基于特征扩展的网构软件测试数据分类模型构建
2021-05-12王钰,刘磊
王 钰,刘 磊
(北京科东电力控制系统有限责任公司,北京 100085)
目前,网构软件测试数据具有数量庞大、种类多、结构复杂等问题[1]。传统的数据分类方法对相近数据不能准确分类,给数据的搜索和查询带来困扰,将海量的网构软件测试数据进行精准划分成为当前数据管理的一大难题[2-3]。文中通过构建基于特征扩展的网构软件测试数据分类模型,明确模型的工作流程,采用特征扩展算法生成数据特征向量空间,通过计算数据的权值和表达能力准确分类,能够处理相近数据,根据数据的特征量进行准确分类,有助于加强对数据的管理且对数据的处理速度较快,适合未来互联网的发展。
1 网构软件测试数据分类模型
基于特征扩展的网构软件测试数据分类模型如图1 所示。
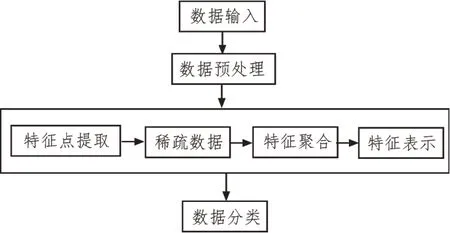
图1 网构软件测试数据分类模型
从图1 可以看出,对于网构软件测试数据,其特征分类包括以下步骤:
1)对于输入网构软件测试数据,提取其特征点,得到的数据特征点集合为F。
2)根据特征扩展算法,利用稀疏分解算法稀疏网构软件测试数据,得到的稀疏数据集合为D,集合F和集合D的关系为:F=nD。
3)聚合所有的稀疏数据,生成数据集W,则W=Pooling(F)。
4)采用平方根聚合方法对数据进行聚合处理,聚合计算的公式为:
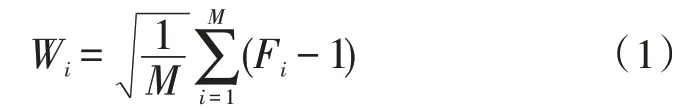
其 中,Wi表示稀疏数据W的第i个元素,m为输入网构软件测试数据中的特征点总数;Fi表示稀疏数据Wi在特征点集合F中的第i个特征点,在对所有稀疏数据进行聚合后,得到的数据稀疏向量表示为:
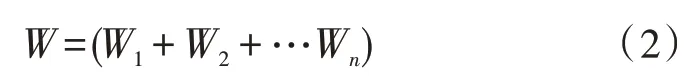
根据稀疏数据的表达进行网构软件测试数据的分类,采用概念树、权值计算和表达计算,表现网构软件测试数据的特征,根据数据特征进行分类和保存[4-5]。
5)将保存的网构软件测试数据进行编号,方便提取和查询。
基于特征扩展的网构软件测试数据分类模型具有以下优点:首先模型将网构软件测试数据特征映射到向量空间,有利于特征扩展和表现;其次,通过精准计算,能够减少分类误差,且计算速度较快,提升了数据关联度处理能力;最后,数据分类后在各个数据库上标注类别和编号,有利于后期的数据调取和查询[6-7]。
2 基于特征扩展的网构软件测试数据分类方法
2.1 特征扩展算法
输入:网构软件测试数据,生成待测数据文件。
输出:网构软件测试数据特征扩展之后的特征向量空间[8-10]。
1)对于待测网构软件测试数据中的任一个特征项,计算特征项的最小置信度和最小支持度,计算公式如式(3)和式(4)所示。
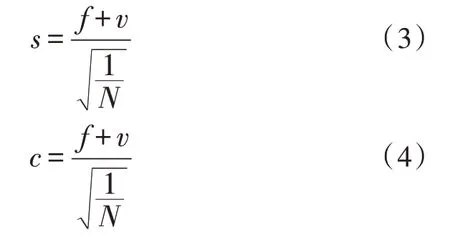
式中,f表示总体真值;v表示标准真值;N表示待测网构软件测试数据总数量;
2)将具有最小执行度和最小支持度的特征项生成查询特征共现集,将查询特征共现集中的网构软件测试数据定义为规则特征项,计算每个项的规则度,规则度H的计算方式如式(5)所示。
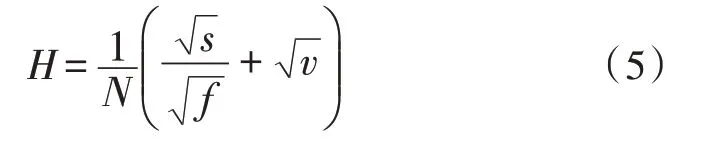
3)若H值大于设置的规则度阈值,则可认为该规则特征项为规则项;若在查询特征共现集中存在唯一规则项,将执行步骤4);若存在两个或两个以上规则项,将执行步骤5);
4)将唯一规则项列入特征空间集中;
5)匹配网构软件测试数据特征;
6)特征空间集中的数据生成特征向量空间,继续计算下一组网构软件测试数据[11-13]。
2.2 网构软件测试数据分类
经过特征扩展后的网构软件测试数据特征向量存在较多的干扰因素,由于网构软件测试数据之间的相似度,影响了网构软件测试数据的特征表达能力,数据分析能够提升数据的表达能力,更利于实现数据分类和查询[14-15]。
首先,概念树通过数据的属性分析进行其数据的概念描述,定义网构软件测试数据的属性权值公式如式(6)所示。
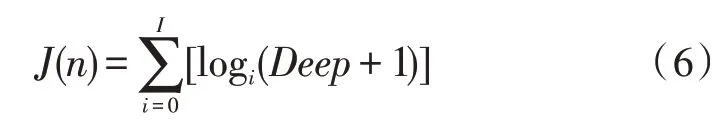
其中,n为该数据在概念树中的位置;I为概念树的编号总集;Deep表示该数据在概念树中的重要性;在公式中加1 的目的在于调节网构软件测试数据的权值,使权值始终为正,避免权值为负导致的复杂计算[16]。
由于数据具有相似性,相似数据间差别不大,为对数据进行精准分类,在计算过网构软件测试数据的权值后,对其表达能力进行计算,如式(7)所示:
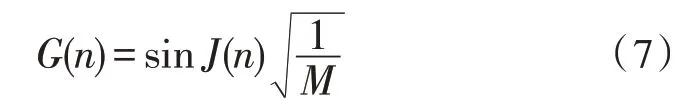
根据网构软件测试数据的表达能力,将其特征值充分表达,根据表达特征值的不同进行合理分类。
3 实验与研究
文中实验研究利用构建的网构软件平台作为实验研究中心,以网构系统为关键计算单元进行平台开发,集成符合FIPA 标准的网构测试数据分类空间,对该空间进行自主性开发与自适应演化检测。采用Spring 平台,支持实验中的分类模型自适应设计操作,同时供给模型构建图形化界面、构架代码研发、分类模型管理等工具,在模型构建的过程中时刻连接外部接口API。构建的实验检测平台框架如图2 所示。
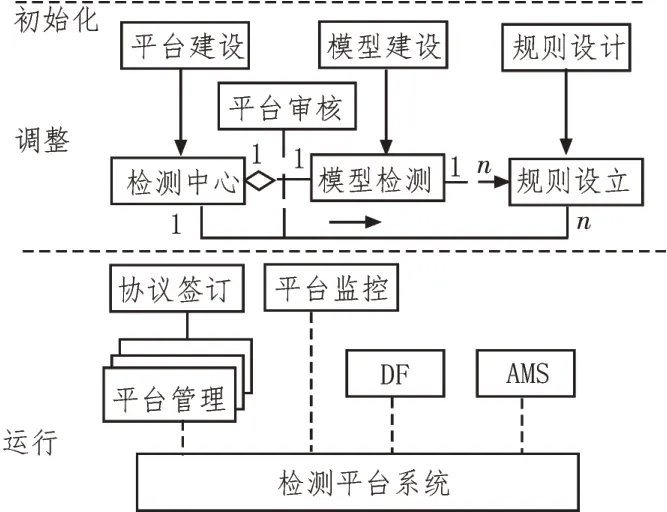
图2 实验检测平台框架图
实验过程中的操作平台分为两个层次:实验运行层与构建结果检验层。平台内部包含AMS 部件,负责内部平台实验数据信息间的通讯、数据分类信息管理以及平台运转生命周期的管理。
在实验组集中引入特征项共现,有效扩展测试数据的测试特征。获得深层模型的测试含义,利用数据共现模型对网构软件测试数据进行平台共享操作,将共享功能与实验检测平台的网络任务相连。在大规模的数据实验收集中,对于两个经常出现的测试指标,应将其转录至统一平台窗口单元中等待检测处理。当经过检测处理后的单元窗口产生数据共组现象时,则表示被检测的测试指标在意义上有着较为密切的关联。共现概率越高,表明数据间的相互关联系数越高。
依照关联程度对经过分类模型分类后的数据相似度进行对比,并构建实验对比图。将数据共现模型引入分类特征扩展中,挖掘训练集特征组合与样本集特征组合间的关系。利用FP 算法计算特征项组合共现数值,将特征项组合看作事务项,测试数据看作事务,可以在给定的最小支撑度阈值与置信度阈值之下找出组合的特征项数据间的关联关系原则,关联关系下的关系原则可表示特征项数据的共现程度,由此获取相应的分类程度。分类数据相似度对比如图3 所示。
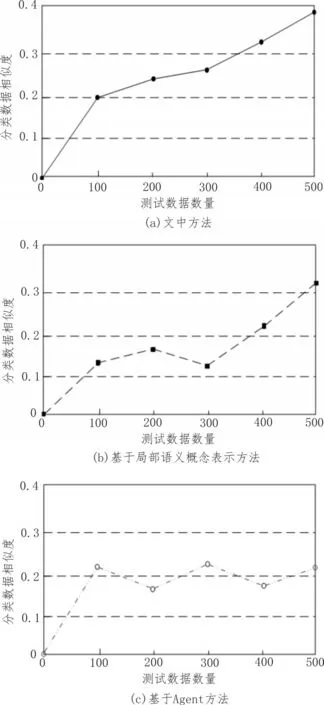
图3 分类数据相似度对比图
根据图3,文中基于特征扩展的网构软件测试数据分类模型构建方法的分类数据相似度明显优于传统方法的分类数据相似度。由于文中构建方法引用DF 部件在测试数据内部调节网构软件的组件形式,结合EBDI 结构绑定分类模型关系,根据模型实体测试信念以及动作更改信念组成分类集合与动作集合,时刻掌握网构软件的调整状态。在算法操作伊始,转变选择函数操作意图,及时反映测试数据的测试环境,排除测试阻碍因素,具有良好的数据共现数值。随时调整测试指标,将标准指标与测试数据相融合,在特征扩展的环境中分析扩展特征项与数据集合间的关系,提高对关系的管理力度。实施动态演化运行机制,给出一致性操作原则与分类管理原则,固定分类模型的构建步骤,防止步骤错乱导致模型构建失误。由此,获取严谨科学的模型构建数据,提升其最终测试的分类相似度。
在分析所构建模型的分类相似度后,研究文中方法的召回率。在实验空间中输入特征共现集数值,设置关联规则抽取阈值,并管理阈值的设置范围,控制阈值数值处于10~100 之间。在经过测试数据特征扩展后,对信息进行分类并将其输出至特征向量空间中。在测试数据集中的任意一个特征项组合中,若在实验查询的过程中产生共现集,则表示该过程存在唯一的一个规则项信息。
此时,提升设定的阈值参数数值,直至其数值大于标准阈值参数数值,执行关联规则右部的特征项信息。在接收控制检验的实验空间中配置SVM分类器,同时提升分类器的操作效率,防止因设备改变而产生的数据分类失败状况。交叉验证处于不同位置空间测试数据分类模型的运行状态,当运行状态的动力供给量较小时,将分类模式调整为低级模式,当运行状态的动力供给量较大时,将分类模式调整为高级模式。由于测试的数据设计网构软件的内部系统运行操作,为此,在对测试数据进行调整后方可执行检测指令。
在实现以上操作后,对分类得出的召回率进行对比,得到召回率对比如表1~3 所示。

表1 文中方法召回率

表2 基于局部语义概念表示的方法召回率

表3 基于Agent方法的召回率
从表中可以看出,文中基于特征扩展的网构软件测试数据分类模型构建方法召回率指标均高于其他两种模型构建方法,表示文中方法的分类性能更高,有利于分类模型的构建。文中在分类模型构建的同时调节算法分析状态,动态绑定模型信息,具有良好的模型掌控性能,可在产生分类准则的前提下执行分类指令,提升整体分类标准,获取更高的分类结果。
4 结束语
文中构建的基于特征扩展的网构软件测试数据分类模型能够有效解决数据的分类问题,不仅为数据的提取和查询,而且为其他领域数据的管理提供了借鉴方法,拓宽了特征扩展的应用领域,更促进了我国大数据技术的发展。实验结果表明,文中基于特征扩展的网构软件测试数据分类模型构建方法可及时调节分类模型信息,利用特征项寻找共现指标,由此获取较优的分类效果,具有良好的发展前景。
