基于VMD-CNN-LSTM模型的渭河流域月径流预测
2021-05-07包苑村解建仓罗军刚
包苑村, 解建仓, 罗军刚
(西安理工大学 西北旱区生态水利国家重点实验室, 陕西 西安 710048)
径流预测是水文学与水资源学科的关键内容,是实现水资源科学规划、合理调配、适应性利用的基础。但在气候变化和人类活动的影响下,径流过程存在高度变异性,对现有预测模型和方法的适用性是一个巨大的挑战[1]。径流序列高度的非线性与不稳定性,使得运用单一模型对径流序列预测,并不能完全捕捉径流序列中的非线性因素[2]。信号分解[3]可将水文序列分解得到多个相对稳定的分量,使模型更好地捕捉特征。许多学者对基于信号分解与各种模型的组合预测问题开展了大量的研究。邵骏等[3]将Bayes证据框架理论[4-5]用于最小二乘支持向量机(LLSVM)参数的优选,建立了中长期径流预报模型。研究结果表明,该预报模型在中长期预报中具有较好的适应性。张洪波等[6]使用经验模态分解(EMD)与ARMIA的混合模型用于月径流预测中,结果较单一的ARMIA模型Nash系数(NSE)提升0.3左右。Wang等[7]将集成经验模态分解(EEMD)与人工神经网络进行组合,与单一人工神经网络方法相比,EEMD-ANN模型在中长期径流预测中有显著的改进。胡庆芳等[8]采用长短期记忆神经网络(LSTM),构建了汉江上游安康站日径流预测模型,研究表明LSTM模型对于峰值的拟合更加精确,但更高精度的预测仍有机会实现。
为了更好地提升预报的精度,更好地适应变化的径流过程,引入变分模态分解(VMD),与卷积-长短期记忆神经网络(CNN-LSTM)[9]进行组合预测,提出VMD-CNN-LSTM模型。将其应用于渭河张家山站,魏家堡站的月径流预测中。CNN用于提取特征,LSTM可以捕获时间序列中的长期依赖关系,具备更好适用性的同时还提高预测的精度。
1 研究方法
1.1 变分模态分解(VMD)
VMD是一种新的非平稳信号自适应分解估计方法。它由Dragomiretskiy等[10]提出。VMD方法采用非递归和变分模式分解对原始信号进行处理,将输入信号分成若干个分量(IMFs)与一个残差(R),对测量噪声有较好的鲁棒性。此外,由于K可以预先设定,通过设置合理的收敛个数,可以有效地降低模型的计算复杂度。
VMD的总体框架是一个变分问题,主要包括变分问题的构造和求解[11]。原始径流序列视为非平稳信号f,将变分问题描述为利用中心频率求K个有限带宽模态函数uk(t)(k=1,2,3…K),从而使每个模态的带宽估计之和最小化[12]。约束条件为所有的分量的和等于原始信号f,具体表达式为:
(1)
式中:{uk}={u1,u2,…,uK}是模态函数的集合;{ωk}={ω1,ω2,…,ωK}是与模态函数相对应的中心频率集;⊗是卷积运算;K是模态函数的总数,δ(t)是Dirac分布,是复平面上模态函数中心频率的相量描述;ωk是模态函数的中心频率。文献[10]给出了VMD分解详尽的计算方法。
1.2 卷积神经网络(CNN)
卷积神经网络(CNN)是一种具有高效特征识别的网络,在图像识别,自然语言处理,无人驾驶汽车等方面得到了广泛的应用[13]。CNN由卷积层,池化层和全连接层组成。卷积层是CNN的核心,其中的卷积核Cj用于提取内部特征:
Cj=σ(∑Ai⊗wi+bi)
(2)
式中:Ai表示输入;⊗表示卷积运算;σ为激活函数,这里选择Relu[14];wi表示权值矩阵;bi则表示偏置矩阵。
池化层主要是对卷积运算后的数据进行池化操作,其作用是压缩数据与去除不必要的信息,有效地提高网络的泛化能力并且提升计算速度。这里选择最大池化方式(Maxpooling[15])。
全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来,为之后的LSTM层的预测提供帮助。一维卷积神经网络结构见图1。
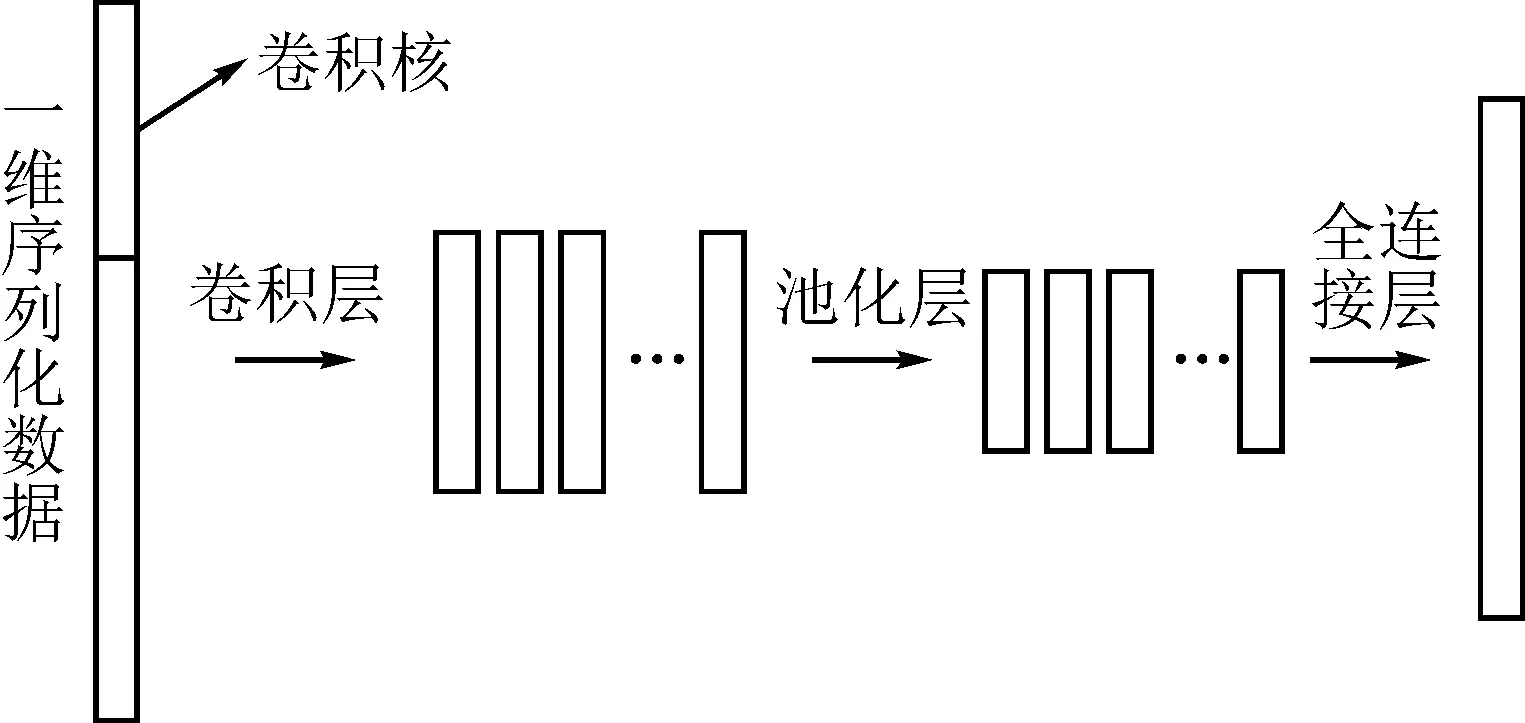
图1 一维卷积神经网络结构图
1.3 长短期记忆神经网络(LSTM)
月径流的准确预测不仅需要考虑近期径流数据,也应该计及远期历史数据的影响。普通的递归神经网络(RNN)具有记忆性,但在应用中难以解决梯度消失的问题[16]。长短期记忆神经网络(LSTM)应运而生,LSTM相较于RNN,能更好地分配历史单元的信息,并且具有捕获时间序列中长期依赖关系的能力。LSTM单元结构见图2。
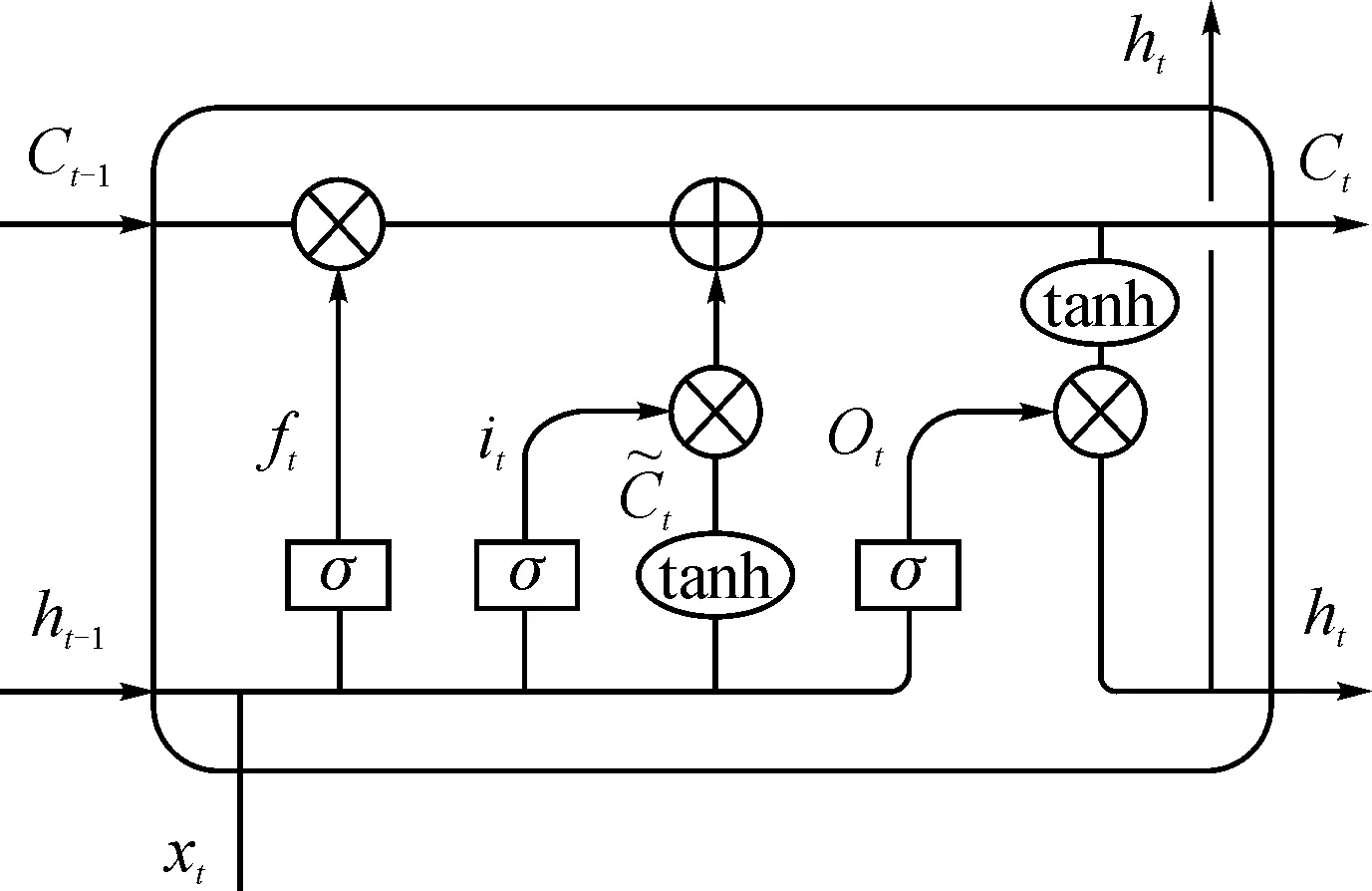
图2 LSTM单元结构图
一个LSTM单元由忘记门ft、输入门it和输出门Ot组成,其中it判断上层输入是否进入隐藏层,Ot选择该单元的输出是否进入下一单元,ft表示是否将该单元的历史信息进行存储。具体计算公式见下。
ft=σ(Wf[ht-1,xt]+bf)
(3)
it=σ(Wi[hi-1,xt]+bi)
(4)
(5)
(6)
ot=σ(Wo[ht-1,xt]+bo)
(7)
ht=ot*tanh(Ct)
(8)
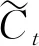
1.4 VMD-CNN-LSTM(VCL)预测模型
VMD-CNN-LSTM(VCL)模型的基本预测流程为如下。
1) 将原始月径流序列进行VMD分解。
2) 将分解后的多个分量进行归一化处理。
3) 选取模型的输入输出。根据月径流的年际变化规律,选取每一个分量的历史滞后12个月作为模型的输入,原始径流序列的第十三个月作为输出,预见期为1个月,如下所示:
(9)
式中:t>12;S为原始月径流序列。
4) 将选好的输入与输出放入CNN-LSTM模型训练,进行预测。实验流程图见图3。
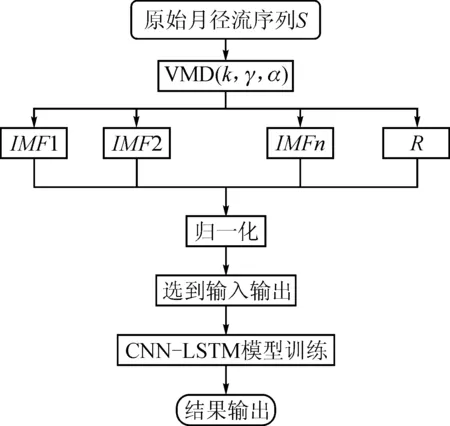
图3 预测模型流程图
1.5 模型验证
选取均方根误差(RMSE),平均绝对误差(MAE)和Nash系数(NSE)对测试集的预测结果进行评价,更加清楚地反应模型的预测效果。
(10)
(11)
(12)
式中:yi为i时刻的预测值;y0为i时刻的实测值;y为实测值的均值。
2 实例分析
2.1 实验环境搭建
本实验全流程采用python3.7完成,其中VMD分解使用python的第三方库vmdpy完成,神经网络的搭建则使用Keras 2.2.4。
2.2 资料来源
渭河是黄河的最大的一级支流,是陕西人民的“母亲河”[17]。主要流经今甘肃天水、陕西关中平原的宝鸡、咸阳、西安、渭南等地,至渭南市潼关县汇入黄河。但近几年来,渭河流域水灾害频发,对社会经济造成了重大影响。因此,对渭河流域进行径流预测的研究有重要的战略意义。
张家山水文站是渭河最大支流泾河的下游干流控制站,站址位于陕西省泾阳县王桥镇岳家坡村赵家沟,东经105°36′,北纬34°38′,集水面积43 216 km2,控制河长397 km,河流平均比降2.78‰,距河口里程58 km。魏家堡水文站是渭河干流控制站,站址位于陕西省眉县城关镇西关村,东经107°43′,北纬34°17′。集水面积37 012km2,河长494 km,流域平均比降2.75‰,距河口里程323 km。本文分别选取张家山站与魏家堡站1960—2005年的552个实测月径流资料为研究对象。其中张家山站前400个月数据作为训练集,后152个月数据作为测试集。魏家堡站前442个月数据作为训练集,后110个月数据作为测试集。张家山站与魏家堡站的实测月径流序列见图4和图5。

图4 张家山站月径流序列
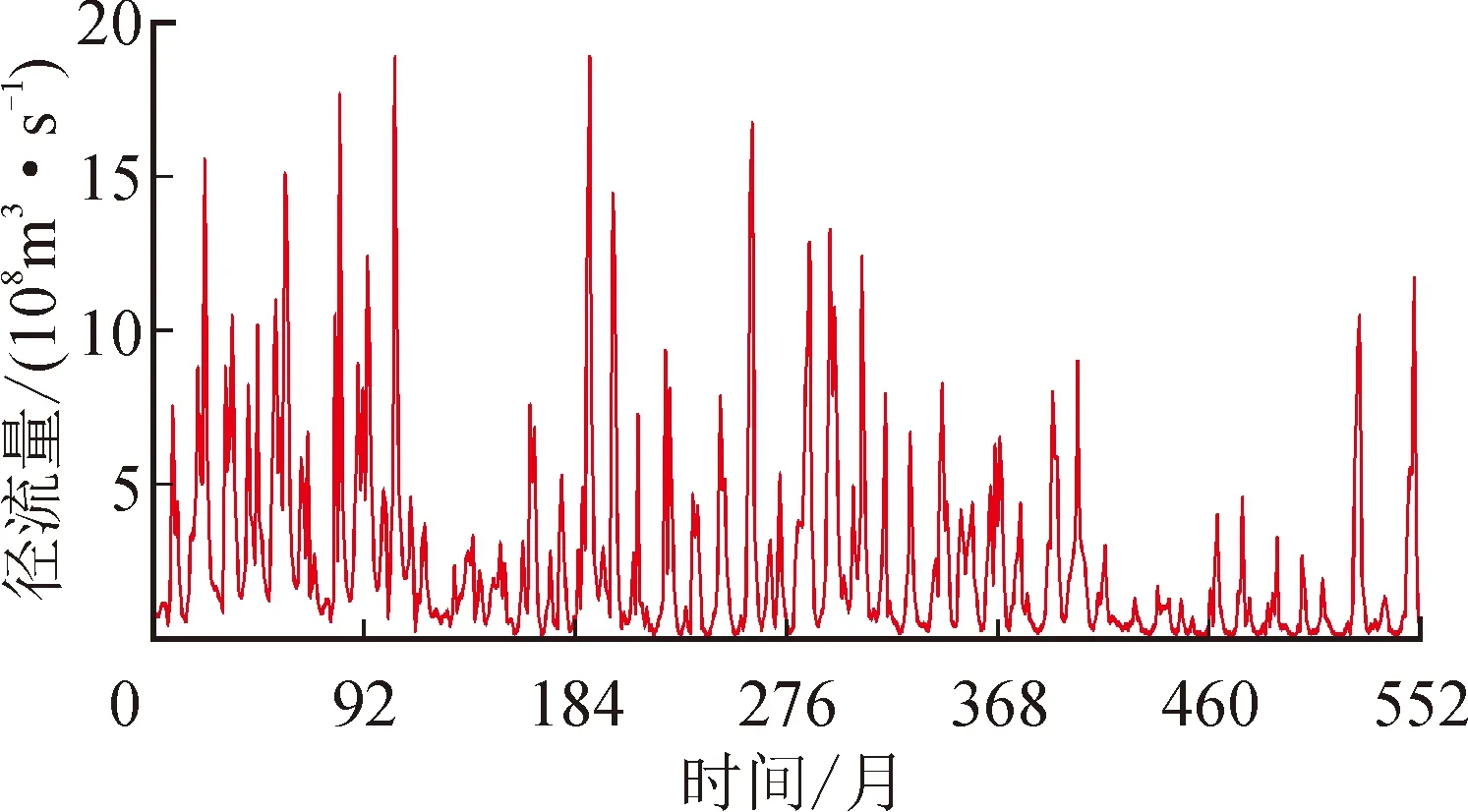
图5 魏家堡站月径流序列
2.3 VCL模型预测
为了使CNN-LSTM模型能更好地识别径流的变化规律,降低预测的难度,对两个站的月径流资料进行VMD分解,最重要的是确定VMD分解的模态数K。通过多次预实验,将每个模态分量进行Fourier变换,发现两个站点的月径流都在K=9时(见图6(a)和图7(a)),中心频率开始出现混叠现象[18],即不同频率的尺度未完全分离(见图6(b)和图7(b)),因此K选择8。

图6 K=8、K=9时张家山站月径流VMD模态分量与对应频谱图
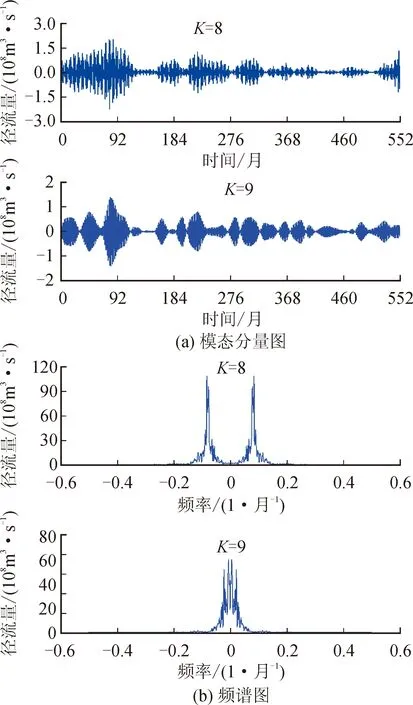
图7 K=8、K=9时魏家堡站月径流VMD模态分量与对应频谱图
如图8和图9所示,通过VMD分解,将原始径流序列分为了不同频率的8个分量,分量的频率由高到低依次排列,前7个分量具有周期性,最后1个分量表示原始径流序列的趋势变化。VMD分解后,原始径流序列中的隐藏信息(周期与趋势)被挖掘出来,这样做不仅使模型能更好地理解周期性的信息,同时也增加了数据量。
2.4 对比试验及结果分析
本实验的CNN-LSTM网络使用两层卷积层,卷积核大小为3×1。一层池化层,采用最大池化(Maxpooling)方式,后接两层LSTM层及一个全连接层输出结果。在相同的预测流程下选择EMD-LSTM(EL)、EMD-CNN-LSTM(ECL)、EMD-LSSVM(ES)、VMD-LSSVM(VS)、VMD-LSTM(VL)进行对比分析。
根据月径流的年际变化规律,将VMD分解好的数据选取输入和输出,用训练集的数据训练模型,用测试集验证模型,不同模型的测试集预测结果见图10和图11。
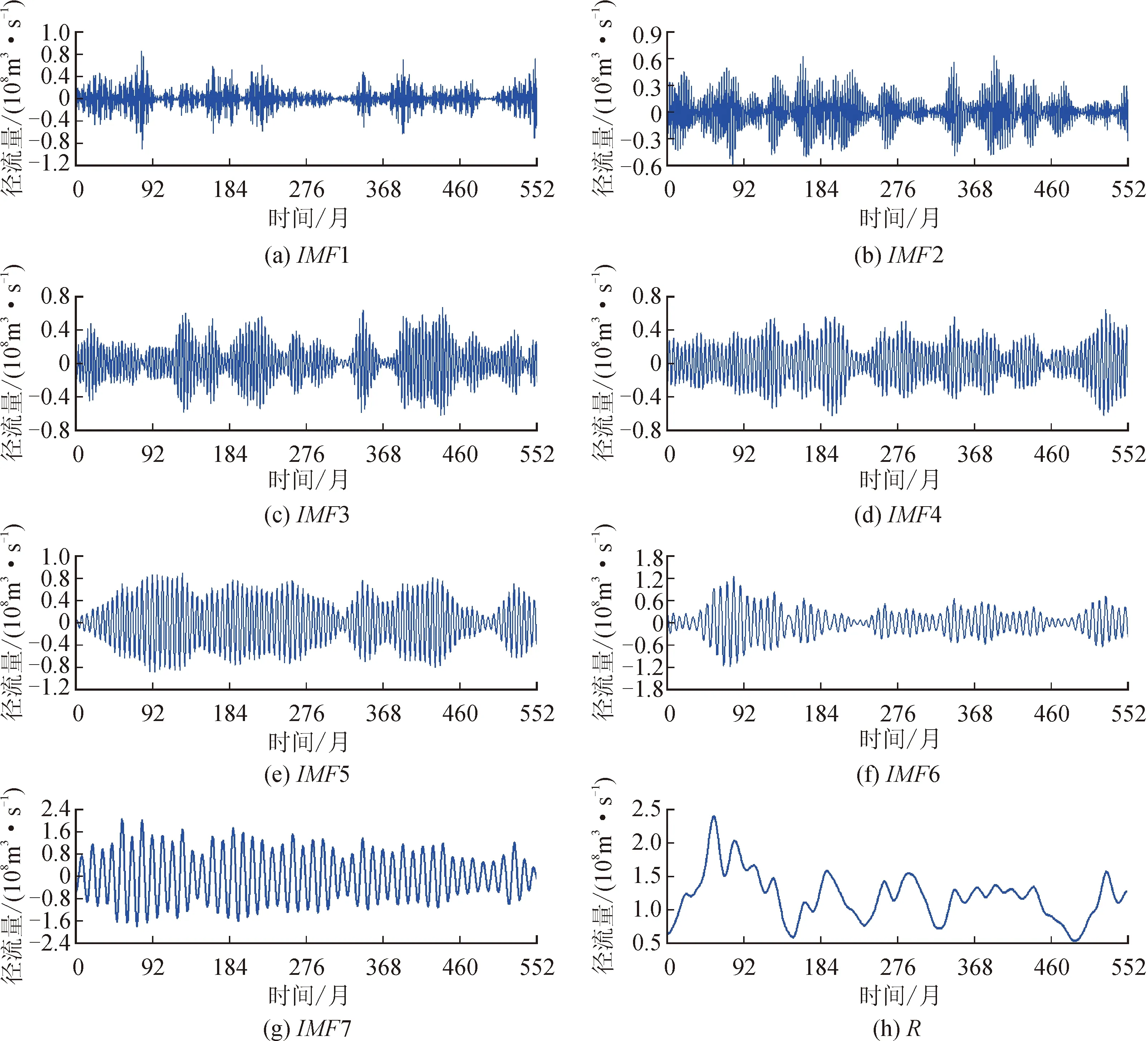
图8 张家山站月径流VMD分解
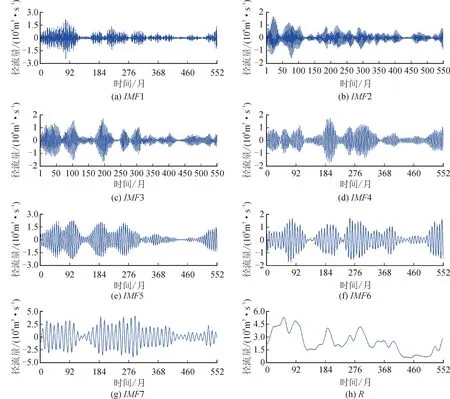
图9 魏家堡站月径流VMD分解
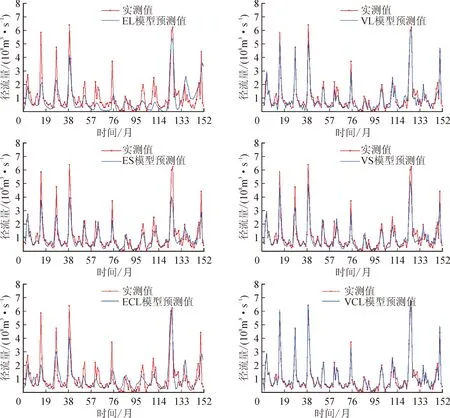
图10 张家山站测试集预测结果图
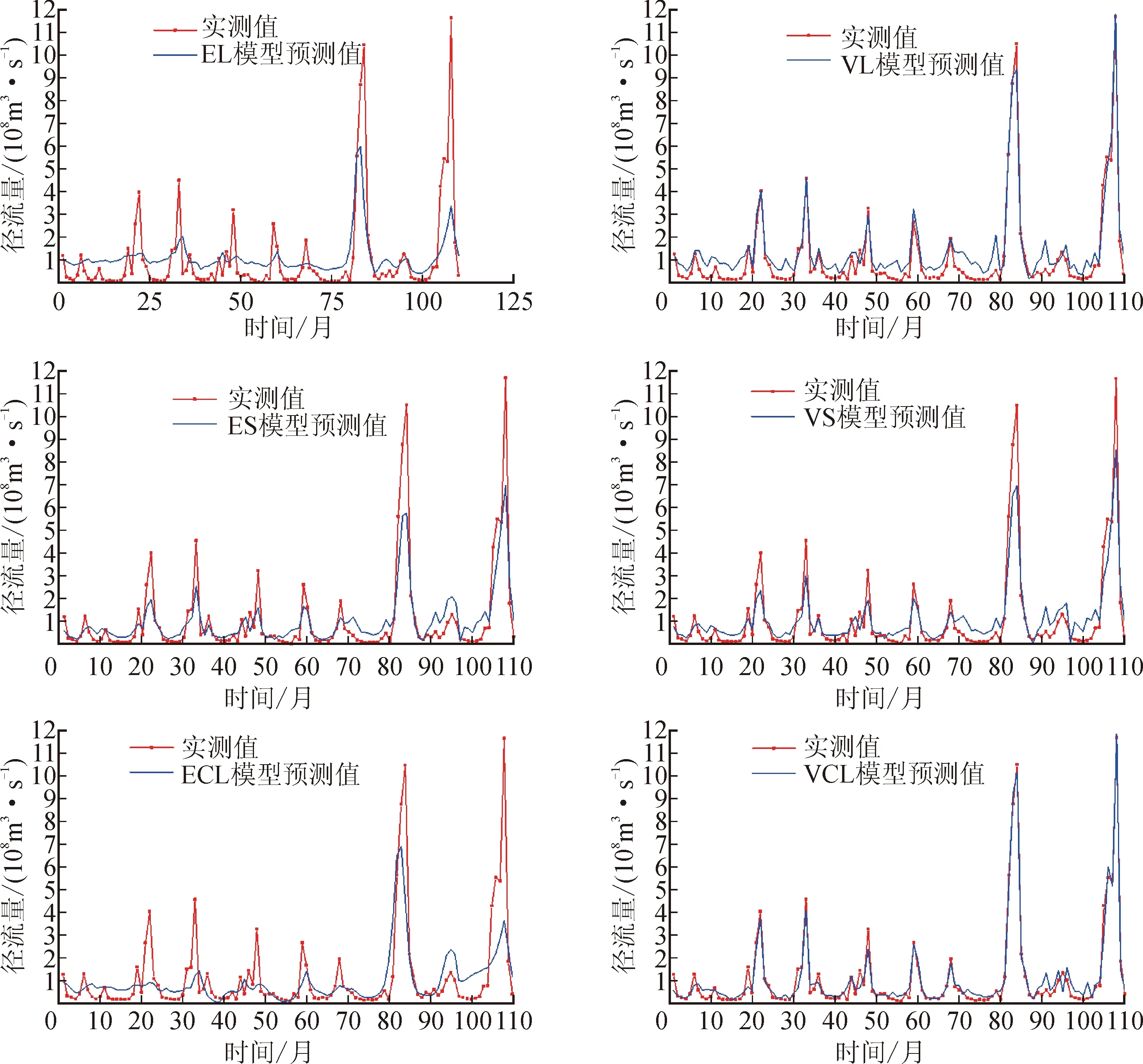
图11 魏家堡站测试集预测结果图
由表1可知,基于VMD分解的VS、VL、VCL模型较之基于EMD分解的ES、EL、ECL模型有较大的预测性能提升。其中VL与VCL模型的预测性能最优,NSE系数达到了0.90以上,MAE与RMSE降低至0.6以内,这主要是因为EMD分解容易产生端点效应和模态混叠的问题,且本实验中的EMD分解的固有模态分量个数为6,相较于VMD可以自由选择模态分量个数来说,数据量较少。而对ECL较之EL、VCL较之VL在预测性能也有小幅度的提升,这是由于卷积核中的池化层可以去除不必要信息,使得LSTM层在预测中的四个判断门中能更好地捕捉长期依赖关系,选择最优的输入和输出,图10与图11可进一步印证结论。除此之外分别对比两个站的EL和ECL模型、VL和VCL模型可以看出,加入卷积层的模型能更好地学习月径流数据的特征,且对于峰值和谷值的拟合更加地精确。两个站的VCL模型的整体预测性能优越,RMSE与MAE等指标较之其它模型均最小,可证明该模型的稳定性以及在渭河流域的预测可行性,可以应用于非线性,非平稳的月径流序列预测中。
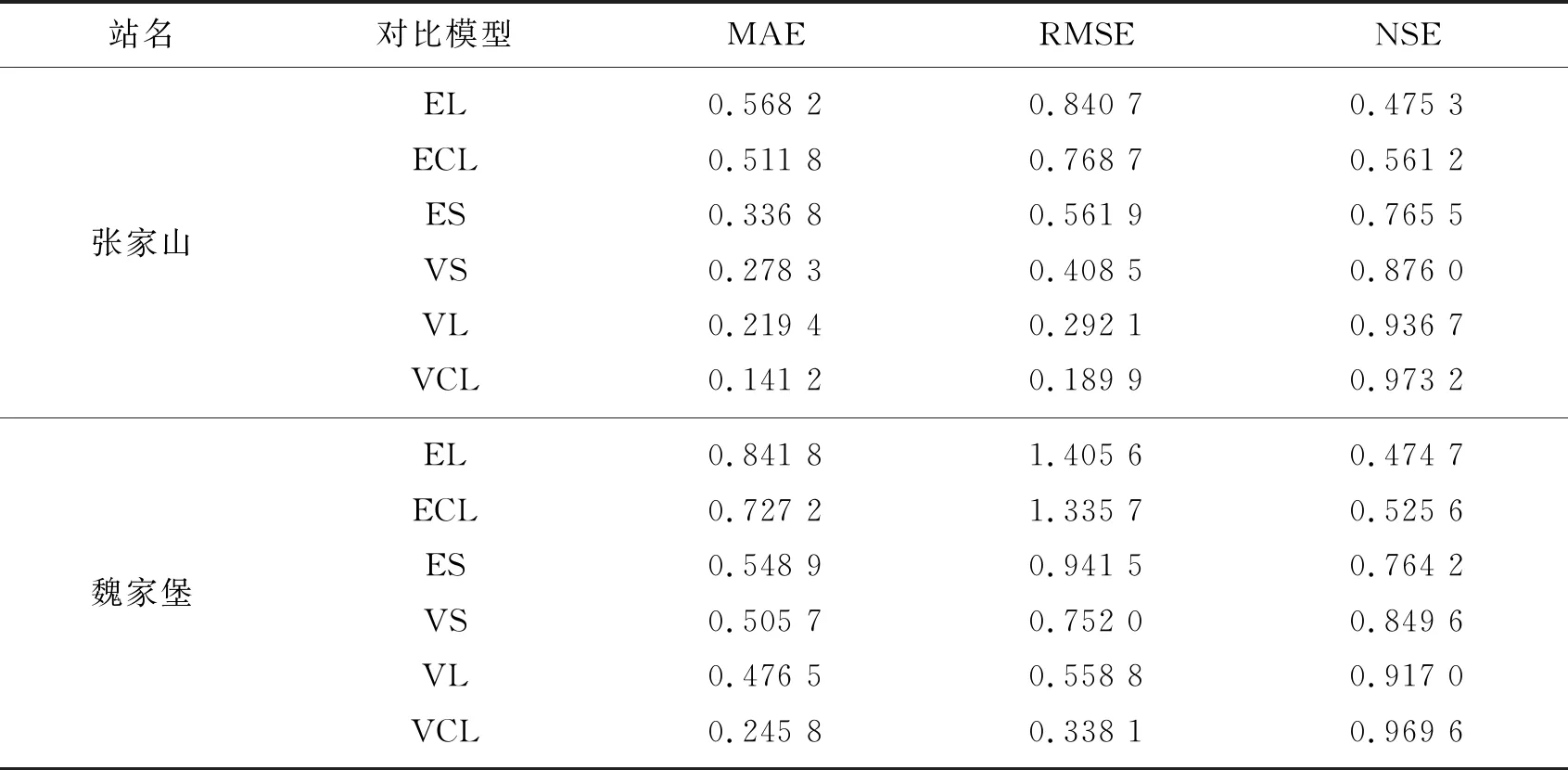
表1 各模型在测试集上的预测效果
3 结 论
为了提升月径流预测的精度,更好地学习月径流序列中的隐藏信息,本文提出了基于变分模态分解(VMD),卷积神经网络(CNN)与长短期记忆神经网络(LSTM)的组合预测方法,并应用于渭河流域张家山站和魏家堡站的月径流预测中,得出的结论见下。
1) 对于高度非线性的月径流序列进行预测时,将原始径流数据分解为多个分量,VMD可以手动选择模态个数,且较EMD能更好地避免中心频率混叠的问题,同时增加了数据量,为数据驱动模型提供了良好的数据基础,因此先将月径流序列进行VMD分解是必要的。
2) CNN-LSTM模型较于单一的LSTM模型能更好地提取特征,且对于峰值谷值的预测更为精确,提供更高的预测精度。本文将VMD-CNN-LSTM模型应用于渭河流域的张家山站,魏家堡站的月径流预测中,相较于EMD-LSTM、EMD-CNN-LSTM、EMD-LLSVM、VMD-LLSVM与VMD-LSTM能取得更高的精度与更低的误差,从而证明该模型的稳定性,为渭河的月径流预测提供了一条新的途径。
