基于在线学习数据的学习行为预测模型
2021-05-02骆莉莎黄星华
骆莉莎,黄星华,苑 溦
(江苏开放大学,江苏 南京 210036)
当前,网络学习已经成为重要的新型学习方式。2020年的突发疫情从客观上快速将线上教育推向了普遍化与大众化。然而,这一快速转变也潜藏着很多实际问题,比如学生短时间内还不能适应新的学习方式,传统课堂学习评价重结果轻过程的模式已经不再适用。
许多学者对于线上教育的评价方法进行了系统研究。冯天敏和张世禄[1]指出,在线学习的评价目的在于监控学习进程、保证学习质量、促进学生发展。雷军程[2]比较了Udacity、Coursera、Edx 三大MOOC 平台的课程评估方式,发现其评价模式与目前传统课堂教学的评价模式类似。代利利和李经山[3]指出,翻转课堂学习需对评价体系的基本价值取向、三个关键维度和指标构成、操作方法和权重分配等进行设计。其他学者[4-5]都对在线教育评价进行了研究。
综合已有研究来看,如何利用大数据挖掘技术分析在线学习行为,采用合理、科学、创新、量化的评价手段反映学生学习过程的每个环节,已经成为当前研究的热点。本文将讨论如何基于在线学习数据实时预测学生的学习行为。
1 LSTM 神经网络模型
学生学习是一个循序渐进的过程,在线学习平台可以记录学习过程中每个阶段的学习数据,这些数据可以看做时间序列数据。人工智能领域的循环神经网络最适合处理时间序列问题。RNN 的特点是隐藏单元间的连接是循环的;如果输入的是一个时间序列,可以将其在时间维度展开,其中的每一个单元,除了处理当前时间点的输入数据外,还要处理前一个单元的输出,最终输出一个时间序列。然而,RNN 模型无法学习到“长依赖”的问题。随后出现了LSTM(Long Short-Term Memory)长短期记忆网络以消除RNN 长期依赖不可靠的问题。
LSTM,是一种特殊的RNN,能够学习较长时间范围内数据的依赖关系,如学生近一个月的学习状态对接下来一周的学习状态的影响。LSTM 是为了避免“长依赖”问题而精心设计的。LSTM 也拥有RNN 的链状结构,但是重复模块则拥有不同的结构。与神经网络的简单的一层相比,LSTM 拥有四层,这四层以特殊的方式进行交互,其结构如图1 所示。

图1 LSTM 神经网络模型
2 数据集与模型训练
本研究基于某课程的在线教学平台自动统计的学生学习数据开展模型训练。本次研究共使用了两个在线教学班(共145 名学生)的在线学习时间序列数据。
本文训练的神经网络模型的目标在于找到学生学习时间序列的某种规律以指导教学。为此,需首先回答以下两个问题:
应该用哪些数据来衡量学生的学习情况。因本研究针对的是学习的时间序列数据,首先要求这样的数据应该是随着学习进程推进能实时收集、不断扩充的数据,而不是单个时间点的数据;因而,期中考试成绩、期末考试成绩不能作为衡量数据。其次,由于涉及数据量大,这样的数据应该是能够自动采集的,而不需要太多教师手动的操作;因而,在线学习平台自动记录的数据更加符合要求,如教学资料的学习时长、学习次数、反复查看次数、学习资料的下载次数、签到数、讨论参与次数、章节测验成绩(系统自动批改)等。再次,学习数据应该是多维的,用于学生学习情况衡量的数据应该既包括学习过程的参与程度数据,也需要包括学习效果的衡量数据;只注重其中一个方面是偏颇的。经过数据筛选,本研究采用学生对学习视频的观看次数和章节测验(系统自动批改)成绩作为学生学习参与程度和学习效果两方面的评价。
对于学生的学习数据时间序列,究竟应该用前多少次的学习数据预测接下来一次学习的学习数据?这个问题在已有研究中并没有确切的方法。首先,学生的学习时间应该遵循一定的规律,一般我们希望学习时长是稳定的,使得学习进程是持续稳定高效推进的。然而,各种因素都会影响学生在特定时间点的学习投入程度,可能的因素(包括但不限于)如下:(1)该时间点学生恰好有其他事务导致学习时间明显降低甚至为零;(2)该部分课程教学资源较为枯燥,学生普遍没有学习兴趣;(3)学生基于之前的学习时间和测试分数认为该门课程较为简单,投入时间不足。对于第(1)个因素,因属于学生的个人偶然因素,教师难以控制,在本研究的模型中也的确难以体现,故在LSTM 模型中增加了Dropout 层,可在一定程度上消除随机因素对本研究模型预测效果的不利影响。对于第(2)、(3)个因素,可以通过课程学习数据反映出来。本研究通过数据分析来寻找答案。为此,以145 名学生的学习数据为数据集进行研究,70%作为训练集,30%作为测试集,以均方差作为模型优劣的衡量参数。LSTM 模型的结构为四个堆叠LSTM 层,每层配置一个随机Dropout层,最后通过一个全连接层得到输出值(输出值即为下一次视频观看时长)。结果如图2 所示。
图2 中,随着采用的前期数据量的增加,模型预测的均方误差逐渐减小,预测精度逐渐升高。当采用的前期数据量较多时,在实际教学过程中,需要前期有一定时长的教学活动之后本研究的模型才能开始发挥作用,不利于教师及时了解学情;当采用前期数据量较少时,模型精度无法保证。对比图2 中某学生学习数据的实际预测效果,综合考虑,可选择采用前5 次学习数据预测下一次学习数据,由此平衡了模型精度与教学反馈及时性的矛盾。
3 模型应用分析
为检验模型应用效果,以第一教学班数据作为模型训练与调试的数据集,随后以第二教学班在线教学过程作为本研究成果的模拟应用场景。
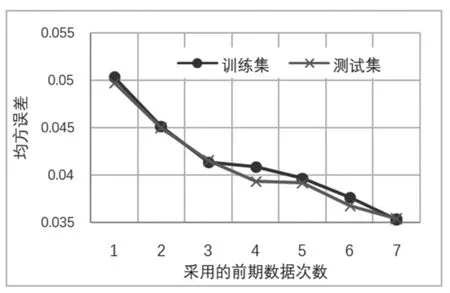
图2 模型误差与采用的前期数据次数
图3 为随机选择的12 位同学的学习数据(各个教学视频的观看时长)。图中,实心点代表实际数据,叉代表本研究模型的预测数据。可以看到,尽管有一定误差,但模型基本能反映数据的整体变化趋势。由于是根据前5 次学习数据预测下一次数据,故前5 次无预测数据。从图中可以看出本研究模型预测结果的一些特点:
(1)模型预测值与实际值相比,波动幅度更小。这是由于模型预测是基于全班所有学生的学习数据,反映的是学生的整体情况,相对个体而言更为稳定,因此波动较小。
(2)模型对学生的较大波动的学习数据有敏感的响应。当学生的某次学习时长有明显向上或向下跳动时,模型预测的下一次学习时长也将相应变化,说明模型能反映学生个性行为。
(3)模型预测具有一定保守性。当学生在某次学习中学习时长突然下降时,即使学生在下一次学习立刻恢复正常学习时长,模拟预测的学习数据仍然偏低,需要多次学习后才能恢复到与实际相当的预测值;而当学生学习时长突然上升后再次降低到稳定水平时,模型预测值也将快速降低,而不会维持在较高水平。

图3 不同学生各次视频观看时长预测与实际对比
4 结束语
本研究基于在线教学的学生学习数据构建了基于前5 次在线教学视频观看时长和各章测试成绩预测下一次在线视频学习时长的人工智能神经网络模型(LSTM 模型)。应用分析表明:该预测模型能很好反映学生的在线学习行为,具备满意的预测能力。该模型对教师实时把握在线教学学情有辅助作用。
