基于数据挖掘技术的私有云在教育领域上的应用
2021-05-11郑慧杰李新解玉衡
郑慧杰 李新 解玉衡

【摘要】 在过去的几年中,云计算已经在各种各样的项目中得到了广泛的应用,这为研究和发展教育行业提供了新机遇。可动态部署的虚拟实验室环境的形式出现,为教育机构的计算资源分配提供了更大的灵活性。在完全沙盒实验室的形式下,学生可以获得“他们自己的”内部网络和对内部所有机器的完全访问权,这使他们能够灵活地收集构建基于异构大数据技术的体系结构的实践经验。本文利用EDUCloud提供了一个私有的云基础设施,可以将本文中描述的数据挖掘技术实验室灵活的进行部署。
【关键词】 数据教育 私有云 虚拟实验室 EDUCloud
Abstract: In the past few years, cloud computing has been widely used in a variety of projects, providing new opportunities for research and development in the education industry. The emergence of a dynamically deployable virtual laboratory environment provides greater flexibility in the allocation of computing resources in educational institutions. In the form of a full sandbox lab, students gain “their own” internal network and full access to all internal machines, this gives them the flexibility to gather the experience of architectures,that is based on heterogeneous big data technologies. This article uses EDUCloud to provide a private cloud infrastructure that allows the data mining labs described in this article to be deployed flexibly.
Key words:Data Education; Private Cloud; Virtual Laboratory;EDUCloud
引言
2010年在加特纳新兴技术宣讲会上,云计算,特别是私有云计算达到了“预期膨胀的顶峰”。如今这项技术已经被广泛接受,但由于其基本概念的多功能性,云计算不仅为商业提供了机会,也为教育和研究应用提供了机会。在专注于教育和研究的机构,供个别学生或小组使用的计算资源非常有限,大多数资源只能以共享的、预先安装的环境的形式提供,通常一次可供多个讲座使用。虽然这在本质上降低了硬件和人员成本,但也要求对学生帐户施加非常严格的权限,以防止用户相互影响,从而有效地限制了练习和项目的可能性。在讲授数据概念和技术时,授予学生对某些系统的管理权限对于让他们收集有关系统、存储和网络配置更改的影响的第一手经验至关重要。面对这一情况,云计算可以提供一种由特殊的虚拟机(VMs)组成实验室的方法,虚拟机(VMs)被按需分组,虚拟机组及其网络在沙盒环境中运行,这些环境具有动态分配和可扩展的资源,可以很容易地运行在不同的讲座或实验。
本文以EDUCloud体系结构为基础,它是一个用于数据分析、分布式系统(包括分布式信息系统)的讲座和实验室。它是面向服务的教学,特别是微服务体系结构,而本文的创新点是教学EDUCloud中面向数据技术的部分。在实验室中进行了初步的数据相关训练,这些训练侧重于基于Apache Hadoop和Apache Spark等技术的数据挖掘和数据分析。对数据挖掘技术的关注以及关于初步经验训练是本文的另一个创新点。
在国外最新的文献中[1-5]可以看出,各大高校在其教育项目中使用云计算的场景正变得越来越多样化。从通用的、协作的软件即服务(SaaS——Software-as -a-Service)平台(如谷歌的G教育套件[2]),再到专门的平台,例如用于教授高性能计算[3]或R平台和Scilab平台[5]。在文献[5]中提到的CloudIA平台,它可以在单个系统中提供SaaS、PaaS(Platform-as-a-Service)和IaaS(Infrast ructure-as-a -Service)的組合服务,在混合云环境中运行,并根据需要扩展到Amazon Web服务。在PaaS中的重点在于使用学生和讲师可以访问的自助门户对单个虚拟机进行ondemand部署。但是,如果没有将它们与定制的内部网络结合在一起的概念,那么使用它们来建立一个功能齐全的微服务实验室是不切实际的。
本文的其余部分结构如下:第二节概述了数据和服务实验室场景提出的需求;第三节描述了系统的体系结构;第四节详细介绍了数据挖掘实验室的设置和其中使用的技术,得出实验中存在的问题;第五节为从该项目中得到的结论,最后对未来的工作进行了展望。
一、场景需求
为了实现给学生提供一个虚拟实训实验室的目标,整个系统的不同部分必须满足许多需求(需求标记设定为RQ1到RQ8以便于参考)。虽然其中许多是由服务场景本身强加的,但也有一些源于围绕云本身的基础设施。由于数据技术(如分布式数据库系统)或数据处理方法(如Map Reduce)在分布式信息系统中经常使用,因此提供一个允许学生在多台计算机中运行此类技术的实验室(RQ1)。学生可能需要自行安装数据库系统等软件,因此他们需要具有完全的根访问权限(RQ2),允许他们安装任意组件或部署容器(例如Docker)来进行与数据相关的练习。
当为用户提供类似上述根级访问的广泛权限时,关键是要防止每个虚拟实验室实例对其他虚拟实验室实例造成不利影响(RQ3),同时仍能在其计算机和学生计算机之间实现完全网络访问(RQ4)。此外,应该可以为集成练习(RQ5)在各个实验室之间创建有限的连接,并在严重错误配置(RQ6)的情况下重置实验室实例。由于数据技术实验室的重点是教学分布式大数据以及数据挖掘和分析相关概念,因此它应该提供一些典型的分布式数据集处理、分布式数据存储、分布式事务处理和分布式数据查询(RQ7)的技术。在其初始版本中,重点应放在分布式数据挖掘相关技术上。为了减少创建和运行任意数量的实验室实例所需的管理工作量,系统应与预先存在的身份验证基础设施(LDAP——Lightweight Directory Access Protocol)(RQ8)集成。
二、系统体系结构
EDUCloud目前的实施基于VMware vCloud Director(vCD)[6]以及附带的产品,如ESXi(Hypervisor)和vSphere,这是因为它预先存在的基础设施和使用此技术堆栈的一些经验。由于这引入了某些特定于平台的限制和要求,EDU Cloud系统的架构概念(见图1)被设计成防止供应商锁定,图1详细说明了单个虚拟实验室(蓝色)和公共服务(绿色)之间的连接。pfSense节点(橙色)也可以作为因特网或其他内部网络的网关。这是通过尽可能避免对特定于平台的特性的依赖,保持实验室设置的概念和主要部分(尤其是虚拟机本身)在不同供应商之间可移植来实现的。
vCD中的实验室以vApp的形式反映出来,vApp由一个或多个VMs(RQ1)及其网络组成,包括内部网络以及与外部网络的连接。因此,每个实验室都有自己的内部网络,将虚拟机相互连接(RQ3),而无需从实验室外部直接访问任何虚拟机。唯一例外的是,所有EDUCloud实验室中都有基于pfSense的[7]网关虚拟机,它充当网关和OpenVPN服务器,允许学生加入内部网络并提供互联网接入(RQ4)。
在其他情况下独立的vApp之间建立连接可以通过在讲座中添加Common Services vApp来提供,这将创建到所有其他站点的点对点VPN连接讲座中的实验室。虽然CommonServices本身可以提供额外的服务,但其pfSense实例也允许被连接实验室使用网络地址转换(RQ5)提供服务。
三、实验
vCD和pfSense都允许使用认证提供者(RQ8)的LDAP基础设施,EDUCloud使用vCD中的权限系统来管理授权,因为目录是作为只读资源提供的。然后,使用访问vCD API的Java客户机将单个vApp的权限同步到相应的pfSense实例。作为一种替代方法,授权可以完全通过LDAP来处理,即使用于身份验证的目录是只读的,也可以使用中间身份和访问管理解决方案,如Keycloop[8],它由EDUCloud管理员控制。所有vApp均从存储在目录中的模板实例化,可以根据需要在各个讲座之间共享。每个模板代表实验室中所有VMs的完整快照,从而可以轻松部署其他实例,以及在发生致命错误配置(RQ6)的情况下将现有实例重置为原始状态。作为此潜在破坏性操作的替代方法,这将导致丢失所有尚未事先备份的工作,还可以在执行有风险的操作之前创建已部署实验室实例的快照。
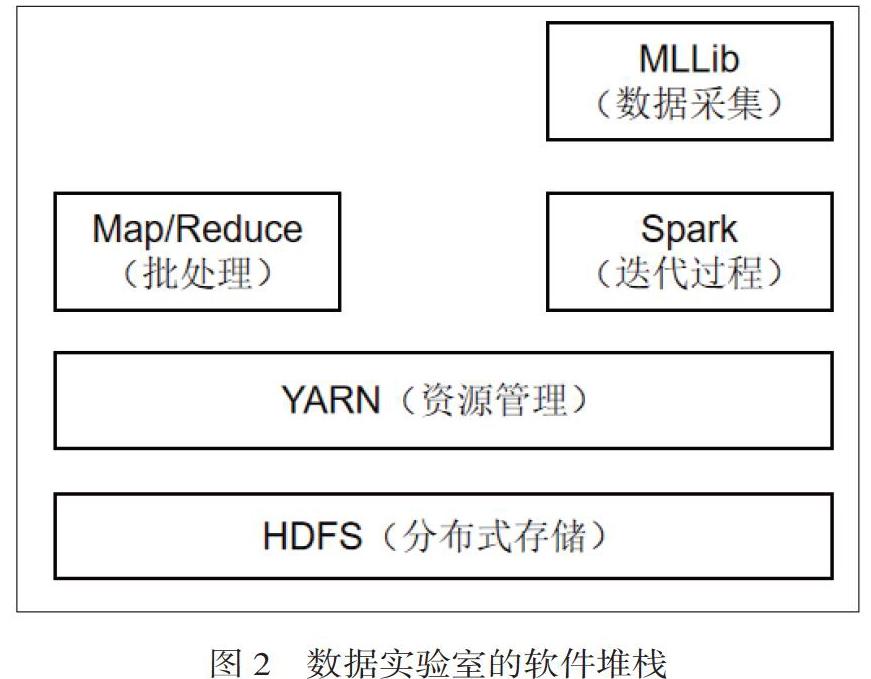
EDUCloud内的数据实验室的目标是为学生提供动手操作的环境,以在分布式大数据处理(包括分布式存储,数据处理和数据挖掘)上获得实践经验。拥有一个分布式环境也很重要,该环境还允许探索与分布有关的问题,即节点故障。作为存储数据的基础,我们使用了受GFS启发的Apache Hadoop和包含的HDFS文件系统[9]。HDFS是面向块的复制文件系统。每个组vApp中使用一个实例,在公共服务vApp中使用一个实例。这个想法是给每个小组自己的分布式文件系统进行实验。在此,该组具有完全权限,并且可以在不干扰其他组的情况下存储,更改和删除数据。甚至允许以例如存储复制因子为3的文件,探索文件副本块的位置并关闭某些节点。
下一层是通用数据处理框架。Apache Hadoop附带了Map / Reduce [10],它可能是该领域中最知名的框架,尽管由于处理步骤之间的磁盘I / O繁重而导致了已知的限制和性能问题。此外,使用Apache Spark [11]作为Hadoop的替代方案,支持对存储在所有群集节点RAM上的数据进行内存内处理。同时安装两个框架可以教给学生这些问题。对于Hadoop和Spark,都使用YARN [12]作为资源管理器。
这两个系统都预先安装在每个组vApp上,使学生可以直接开始与数据处理相关的练习。他们具有对自己的集群的完全root訪问权限,因此他们还可以使用Hadoop或Spark的配置运行实验。万一它们使安装崩溃,则可以安装vApp模板的新副本。
以下是具体实训:
实验1: Warm up
本实验的目标是学习如何使用环境,设置所需的VPN连接以及通过存储和检索文件来获得HDFS的初步经验。HDFS Web UI用于浏览文件块及其副本的物理位置。
实验2:Map/Reduce
在本实验中,学生必须实施两个基本的Map / Reduce工作才能学习Map / Reduce的思维方式。第一项任务是经典单词计数问题的简单变体,并进行了一些预处理以避免复制可用的解决方案,而第二项任务则更为复杂。必须评估包含友谊数据的数据集,以找到每对人的所有共同朋友。该设置需要两个Map / Reduce作业才能顺序运行。
实验3:Spark
这里的重点是获得Spark的经验并比较Spark和Map / Reduce。该任务是使用Spark重新实现Lab 2的第二个任务。由于spark允许更自然的计算链接,并且对数据具有更丰富的基本操作集,因此该解决方案更易于理解。另一个目标是比较运行时并了解Spark和Map / Reduce之间的体系结构差异。
实验4:Iterative jobs
该实验室专注于迭代作业,这在Map / Reduce中通常是有问题的。迭代作业的典型示例是K均值聚类。该算法计算新的群集质心,并在每一轮中将所有点分配给这些质心。该任务是使用131 Map / Reduce和Spark两次实施此算法。 Map / Reduce版本通过在每次迭代中将多个中间结果写入磁盘来产生大量I / O。Spark版本可以将所有数据保留在内存中,并分布在整个群集中。
实验5:Failure tolerance
在分布式设置中,节点或链接故障是日常操作的正常部分,每个分布式作业都必须能够解决此类问题,而无需重新启动整个作业。因此,故障管理(包括在其他节点上重新启动部分工作并使用检查点数据的能力)是框架的重要组成部分。在本实验中,学生将探索这些功能,并比较Hadoop和Spark的容错能力。学生将数据存储在HDFS中,通过停止VM杀死数据节点,并探索在中断期间和重新启动发生故障的节点之后会发生什么情况。此外,运行Map / Reduce和Spark作业会遇到节点故障。
实验6:Data Mining
通常,数据学家不会实现基本的数据挖掘算法。标准方法是使用软件包或库提供的现有实现。在这些练习中,学生探索基于Spark的MLLib [13],以使用决策树和逻辑回归等算法运行分类任务。
在该项目的高峰期,大约有15名学生在三个小组中平均每周工作1.5天,在实验过程中出现了以下的问题:由于数据库日志太大而造成冻结云;学生的初始设置不正确:他们采取了“便捷的方式”,因为他们没有足够仔细地查看设置建议,这确实在项目中期对他们造成了很大的影响;不兼容/部分完整(子)产品版本等。
四、结论与展望
EDUCloud提供了一个可靠的,可扩展的私有云解决方案,用于托管虚拟实验室,这些虚拟实验室用于教授微服务和计算机科学领域的其他主题。它为学生提供了对沙盒环境中的虚拟机和网络的根访问权限,从而获得动手实践的经验。同时,它可以使讲师和导师以最少的管理工作来设计更复杂的运动任务,因为可以轻松地从预制模板中实例化新实验室。已经提供了一个专门的实验室设置作为在EDUCloud上运行的虚拟实验室的示例,用于教授(可能很大的)数据挖掘和分析的EDUCloud概念。
该实验室为学生提供了用于数据挖掘实验开发的预配置堆栈,利用诸如Apache Hadoop和Apache Spark之类的技术来展示數据挖掘和分析特定的技术和模式。单个实验室中两个堆栈的存在以及已部署实验室实例的互连性也为学生群体之间的比较练习提供了机会。
尽管EDUCloud已经能够跨多个服务器进行横向扩展,但其当前实施方式将其限制为私有云功能。 当例如由于调度问题而必须并行运行大量实验室实例时,这可能变得特别具有挑战性,这可能超出可用硬件的计算资源。为了缓解这些问题,即将到来的项目包括将EDUCloud迁移到混合云概念,使其可以按需使用公共云资源进行横向扩展,同时保持对敏感应用程序的隐私保护。迁移的一部分是对开源虚拟化平台和框架(例如Proxmox [14],尤其是OpenStack [15])的评估,后者将允许与各种公共云提供商进行无缝集成。VMware组件是当前系统唯一的专有,封闭源代码部分,切换到这些解决方案之一可以使EDUCloud的整个堆栈仅在开源软件上运行。除此之外,进一步的研究主题包括为计算机科学的其他领域开发新的实验室概念,提高平台的弹性和改善资源调度。后者目前由人工处理,并计划通过将其与实验室和讲座的实时时间表同步,并将其与预定平台集成以处理项目和其他活动而实现自动化。特别是在EDUCloud的数据技术相关部分中,我们还计划包括针对传统分布式关系数据库管理技术的实验室,例如,有关数据分段,复制,分布式查询处理和分布式事务的技术和练习。另一个实验室应涵盖不同的NoSQL范式和数据库管理系统。
参 考 文 献
[1] Fenn, Jackie & Lehong, Hung. (2011). Hype Cycle for Emerging Technologies, 2011.
[2] Google for Education:[J]. Google, 2012.
[3] S. S. Foley, D. Koepke, J. Ragatz, C. Brehm, J. Regina, and J. Hursey, “Onramp: A web-portal for teaching parallel and distributed computing,” Journal of Parallel and Distributed Computing, vol. 105, pp. 138–149, 2017.
[4] K. Chine, “Learning math and statistics on the cloud, towards an ec2-based google docs-like portal for teaching / learning collaboratively with r and scilab,” in 2010 10th IEEE International Conference on Advanced Learning Technologies. IEEE, 2010, pp. 752–753.
[5] F. Doelitzscher, A. Sulistio, C. Reich, H. Kuijs, and D. Wolf, “Private cloud for collaboration and e-learning services: From iaas to saas,” Computing, vol. 91, no. 1, pp. 23–42, 2011.
[6] Cartwright H . VMware vSphere 5.x datacenter design cookbook over 70 recipes to design a virtual datacenter for performance, availability, manageability, and recoverability with VMware vSphere 5.x[J]. 2014.
[7] Krupa C. Patel, and Dr. Priyanka Sharma. “A Review paper on pfsense – an Open source firewall introducing with different capabilities & customization.” International Journal Of Advance Research And Innovative Ideas In Education 3.2(2017) : 635-641.
[8] Chen W . Does the Colour of the Cat Matter? The Red Hat Strategy in Chinas Private Enterprises[J]. Management & Organization Review, 2010, 3(1):55-80.
[9] S. Ghemawat, H. Gobioff, and S.-T. Leung, “The Google File System,” in Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles, ser. SOSP 03. New York, NY, USA: ACM, 2003, pp. 29–43.
[10] J. Dean and S. Ghemawat, “MapReduce: simplifified data processing on large clusters,” Communications of the ACM, vol. 51, no. 1, pp. 107–113, 2008.
[11] M. Zaharia, R. S. Xin, P. Wendell, T. Das, M. Armbrust, A. Dave, X. Meng, J. Rosen, S. Venkataraman, and M. J. Franklin, “Apache spark: a unifified engine for big data processing,” Communications of the ACM, vol. 59, no. 11, pp. 56–65, 2016.
[12] V. K. Vavilapalli, A. C. Murthy, C. Douglas, S. Agarwal, M. Konar, R. Evans, T. Graves, J. Lowe, H. Shah, and S. Seth, “Apache hadoop yarn: Yet another resource negotiator,” in Proceedings of the 4th annual Symposium on Cloud Computing. ACM, 2013, p. 5.
[13] X. Meng, J. Bradley, B. Yavuz, E. Sparks, S. Venkataraman, D. Liu, J. Freeman, D. B. Tsai, M. Amde, and S. Owen, “Mllib: Machine learning in apache spark,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 1235–1241, 2016.
[14] Sarup J , Shukla V . Web-Based solution for Mapping Application using Open-Source Software Server[J]. International Journal of Informatics & Communication Technology, 2012, 1(2):91-99.
[15] Donnelly, Caroline. OpenStack Foundation sets to build enterprise trust in open source clouds.[J]. Computer Weekly, 2016.
