基于动态路由胶囊架构的电网客服优化设计
2021-04-30庞渊源朱晓鸿
庞渊源,田 然,朱晓鸿,王 鑫,陈 鑫
(国网江苏省电力有限公司信息通讯分公司,江苏南京 210000)
随着我国电力系统的大规模发展,电力客服系统的重要性日益凸显。仅以广东电网为例,高峰时期日均客服人员为320 人,人均处理客服业务两万宗。但基于人工的电网客服系统受到技术水平的限制,普遍存在客户满意度低,客户数据不能及时、有效地反馈等问题[1]。
基于信息检索与模板规则的聊天机器人已有较长的历史,在未有特定上下文的情况下,聊天机器人通过学习客服问题数据库,自动回答用户有关产品或服务的信息性问题。受到聊天机器人工作原理的启发,该文设计了一款基于动态路由胶囊架构[2]的电网客服应答系统。基于电网服务热线的数据库,使用深度学习与动态路由胶囊架构的新技术对客服工作进行优化改善,精准解决客户需求。
1 基于深度学习的语言预训练
用户与电网客户服务系统之间的对话,可理解为请求的一个单词序列映射到响应的一个单词序列,如图1 所示。深度学习技术可以应用于学习从序列到序列的映射,以建立更加符合用户需求的问答系统。
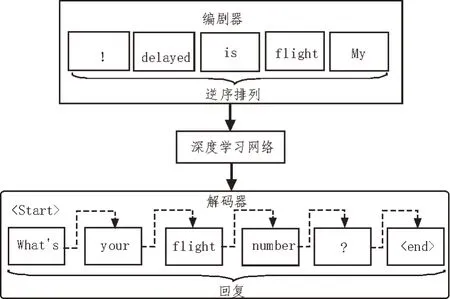
图1 用于对话的深度学习模型
1.1 序列到序列的深度学习系统
该系统由两个LSTM 神经网络[3]组成,一个用于将输入序列映射到固定长度向量的编码器,另一个用于将向量映射到可变长度输出序列的解码器。LSTM 神经网络可以在较长时间内,存储语言序列信息[4]并根据优先级学习阻止或传递信息,从而学习从语言序列到语言序列的映射。
1.2 Word2vec神经网络语言模型
用户请求的字词不能直接用作LSTM 的输入,每个单词转换为固定长度的特征向量。传统的基于词典方法,可以将用户语言转换为特征向量[5]。但用户语言中存在大量语句,无法在词典中找到映射关系。在词典映射法中将单词视为离散元素,并产生高维向量。因此必须学习大量参数,而这将会导致数据稀疏,降低模型的识别精度。
本次系统采用单词嵌入方法Word2vec 神经网络语言模型,以无监督的方式从客户与客服对话中学习语言的分布式进行表示[6]。每个嵌入维度代表单词的潜在特征,捕获有用的句法与语义属性。例如,在一个离散的空间中,“抱歉”、“道歉”与“高兴”之类的词互相等距。Word2vec 可以在连续的空间中表示这些单词,“对不起”与“道歉”之间的距离比“对不起”与“高兴”之间的距离短,从而增强了模型的识别精度[7]。
1.3 神经网络预训练
基 于“in_reply_to_status_id”和“in_reply_to_user_id”字段将每个回复与其请求进行匹配,重建数据库中的对话。在收集的超过260 万个用户请求中[8],有40.4%收到答复,87.6%的对话仅得到一次答复。对问答数据进行整理分类,建立深度学习的语言训练算法,如图2 所示。
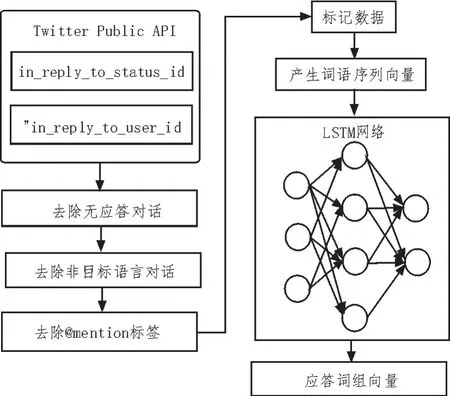
图2 深度学习算法流程
图2中,建立的深度学习框架训练问答系统如下:
1)清理数据[9]。删除了非目标语言的对话与带有图像的请求。
2)标记数据[10]。在对话数据库中建立最频繁的10 万个词组词汇表。
3)产生Word2vec 功能[11]。使用收集的词组词汇表训练Word2vec 模型,词汇表中的每个单词均被转换为640 维向量。
4)训练LSTM 网络[12]。LSTM 的输入与输出是单词序列的向量,而一个向量对应编码或解码一个单词。考虑到在客户的请求序列到任务序列中,深LSTM 较浅LSTM 具有明显的优势,因此使用随机梯度下降与梯度裁剪技术训练深LSTM[13]。
2 客服系统设计
在基于LSTM 训练的客服系统语句的映射关系基础上,使用MIML 框架。对于客服系统分析需求构建系统,设计动态路由胶囊架构的客服系统。
2.1 MIML架构设计
MIML 架构用于单个或多个实体对的文本语句集,由X={x1,x2,…,xn}进行表示[14]。假设有E个预定义关系(包括未知关系)要提取,对于每个关系r,预测目标由进行表示。
为规范客服系统的输入,对于每个句子x1,使用预训练的单词嵌入将每个单词标记投影到dw维空间上[15]。使用位置特征作为从当前单词到M个实体的相对距离组合,并将这些距离编码为M个dp维向量。对于单实体语句的对应关系提取时,令M=2;对多个实体语句对应关系提取时,令M=4(即两个实体对)。当两个元组有一个公共实体时,客服语句中有3 个实体,因此将到缺失实体的相对距离设置为较大数量。最终将每个请求句子转换成矩阵,如式(1)所示。
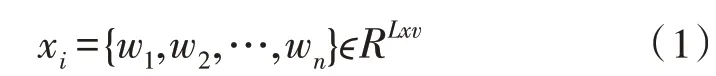
式中,L是规范化步长,V=dw+dp*M。
在此基础上,使用LSTM 网络来深度学习句子的语义。从两个方向将LSTM 的当前存储单元隐藏状态向量ht相结合,得出在时间t处的输出向量,其中B表示LSTM 网络的维数。
为了提高对客户请求的重点词组理解,引入词级注意机制,导入句子中几个与所表达关系相关的词。在每次迭代中选择表达含义可能性最高的词组训练模型,以提高模型的理解能力。
2.2 初级胶囊层设计
将胶囊的实例化参数集定义为Ui∈Rd,其中d是胶囊的尺寸[16]。定义跨不同窗口共享的滤波器为wb∈R2×2B,此时存在一个窗口以步长为1 的速度遍历语言序列,产生胶囊列表U∈R(L+1)×C×L,共C×d个滤波器,胶囊列表的元素,可由式(2)表示。
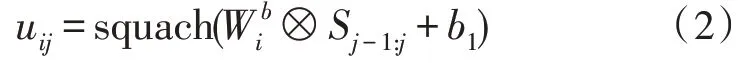
式(2)中,其中0<i<C×d,0 <j<L+1,,b1是偏差项。对于所有C×d滤波器,将生成的胶囊特征图重新排列为U={u1,u2,…,u(L+1)×C},其中共(L+1)×C个d维向量被收集为胶囊。
2.3 动态胶囊路由设计
生成对子向量的预测矩阵,如式(3)所示,同时,文中进一步研究了转换矩阵的计算方法。
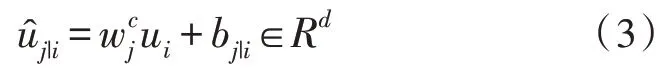
本次设计的动态路由方案可转换为非线性映射图谱,如式(4)所示。

在映射图谱的基础上,使用父代胶囊的存在概率迭代修改胶囊间的连接强度,每个单独连接k的边际损失Lk,如式(5)所示。
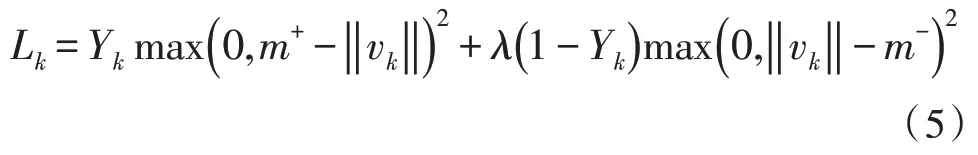
其中,若连接k存在,则Yk=1,m+=0.9,m-=0.1,λ=0.5。胶囊网络的总损失LTotal可以表示为
2.4 模型预测
动态路由架构中使用到的相对关系特征提取可分为:单实体关系与多实体关系。对于单实体对关系提取时,通过计算代表每个关系的概率向量uj的长度实现。对于多个实体对的关系提取时,选择前两个概率大于阈值的胶囊连接关系。最终,可以得到预测关系r。对于一对实体(e1,e2),为了选择胶囊元组所属的关系,计算实体与胶囊关系的预训练嵌入系数rk=arg min|t-h-rk|。其中,t、h分别是实体e1与e2的关系系数,rk是实体间关系比重。
3 实验与评价
为验证本次基于动态路由胶囊架构的系统,使用混合CBR-ANN 方法对其性能进行评估。该方法基于LVQ3 神经网络执行CBR 循环任务,综合评价系统的性能。基于k近邻(KNN)的传统CBR 系统需要调用含有所有案例数据库,以执行准确的检索。通过训练对数据库知识泛化,CBR-ANN 方法较大地减少了搜索空间。
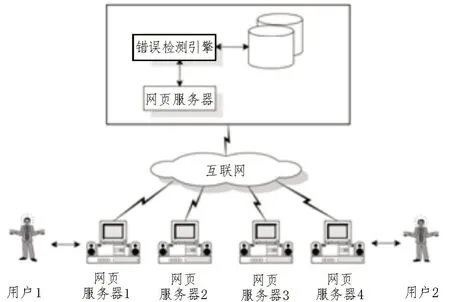
图3 验证平台
如图3 所示,验证平台基于333 MHz 奔腾II 的Windows NT 操作系统,RAM 为128 MB。网页服务器Netscape Enterprise Server 3.0 用作超文本传输协议(HTTP)服务器。故障诊断引擎采用Microsoft Visual C ++链接到Web 服务器的通用网关接口(CGI)程序实现。Microsoft Access 数据库管理系统用于存储客户服务数据。
3.1 算法检索效率实验
首先,进行客服系统神经网络的检索效率实验,通过记录网络预训练时间、总训练时间与平均在线检索时间来衡量检索效率。在数据库中存在9 392例有效客服需求案例,关键字列表中可查的关键字数量为2 173。在Wordnet 词典中检索的单词数为121 962,用户输入的最大关键字数为20。实验统计结果,如表1 所示。
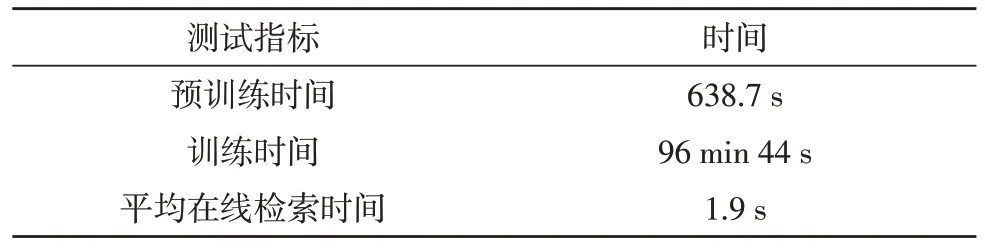
表1 算法检索效率测试结果
表1 中,尽管总的训练时间较长,但由于系统仅需在离线模式下进行一次训练,因此系统的实例化成本仍较低。另外,平均在线检索时间仅为1.9 s,可做到实时反馈。
3.2 检索精度实验
检索精度取决于客服系统的预处理设计精度,添加新关键字的频率、胶囊架构的辨错率及用户请求表达的准确度。对本动态路由胶囊系统设计实验,测量正确辨别客户需求的次数,以及所需的检索迭代次数来检验系统的检索精度。若用户输入由众多新关键字组成,则这些关键字不属于关键字数据库,且准确性会受到影响。因此系统通过继续学习,以提高检测的准确性。
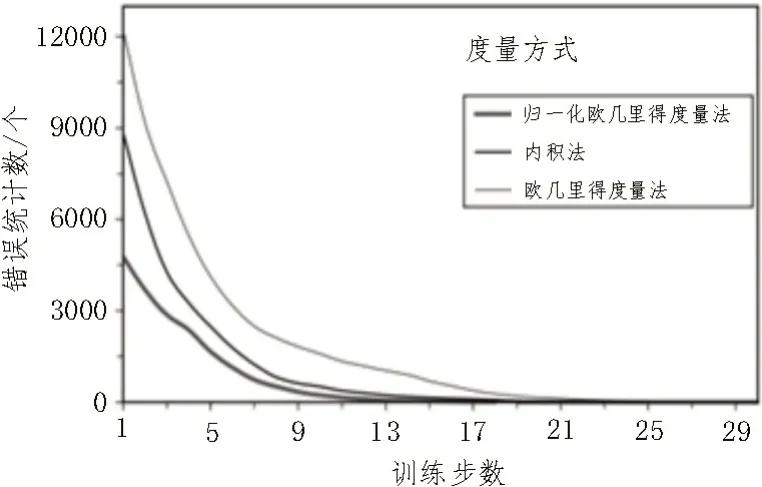
图4 3种度量下的模型训练
图4 所示为距离度量和训练时期对准确性的影响。欧几里得距离度量标准的错误率最高,而标准化欧几里得距离方法的错误率最低。在神经网络收敛之前所需的训练时期,错误计数是指在训练集中的70 137 条记录中,由神经网络计算出的不正确输出的数量。

表2 系统检测精度结果
如表2 所示,使用3 种方法度量系统的检测精度可知,欧几里得距离度量的错误率最高,而归一化欧几里得距离法的错误率最低。
3.3 技术对比实验
在该节中将基于动态路由胶囊架构的客服检索技术与传统基于CBR 系统中的KNN 检索技术进行比较,分别对比基于服务记录的测试集,与基于用户故障描述的实验性能,结果如表3 所示。
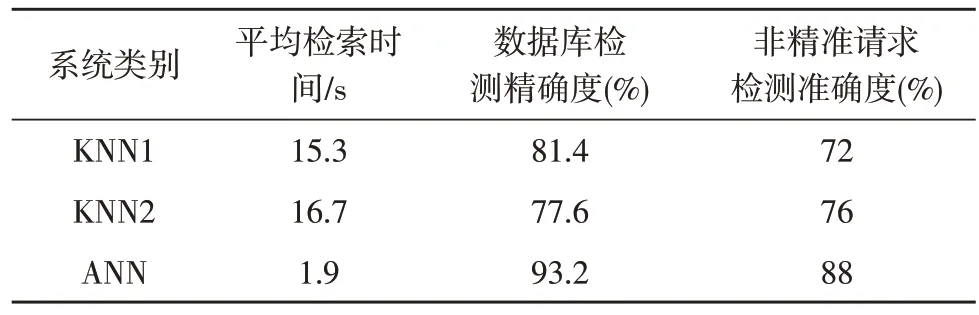
表3 技术参数实验测试结果
实验的第一部分中,使用了15 850 条测试服务记录的测试集,动态路由胶囊架构技术在速度与准确性上均优于KNN 方法的两种变体。在使用欧几里得距离法进行匹配的KNN 技术中,KNN 架构始终为各个关键字分配相等的权重,且检索进度大幅下降。在使用模糊三元组匹配的KNN2 技术中,KNN网络为匹配的3 个字母每个序列分配不同的比重,尽管提高了对关键词的容错能力。但与动态路由胶囊架构相比,检索精度仍较低。
实验的第二部分中,为了检验系统在客户输入无法准确描述故障条件下系统的检测精度,采集了共50 个不准确的故障描述。分析表3 可发现,所用3 种检索技术的准确性均较低。动态路由胶囊架构的准确性为88%,KNN1 技术的准确度为72%,而KNN2 技术的准确度为76%。KNN2 使用的模糊三字匹配法较KNN1 技术使用的欧几里得距离匹配具有更优的性能,能够处理用户输入中的拼写错误与语法变化。但由于其未像动态路由胶囊架构那样考虑客户输入语句的同义词形式,因此其准确性低于动态路由胶囊架构。
4 结束语
该文基于对现有人工客服系统的分析,通过与聊天机器人的技术原理进行比较,设计了一款基于动态路由胶囊技术的客服系统。对客户语言使用基于深度学习的技术进行语言预处理,基于现有数据库,设计形成多种语言、深层次的智能化客服系统并实时采集数据。通过人工智能技术不断完善服务水平,以增强系统对客户意图需求的理解能力,提高了电网客服的工作效率与自动化程度,进一步提高了服务水平。
