图神经网络在自然语言处理中的应用
2021-04-29陈雨龙付乾坤
陈雨龙,付乾坤,张 岳
(1.浙江大学,浙江 杭州 310027;2.西湖大学 工学院,浙江 杭州 310024;3.西湖高等研究院 前沿技术研究所,浙江 杭州 310024)
0 引言
自然语言处理中存在很多图结构。如图1所示,从句法结构、语义关系图、篇章关系结构,到实体和共指结构、关系结构和知识图谱,都是一般的图结构。一个句子内部的字、词相邻关系也构成图结构。形式上,图由节点和边组成。本文以三类图结构为例,观察自然语言处理任务中相关的节点和边,以便更具体地了解这些任务所对应的图。
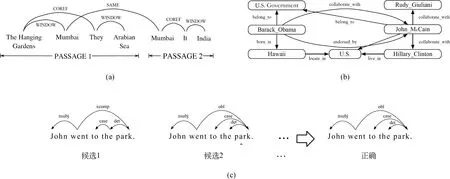
图1 自然语言处理中的图结构
第一类图结构是基于句子的语言结构。已有研究表明,对关系提取、机器翻译和其他自然语言处理任务,句法[1]、语义[2]和篇章结构信息[3]非常有用。因此,一种在句子上定义图结构的方法是把每个词当作节点,并把句法依存关系、语义角色和篇章关系等节点之间的链接当作边。我们可以在相邻单词之间添加多种类型的边,从而形成一种具有统一节点类型但具有不同边类型的图。
第二类图结构是基于文档中的实体和共指关系连接构建的,如图1(a)所示。对于机器阅读的任务,有研究表明,为了正确地回答问题,对参考文档中不同的句子进行推理可能是有必要的[4]。一种为这种推理构建图结构的方法是把文档中提及的实体作为节点,并把实体之间的共指链接作为边。另外,除了文本文档中的实体,知识图谱中的实体也可以使用图神经网络进行编码,如图1(b)所示。
第三类图结构可以是结构预测任务中的图结构本身。具体来说,如图1(c)所示,多个基准结构化预测模型给出的候选图结构可以使用图神经网络表示来进行重排序。这样的候选图结构可以由一个基线系统的k个最优的输出结构组成。当将这些结构整合在一起形成一个图时,可以提取其中有用的特征,以便从中进一步预测出正确的输出[5]。
近年来,图神经网络已被广泛运用到自然语言处理的大多数任务当中。有一系列的工作利用图神经网络对上述几类任务中的图结构进行编码,从而更充分地得到相关表示,能有效地解决相关问题。本综述系统性地汇报相关工作,首先介绍图神经网络的基本概念,然后根据不同任务,分别介绍图网络在自然语言处理中的应用。与已有的图神经网络综述[6-7]相比,本文针对自然语言处理进行详细阐述。
1 图神经网络的基本概念
深度学习在自然语言处理中的应用是从序列表示开始的[8-9]。不同神经网络架构被用来编码句子和篇章。这种序列输入的编码方式具有很强的表达能力,给众多自然语言处理任务带来了性能提升。然而,序列编码网络不能直接从树、图状等常见结构中提取深度学习特征。有后续研究把序列编码器扩展为树状结构编码器[10-12]或者有向无环图(directed acyclic graph, DAG)编码器[13]。这些编码器可以解决句法树和包含限定指代关系等结构的特征提取问题,但是,它们不能作为一般图的编码器,解决环状结构的特征提取。
图2(a)展示了一个抽象语义表示(abstract meaning representation,AMR)结构,对应的句子是“The boy wants to go”。在这个AMR图中,节点“boy”是节点“go-01”和节点“want-01”的施事(agent)。此外,节点“go-01”还是节点“want-01”的受事(patient)。这种关系形成了一种有向无环图,此处“环”指信息,从某一节点流出,并回到该节点。这种图结构是无法用树状LSTM直接建模的。然而由于这种图是有向的,我们仍可以定义一个时间顺序,用循环神经网络计算隐含状态。此类时间步顺序在序列LSTM中从左到右,在树状LSTM中自底向上。通过这种结构,信息在不同节点中一层层传递,以学习全局特征。事实上,对序列和树状LSTM结构稍加修改就可以用来对DAG进行建模。

图2 图神经网络基本思路
图2(b)展示了一个更一般的语义图,这种语义图具有循环结构。与树和DAG相比,此类图的表示更富有挑战性。具体来说,环路会导致图中节点失去自然顺序,而后者是定义循环神经网络时间步的基础。为了解决这个问题,可以使图中节点隐含状态的计算独立于节点的顺序。对于序列和树状LSTM,隐含状态是计算当前输入在长期记忆作为上下文时的语义表示。对于有环图,我们也希望每个隐含状态能够表示图级别上下文中的节点。为此,可以让每个节点循环地从其邻居节点收集信息,以提取上下文特征。
1.1 图神经网络(Graph Neural Network, GNN)的基本思路
如图2(c)所示,为了实现上述目标,本文选取图的边的正交方向作为时间步的顺序方向,以便节点的隐含状态能够沿着图的结构循环地进行信息交换。可以将图2(c)视为图2(b)中图结构的一系列“快照(snapshots)”,每个快照对应于一个循环时间步。在每个时间步,每个节点的隐含状态表示可以通过利用上一个时间步中该节点和其邻居节点的隐含状态信息来进行更新。其中,邻居节点是指与该节点有一条边连接的其他节点。通过这种方式,节点的状态以一种不断增大上下文信息的方式被迭代更新。具体而言,对于图2(b),每个节点的状态分别在经过1、2和3个循环步骤之后,能够捕捉到距离2、4和6个边之内的节点的上下文信息。
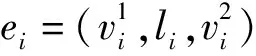
1.2 图循环神经网络(Graph Recurrent Neural Network,GRN)

(1)

1.2.1 无向图的消息计算
(2)

(3)
其中,emb 表示节点的嵌入,embe表示边的嵌入,l(i,k)表示vi和vk之间的边的标签,Wx和bx是模型参数。
1.2.2 有向图的消息计算

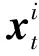
emb(vk)]+bx↑)
(7)
emb(vk)]+bx↓)
(8)
(9)
其中,Wx↑,bx↑,Wx↓和bx↓是模型参数。与式(3)中相似,l(i,k)表示从节点vk到vi边的标签。
1.2.3 消息传递中隐含状态的计算
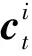

1.3 图卷积神经网络(Graph Convolutional Neural Network,GCN)
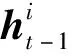
(16)
式(16)可以被视作一个标准卷积滤波器(convolutional filter)操作,其中,Wm,Wx和bx是模型参数。
1.3.1 区分不同边标签
一种GCN的变体使用不同的权重收集来自不同类型边的信息(即具有不同标签的边)。即将连接节点vi和vk的边标签表示为l(i,k),将vi和vk的边的方向表示为 dir(i,k)。可以通过将式(16)替换为式(17)、式(18)来定义GCN。

1.3.2 添加控制门

(19)
使用控制门后,可以将式(17)拓展为式(20)的形式:
(20)
1.3.3 与GRN的比较
GRN和GCN之间的差异与RNN和CNN之间的差异类似。前者具有更多的模型参数,因此可以具有更好的性能,但是其运行效率较低。
1.4 图注意力神经网络(Graph Attention Neural Network,GAT)

(21)
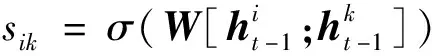
(22)

(23)
其中,W是模型参数。
为了得到更好的性能,可以使用Transformer[20]结构代替式(22)和式(23)。
1.5 图神经网络与序列、树神经网络之间的关系
由于序列与树状结构也属于图结构,图循环神经网络可以应用于序列和树结构。由图网络实现的序列S-LSTM[13]与树(GCN for relation extraction表示)[5],与传统LSTM、树状LSTM有着本质区别。与这些模型相比,图LSTM[14-15]具有两个主要优点。首先,在序列和树状LSTM中,节点之间的信息交互是单向的:节点仅能接受来自其前驱节点的信息,而无法接受后继节点的信息(双向LSTM是一种解决办法)。相比之下,图LSTM允许节点同时与其所有邻居节点进行信息交互,而与节点间边的方向无关。这种机制可以实现更丰富的信息集成。其次,图LSTM允许图中所有的节点进行同步的更新,因此,与序列和树状LSTM相比,它的并行化程度更高。就节点数而言,循环时间步T的总数可能少得多,因此在并行化时,图LSTM可以比树状LSTM更快。
GCN和GAT可以分别视为限制上下文节点的CNN和SAN的通用形式。具体而言,CNN可以被视作一种特殊的GCN:其通过在局部邻接词节点窗口上添加无向边来为句子定义图结构。Transformer模型可以视作是一种针对句子的GAT形式,其中所有词节点以全连接的方式形成图。需要注意的是,不同类型的图神经网络之间的边界不是很严格。例如,带有门的GCN与GAT非常相似。根据图的不同形式,节点和边的参数化可以非常灵活。例如,在GCN中,不同的参数矩阵可以适用于不同类型的边。
图神经网络也可以看作是一种特征整合的方法。在图神经网络中,以图节点表示原子特征,并在特征图上进行其特征交互,以此实现这两者的组合。图结构的定义是自然语言处理任务中设计图神经网络的关键,图结构需要由人工进行设置,并且在训练过程中无法调整。因此,离散的图结构可以视作各个特征之间关联的一种先验知识。节点之间的信息交换或显式特征组合是在图结构上进行的。
2 图神经网络的应用
本节具体讨论图神经网络在自然语言处理不同任务中的应用。我们以任务为单位总结不同文章,同时也考虑到图神经网络从简单到复杂,以及发表时间的顺序。
2.1 阅读理解(Reading Comprehension)
机器阅读理解[4]的输入是一个篇章,以及一个和篇章相关的问题。输出一般是从多个选项中找到最符合问题的答案。机器阅读理解的数据集有很多,简单的数据集,比如SQuAD[21],只需要从篇章中找到直接相关的事实。更复杂的阅读理解,需要从多个相关的事实中整合信息,如HotpotQA[22]、RACE[23]、MCTest[24]等。如图3所示,在WikiHop[25]这个数据集中,一个问题的答案,往往需要从多个事实中找到线索,并且进行整合。

图3 机器阅读理解问题
代表性工作1:实体图为有效地整合信息,Song等[4]以文本中提到的命名实体和代词为基础,构建图结构。具体而言,命名实体和相关的代词被当作图中的节点。同时定义三种节点之间的边。第一种是指代类型的边。比如一个代词和其所指代的名词,这种边可以被称作coref。第二种是不同句子中相同的命名实体之间的连边。这种边可以增强不同句子之间的线索联系,可以被称作same。第三种是同一个句子之间,一个固定窗口之内的不同实体之间的边。这可以当作是一种局部关系特征。这类边可以被称作window。最终形成的图结构如图4所示。
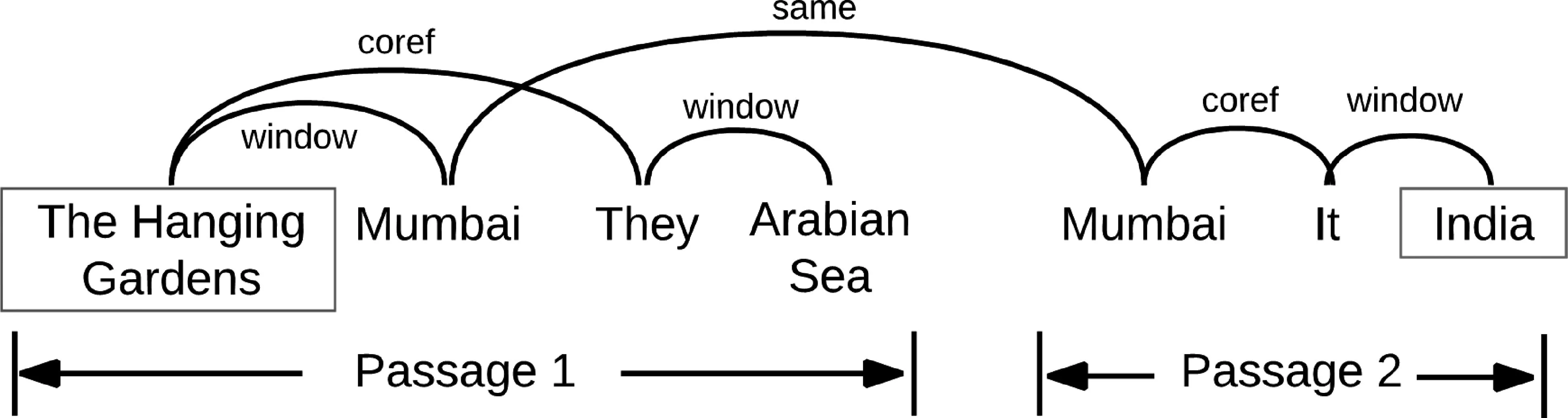
图4 Song等文中图结构定义
这种图结构给不同线索的整合提供了依据。由于图中可能存在循环边,可以利用图循环神经网络对线索整合图进行编码。具体而言,如图5所示,给定一个篇章和相关问题,Song等用循环神经网络先对它们各自进行LSTM序列编码,得到每一个词的隐状态表示。在此基础之上,Song等以相关实体和代词的隐状态作为图神经网络节点状态的初始值,进行图循环神经网络的迭代。经过几轮信息交互,相应的实体和代词的隐状态表示被用于进行答案选择。

图5 Song等文中模型结构
为了选择答案,Song等用不同步骤的篇章以及问题的隐状态和候选答案进行匹配,并把这些不同步骤的结果进行加权平均,得到最终的答案打分。通过整个网络进行端到端的训练,实验表明,这种基于图的信息整合显著地提高了问答质量。与不进行信息整合的局部编码方法相比,以及与只使用指代关系作为信息整合线索的方法相比,性能得到显著提升。
在Song等[4]工作基础之上,Cao等[26]引入了更多边的类型,以及ELMo上下文嵌入向量特征;Tu等[27]进一步探究了由不同类型节点(包括文档、问题和候选答案)构建的异构图带来的影响。
代表性工作2:动态推理受到认知科学研究中双加工理论的启发,Ding等[28]提出了一种基于认知图谱的问答系统(cognitive graph QA,CogQA)。简单地说,双加工理论认为人脑在处理阅读理解问题时,通过交替地进行无意识的直觉机制和有意识的推理机制两个过程,来快速检索信息并进行深度推理。类似地,CogQA也由相应的系统1和系统2构成:系统1负责从文本中抽取与问题相关的实体,并构建基于实体的认知图;系统2负责对认知图进行推理。
Ding等使用文档和问题中的实体作为节点构建认知图谱。如图6所示,模型首先抽取问题中的实体作为初始的活跃节点。之后,模型通过不断迭代系统1和系统2来扩展认知图谱和更新图中节点的隐含状态,直至认知图谱中没有活跃节点或者认知图谱已经足够大。
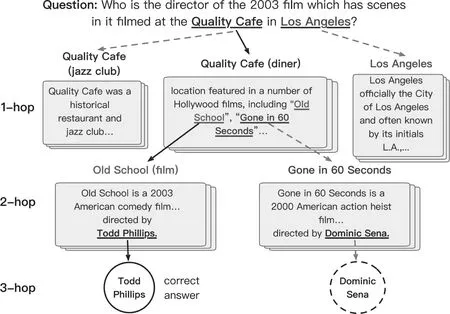
图6 Ding等文中模型工作机理
模型具体框架如图7所示。在访问某活跃节点时,给定问题、该节点的线索和相关段落作为输入,系统1使用BERT抽取出文档中与问题相关的下一跳(next hop)实体和候选答案实体:下一跳节点注重节点所属的上下文与问题描述的匹配程度,主要用于模型进行下一跳推理;而答案节点则更注重于问题所指答案的语义相关性,主要用于答案预测。模型将抽取出的新实体作为新节点加入认知图谱,并在该活跃节点和新节点间添加边。在抽取出的下一跳节点中,模型选取已经出现但与该活跃节点构成新边的节点标记为活跃节点,以待模型进行下一步推理。
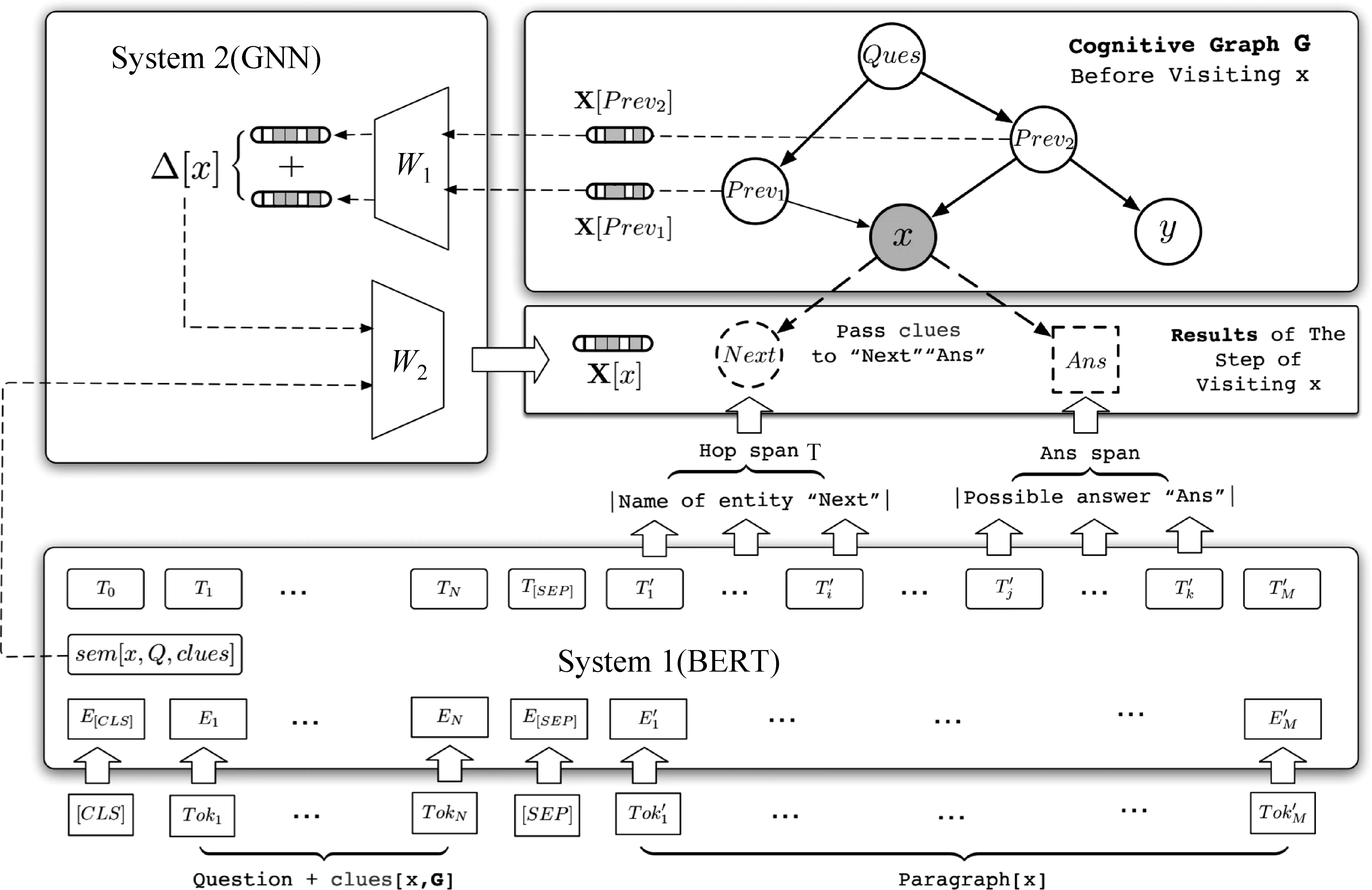
图7 Ding等文中模型框架图
同时,系统1还将所有输入的全局隐含表示作为其语义表示,该表示将被系统2用于认知图中新增节点隐含状态的初始化和其他节点的信息更新。系统2利用系统1计算出的语义表示作为该节点的初始表示,并利用GCN对认知图中的节点进行信息更新来实现隐式推理。此外,针对该活跃节点,系统2还为其后继节点选取线索信息,为后继节点的推理起引导作用。最终,所有答案节点的隐含表示都将通过一个全连接网络,并进行加权平均得到最终答案。在HotpotQA数据集中Fullwiki版本的实验表明,与基于信息检索—抽取的方法相比,这种基于BERT[29]和GNN的CogQA模型不仅具有一定的可解释性,还具有更好的性能。实验分析表明,通过并行地在不同推理路径上探索,CogQA在更复杂的多跳推理问答中具有较好的鲁棒性。
更多工作在上述多跳推理问答工作的基础上,为了更好地从纯文本中提取有效信息,并进行推理,Qiu等[30]提出了一种动态融合图网络(dynamically fused graph network,DFGN)构建动态实体图结构(dynamic entity graph)。给定一组文档和一个问题作为输入,DFGN首先使用一个基于BERT的分类器对所有句子进行编码和匹配,选取所有文档中与问题相关的段落构成针对句子的上下文。之后,DFGN对上下文进行命名实体识别,并从所有实体中选择部分实体构图。他们构建了三种边:①连接出现在同一句中的节点间的边,即句子级别的边;②连接属于同一提及(mention)实体间的边,即上下文级别的边;③连接同一段落中的中心节点和其他节点的边。Qiu等使用GAT对上述图结构进行编码,并且以此更新文档表示。在得到新的文档表示以后,该方法重新选择一组相关实体节点,更新图结构。这个文档和图表示的迭代更新重复数次,以实现推理过程。在Distractor Hotpot数据集中的实验表明,其性能较基线模型有了显著的提升。消融实验表明,模型中动态的融合模块是模型性能提升的关键,印证了Qiu等提出的逐步推理机制的有效性。
Fang等[31]提出了层次化图神经网络(hierarchical graph network)。首先通过短语匹配、文本分类等方法选取与问题最相关的段落,再根据段落内实体的维基百科超链接(hyperlink)去寻找可能有关的段落。在选取好候选段落之后,Fang等根据实体、句、段落等三种不同粒度创建了实体、句子、段落和问题等四种类型的节点,并根据节点间的七种关系构建了异构图。之后,使用图注意力网络实现节点间的信息传播和整合。在HotpotQA上的实验表明了这种分层图神经网络的有效性,消融实验表明了分层图结构间各节点间的信息交互能有效保证模型进行正确的推理。
此外,与阅读理解问答相关的一个任务是基于阅读理解的问题生成。Pan等[32]提出了一个深度问题生成任务(deep question generation, DQG),即模型需要根据给定的多个文本片段生成一个有意义且复杂的问题。为了使模型能够理解多个输入文本间的文档级关系,同时根据既定信息进行推理,生成合理问题,Pan等根据文本的语义角色关系和依存关系构建语义图结构,并使用基于注意力机制的控制门图神经网络(attention-based gated graph network, Att-GGNN)来进行节点表示的更新。语义图的特征表示与利用双向循环神经网络编码得到的文档特征表示整合在一起作为富含语义信息的文档表示,用于联合训练问题文本生成和相关内容选择两个任务。在HotpotQA上的实验表明,这种语义图结构能够帮助模型推理出内容相关的文档片段,进而帮助生成合理且复杂的问题。
为了更好地解析在面向知识库的问答系统中具有多元关系的复杂问题,Sorokin等[33]使用图神经网络帮助语义解析器更好地理解问题文本中实体的关系,输出正确知识库查询语句。简单来说,Sorokin以问题文本中的实体为基础,构建可能的语义图结构,并使用一种带有控制门的图神经网络(gated graph neural network, GGNN)来对语义图进行信息的编码和整合。随后通过计算语义图特征与问题文本特征的相似度,选取最有可能是正确答案的语义图,并使用其对应的查询语句在知识库中搜索出正确答案。Sorokin等在WebQSP-WD[34]和QALD-7[35]两个数据集上均取得了较好的结果。
为了更好地利用外部知识库WordNet[36]和ConceptNet[37]中的结构信息,Qiu等[38]提出了一种结构化知识图感知网络(structural knowledge graph-aware network, SKG)来学习外部知识库中的结构化信息。给定问题和文档段落作为输入,Qiu等根据段落中所有词的词根在知识库中进行检索,选取包含词根的知识三元组结构,并合并各个三元组中相同的实体节点,生成与段落相关的知识图。Qiu等利用图注意力网络来更新知识图中的隐含状态表示。随后Qiu等使用一个控制门将文本表示与知识表示结合在一起形成最终的表示,这些表示被用于预测段落中的答案位置。在ReCoRD数据集[39]上的实验表明,这种图神经网络能够有效融合与答案相关的外部知识,并利用这些知识帮助答案选择。
除了上述问题之外,阅读理解的另一个难点是常识问答,如CommensenseQA[40]。常识问答需要机器能够理解没有在问题中直接体现的常识,而如何正确地选择并利用这些知识具有很大挑战性。为了解决这个问题,Lv等[41]提出了一种利用混合外部知识(heterogeneous external knowledge)的基于图结构的推理模型。给定一个常识问题和一组候选答案,Lv等首先从结构化的ConceptNet和非结构化的Wikipedia数据库中抽取相关的结构化知识和生文本,并利用语义关系标注器从生文本中抽取三元组。这是两种混合来源的知识构建与常识问题相关的图结构。随后通过基于图的推理模块,利用图卷积神经网络对图节点进行信息编码,并利用图注意力网络对信息进行整合,从而选择候选答案。实验结果显示,图神经网络在整合、利用外部知识上,特别是通过多个实体间的关系来推测复杂问题的答案,具有明显优势。
针对谷歌发布的具有长短两个粒度答案的长文档阅读理解NQ(natural questions)任务[42],Zheng等[43]提出了基于图注意力网络的阅读理解框架,对长文本阅读理解中文档、段落、句子和词等四个级别的信息进行建模,以获取不同粒度的文本特征表示,并对长短两种答案的预测进行联合训练。相较于传统方法,这种图网络模型不仅考虑了不同层次的文本特征,还考虑了长短两种答案间的关系,从而在NQ数据集上取得了最优效果。
2.2 信息抽取(Information Extraction)
信息抽取任务[44]是指从文本中抽取出结构化的实体、关系以及事件等信息,其输入一般是纯文本,输出是指定类型的结构化信息。信息抽取一般还可以分为实体识别[45]、关系抽取[46]和事件抽取[47]等子任务。实体识别一般指在特定或开放域的文档中,抽取出特定的实体,并对其类别进行识别,如命名实体识别。关系抽取是指根据一组实体或事件所属的上下文,判别它们之间的特定关系。事件抽取是从一组文档中,抽取出特定事件,这些事件是指对某一事实的客观描述,一般定义为特定人、物在特定时间、地点所发生的相互作用。除了这些单一任务,近来越来越多的工作也关注于联合信息抽取的任务,如实体和关系的联合抽取等。
代表性工作1:多元关系抽取在关系抽取任务中,传统的数据集主要关注于二元关系[48],即出现在同一句内的两个实体之间的关系。更复杂的数据集,如Peng 等[49]提出的生物医学领域的数据集,则包含多个实体之间的相互关系,即多元关系(n-ary relation)。相比于简单的二元关系,这种多元关系的抽取不仅需要模型在不同的句中检测相关实体,还要进一步判别它们的交互关系。
为了更好地识别实体间的复杂关系,Peng等使用了一种基于双向DAG的LSTM模型来对多元实体进行关系抽取。具体来说,给定一段文档作为输入,他们以句子中的词作为节点,并在相邻的词之间、具有依存句法关系的词之间,以及具有句间关系的句子中的根节点词之间添加连边,从而构建图结构。为了处理这种图结构,Peng等首先按照边的方向将其拆分成从左至右和从右至左的两个单向图。之后,树状LSTM根据两个单向图对句子分别进行编码,从而得到句子的双向隐含表示。句子中每个词的最终表示则由其对应的双向隐含表示拼接得到。最终,基于逻辑回归的分类器使用所有词的最终表示来进行关系预测。实验证明,在生物医药领域的数据集上,这种基于双向图的LSTM比基于传统的树状LSTM基线系统具有更好的性能。但是,这种简单根据边的方向来对原始图切割的方法不仅会破坏图中异向的链状结构,造成信息流失,还会忽略兄弟节点之间的信息交互。
为了解决上述问题,Song等[50]使用图LSTM模型,这种模型无须对图结构进行切割、破坏图结构,因此可以更好地利用图中的重要信息。具体来说,在初始构图方式上,Song等遵循了Peng等的方法。同时,他们使用每条边的边标签的词嵌入表示和该边连接的源端词的词嵌入表示计算得到每条边的初始表示。这些表示将作为图状LSTM的输入。之后,与Peng 等不同,Song等没有对图进行切割,而将整个图作为一个整体,使用图循环神经网络对其进行图状态的更新,如图8所示。经过几轮信息传递之后,每个节点都能够捕获远距离节点中的信息。最终,所有节点的隐含表示都被输入到一个基于逻辑回归的分类器,用于节点间的关系预测。实验表示,经过5次信息传递,这种基于图状态的LSTM关系抽取模型,在二元和三元关系抽取任务上,都比双向DAG LSTM有了较大性能提升;同时,这种模型的训练和解码速度,要显著快于双向DAG LSTM。
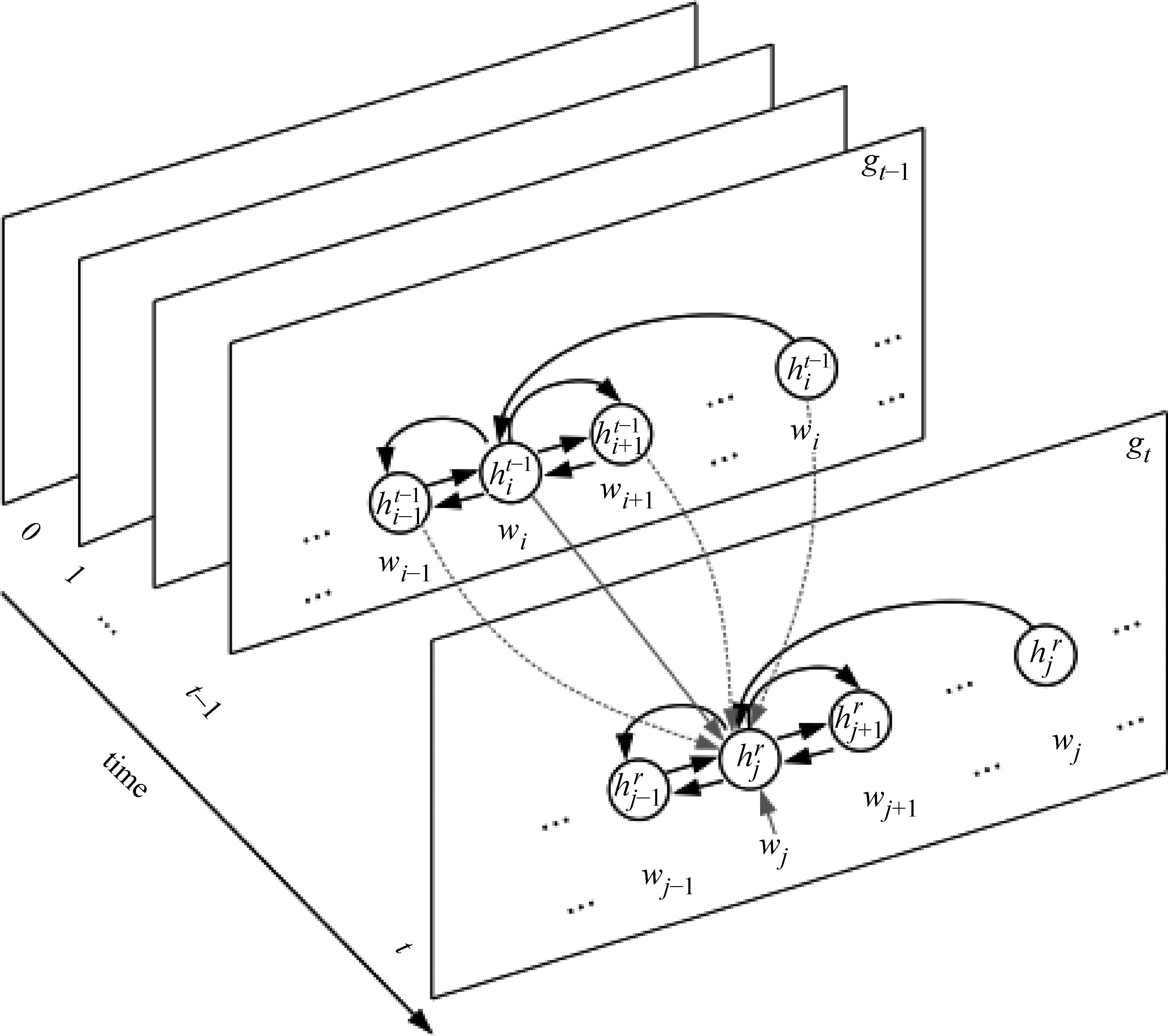
图8 Song等图LSTM模型
代表性工作2:输出图重排序(re-ranking)同样地,针对联合实体关系抽取任务,Fu等[5]提出了一种关系图模型(GraphRel),把实体关系结构作图建模。该模型不仅考虑了实体和关系类型之间的交互,还考虑了共享相同实体的不同关系间的相互作用。总的来说,GraphRel分为两个阶段:在第一阶段中,基于双向LSTM和GCN的编码器对句子和其依存树进行编码以得到句子的序列和依存特征,并利用这些表示抽取出实体和实体间的关系三元组;在第二阶段中,GraphRel根据第一阶段中的信息,重新构造一个具有关系加权边的全连接关系图,并使用关系加权的GCN网络对其进行编码,以此来完成关系三元组间的关系交互,如图9所示。
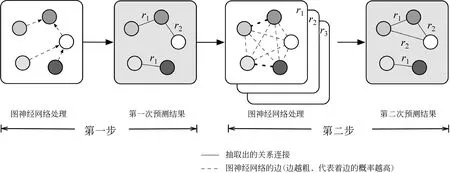
图9 Fu等文中模型框架
具体而言,给定一个句子,在第一阶段中,Fu等将句中每个词的词嵌入表示和词性嵌入表示结合作为输入,并用双向LSTM对其编码,得到每个词的隐含状态表示。这些表示将被作为句子依存句法树中对应词节点的初始状态。由于依存句法树是一种有向的图结构,Fu等使用双向GCN对节点的流出和流入特征进行编码,并将编码后节点的双向表示拼接在一起作为该节点最终的特征表示。这些词的特征表示将被输入到一个一层LSTM网络中,用于抽取实体,并在此基础上,用于对所有实体对间的所有可能的关系进行加权打分。
在第二阶段,Fu等利用第一阶段中的实体作为节点,将每对实体间特定关系的打分作为加权边,重新构建了一种全连接的关系加权图,如图10所示。Fu等使用双向加权GCN对关系加权图进行编码,以此来捕获节点间不同关系的交互信息。最后,Fu等利用这些新得到的节点编码表示来进行命名实体识别和关系分类。整个模型端到端的训练,两个阶段中实体损失和关系损失都计算在模型总体的损失中,以联合训练。

图10 Fu等文中图结构
模型使用NYT[51]和WebNLG[52]数据集来进行实验。实验和分析表明,在命名实体识别和关系抽取两个任务上,相较于Novel Tagging、OneDecoder和MultiDecoder等基线模型,这种基于GCN的实体关系抽取模型在第一阶段就能够有效抽取句子中序列和依存特征信息,已经可以取得较好的性能;而在第二阶段,模型能够进一步考虑实体与不同关系间的相互作用,从而能够对实体间具有语义重叠的关系进行更全面的建模,取得更好的实验结果。
代表性工作3:扫描文档建模除了纯文本数据,日常生活中还存在视觉与文本信息相结合的视觉富文本(visually rich document,VRD),如购物收据、保险单据等,这种视觉富文本也蕴含大量可抽取的语义信息,如商品价格、税费等(图11)。视觉富文本中的语义结构信息不仅仅存在于文本内容中,还表现在文本的视觉特征中,如表格结构、文档布局等,因此一般针对纯文本的方法很难有效抽取此类数据中的有用信息。为了解决这一问题,Liu等[53]提出了一种能够结合文本信息与视觉信息的卷积神经网络模型,从这种数据中进行多模态信息抽取。

图11 Liu等文中数据样例
如图12所示,为了有效地表示这种富文本数据中的语义和结构信息,Liu等首先使用光学字符识别工具(OCR)对原始的文档图片进行识别,将其转换为一组带有位置信息的纯文本片段。他们将这些文本片段作为文档图中的节点,并将文本片段间的相对形状、距离等视觉依存信息作为节点间的边,以此构造了一种全连接的有向文档图。之后,Liu等使用双向LSTM对文本片段进行编码,并将得到的隐含表示作为对应节点的嵌入表示。同时,他们还将两个文本片段间的水平、垂直距离,源端文本片段的形状和它们的相对形状作为对应有向边的特征,来作为边的嵌入表示。

图12 Liu等文中图结构
如图13所示,在构建好图结构并对节点和边初始化之后,Liu等利用基于图自注意力网络(GAT)的方法对图中的视觉文本信息进行编码。之前所介绍的针对纯文本图神经网络编码一般仅对节点进行操作,而在上述文档图中,节点的嵌入表示仅包含文本信息,而视觉信息则存在于边中。为了有效利用边中的视觉特征,Liu等在“节点—边—节点”三元组上进行卷积操作,同时对节点和边进行信息的整合和更新,以此加强三元组之间的视觉特征信息交互。经过几层图网络编码,文档图中的每个节点都富含视觉信息和上下文信息。如图14所示,最终这些节点的表示将和对应的文本片段中的词嵌入表示拼接在一起,输入到一个双向LSTM和条件随机场(conditional random field,CRF)来抽取文档中的实体。Liu等在增值税发票和国际采购收据两个真实的数据集上进行了评测。实验表明,相较于仅使用纯文本信息的基线模型来说,模型在各种类型的实体抽取上都有较好性能,尤其模型在针对纯文本无法单独表示的实体抽取上,性能有显著提升。该实验结果表明,这种基于图网络的信息抽取模型能够有效利用视觉富文本中的多模态信息。进一步的消融实验表明,视觉特征的加入是模型性能提升的主要原因,同时也证明了在三元组上进行图网络编码操作的有效性。
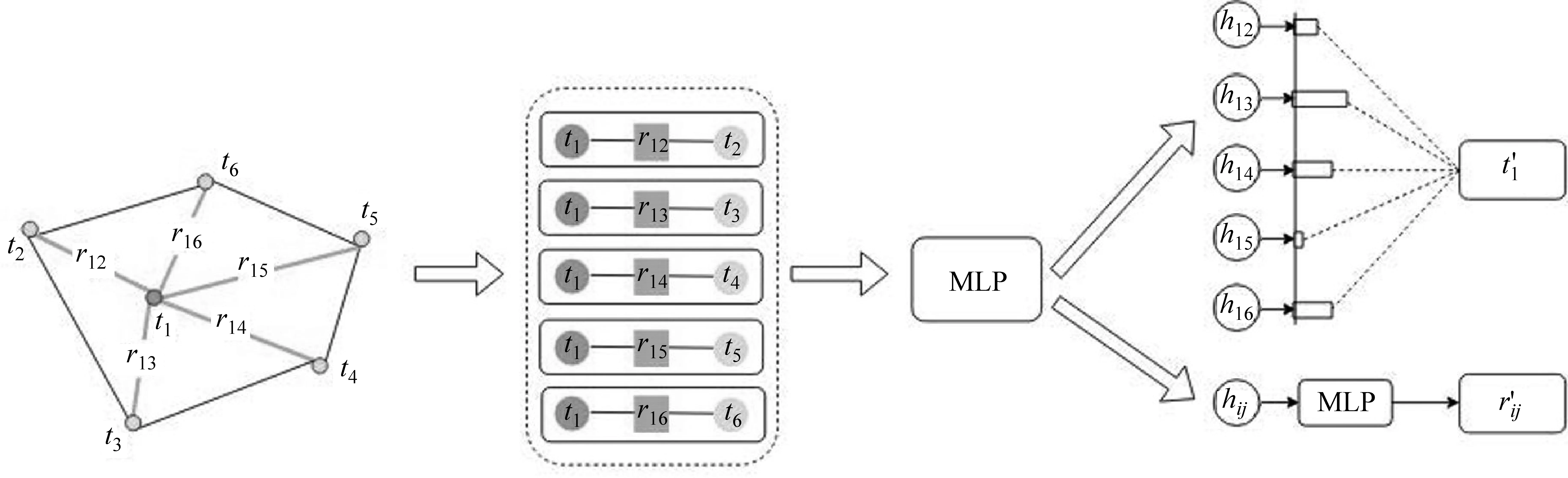
图13 Liu等文中节点图表示

图14 Liu等文中模型框架图
更多工作如上文所述,依存句法(图15)树能够帮助模型更好地识别句中实体之间的关系。这种方法很大程度上依赖于句法分析器的表现。但在新闻领域之外,依存句法分析的准确率相对较低。为了缓解句法分析器在医疗文本领域的弱表现问题,Song等[54]提出了一种利用依存句法森林(dependency forest)的医疗关系抽取模型。相比于单个句法树,依存句法森林中的节点之间涵盖多个可能的句法关系。Song等使用图卷积神经网络对句法森林进行编码,并选取有用的句法关系。相比于传统方法与使用单一句法树的方法,这种方法不仅具有较高准确率,还具有更好的领域适应性,一定程度上缓解了句法分析的域外问题。沿袭Song等的工作,Jin等[55]进一步提出了利用一种3D向量的完全依存句法森林(full dependency forest)的方法,涵盖了句中所有词可能的依存关系。Jin等使用了一种基于数据依存的卷积神经网络(data-dependent CNN, DDCNN)对其进行编码。在包括医疗、新闻等多个领域的实验表明,这种方法具有明显较好的领域适应性,能够大幅减少因句法分析器在新闻领域外的低表现造成的错误问题。

图15 依存句法信息图
在实体类别识别领域,Jin等[56]使用了一种层次多图卷积神经网络(hierarchical multi graph convolutional network, HMGCN)来解决大规模知识库中缺少实体类型的问题。在中文命名实体识别领域,Zhang等[57]引入了词典信息,在字符序列的基础上构建了图结构,并使用基于网格LSTM(lattice LSTM)的方法对其编码。Gui等[58]使用带有控制门的基于词法的图神经网络(lexicon-based graph neural network)对同样结构进行编码和信息更新。Sui等[59]提出了一种基于中文字符的协同图神经网络(character-based collaborative graph network)。这种方法不仅利用了能够组成词组的字符间的关系,还能够自动匹配词组,并捕获字符与上下文间的关系。
在关系抽取领域,Zhang等[60]利用知识库中标签间的隐式关系,并利用图卷积神经网络对知识图进行编码,线性地学习标签间的关系信息。实验表明,这种方法能很好地解决关系抽取中的长尾问题(long-tail)。此外,在文档级别的关系抽取问题上,Sahu等[3]以文档中的词为节点,以句内关系包括句法关系、相邻关系等,以及句子间的篇章关系包括共指、相邻的句子关系等,构建图结构,并且使用图卷积神经网络对其进行节点内的信息更新和节点间的信息整合。
在事件抽取方面,Liu等[61]提出了联合多事件抽取模型(jointly multiple events extraction,JMEE),同时进行事件检测和事件类型识别。他们在模型中引入了基于句法分析树的特征,并使用图卷积神经网络对句法图进行编码。在此基础上,为了更好地解决具有多跳关系的事件抽取问题,Yan等[62]利用句法树构建了以事件触发词为节点的多阶句法树,并使用基于多阶图注意力网络的事件检测(multi-order graph attention network based method for event detection, MOGANED)对不同触发词选取有用的上下文信息进行编码。这种方法相比于JMEE模型,能够更好地对复杂的事件进行检测,同时也避免为了捕获多跳事件关系而直接使用多层图卷积神经网络造成的过平滑(over smoothing)问题。
在跨语言信息抽取方面,Subburathinam等[63]采用迁移学习的方法,使用图卷积神经网络去整合跨语言的关系和事件中通用语言特征表示。与传统方法相比,这种基于图网络的跨语言关系和事件抽取方法在中文、英语、阿拉伯语等多语言数据集上均取得较优表现。
2.3 机器翻译(Machine Translation)
机器翻译的输入是源语言的一个或多个句子,输出是对应的目标语言的句子。传统的机器翻译系统一般使用基于短语的方法[64],以及编码—解码器的结构来进行多语翻译[65-66]。这些方法无法对显性的句法或者语言的层次结构进行建模。
代表性工作1:句法信息一些基于循环神经网络的模型可以间接地将句法信息融入机器翻译中[67-68],但这些模型在建模过程中对句法和翻译之间的交互设置了硬性约束,而这些过于严格的交互约束通常会影响机器翻译的准确性和流畅性[69-70]。
为了更好地将有用的句法信息融入机器翻译中,Bastings等[1]以句子的依存句法关系为基础,构建图结构。具体而言,源句子中的每个词被当作图中的各个节点,句中各个词的依存关系被定义成边,依存关系的类型也就是边的类型。这种句子的依存关系可以看作是一个有向图,因此可以使用卷积图神经网络对它进行编码。
Bastings等采取了一种改进的图卷积神经网络——句法图卷积神经网络,对不同类型的边进行建模。具体而言,在图16中,给定一个源语言的输入句子,在编码端,Bastings等首先使用CNN对源端每个单词及其一定上下文信息进行编码,得到上下文相关的每个单词的隐含状态。然后,句法图卷积神经网络将之前得到的每个词的隐含状态作为输入节点的初始值,将源句子的依存句法作为边,进行图神经网络迭代,从而丰富每个词的表示所包含的有效信息。经过多轮信息的更新迭代,句法图卷积神经网络输出句子的表示,并交由解码器进行解码,输出目标语言的句子。为了更好地排除由句法结构预测导致的潜在错误信息的影响,他们在句法GCN中添加控制门这一机制。与GAT相似,这种控制门能够用来均衡单边信息的权重、忽略具有潜在错误信息的句法边。这种方法在为编码器提供丰富的句法信息的同时,能够让编码器自己选择对机器翻译有用的信息,从而规避句法约束对机器翻译产生的损伤。
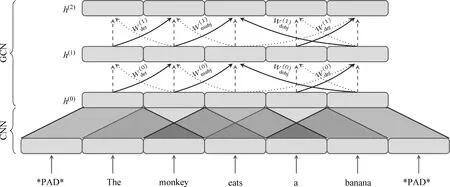
图16 Bastings等模型结构图
在WMT16[71]任务中的英语—德语和英语—捷克语数据集上的实验表明,这种基于卷积图神经网络的模型能够将句法信息集成到机器翻译中,并使得模型性能产生显著提升。基于BLEU4评价标准的结果显示这种方法在机器翻译的词序和词法/子词编码的选择上有显著改善,而这两者源于句法信息的有效使用。
除了句法信息之外,句子的语义表示也一直被认为能帮助机器翻译在目标语句中保留源句子的一些特定信息,并且能够提高机器翻译的泛化能力。Marcheggiani等[72]利用句子中的述词论元结构(predicate-argument structure)来构建图结构,并使用与Bastings等相似的图卷积神经网络编码语义结构,将其融入机器翻译中。具体来说,给定一个源句子,他们首先对句子进行语义依存角色分析[73],从而得到句中的述词、论元和它们之间的语义角色关系(图17)。之后,Marcheggiani 等将述词和论元作为图的节点,并将其之间的语义角色关系作为带有标签的边来构建图结构。

图17 语义角色关系图
代表性工作2:深层语义信息尽管语义角色标签能够帮助神经机器翻译解决论元变换问题,但是语义角色标签仅关注于述词和论元的关系,而往往会忽略句子其他信息。为了更好地利用句中其他结构化的语义信息,Song等[2]提出了利用AMR作为额外知识来源的语义神经机器翻译模型。AMR是一种语义范式,能够将一句话的含义编码成为一个有向有根图。图18展现了图17中句子的AMR图,AMR不仅包含这种述词论元关系,还可以直接捕获实体之间的关系,并且从具有形态变化的和功能性的词(如动词、介词)中抽取其抽象语义。
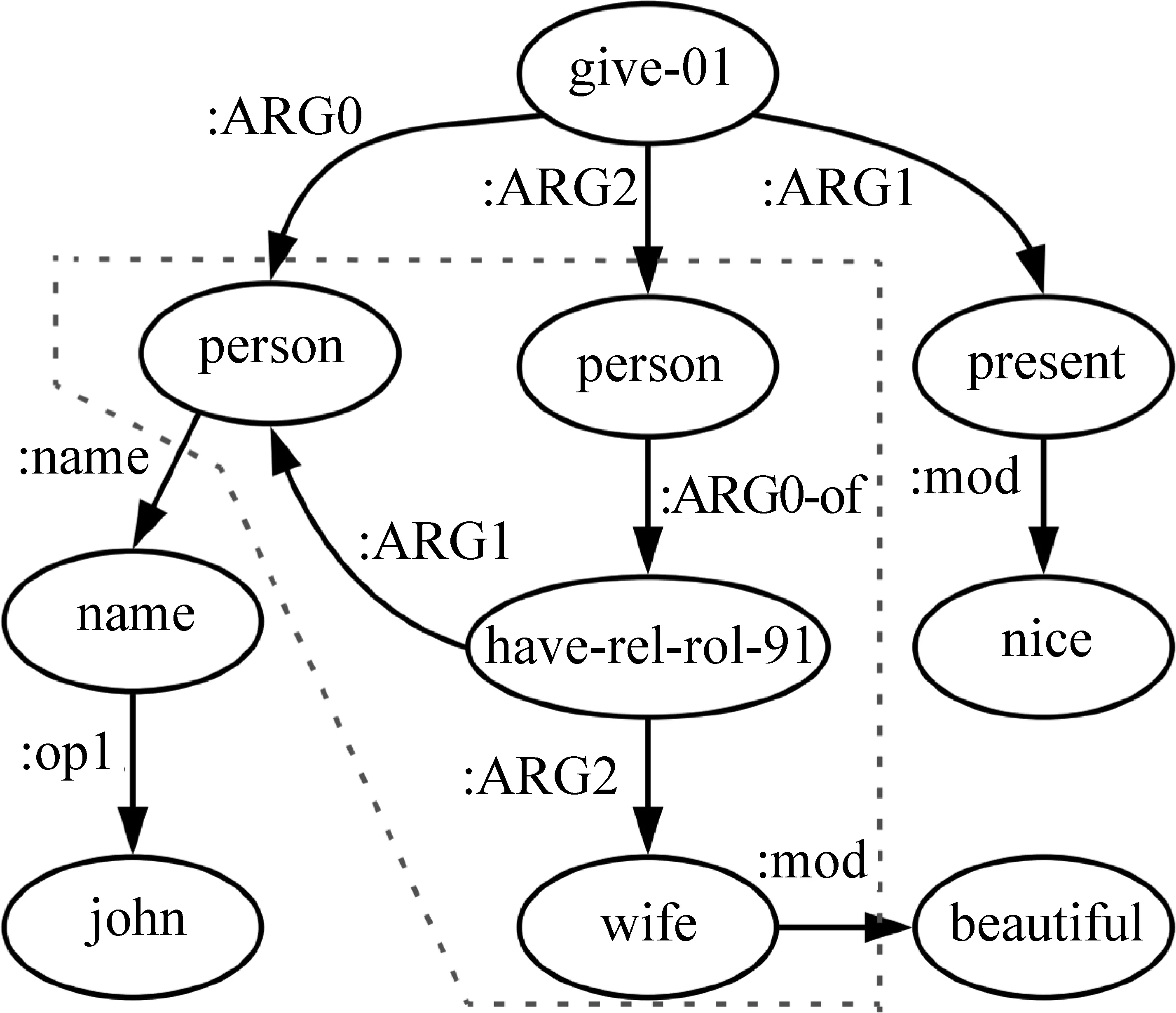
图18 AMR结构图
如图19所示,为了进行翻译,Song 等对句子的AMR图结构使用图神经网络编码,并将图的表示与句子的编码表示相结合来进行解码,从而达到将语义信息融入机器翻译的目的。具体而言,在AMR编码阶段,他们首先使用AMR解析器[74]将待翻译的源句子抽象成对应的AMR图,然后将AMR中的概念作为节点,以概念间的弧作为边,使用图循环神经网络进行编码。

图19 Song等文中模型结构
在AMR解码阶段,Song等使用了一种基于双注意力的RNN解码器(doubly attentive decoder)。与一般的基于注意力机制的RNN解码器不同,这种解码器在计算上下文向量时,使用图神经网络输出的节点隐含状态来代替一般RNN编码器的隐含状态,与当前RNN解码器输出的隐含状态拼接得到注意力矩阵。
Song等采用WMT16英语-德语数据集对模型进行训练,并在NC-v11上进行主要实验结果测试。实验结果表明,与以往工作相比,引入AMR的图神经机器翻译模型,性能有较大提升,特别地,实证分析发现这种方法能够更好地解决源句中因述语论元间隔过大导致的翻译问题。
更多工作Yin等[75]提出了一种基于图神经网络的多模态融合编码器去捕捉视觉和文本数据中不同对象的语义关系。他们以输入文本中的实体和图片中的视觉对象作为节点,以单一模态内部实体和两种模态中实体的对应关系作为边构建多模态图结构,再使用基于图网络的编码器对多模态图进行同一模态内和不同模态间的节点信息融合,以得到各节点的隐含状态表示。实验表明,这种基于图网络的编码器能够捕获不同模态间语义的交互关系,从而取得更好的编码效果。
2.4 其他领域应用
目前自然语言处理中关于图神经网络的研究覆盖了几乎所有主流任务。
2.4.1 词嵌入表示
词嵌入[76-77]是NLP任务的基础组成部分。传统的词嵌入方法大多利用词的序列上下文信息而没有利用词的句法上下文信息。也有研究表明,从文本的依存分析中解析出来的句法上下文以及来自语义知识库的语义信息可以提升词嵌入的质量。Mikolov等[76]通过将单词与其依存关系相连接来合并语法上下文。这严重扩展了词汇表,从而限制了大型语料库上模型的可伸缩性。
Vashishth等[78]通过提出一种基于图卷积的灵活方法——SynGCN来学习单词嵌入。SynGCN利用单词的依存关系灵活地进行编码而不会增加词汇量。具体来讲,SynGCN在传统词嵌入学习框架中加入了一层syntactic信息融合层,如图20所示。一个句子的词与词之间通过依存句法解析器得到句法关系,这样通过句法信息构成了图,随着图神经网络的叠加,句法信息被融合进了词嵌入之中。同样地,Vashishth等类比于SynGCN构建了一个SemGCN框架用于融合语义知识。实验表明,SynGCN学习的单词嵌入在各种任务上的表现优于现有方法,SynGCN和SemGCN的组合可以获得最佳的整体性能。然而相较ElMo等上下文表示(contextual embedding),SynGCN与Skipgram,GloVe等传统表示一样,在外部评价(external evaluation)中没有明显优势。
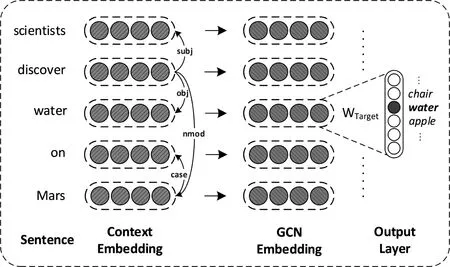
图20 Vashishth等文中模型框架
2.4.2 文本表示
一般文本分类任务通常采用双向循环神经网络作为句子信息表示的基本模型。尽管双向LSTM是一种强大的文本表示工具,但该模型也被证明存在一些限制。例如,LSTM的序列结构使这种模型在对文本序列建模过程中无法并行计算,从而可能导致计算瓶颈,也无法对局部信息(n-gram)更好地进行表达。此外,有序的信息流动方式导致捕获远距离依赖项的能力相对较弱,这可能造成对长句子编码的性能较低。
为了解决上述问题,Zhang等[13]提出了一种用于文本编码的句子状态LSTM结构(sentence state LSTM, S-LSTM)。这种S-LSTM与传统的LSTM之间的区别主要体现在其节点循环更新的方式上:传统LSTM按照文本序列的某一方向作为时间步方向,对节点的隐含状态进行顺序地更新;而S-LSTM选取与文本序列正交的方向作为时间步,利用句子级隐含状态和词的隐含状态进行当前节点状态更新。
具体来说,Zhang等以句子中的单词作为节点,并在相邻的节点间添加边。同时,添加一个表示整个句子状态的额外全局节点(global node),与每个单词相连。该节点用于整合每个单词非局部信息,可以用作分类任务的全局句子级表示。在某个时间步中,每个词节点整合上一时间步中的句子状态节点和该节点的左右邻居节点中的信息,用于词节点的隐含状态更新;句子状态节点利用上一时间步中所有词节点的隐含状态进行信息更新。这种节点的更新方式使S-LSTM具有更强大的表示能力。
在电影评论数据集[79]上的文本分类任务和在PTB上的序列标注任务实验表明,相比基于传统LSTM和CNN的基线模型,S-LSTM能够更好地捕获句子的全局信息,从而具有更强大的表示能力。同时,在16个不同领域数据集上的实验表明,这种S-LSTM不仅比传统LSTM具有更好的性能,其并行式的节点更新方式还使S-LSTM具有更快的计算速度。
2.4.3 情感分析
层次短语(hierarchical phrases)情感分析的目标是预测句子及句子的成分组成树中的每个短语的情感类别。如图21所示,该任务的难点在于上下文信息带来的歧义性。Zhang等[80]提出了一种使用图卷积神经网络和图循环神经网络的树通信模型,该模型允许在短语组成树之间进行丰富的信息交换。为了实现更好的交互,Zhang等进一步提出了一种基于GRN的新型时间注意机制,用来融合每次通信之后的信息。实验表明,与双向LSTM相比,使用GNN增强节点通信的tree-LSTM性能得到了显著提升。

图21 Zhang等文中样例分析
2.4.4 社交文本分类
分析新闻媒体在讨论某一事件中的政治观点是一项重要且具有挑战性的任务,政治观点的识别可以为检测虚假内容和谣言打下基础。与传统舆情分析的不同点在于,新闻叙事试图保持信誉并显得公正,但是通常通过强调故事的不同方面,以微妙的方式引入偏见。因此传统的显式观点分类方法不能奏效。Li等[81]假设新闻文本中表达的政治观点也将反映在新闻传播的方式以及认可该媒体的用户的身份上,由此通过将新闻文章和共享这些文章的社交圈嵌入一个单一的空间中,Li等构建了一种融入社交网络的文本表示形式,从而可以预测与之相关的政治偏见。
图22描述了这些设置。通过分享消息链接将文章节点连接到用户节点,而这些用户又通过关注或好友关系连接到政治相关的用户(例如,美国共和党或民主党的Twitter账户)。Li等[81]使用图循环神经网络在这个构建的社交网络中进行信息的融合,隐式地学习到了文本背后用户固有的政治倾向,最终得到的文本表示融合了与之相关的用户的政治行为,因此可以用来更好地帮助预测文本的政治偏见。这种新颖的想法同样有进一步挖掘的价值,如更细粒度的舆情分析。
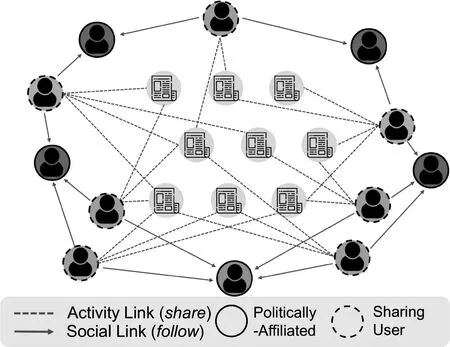
图22 Li等文中图结构
2.4.5 句法分析
图神经网络也可以显著地提高依存分析这类基础自然语言处理任务。给定一个句子,依存解析器首先对所有单词对的有效依赖关系的可能性进行评分,然后使用解码器(如贪婪算法、最大生成树算法)从这些评分中生成完整的解析树。从观察到的特征(单词,位置,词性标注标签)到隐藏状态的表示,结构信息对于获得准确而强大的解析性能至关重要。传统的递归神经网络(RNN)忽略了与依存结构有关的功能。单词的从属树的边应该是有向边,因此biaffine映射方法[82]区分单词的头部(head)和从属(dependent)向量。按照这种思路,可以很自然地将更多的结构化知识(如兄弟节点)引入节点表示中。
与常用的在依存树上运行GNN的句法图网络(Bastings等[1],Zhang等[80])相比,Ji等[83]使用GNN来构建依存解析器本身,如图23所示。具体来讲,给定一个加权图,GNN通过递归聚合邻居节点来表示特定节点。对于句法解析任务,Ji等在完全图上构建GNN,通过堆叠多层GNN,节点的隐藏表示逐渐汇聚各种高阶信息,并将全局特征传入解码器的最终决策层中。实验表明,GNN融合高阶特征的确对句法分析任务带来有效的性能提升。
图23 Ji等文中模型框架
2.4.6 语义角色标注
Marcheggiani等[73]使用图卷积神经网络编码句法结构,提升语义角色标注质量,基本方法与Bastings等[1]在机器翻译的工作相同。
2.4.7 文本生成
文本生成包含众多任务,如语义到文本的生成(realization)、结构化信息到文本的生成(data to text)、文本到文本的生成(text to text)和多媒体到文本的生成等。图神经网络在众多任务中都有应用。Song 等[14]和Beck等[15]用GRN编码AMR,实现AMR to text。Damonte等[84]、Cai等[85]、Zhu等[86]和Zhao等[87]扩展了该项工作。Koncel-Kedziorski等[88]和Ribeiro等[89]讨论了结构化数据的图网络编码以及文本生成。Li等[90]和Liao等[91]研究了长文本的图表示以及相关摘要、评论的生成。
3 总结
本文中涉及的文章总结如表1所示。综上所述,图神经网络在自然语言处理领域受到了越来越多的研究关注,解决的问题涉及到了各个层面。由于众多类别的信息以及它们之间的关系都可以表示为一般的图结构,图神经网络成为一种提取有效特征的重要工具。现有的研究大体可以分为两个层面,首先是把不同任务的关键信息以图的方式建模,其次是探讨不同图网络结构的改进。我们认为,第一种研究更具有普遍性和学术价值,同时为特定任务定制有效图神经网络提供辅助手段。相信在未来的研究工作中,图神经网络将会像序列神经网络结构一样,成为深度学习不可缺少的一种工具,而其概念本身将淡出研究的关注点。

表1 本文中讨论的文章总结
