面向自然资源信息提取的多源异构数据融合技术
——以汉江流域NDVI数据为例
2021-05-10汤宇磊吴杨杨蒋兴征冯亮高阳
汤宇磊, 吴杨杨, 蒋兴征, 冯亮, 高阳
(1.中国地质调查局地球物理调查中心,河北 廊坊 065000; 2.自然资源要素耦合过程与效益重点实验室,北京 100055; 3.四川大学建筑与环境学院,四川 成都 610065; 4.中国农业大学土地科学与技术学院,北京 100083)
0 引言
进入信息时代以来,人类对地球的观测与探测能力不断提升,获取的数据量成幂律增长,数据处理技术的不断丰富为数据融合利用提供了可能。各类自然资源时空属性信息充实于大量非关系型、非结构化和半结构化数据中,具有典型的多源、多维、多类、多尺度等特征[1]。已有研究表明,多传感器数据融合相较于单一来源数据在数据准确性和实际应用方面更具优势[2]。欧美等国基于不同卫星传感器,相继发布了各类归一化植被指数(Normalized Difference Vegetation Index,NDVI)遥感数据产品,在生态恢复工程评价[3]、林草资源监测[4]、生物多样性估算[5]、高分辨率森林覆盖分类[6]等诸多方面发挥了重要作用。但NDVI数据源的多源性同时也带来了植被评估的不确定性[7],一定程度上限制了遥感数据的价值挖掘及植被演变研究的延续性和准确性。不同流域之间植被种类与分布存在较大差异,NDVI反演参数差异较大,难以依据单一产品客观评估区域植被生长水平[8],迫切需要针对各类时空数据开展规则化重建、数学建模等工作,实现多源异构自然资源信息的融汇和海量观测数据的高效利用。汉江流域是我国南水北调工程的水源地,也是长江中游生态保护屏障区,国内外学者针对流域生态服务[9]、水文效应[10]、湿地变化[11]等开展了大量研究,但基于多源数据的资源-生态评估工作有待进一步深入。本文以汉江流域植被覆盖为研究案例,探索了一种基于数据规则化重构与机器学习算法的多源异构数据融合技术,有效融合了各类数据信息,获得了多年期高分辨率自然资源观测指标时空数据集,实现了地表植被演变的精准评估,进而定量核算了各类自然资源禀赋规模与时空演变规律,为区域长时间序列生态保护情况评估与社会经济发展策略回溯提供了数据支持,对我国自然资源调查和经济社会绿色健康发展具有现实意义[12]。
1 基于机器学习的多源异构数据融合技术
1.1 数据融合理论简介
数据融合指处理来自单一和多个来源的数据和信息关联的多层次过程,以实现重新定位,从而及时、完善地对其形势、风险及重要性进行评估[13],主要包括数据级融合、特征级融合和决策级融合3类。数据运营层主要针对数据读入、置信验证等方面进行原始数据融合; 数据仓库层主要针对权重筛查、时空定位、特征空间提取进行特征数据融合; 数据产品层主要针对全局模拟、需求导向等进行决策分析融合(图1)。
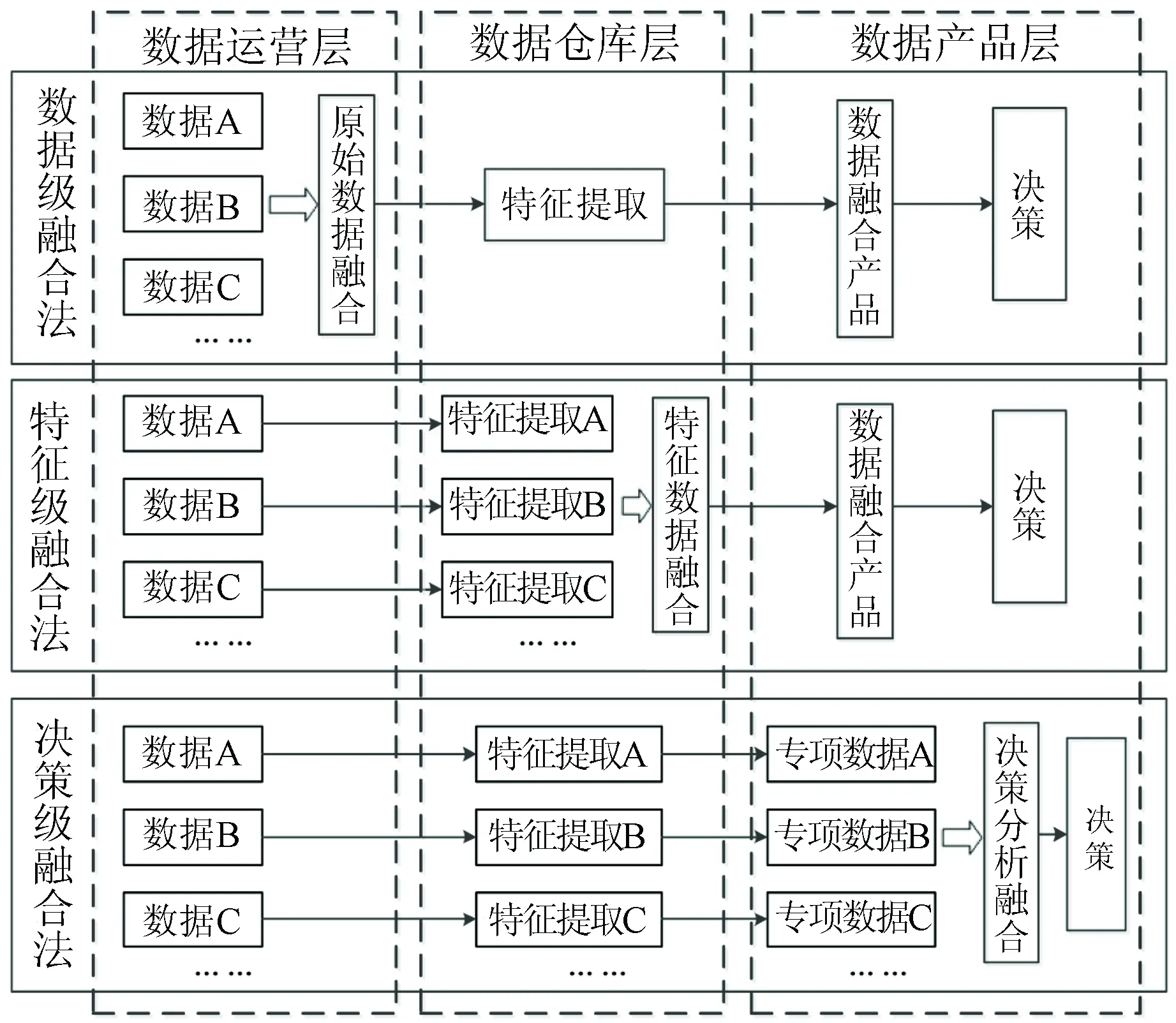
图1 3类数据融合方法技术路线
1.2 数据规则化重构
数据规则化重构是数据融合的先决条件,也是数据管理的必要步骤。随着生态环境质量评估与自然资源存量调查的不断深入,数据源不断丰富,不同的变量数据在数据结构、格式、时空分辨率等方面均存在较大差异,需预先进行数据规则化重构。在数据建库过程中要兼顾服务器存储与计算效率,通常采用PostgreSQL、MySQL、Oracle等主流数据库软件平台搭建目标数据的底层架构,并通过搭建数据索引提高数据检索速度,建成融合研究前的环境基础数据库。这个环境基础数据库为自然资源变化区域的快速识别与精准定位提供了有效抓手。
1.3 机器学习建模评估
多源遥感NDVI在不同植被类型区域内的相关性不同,即在像元尺度上的相关性存在差异,难以依据线性关系进行有效拟合[14]。随机森林(Randon Forest,RF)是精细空间和时间分辨率下预测地面植被覆盖情况的有效工具,可以有效解决上述问题[15-16]。本文以RF为主体,辅以遗传算法进行因子权重与数据特征空间迭代筛查,实现机器学习数据融合。在模型训练过程中,导入训练数据集构建回归树。随机选择三分之一的预测变量用于构建每棵树[17]。首先,基于单个节点构建一个树; 然后,重复引导步骤,直到每个终端节点中只有一个数据条,从大量训练样本中提取特征,在回归树的每个节点处选择最佳分割,构建自变量与各协变量之间的相互关系,提取训练样本特征空间; 最后,建立指标因子预测子模型。植被变化不仅包括自然属性,还涵盖经济、社会、生态等多类人文属性。通过融合3类NDVI数据产品和Landsat部分解译数据,配合气象、地形、流域模式、人口密度等环境协变量对研究区域及时段进行模型预测。
2 材料与方法
2.1 研究区概况
汉江流域地处长江经济带中部,涵盖面积超过15万km2,位于我国南北气候过渡带,气候温和湿润(年均气温14.1 ℃),水量较丰沛(年均降水量972 mm),是我国重要的水源涵养地和长江中游生态保护屏障区。区域温带季风气候与平原地形特点赋予了流域良好的植被覆盖条件,流域天然植被主要为亚热带常绿阔叶林与常绿和落叶阔叶混交林。流域地势呈现西北高、东南低的特点,分别以干流丹江口和钟祥为节点,区分上、中、下游。上游高山耸立,峡谷多,植被景观丰富,丹江口水库是南水北调的中线水源区; 中、下游的江汉平原是我国中部地区重要的农作物产区[18],城市外延化进程明显。区域工农业等社会、经济活动的不断加剧与人口的快速增长,造成流域生态功能弱化、自然资源减少等,这些问题值得关注。
2.2 基于机器学习的汉江流域多源NDVI数据重构
数据重构主要包括数据获取与清洗、特征工程建模、模型检验、产品输出等过程。本研究针对汉江流域上中下游植被的不同特点,结合区域林地、草地、湿地等主要土地利用类型,开展了基于机器学习的多源NDVI数据重构研究,通过交叉验证与真实值检验等方式评估了重构数据的准确性与精度。
2.2.1 数据获取与清洗
NDVI数据来源于MODIS(美国)、SPOT-VGT(法国等)、PROBA-V(欧洲)3类卫星传感器,时间跨度分别为2000年1月至2019年12月,2000年1月至2014年5月和2013年10月至2019年12月。MODIS产品为16 d短期合成数据,一定程度上消除了大部分气象因素与云层的影响,但仍存在部分噪声干扰[19]。SPOT产品对于常绿阔叶林和针叶林的指示准确,优于MODIS[20],但受卫星寿命限制,已于2014年5月停止提供数据。PROBA-V产品是一类植被专有观测传感器,具有与SPOT-VGT相似的光谱特征,旨在延续其地表植被观测任务,两者在整体上保持了观测一致性(均方根误差RMSE为0.003),同时也存在某些未知的非系统差异[21]。
基础数据共涵盖NDVI数据、自然类环境协变量、社会经济协变量等12种不同数据来源(表1)的45个数据信息。各类数据均进行了值域分布检查、异常值剔除、置信区间筛查,去除了部分不良噪音。根据不同数据源格式,基于R、Python、SQL等不同计算机编译语言,实现了数据批量导入[22]。
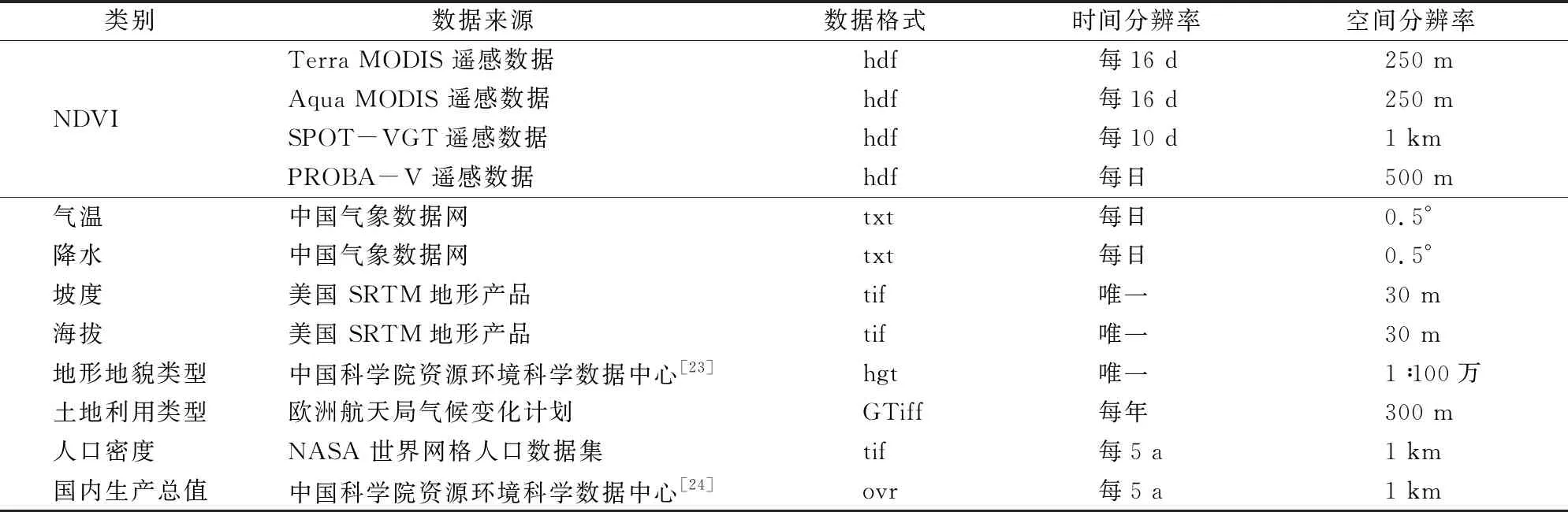
表1 基础数据信息汇总
2.2.2 基于机器学习的多源数据融合建模
本研究首先构建了汉江流域高分辨率空间网格(1 km×1 km),获得基础网格单元155 365个。之后以盆地网格要素的单元格中心点为基准,将各类数据进行重采样处理,嵌套进入对应网格中。Landsat辅助解译数据直接依据经纬度进行网格落定; NDVI值(两组卫星数据插值后)、人口密度和国内生产总值(Gross Domestic Product, GDP)3类数据的空间分辨率与基础网格一致,采用最近距离法进行重采样匹配; 气象(差值后数据)、海拔、NDVI值(年度最大值)和土地利用类型4类环境协变量数据的空间分辨率高于已有网格,采用嵌套与反距离权重插值相结合的方法,对源数据网格内多测量值进行加权和加和; PBLH和排放清单数据的空间分辨率低于基础网格,采用反距离权重插值方法,基于源数据的多测量值的加权平均,进行网格值重采样。同时,为了保证数据的空间平滑性,对人口密度、海拔、NDVI和土地利用类型4种数据均进行了二次空间卷积,卷积前后的两个变量均作为变量数据加入模型构建中,相关过程基于PostGIS、Rstudio等实现(图2)。
经过梳理,20 a的基础数据中,有效记录为3 728.76万条,每个数据集设立唯一的DOI编码,明确数据溯源,便于数据后期发布过程中的知识产权保护。数据均依据变量类别,通过数据时段和网格编号ID实现各类信息时空化识别与提取,为下一步数值建模提供支撑。模型训练样本为2015—2019年Landsat影像解译数据及部分实测值。模型添加了季节性变量,对变量取值空间进行了有效分隔。
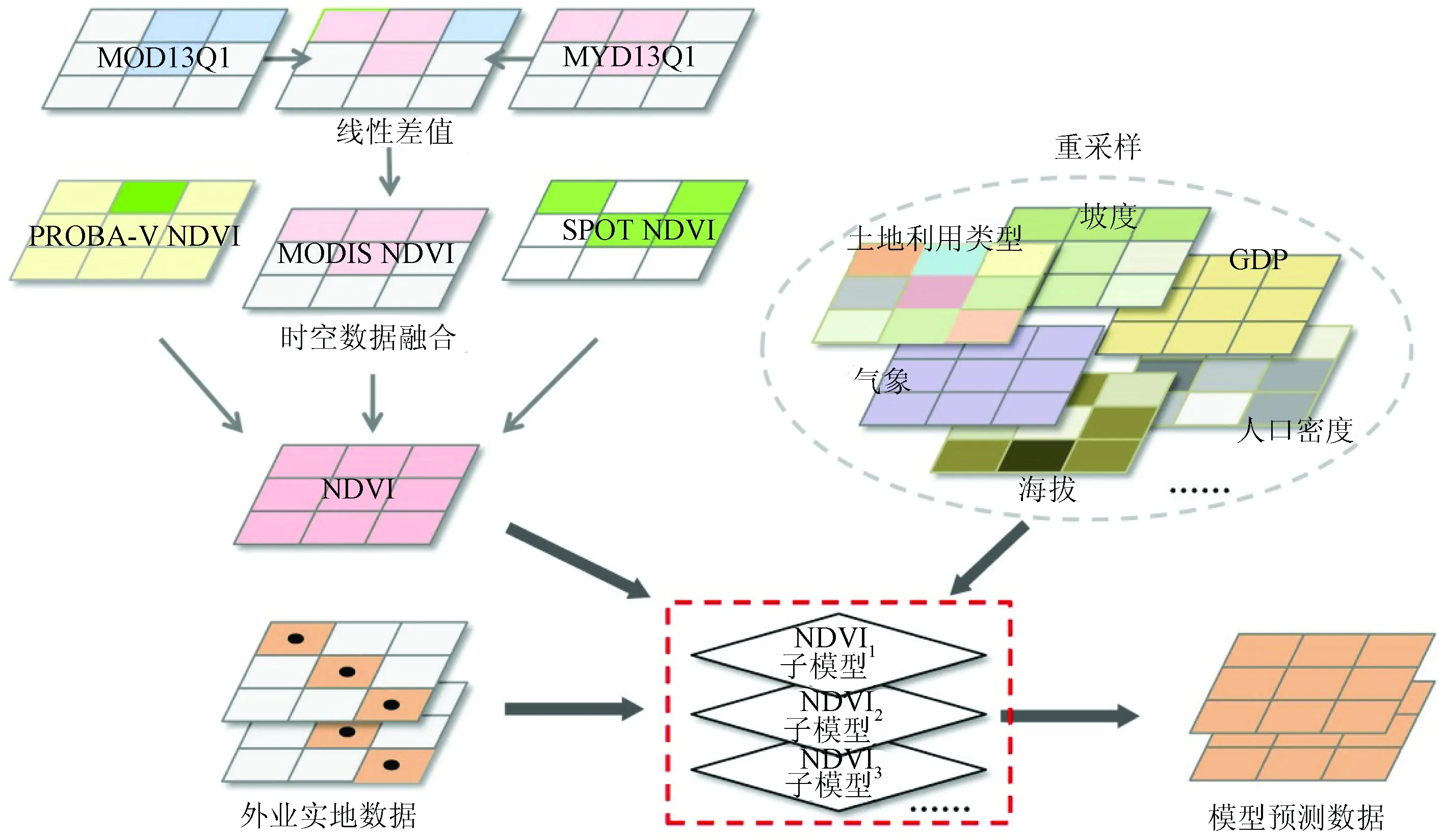
图2 研究技术路线
通过量化各变量因子单一置换后的预测误差结果差异,筛查出每个变量的相对重要性[25]。基于袋外误差结果,剔除了各子模型中相关重要性低(<5‰)的自变量。依据多组模型超参数调整实验结果,各子模型中树的棵数设置为500,最终预测结果取所有回归树结果的均值。在并行与并发运算支持[26]下,单次模型预测运行时间为55 min,各子模型的模拟结果均达到近似最优的计算效率和预测性能。
2.2.3 模型准确性检验
k折交叉验证是检验时空模型泛化能力的合理有效的方法,可以有效避免模型可能存在的过度拟合现象。将模型的训练数据根据数量大小,平均分为k份,每次使用其中的(k-1)份数据进行模型训练,预测余下1组数据,最后将k次训练的结果全部合并,并与原始训练集数据进行比较,根据决定系数(R2)、均方根误差(Root Mean Square Error, RMSE)等指标衡量模型的预测准确性。
3 结果与讨论
3.1 模型验证与评估
本文兼顾服务器计算效率,基于网格经纬度的分组方式将32.7万行训练数据进行20折交叉验证,得出决定系数R2为0.86,表明了模型在NDVI时空分布重构上的优越性(图3)。同时,基于年份与月份进行交叉验证,R2分别为0.77和0.82,基于流域上、中、下游分别建模验证,R2分别为0.88、0.86和0.82,表明模型在时间外延与空间外延上均表现出较好的预测准确性。同时,根据流域42个实地林草样地调查结果比对,重构数据的植被覆盖准确度为92.9%,高于单一数据源MODIS(88.0%)、SPOT-VGT(83.3%)和PROBA-V(76.1%),体现了基于机器学习的多源数据融合技术的优势。
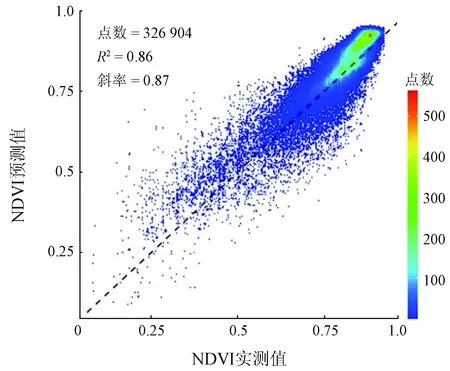
图3 模型交叉验证结果
3.2 汉江流域2000—2019年植被NDVI时空变化
NDVI值域高、低地区交错,受局部气候、地形、人文等因素分布差异影响,具有明显的空间异质性[27-28]。流域上游植被茂密,植被覆盖处于相对最高水平(NDVI>0.8),属亚热带山地湿润季风气候,降水与日照充足,气候温和,区域的水热条件非常适合植被的生长和更新[29],森林覆盖率高,汉中市、安康市市区及周边地区是上游植被覆盖较低的区域; 中、下游各城市及周边区域植被覆盖较低(NDVI城区=0.52±0.03),通过与县级及以上等级的居民点叠加分析,NDVI低值区主要为城镇等人口聚集区,与Landsat影像解译结果一致,丹江口水库是汉江流域的重点水利工程,其改变了流域中、下游部分生态系统的原有面貌[30]。研究区植被覆盖水平相对较低(NDVI≤0.3)的区域主要分布于丹江口水库和武汉市、襄阳市、南阳市市区及其周边地区(图4)。
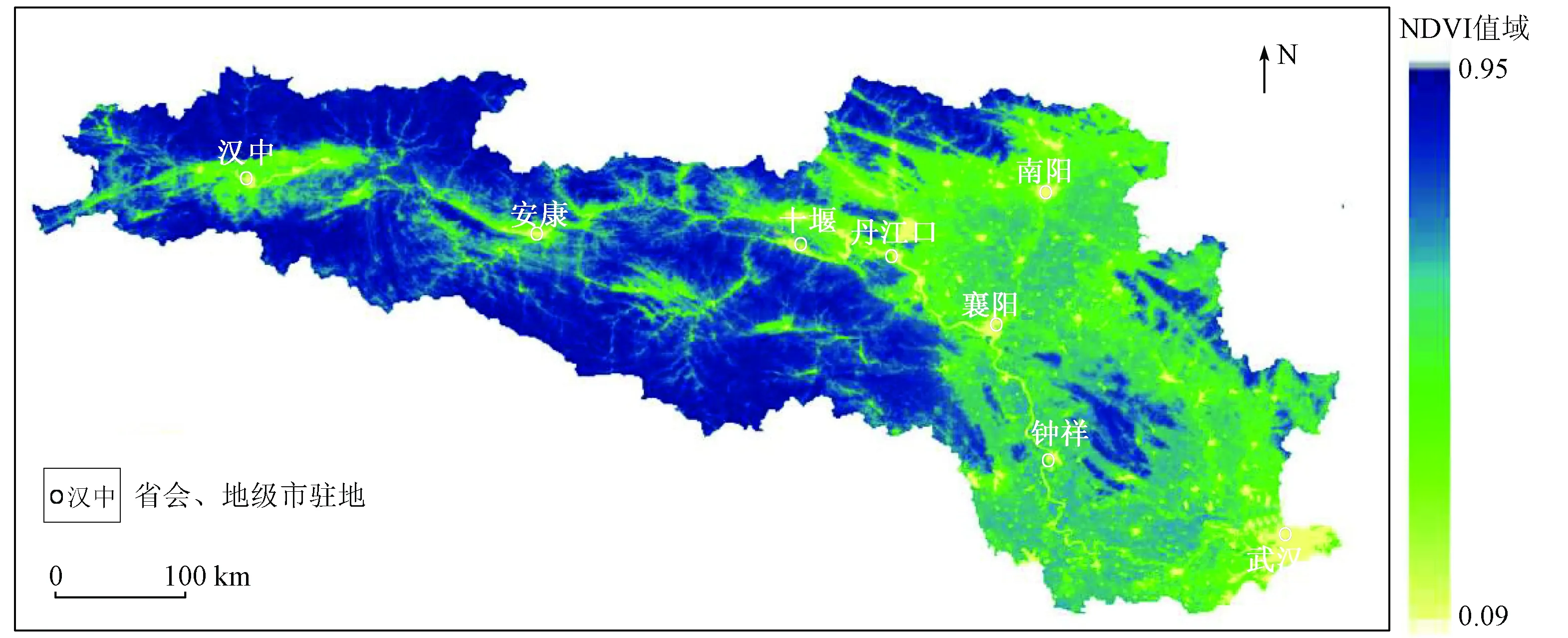
图4 汉江流域2000—2019年NDVI年最大值空间分布
流域的植被覆盖率整体呈波动增加趋势,总增长率为1.6%/10 a,中、上游增量较明显[31](增长率分别为2.2%/10 a和1.6%/10 a),下游植被覆盖率基本维持不变,一直处于波动阶段。流域植被改善面积达到75.1%,其中5.4%面积的植被改善程度超过10%,植被退化面积比例为10.2%。植被覆盖变化分布存在地区差异,河流沿岸和人类活动密集区植被覆盖变化显著[32](图5)。计算结果表明,20 a间流域植被覆盖上升区人口密度平均减少0.3%,植被退化区人口密度平均增长4.0%。植被覆盖上升区主要分布于汉江上游沿岸和流域东北部区域,丹江口水库周边与荆门市西部区域植被改善情况尤为明显,一定程度上表明国家水源保护地退耕还林、荒地造林、水土保持等政策的有效性,表明人类活动发挥了积极作用[33-34]。植被覆盖减少区则主要位于城市及周边区域,也是人类活动密集区。
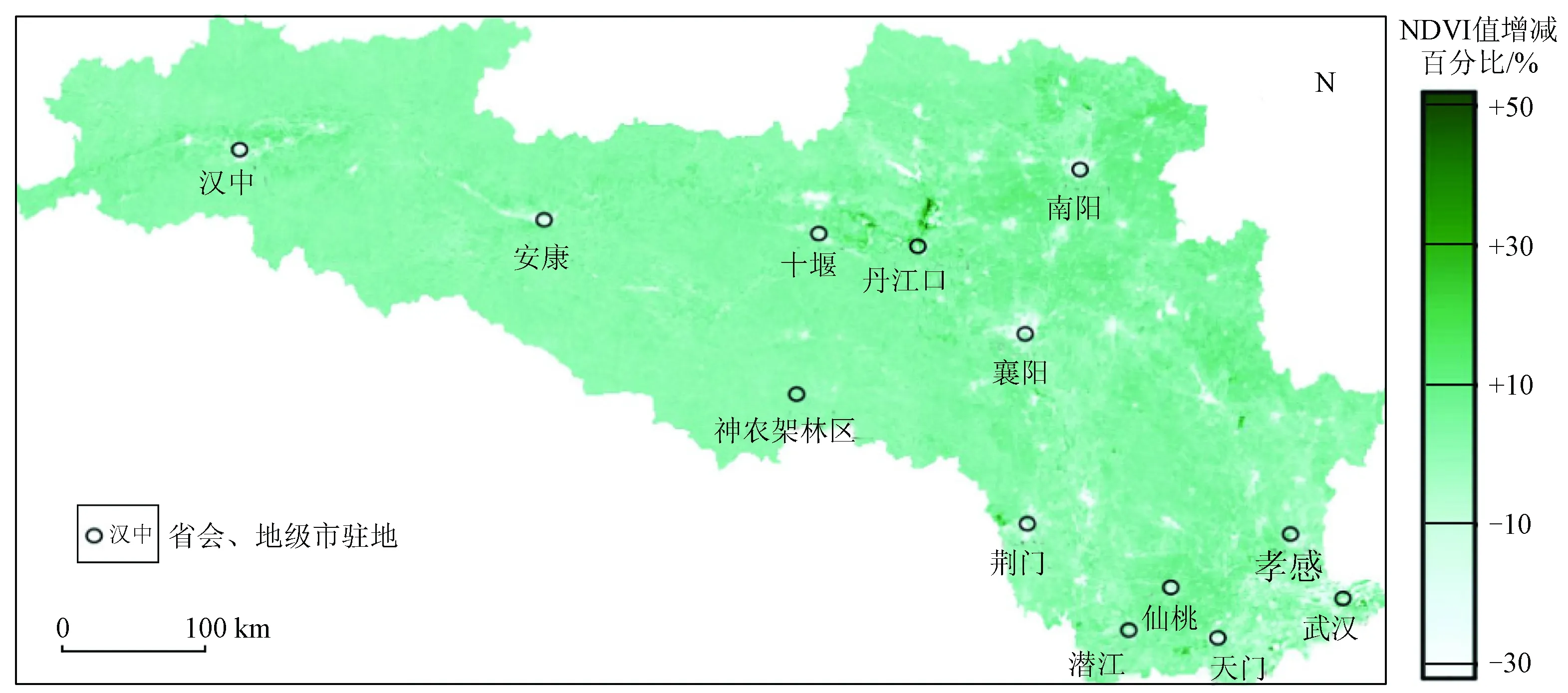
图5 汉江流域2000—2019年NDVI空间变化趋势
3.3 汉江流域植被NDVI变化与人类活动间关联
流域的土地利用类型主要包括林地、园地、耕地、湿地/水体和城区,各类土地植被变化特征有所差异。本文将获得的NDVI数据集与流域两类土地利用类型数据相交叠加,得到流域各类土地NDVI时空变化序列(表2),进而评估出区域自然资源赋存与生态环境质量情况。
由表2可知: 汉江流域所属林地与园地主要位于上游地区,一直保持着整体较高的植被覆盖水平且稳中有升(NDVI林地=0.903±0.006,NDVI园地=0.888±0.010),长期以来的森林抚育、封山育林等积极行为使森林生态系统保持了稳定向好的趋势[35-36]; 耕地主要位于中、下游的江汉平原,NDVI维持稳定水平(NDVI耕地=0.799±0.009); 湿地/水体主要分布于河流及周边区域,NDVI水平中等(NDVI湿地/水体=0.572±0.009),变化不明显,丹江口水库大坝下游,即流域中、下游,湿地生态系统有所恢复; 城区NDVI则下降较为突出,每10 a平均下降4.7%,城市建设用地的不断扩张带来了植被的消极变化。上游森林资源与下游耕地资源均保持了相对稳定的水平,一定程度上体现了20 a间上游森林生态系统与中、下游耕地资源的相对稳定性[37]。但随着城镇化进程的不断推进,人类活动密集与城市向外扩张造成城区及周边区域植被覆盖显著减少,区域生态风险形势依然不容乐观。
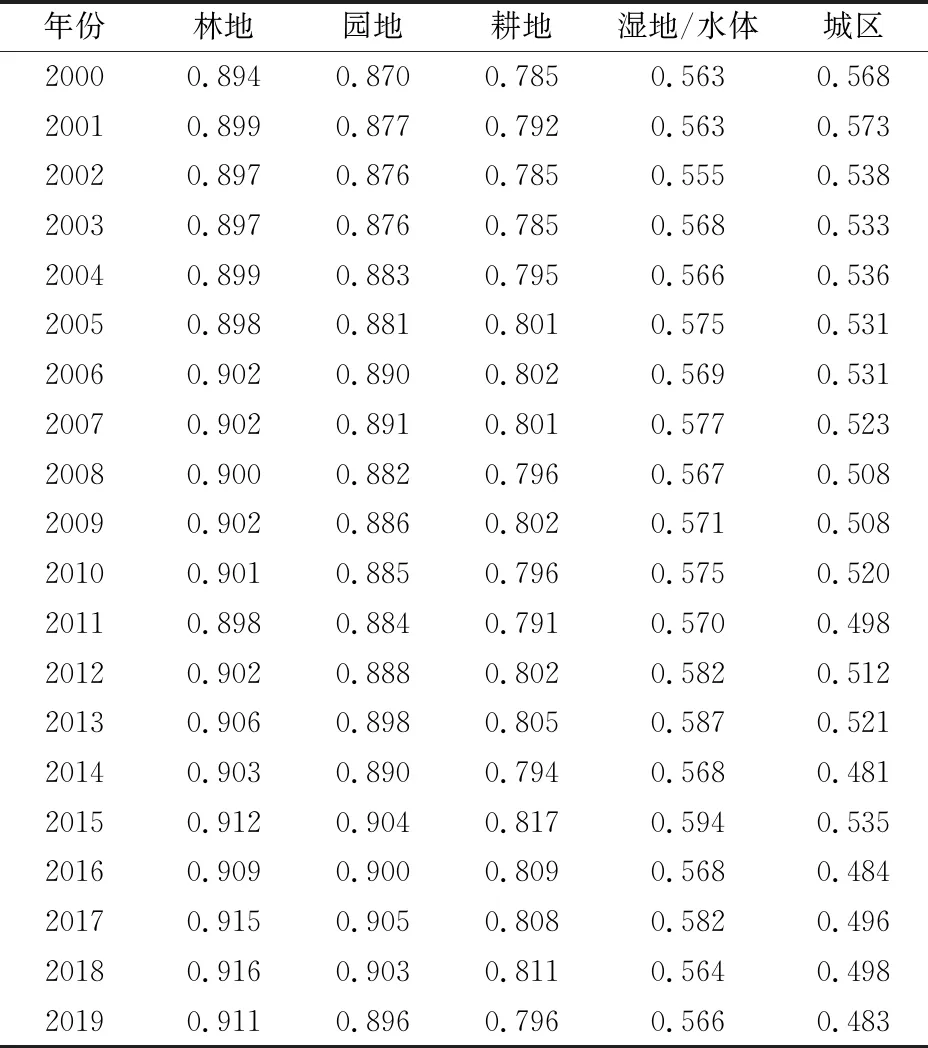
表2 汉江流域2000—2019年不同土地利用类型下NDVI最大值汇总
基于研究区各网格单位计算流域多年期NDVI与人口密度Spearman秩相关系数,两者相关性空间分布具有明显的空间异质性(图6)。NDVI与区域人口密度正相关性区域占总面积的28%,主要集中于河南省南阳市辖区,印证了该区域退耕还林工程成效明显[38]; 负相关性区域占总面积的72%,主要分布于流域中游耕地区及人口密度较高的城市区域。两类截然不同的相关系数分布情况体现了人类活动对植被覆盖影响的不确定性和随机性,会受到国家政策和不同时期发展需求等多种因素的影响[39]。
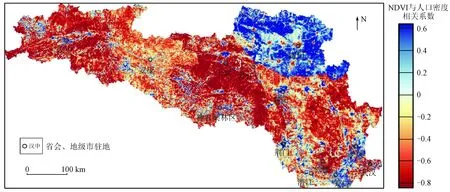
图6 汉江流域NDVI与人口密度相关系数空间分布
3.4 不足与展望
本文主要针对植被每年的生长旺盛期进行逐年NDVI最大值模拟与分析,未进行植被生长季全周期的跟踪观测。未来可基于该融合技术方法,进一步提升数据的时空分辨率,模拟年内植被生长全过程,更精准地实现植被动态观测,更好地支撑自然资源管理与生态质量评估。
4 结论
本研究聚焦自然资源信息高效提取与利用,以汉江流域NDVI数据为例,探索了一种多源异构数据融合技术,主要结论如下。
(1)基于机器学习的多源数据融合技术具有速度快、准确度高、经济高效等优势,本研究面向自然资源信息提取领域,形成了一个多源异构数据智能融合技术方法,可实现数据高效利用与特征空间快速优选。
(2)以汉江流域为例,基于随机森林算法,融合了3种异源NDVI数据产品,构建了NDVI回溯预测子模型,获得了2000—2019年汉江流域NDVI逐年时空分布数据集,模型交叉验证决定了系数R2为0.86,空间分辨率为1 km。模型从多源数据中优化提取了数据特征空间,与原有单一数据产品相比,模拟结果更贴近实际,数据质量有所提升。
(3)汉江流域植被变化与区域人类活动密切相关,两者相关系数分布存在显著的空间异质性,正相关区主要为流域东北部区域,负相关区主要为流域中游耕地地区与城市周边区域。人类活动对植被的影响受国家政策、经济发展等多方面因素控制。
