数﹑流持续的时间﹑流的总字节大小﹑流中各个包大小的最大值最小值均值等。在实际统计特征提取时需根据五元组属性值汇总出不同的流,根据不同的分类场景需求,可以进一步对不同的流进行切分并分段统计从而生成流量统计特征,如按固定包数统计则仅提取每个流的前N个数据包,按固定时间段统计则将流中所含数据包按时间戳顺序进行时间范围归并。表1所示的部分示例展示了统计特征规则抽象与特征提取库实现方式之间的对应关系。 图1 特征提取库模块化复用过程 表1 统计特征规则抽象与特征提取库对应关系(部分) 首先在网络拓扑结构中部署流量采集软件,使得采集软件可以发现整个拓扑中所有网络设备的通信数据包,将采集到的原始流量数据(二进制文件)保存至硬盘空间,使用流量分析工具从此二进制文件中提取出所需要的文本数据并存储为CSV文本文件格式,接下来通过数据库管理工具将此CSV文件数据导入至数据库表中,最后由数据库语言(SQL)统计出流量特征数据并导出结果文件。各个环节对原始流量数据依次进行处理,并生成相应的中间状态结果数据,将前一环节的处理结果作为后一环节的数据输入,经过多种数据形态的转换,最终生成所需数据集。各环节数据形式转化过程如表2所示。 表2 各环节处理前后数据形式变化情况 本文提出的网络流统计特征预处理流程及架构如图2所示。本节阐述了从pcap文件采集至最终生成CSV训练数据集的全部处理环节,各详细实现步骤如下。 图2 网络流统计特征预处理流程及架构 步骤一在欲采集的网络中,使用端口镜像技术[25]将顶层交换机上所有网络端口的收发数据转发至其上一个独立的汇聚端口,该汇聚端口连接至数据采集主机,采集主机上安装并运行Wireshark流量采集软件。Wireshark中选取连接汇聚端口的网卡进行数据监听和采集,并设置pcap文件的存储路径及存储规则,如可设置每天或每文件大小达到1 GB等规则进行pcap文件的拆分存储,默认情况下Wireshark会实时采集数据至内存中,如果一次性采集周期较长或网络流信息较大则会造成内存溢出的异常。 步骤二将采集得到的pcap文件,通过tshark命令行工具,自定义提取出所需要的属性(field)值,如五元组值﹑包长度﹑包产生时间等,并存储为CSV格式文件。根据所属协议的不同,Wireshark目前有超过几十万的属性字段(field)可供使用[26],这就要根据不同分类场景的领域知识,灵活甄别选用。 步骤三使用Navicat Premium(或SQLyog)工具,将步骤二生成的CSV文件通过图形化界面操作(新建连接→选择已有或新建数据库→选择表导入向导→导入类型选择CSV文件)导入至MySQL数据库中,成功导入后每个CSV文件对应生成一张同名数据库表。 步骤四打开数据库的查询分析器工具,使用SQL(Structured Query Language)编程语言[27]从数据表中查询汇总出所需的流统计特征值记录,并根据应用或设备的类别(如按MAC地址或协议等属性进行区分)增加相对应的训练标签(label)列。综合运用SQL语言提供的COUNT、AVG、MAX、GROUP BY等函数语句可以方便地进行统计信息值的计算,对于多张数据库表的统计汇总可以使用UNION语句来处理。 步骤五在步骤四的查询结果显示窗口中,通过Navicat Premium工具的导出功能,将预处理后的记录以CSV格式进行导出并作为神经网络模型的训练数据集。 至此整个预处理流程执行完毕。如果使用最终生成的CSV文件来训练神经网络模型没有达到预期结果,可再次返回步骤四尝试其他的统计特征组合,选取效果最优的组合方案。如果步骤三中生成的数据库表字段不足,可以再次重复步骤二,提取出更多种类的数据包属性字段,并继续执行后续步骤即可。在处理步骤二时可以将有价值或较常用的数据包属性值一次性提取出来,在后续步骤中可以选择性使用,从而降低每次实验尝试的复杂度和时间成本。 实验环境在天津师范大学数据中心中进行,该数据中心负责维护校园网网络,拥有校园卡维护系统﹑学生及教职工管理系统、弱电间和教学楼监控安防系统等,各个系统后台服务器通过不同的网络隔离机柜独立部署和运行。 选取监控安防系统作为数据流的采集网络,该网络通过集中器将各楼宇分散的安防设备与数据中心建立连接,每个集中器对应采集温湿度﹑烟雾﹑火焰﹑水浸﹑人体及电能监测共六种传感器设备,集中器的采集端使用485接口连接设备,对上层使用RJ45网口传输数据。每台监控设备自身含有RJ45网口,可以独立上传通信数据。整个网络将监控摄像头和集中器分为两个子网络,子网间由路由器连接并分属于不同的网段,后台服务器通过固定的时间间隔下发数据采集命令,产生通信数据流。整个校园部署集中器和摄像装置较多,表3列出了部分设备及网络配置,图3显示了其中一个监控区域的状态数据。 表3 校园监控及安防系统网络组成设备(部分数据) 图3 设备间房间状态监控 由于该系统为巡检类系统,所有流量设备会根据收到的采集命令定期向服务器上报状态数据,故直接在后台服务器上部署Wireshark软件进行流量采集。服务器操作系统为Windows Server 2008,Wireshark版本为win64-1.10.4,设置pcap文件存储路径为D:wiresharkpackageCapture,当文件大小达到50 MB时进行拆分并使用格式“rawdatas_{序号}_{年月日时分秒(采集开始时间)}”自动命名。部分采集的pcap文件如图4所示。 图4 采集的pcap文件(部分数据) 为了更好地说明本文方法的适用性及便于对比,统计特征提取过程将在公开的pcap文件集上进行实验,该数据集是文献[28]于2018年在网站https://iotanalytics.unsw.edu.au/iottraces上公布的原始流量数据集,数据在物联网环境中进行收集,经过3周多时间共采集了属于7个类别的21种设备的流量数据。文献[5]在该数据集上找到了一组能够明显区分不同设备类别的统计特征属性集合(用户包数量﹑用户包长度平均值﹑用户包长度峰值﹑控制包数量﹑控制包平均值﹑控制包峰值)。下面通过实验完整实现文献[5]中的特征提取需求,以此说明本文方法的有效性和适用性。 首先下载全部2016-09-23至2016-10-12共20天的pcap文件,每天对应一个文件并以对应日期命名。通过tshark工具逐一对20个pcap文件进行属性(field)值提取,并对应生成20个CSV文件,tshark默认与Wireshark软件共同安装在同级目录下,实验所用主机操作系统为Windows 7安装路径在C:Program FilesWireshark下。其中一个pcap文件的完整提取过程代码如图5所示。 图5 tshark提取pcap文件至CSV 将提取出的CSV文件通过SQLyog工具逐个导入MySQL8.0.16数据库,导入过程如图6所示。 图6 CSV转储至数据库 根据需求,需要将数据包按照所属类别进行排序,每个类别中的数据包按所属设备进行排序,排序后每个设备中的数据包再以5分钟的间隔时间进行汇总,统计出每个间隔时间段内的包数量﹑包长度平均值和包长度峰值,并根据每个包传输协议的不同,将上述三个汇总值分别拆分为用户数据和控制数据,最后根据不同类别打上相应的训练标签(label)值。通过SQL语言实现该需求的代码如下: SELECT CONCAT(DATE_FORMAT(′_ws#col#AbsTime′, ′%Y-%m-%d %H:′),IF(FLOOR(DATE_FORMAT(′_ws#col#AbsTime′, ′%i′)/5)<10,CONCAT(0,FLOOR(DATE_FORMAT(′_ws#col#AbsTime′, ′%i′)/5)),FLOOR(DATE_FORMAT(′_ws#col#AbsTime′, ′%i′)/5))) AS5MinInterval, COUNT(CASE WHEN ′_ws#col#Protocol′ NOT IN (′ICMP′,′ARP′,′DNS′,′NTP′) THEN 1 ELSE NULL END) AS userPacketNumber, AVG(CASE WHEN ′_ws#col#Protocol′ NOT IN (′ICMP′,′ARP′,′DNS′,′NTP′) THEN CONVERT(′frame#len′, DECIMAL) ELSE NULL END) ASuserPacketLengthAvg, MAX(CASE WHEN ′_ws#col#Protocol′ NOT IN (′ICMP′,′ARP′, ′DNS′,′NTP′) THEN CONVERT(′frame#len′,DECIMAL) ELSE NULL END) ASuserpacketLengthPeak, COUNT(CASE WHEN ′_ws#col#Protocol′ IN (′ICMP′,′ARP′, ′DNS′,′NTP′) THEN 1 ELSE NULL END) AS controlPacketNumber, AVG(CASE WHEN ′_ws#col#Protocol′ IN (′ICMP′,′ARP′, ′DNS′,′NTP′) THEN CONVERT(′frame#len′,DECIMAL) ELSE NULL END) AScontrolPacketLengthAvg, MAX(CASE WHEN ′_ws#col#Protocol′ IN (′ICMP′,′ARP′, ′DNS′,′NTP′) THEN CONVERT(′frame#len′,DECIMAL) ELSE NULL END) AScontrolpacketLengthPeak, CASEWHEN (IFNULL(′eth#src′,″)=′44:65:0d:56:cc:d3′ OR IFNULL(′eth#dst′,″)=′44:65:0d:56:cc:d3′) THEN 1 WHEN (IFNULL(′eth#src′,″)=′e0:76:d0:33:bb:85′ OR IFNULL(′eth#dst′,″)=′e0:76:d0:33:bb:85′) THEN 2 WHEN (IFNULL(′eth#src′,″) IN (′00:24:e4:11:18:a8′,′70:ee:50:18:34:43′,′00:16:6c:ab:6b:88′) OR IFNULL(′eth#dst′,″) IN (′00:24:e4:11:18:a8′,′70:ee:50:18:34:43′,′00:16:6c:ab:6b:88′)) THEN 3 WHEN (IFNULL(′eth#src′,″) IN (′ec:1a:59:79:f4:89′,′50:c7:bf:00:56:39′) OR IFNULL(′eth#dst′,″) IN (′ec:1a:59:79:f4:89′,′50:c7:bf:00:56:39′)) THEN 4 ELSE -1 END ASlabel, case WHEN (IFNULL(′eth#src′,″)=′44:65:0d:56:cc:d3′ OR IFNULL(′eth#dst′,″)=′44:65:0d:56:cc:d3′) THEN ′Hubs_Amazon Echo_44:65:0d:56:cc:d3′ WHEN (IFNULL(′eth#src′,″)=′e0:76:d0:33:bb:85′ OR IFNULL(′eth#dst′,″)=′e0:76:d0:33:bb:85′) THEN ′Electronics_Pix photo frame_e0:76:d0:33:bb:85′ WHEN (IFNULL(′eth#src′,″)=′00:24:e4:11:18:a8′ OR IFNULL(′eth#dst′,″)=′00:24:e4:11:18:a8′) THEN ′Cameras_Withing Smart Baby Monitor_00:24:e4:11:18:a8′ WHEN (IFNULL(′eth#src′,″)=′70:ee:50:18:34:43′ OR IFNULL(′eth#dst′,″)=′70:ee:50:18:34:43′) THEN ′Cameras_Netatmo Welcome_70:ee:50:18:34:43′ WHEN (IFNULL(′eth#src′,″)=′00:16:6c:ab:6b:88′ OR IFNULL(′eth#dst′,″)=′00:16:6c:ab:6b:88′) THEN ′Cameras_Samsung Smart Camera_00:16:6c:ab:6b:88′ WHEN (IFNULL(′eth#src′,″)=′ec:1a:59:79:f4:89′ OR IFNULL(′eth#dst′,″)=′ec:1a:59:79:f4:89′) THEN ′Switches&Triggers_Belkin Wemo Switch_ec:1a:59:79:f4:89′ WHEN (IFNULL(′eth#src′,″)=′50:c7:bf:00:56:39′ OR IFNULL(′eth#dst′,″)=′50:c7:bf:00:56:39′) THEN ′Switches&Triggers_TP-Link Smart Plug_50:c7:bf:00:56:39′ END ASdevice FROM world.′16-09-23_export_csv′GROUP BY label, device,5MinInterval HAVING label !=-1 /*hereunion other tables*/ ORDER BY label,device,5MinInterval 上述代码实现了2016年9月23日的流量统计特征值提取,其他日期的特征提取,仅需在此代码基础上更换表名后使用UNION语句连接即可。将SQL查询结果导出为CSV文件作为神经网络模型的训练数据集,如图7所示,得到的属性列可分为流量特征和业务特征两类,其中用户包数量(userPacketNumber)﹑用户包长度平均值(userPacketLengthAvg)﹑用户包长度峰值(userPacketLengthPeak)﹑控制包数量(controlPacketNumber)﹑控制包长度平均值(controlPacketLengthAvg)﹑控制包长度峰值(controlPacketLengthPeak)为六个统计特征列,5分钟时间段(5MinInterval)﹑标签类别(lable)﹑标签对应的设备(device)为三个业务特征列,通过六个统计特征列和一个训练标签列即构成了深度学习领域的训练数据集,另外两个业务特征列仅便于人工校验。得到的这六个统计特征列即完整实现了文献[5]所提出的对于设备分类场景区分度最高的一组特征向量。类似地可生成测试数据集,至此完成整个预处理实验流程。 图7 预处理后生成的流量统计特征数据集(前20条) 为了进一步说明本文方法的有效性,将本文方法﹑流量提取工具SDN-pcap-Simulator以及传统Excel统计方式三者进行实现对比。SDN-pcap-Simulator是文献[28]中公开数据集所配套的预处理工具(C语言编写),根据说明其调用方式为bin/sim[pcap-filename][mode]。参数mode有三种模式,分别为0-获取所有IP流﹑1-获取所有NTP流﹑2-获取所有DNS流,通过一条命令可以提取到所有IP包。虽然是与数据集所配套的工具,但其所提供的功能有很大局限性,仅是把解析到的网络流写到一个日志文件里,没有进一步处理且不计算统计特征。作为Office办公软件之一的Excel工具,具有十分强大的数据处理功能,可以操纵和汇总CSV文件格式数据,通过其所提供的数据透视表功能可以手动实现分类汇总的统计功能,但由于Excel同一工作表的记录行有数量限制,在实际操作中提示超出1 048 576行的处理上限,且文件十分庞大操作响应缓慢,这对于动辄数千万记录的pcap包文件,显然已经超出了其处理能力,这就导致传统Excel的预处理方式效率低﹑易出错﹑不易维护。本文方法创新性地提出统计特征规则抽象与特征提取库对应的思想方法,较现有流量提取工具极大地提升了流量特征提取工作的需求通用性,在处理能力和处理效率方面较Excel手动拖曳数据方式有了显著提升,由于结合了关系型数据库及SQL语言的处理优势,后期数据调整的灵活性﹑海量数据的批处理能力和代码的可扩展可复用性均可以得到有效保证。表4为三种预处理方式的效果对比。 表4 三种预处理方式的效果对比 由于SDN-pcap-Simulator在通用性上无法实现定制需求,下面只对Excel和本文方法进行数据处理效率的定量比较。对比的统计特征需求为汇总并提取出不同数据流的包数量和包长度平均值,使用的处理机器配置为Intel i5- 4210M 2.6 GHz处理器﹑4 GB内存﹑64位操作系统,对比数据源选取16-09-23.pcap流量文件,该流量文件中共有947 072条数据包记录。本文方法通过表1中第一项﹑第三项﹑第四项组合实现;Excel方法通过数据透视表设置五元组为行标签,数量和平均值为数值标签来实现。表5显示了两种方法对于上述统计特征需求的处理效率对比,其中统计执行阶段本文方法用时高于Excel方法是由于Excel在数据加载(文件打开)时将数据读取到了内存并写到界面上,等到统计执行时Excel就只在界面上和内存中操作,不用再读取物理文件,因为Excel在数据加载阶段消耗了较长时间,导致了单纯的执行速度Excel会比较快。不难发现由于本文方法采用的数据载体是数据库表,在数据加载和全部处理过程用时上有明显优势,且若对数据字段较为熟悉,可省略数据加载过程用时,直接运行SQL语句统计执行即可,而Excel方法必须经过较长的数据加载过程。 表5 数据处理效率(平均用时)对比 s 本文提出利用关系型数据库提取网络流统计特征的方法,综合运用了网络领域知识和数据库领域知识,并结合了深度学习领域数据集的构建格式[10],完成了从原始pcap流量文件至神经网络模型训练文件之间的预处理转换,实验结果显示了该方法具有很好的实用性和普适性。未来可以进一步改进为动态SQL结合SP(存储过程)的方式,从而提升大批量pcap文件的处理效率和自动化程度。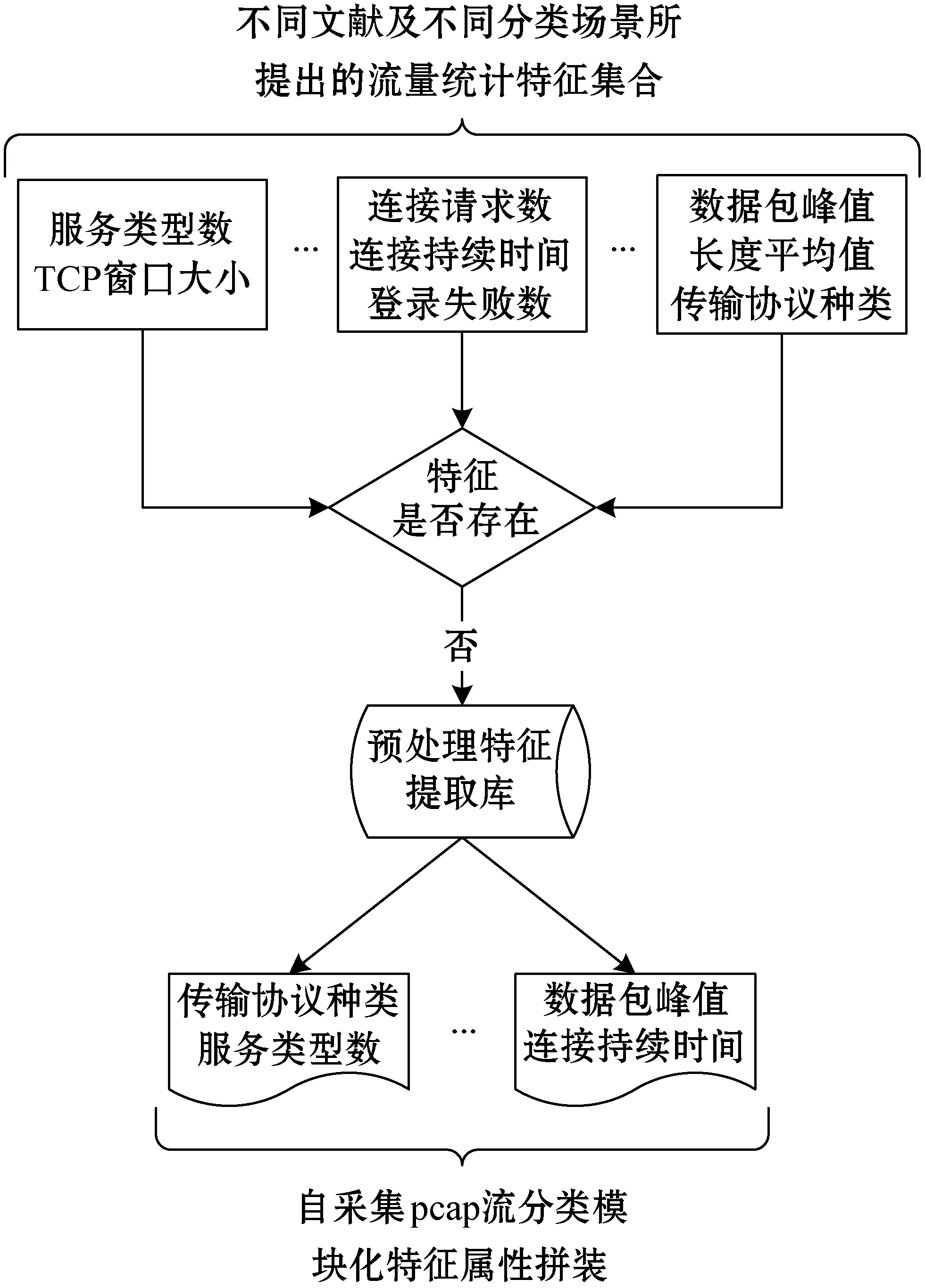

2.2 数据交互与实现方法
3 实 验
3.1 网络数据流采集


3.2 统计特征提取
3.3 方法对比

4 结 语
