基于云计算的电力服务大数据共享系统设计
2021-04-30顾晶晶
俞 阳,顾晶晶
(1.国网江苏省电力有限公司营销服务中心,江苏南京 210019;2.国网江苏省电力有限公司句容市供电分公司,江苏句容 212400)
工业电力数据的采集结果受到天气、能源等数据之间关联性的影响,导致电力数据类型不断增多,电力大数据实时处理的特点使其对数据处理和分析的速度要求更高[1]。有效使用软硬件资源、降低投资、节约成本、及时挖掘出知识的“金块”数据海,使员工能够获得高层次知识,有效地管理和控制电网的重要决策,是解决大数据时代网格控制难题的有效方法之一,电力企业共享大数据就是其中一种[2]。以往一直采用经典的粗糙集理论来减少时间复杂性,提高工作效率。但是,这些属性约简算法假设所有数据都一次性加载到内存中,显然不能共享电力服务大数据[3]。在传统关系数据库技术的基础上提出的属性约简共享方法,在处理小规模属性约简问题时具有很好的时间性能,但由于硬件的严重限制,这些方法能够处理的数据量和及时性都很低,导致共享周期很长[4]。针对这一问题,提出基于云计算的电力服务大数据共享系统,借助软硬件资源来处理大量增加的电力服务大数据。
1 特征分析
智能电网中的发电、配电、传输、销售、管理等各个环节都会产生大量的数据,称为电力服务大数据。该系统是通过各种设备上部署的大量传感器、每个用户家庭安装的智能电表、市场营销系统收集到的客户反馈等多种数据源生成的,并汇集为一个集中的数据中心进行统一存储管理。电力服务数据具有体量大、种类多、速度快等特点[5]。
1)体量大
随着智能电网建设的深入,设备传感器、智能仪表等终端数据采集设备已经密集部署,数据采集规模将呈指数级增长,达到TB 甚至PB 级别[6]。
2)类型多
除传统的结构化数据外,生产管理、营销等系统也产生了大量的音频、视频等半结构化、非结构化数据[7]。资料种类的多样化要求存储与处理技术的多样化,研究的重点是电气信息采集的数据处理系统,仍然是以结构化数据为主,没有对半结构化和非结构化数据的处理进行讨论[8]。
3)速度快
大容量数据的采集和处理速度极快,终端数量的迅速增加,对存储系统提出每秒可达到数十万次数据吞吐量的要求[9-11]。
2 系统结构设计
电力服务云计算大数据共享系统由超级节点和终端节点两部分组成,各节点之间通过无线传感器网络连接。系统硬件结构如图1 所示。
在电力服务大数据共享系统中,超级节点为系统提供终端节点发现、资源发布、内容定位等服务,同时为所有终端节点提供注册信息和元数据[12-13]。主要负责本地资源库的管理、电力服务的大数据共享和元数据文件生成[14-15]。
In America,where the white dominate the country,the black belong to a culturally subordinate group.In a similar way,female belongs to another culturally subordinate group in patriarchal culture.
2.1 微处理器
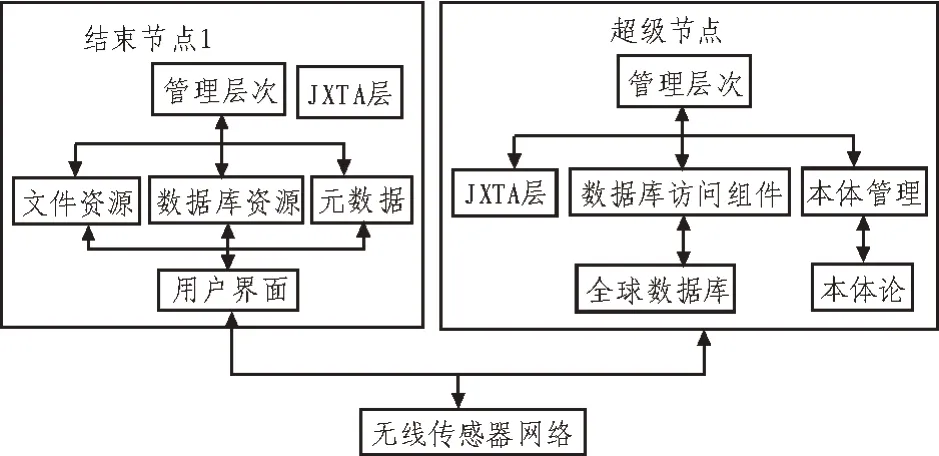
图1 系统硬件结构
选用PIC18LF6680 单片机作为超级节点主控制器的核心处理器,内置8 位RISC 处理器核心,外置10 MHz时钟驱动,内置锁相环,最高驱动频率40 MHz,最大容量4G;64K 增强自编程闪存,3.5K 高速、全静态随机存储器,1K 可擦式可编程存储器;此外,处理器还集成了许多外部设备。扩展处理器外设上的4 个按钮,输入一些命令信息;展开4 组数码管和2 个led 显示节点的工作状态;在实际操作中,设备的按钮和显示器组成一个简单的人机交互界面,便于开发和调试节点软件[16-18]。
将标准RS232 串口扩展为MAX232 级转换器,以方便接口调试。使用者可以透过电脑观察结点的工作状况,并充分考虑到某些仪器会使用CAN 总线。SN65HVD230 收发机扩展了CAN 总线接口,支持CAN 总线接口协议。
2.2 数字传感器
在生产单总线设备时,将一个64 位的二进制ROM 代码写成芯片序列号。通过这种方式,每一个设备都可以通过寻址进行识别。64 位的ROM 代码结构如下:前8 位为产品类型,后8 位包含56 位CRC校验码,并包含每个设备的序列号。DS1820 型号传感器如图2 所示。
图2 DS1820型号传感器
用DS1820 型传感器涂覆3 针的PR-35 或8 针的SOIC,GND 作接地处理;用I/O 作数据输入/输出,用PR-35 作漏电保护;VDD 作为外部+5 V 电源端,未用时应接地;NC 为空针头。该数字传感器包括寄生电源、单接口的64 位激光动态存储器和一块平板式静态存储器,主要用于存储共享资源。由于每个DS1820 包含一个硅序列号,因此可以将多个DS1820芯片连接到总线上。DS1820 只有一条接口线(单线接口),可以读写DS1820 的信息,也可以从数据总线获取电力服务大数据。DS1820 只有3 个引脚,其中两个连接电源VDD 和GND,另一个连接总线DQ(数据输入/输出)。它的输出和输入都是数字信号,与TTL 电平相容,可以直接与单片机相连,缩短转换时间。
3 系统功能设计
在数据共享中,最重要的部分是平台层。通过信息共享平台,用户可以对信息进行查询和反馈,并具有安全监测功能。对于节点规模较大、节点结构完整的应用层,通过相应设备就可以满足不同节点的信息需求。云计算共享的基本原则是:筛选大量的共享模型,建立电力服务大数据共享模型的排序方法,从而达到最优和最完善的效果。其具体过程如下:
设M(t)为互补判断矩阵,当时间t为0 时,可设置迭代判断次数为n。最小非负偏差量为,最大非负偏差量为,其中i、j表示电力服务大数据最小和最大数量。根据式(1)求取互补判断矩阵M(t)一致性指数:
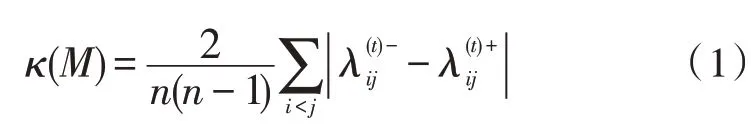
如果互补判断矩阵M(t)一致性指数小于设定的阈值,那么需直接输出互补判断矩阵结果,否则需重新选择数据来判断。根据该结果,对云计算环境下电力服务大数据共享模式展开分析,以此获取最优共享结果。
4 实 验
基于云计算的电力服务大数据共享系统实验验证过程中,数据库服务器选用的是MySQL 数据库,应用服务器为tomcat,对电力服务大数据系统访问流程如下所示:提出访问申请,接收器接收到正确地址,按照负载均衡方案,请求结果被转发到虚拟机上进行数据交互。
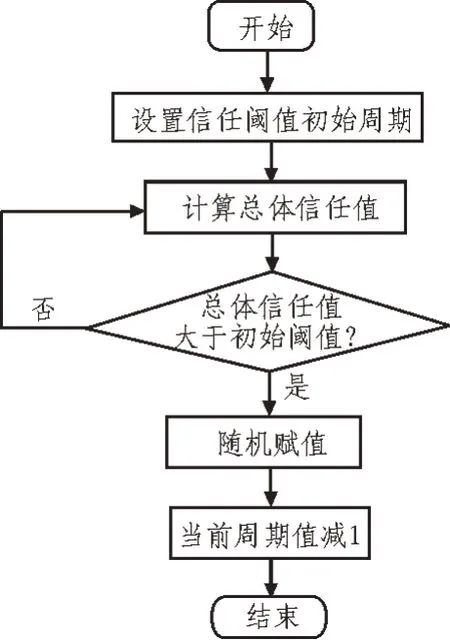
图3 干扰数据检测流程
4.1 开发环境部署
将Java 作为开发语言,将struts 作为系统框架,将tomcat 用作应用服务器,SQL Server2012 用作系统开发中的数据库管理系统。Myeclipse7.0 也被用作开发工具。利用Cooja 网络模拟器进行模拟实验,利用HMACMDS 算法生成认证消息代码,并与tinyDTLS 库验证数据源。在仿真中使用的网络拓扑如图4 所示。
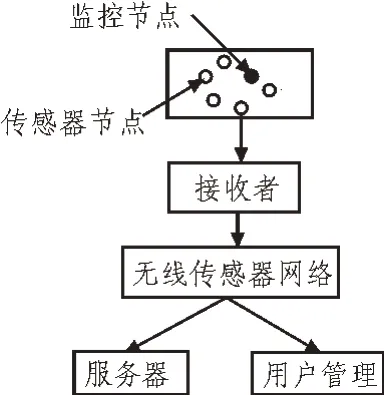
图4 网络拓扑结构
模拟期间没有考虑信息延迟,之前信任值与当前信任值中新产生的信任值相同,所以所有权重设为0.5。通过仿真实验,分析了由于错误信息而导致正常节点整体信任度下降的原因。
4.2 共享效率实验分析
4.2.1 数据干扰情况下共享效率对比分析
1)创造虚假信息
创造虚假信息对数据共享造成一定干扰,基于该情况分别使用基于经典粗糙集理论共享系统、基于传统关系数据库技术共享系统和基于云计算共享系统分析电力服务大数据共享效率,结果如图5所示。
由图5 可知,使用传统两种系统的数据共享效率都低于70%,而使用基于云计算共享系统数据共享效率始终高于85%。
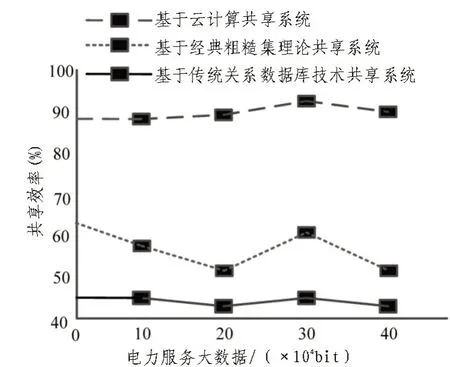
图5 创造虚假信息情况下3种系统共享效率对比结果
2)多个攻击点
由于共享系统是由大量数据汇集经过处理后组成的系统,因此容易受到多个攻击点攻击,导致数据中干扰数据较多。基于该情况将3 种系统共享效率进行对比分析,结果如图6 所示。
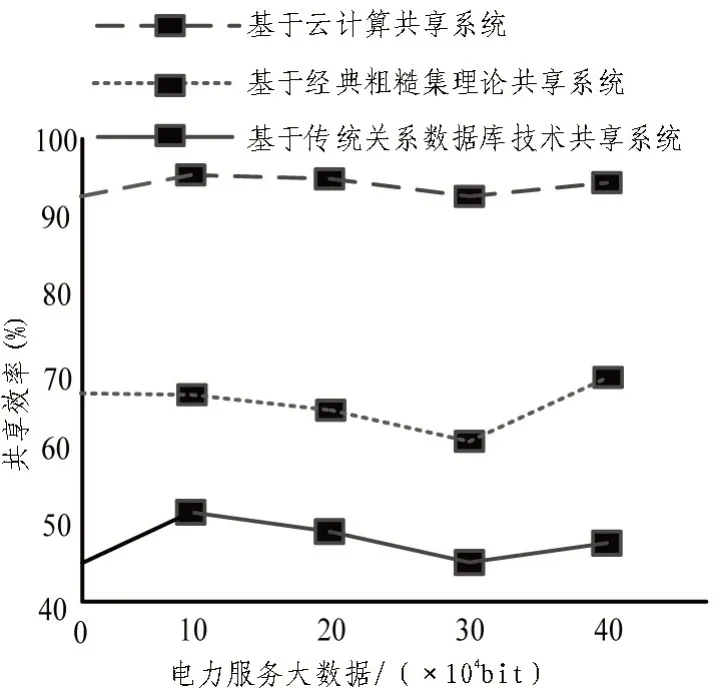
图6 多个攻击点情况下3种系统共享效率对比结果
由图6 可知,在该情况下3 种系统共享效率与创造虚假信息干扰行为相比都呈现出上升趋势,使用基于云计算共享系统数据共享效率始终高于90%。
通过分析结果可知,基于云计算共享系统在数据干扰情况下共享效率较高。
4.2.2 正常情况下共享效率对比分析
为了进一步验证该系统设计的合理性,剔除干扰数据,如图7 所示。
在主机训练集的范围内,数据能够正常工作。若监测到的数据异常,则表示受到攻击。如监控数据正确,则需要修正。在此基础上,提出了共享系统V1 的经典粗糙集理论、传统关系数据库的共享系统V2技术、基于云计算的共享系统V3技术,用以比较分析电力服务大数据共享的效率。表1中列出了结果。
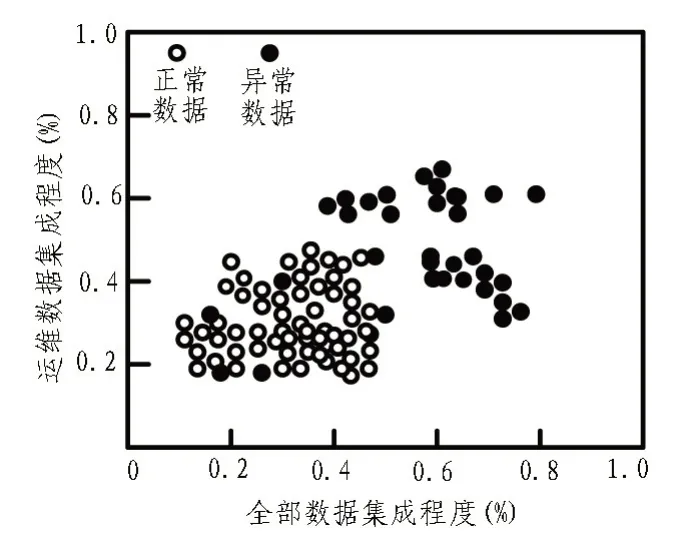
图7 剔除干扰数据
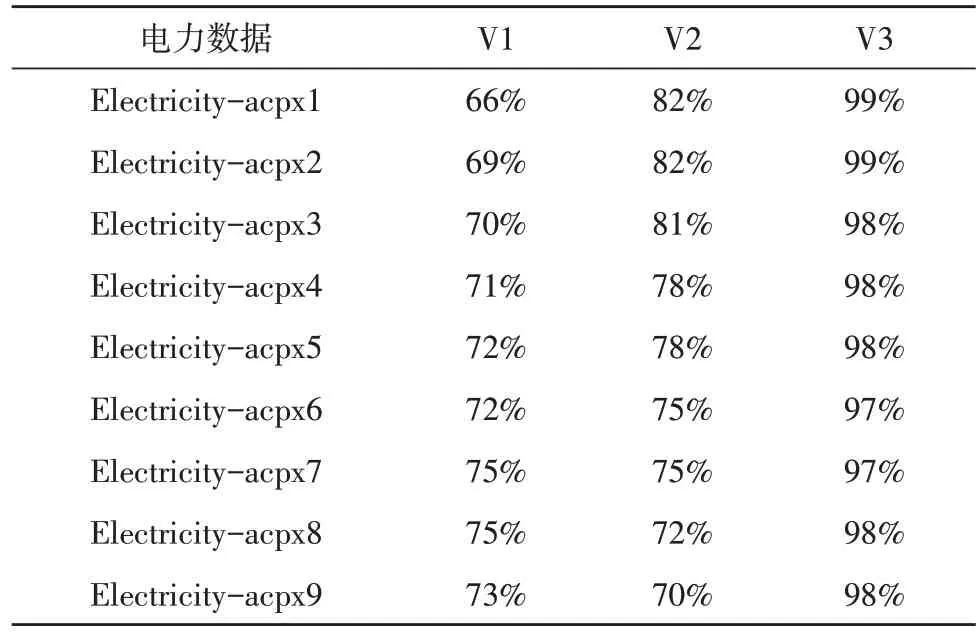
表1 3种系统共享效率对比分析
由表1可知,在无干扰数据情况下,3种系统共享效率都相对较高,绝大部分超过70%,具有良好共享效率。
5 结束语
针对电力服务的特点,以云计算为背景,结合云计算技术的最新发展,建立基于关系数据库电力服务的电力数据分析系统,解决电力数据分析系统性能和可伸缩性瓶颈问题。实验结果表明,该系统性能优良,能有效地提高硬件资源利用率,缩短应用程序的响应时间。为了应对电力大数据爆炸给数据分析技术带来的挑战,未来还可以增加支持跨数据中心的分布式存储系统和工作流管理模块。
