基于神经机器翻译编码器的语义学习分析
2021-04-29徐东钦李军辉贡正仙
徐东钦,李军辉,贡正仙
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
近年来,神经机器翻译(neural machine translation)[1-3]凭借其序列到序列(Seq2Seq)[4]框架的良好表现,已成为主流的机器翻译方法。序列到序列框架包含一个编码器和一个解码器,其通过编码器将源端序列编码成高维度向量,再通过解码器将高维度向量解码获得目标端序列。在这一过程中,各类信息皆表示为高维度向量,很难直观地去解释编码器与解码器的工作,例如:
(1)编码器是否能够从源端序列中捕获源端语义信息?
(2)如果编码器能够捕获源端语义信息,那么捕获的是何种语义信息?对下游任务是否有帮助?
(3)如果为编码器提供更多的语义信息,是否能够提升神经机器翻译的性能?
本文的工作侧重于回答上述三个问题。特别地,本文使用了抽象语义表示(abstract meaning representation, AMR)[5]作为语义信息的表示载体。AMR是近些年来备受关注的一种语义表示方法,其把自然语言文本以句子为单位,将句子的语义抽象表示为单根有向无环图。如图1(c)所示,句子中lost和our等词分别被映射 “lose-02”和“we”等AMR图中节点,这类节点被称为概念(concept)。连接概念之间的边,如图1中“:ARG1”和“:manner”等表示两个概念之间有向的语义关系。如图1中(d)所示,AMR图文本表示中“~e.N”等表示概念、边与源端序列中第N个词所对齐(从第0个词开始计数),如“bitter~e.0”表示“bitter”与源端序列中第0个词“Bitterly”对齐。“w”等变量表示指示引用节点,如“l”指向“lose-02”。需要注意的是,目前AMR还无法做到表述句子的完整语义。AMR侧重的是描述某个句子内部存在的概念(concept),以及它们之间的语义关系,但同时忽略了时态、名词单复数等信息。例如,图1中(c)并没有标注概念“lose-02”的时态信息。

图1 抽象语义表示示例
本文通过AMR中所包含的词对齐信息与语义信息,分别抽取单词级别与句子级别的语义信息,再设计实验验证神经机器翻译在多大程度上能够捕获单词级别语义和句子级别语义。单词级别的语义分析实验利用AMR图中词对齐信息设计序列标注任务,利用编码器对源端序列编码后的每个单词的隐藏状态去预测与其对齐的AMR语义标签。句子级别的语义分析实验则利用AMR图中的语义信息设计序列生成任务,利用编码器编码源端序列,利用解码器生成对应的AMR序列。
1 相关工作
如何理解神经机器翻译模型在训练过程中学习到了何种信息是研究者一直想解决的问题。为了更好地去理解神经机器翻译模型的运行方式,已有一些相关工作尝试从不同的角度,如词法、句法和语义等,去解释翻译模型所捕获的信息。本文按照发表时间顺序,将相关工作归纳如下。
(1)解释神经网络模型的一种常见方法,是将如词嵌入、隐藏状态等高维度向量使用t-SNE方法[6]映射到二维空间。
(2)Shi等[7]通过设计两种不同的实验方案,分析神经机器翻译编码器能否学习到句法类信息,并发现编码器能够捕获到一定量的源端局部信息与全局句法信息。
(3)Belinkov等[8-9]从词汇语义、形态句法角度研究了神经机器翻译编码器、解码器的词嵌入与句嵌入信息。
(4)Ding等[10]利用层级相关性传播算法,计算模型中任意两个节点之间的相关性,可视化分析了神经机器翻译中源端、目标端与隐藏状态之间的关系,并对翻译中出现错误进行了原因分析。
(5)Conneau等[11]在探索主流模型的句子嵌入表示学习到哪些信息时,设计实验从表层信息、句法信息、语义信息三个方向研究不同编码器学习到的信息,从中发现神经机器翻译编码器能够学习到丰富有效的语义特征。
(6)Marvin等[12]从单词语义的角度,利用主成分分析图,解析神经机器翻译模型学习到的词义消歧能力。
(7)Poliak等[13]使用预训练的神经机器翻译模型,通过自然语言推断任务研究编码器捕获到的语义信息,并发现编码器可能捕获到大部分语义角色标注信息,不善于捕捉指代消解信息,或许在语义推理方面的表现较差。
(8)Voita等[14]分析基于自注意力机制的编码器,并发现其多头自注意力机制可以学到相邻词语信息与句法结构。
本文从语义的角度研究神经机器翻译编码器能否学习到语义信息。但与Conneau等的工作不同,本文以AMR作为词或句子的语义表示载体,分析神经机器翻译编码器对源端句子的语义捕获能力。基于AMR的语义分析近年来受到越来越多的关注,一种常见的语义分析方法是将AMR进行线性化,将AMR语义分析看作是一个序列到序列的问题[15-18]。本文以此为基础,利用AMR图中包含的语义信息,设计单词级别与句子级别的语义分析实验,并提出语义分析和机器翻译的联合学习模型。
2 本文方法
本节将详细描述分别从单词级别和句子级别的角度分析编码器捕获语义。两种语义分析方法可分别看作序列标注任务与序列生成任务,通过预测标签的准确率和预测AMR序列的准确率来判断编码器是否学习到语义及其掌握语义的程度。
2.1 序列到序列模型
本文使用Transformer[3]序列到序列神经机器翻译模型。Transformer模型由编码器与解码器组成,编码器与解码器分别由多个堆叠的编码器层与解码器层组成。编码器层包括自注意力层(self-attention layer)和全连接前馈神经网络(position-wise feed-forward networks, FFN),解码器则包括自注意力层、编码器与解码器注意力层(encoder-decoder attention layer)和全连接前馈神经网络。每一子层之间使用了残差连接(residual connection),并且应用了层级正则化(layer normalization)。
与基于循环神经网络和基于卷积神经网络的序列到序列模型相比,通过注意力机制Transformer不仅能够捕获序列之间的长距离依赖,同时还能够并行处理。目前在机器翻译、句法树解析等任务中,Transformer均取得了较好的成绩。有关Transformer模型的更多细节,可以参阅Vaswani等[3]的论文。
2.2 语义分析方法
本节将描述基于AMR对神经机器翻译编码器的语义分析方法。基于预训练好的神经机器翻译模型,利用该模型的编码器(NMT_encoder),并固定编码器模型参数,分别从单词级别与句子级别两个方面设计实验。由于目前神经机器翻译大都采用子词技术以解决低频词的翻译问题,为了与神经机器翻译模型兼容,本文实验中对源端序列与目标端序列均使用了BPE方法[19]处理。
2.2.1 单词级别语义分析方法
单词级别语义分析方法从单词级别的角度出发,研究编码器捕获到的每个单词对应的语义信息。记源端句子为X=(x1,x2,…,xn),根据句子中单词与其AMR图中节点与边的对齐关系,可以为X中每个单词xi获取其语义标签。下面以引言中的图1中(a)源端句子为例,说明获取句子中每个单词的对齐语义标签。
(1)如果单词xi在AMR图中有唯一对齐的节点或边,则将该结点或边记为xi的语义标签。如单词“lost”仅对齐AMR图中“lose-02”节点,记单词“lost”的语义标签为“lose”。为方便起见,本文忽略AMR图中概念节点的数字后缀。
(2)如果单词xi在AMR图中有多个对应的节点或边,则将多个节点或边用“_”连接,记作一个联合语义标签。如单词“our”与AMR图中的边“:ARG0”、节点“we”对齐,记“our”的语义标签为“:ARG0_we”。
(3)除以上情况,将单词xi的语义标签设置为“
由此可以获得源端单词序列的X的语义标签序列L=(l1,l2,…,ln)。对图1(a)中单词序列,其对应的语义标签序列为(:manner_bitter, lose,:ARG0_we, Ryukyu, Islands)。
单词级别语义分析实验将源端单词序列X=(x1,x2,…,xn)看作输入,预测语义标签L=(l1,l2,…,ln)。其中,n代表序列中单词个数。源端每个单词均有与之唯一对应的语义标签,因此,实验可以看作一个序列标注任务,使用源端单词xi经过神经机器翻译编码器(NMT_encoder)编码后的隐藏状态hi,预测其语义标签li。由于语义标签种类较多,传统的CRF方法并不适用;同时,为了与使用子词化处理的神经机器翻译保持兼容,这里对源端序列与目标端语义标签均做了子词化处理。
源端单词序列X=(x1,x2,…,xn)经过BPE处理后得到源端子词序列X′=(x′1,x′2,…,x′m),语义标签li经过BPE处理后得到子语义标签序列l′i=(l′i1,l′i2,…,l′ij)。其中,n代表单词个数,m代表子词个数,i代表语义标签序列L中第i个语义标签,j代表子语义标签个数。
源端子词序列X′经过编码器(NMT_encoder)编码后获得源端子词序列的隐藏状态H′=(h′1,h′2,…,h′m),根据源端单词序列xi对应的子词序列(x′i1,x′i2,…,x′is),将子词序列隐藏状态(h′i1,h′i2,…,h′is)求和获得xi的隐藏状态hi,由此可获得源端单词序列X=(x1,x2,…,xn)的经过编码器(NMT_encoder)编码后的隐藏状态H=(h1,h2,…,hn)。其中,s代表单词对应的子词数量。如图2所示,源端单词“Bitterly”由BPE处理得到子词序列“Bit@@”、“terly”,子词序列经过编码器编码后获得其隐藏状态,对“Bitterly”的子词序列隐藏状态求和即可获得“Bitterly”的经过编码器的隐藏状态。
对于每个单词xi的隐藏状态hi,使用解码器(记为Label_decoder)预测其语义子标签序列l′i=(l′i1,l′i2,…,l′ij),并去除BPE标记,合并获得单词xi的语义标签。由于语义子标签序列均较短,解码器Label_decoder采用基于门控循环单元(gated recurrent unit,GRU)[20]的解码器。
2.2.2 句子级别语义分析方法
句子级别语义分析方法从句子级别的角度出发,研究编码器捕获到的整个句子中包含的语义信息。
将源端单词序列X=(x1,x2,…,xn)看作输入,预测AMR序列Y=(y1,y2,…,yt)。其中,n,t分别表示源端序列X和目标端序列Y中单词(或子词)个数。以图1所示,由于句子级别语义分析的输入是经过BPE处理的源端序列(b),输出是经过BPE处理的AMR简化序列(f),因此,句子级别语义分析可以看作序列生成任务。
本文使用Ge等人[18]的AMR解析方法,训练时使用预处理将AMR图转化为AMR序列,测试时使用后处理将AMR序列转化为AMR图。以图1为例,在预处理过程中,通过移除变量、删除wiki链接、换行符和复制共同引用的节点,可以获得AMR图文本表示的AMR简化序列;在后处理过程中将AMR序列中的概念分配唯一变量,同时修复冗余、重复信息和不完整的概念,添加wiki链接,修改共同引用节点,使其恢复成完整的AMR图(1)详细的预处理和后处理过程可以参见https://github.com/RikVN/AMR。
源端序列X=(x1,x2,…,xn)经过神经机器翻译编码器(NMT_encoder)编码后得到隐藏状态序列H=(h1,h2,…,hn),通过使用解码器(记为AMR_decoder)预测其AMR序列Y′=(y′1,y′2,…,y′t),最后使用后处理脚本将AMR序列Y′恢复成完整的AMR图。
在句子级别的语义分析实验中,使用的解码器(AMR_decoder)是基于Transformer的解码器。图2是预测单词的语义标签示意图。

图2 预测单词的语义标签示意图
3 实验
3.1 实验设置
3.1.1 数据集
为了更好地理解神经机器翻译编码器捕获源端句子语义的能力,本文对两个编码器进行语义分析。这两个编码器分别用于训练大规模和小规模机器翻译数据。具体地,大规模机器翻译训练数据来源自WMT14机器翻译数据集(2)http://www.statmt.org/wmt14/translation-task.html,由英语到德语的平行语料库Europarl v7、Common Crawl corpus和News Commentary构成,共包含4.5 M平行句对。此外,本文使用数据集中News Commentary v7(NC-v7)部分做小规模数据实验,共包含201 K平行句对。实验使用newstest2013和newstest2014分别作为开发集和测试集。
语义分析AMR语料来自AMR 2.0(LDC2017T10)数据集,其中,训练集、开发集和测试集分别包含36 521、1 368和1 371个标记了AMR图的句子。
实验使用BPE方法对数据集进行处理。英文语料与语义分析语料联合BPE处理并设置20 K合并操作,机器翻译德语语料BPE处理同样设置20 K合并操作。在小规模数据上获得英文及语义词汇20 179个,德语词汇20 052个;在大规模数据上,获得英文及语义词汇23 270个,德语词汇23 031个。
AMR语义解析基准实验与Ge等人[18]的处理方法保持一致,对联合源端、目标端做BPE处理,设置20 KB合并操作且共享源端与目标端词表。在单词级别语义数据上获得词表的大小为17 274,在句子级别语义数据上词表大小为19 102。
3.1.2 评测指标
机器翻译性能使用multi-bleu.perl(3)https://github.com/moses-smt/mosesdecoder/blob/master/scripts/generic/multi-bleu.perl脚本评测;句子级别语义性能使用Smatch[21]脚本评测(4)https://github.com/snowblink14/smatch;单词级别语义性能使用F1值评测,计算如式(1)~式(3)所示。
其中,P为准确率,R为召回率。在计算过程中,并没有包括那些语义标签为
3.1.3 模型设置
本文实验模型基于开源框架OpenNMT-py实现的Transformer。单词级别语义分析基准模型由Transformer编码器与GRU解码器组成,句子级别语义分析基准模型由Transformer编码器与Transformer解码器组成。语义分析模型(NMT_small、NMT_big)的编码器使用预训练好的神经机器翻译模型编码器参数,并固定编码器参数。
在参数设置方面,词向量和编码器、解码器的隐藏层的维度均为512维,编码器层与解码器层的层数均设置为6层,多头注意力机制设置为8个头,前馈神经网络的维度设置为2 048维。模型参数均使用Glorot Initialisation方法初始化,共享初始化解码器词嵌入层与生成器的参数,句子级别语义分析模型额外共享初始化了编码器与解码器的词嵌入层参数。模型参数使用优化器Adam优化,其中Adam优化器的参数β1为0.9,β2为0.98,ε为10-9。在训练过程中,固定了随机种子seed为3 435,以token为单位的批处理大小设置为4 096(神经机器翻译NMT_big为8 192),warm-up step设置为16 000,learning rate为0.5,dropout为0.1(GRU解码器dropout设置为0),label smoothing为0.1,并使用相对熵作为损失函数。
实验模型在GTX 1080Ti显卡上训练,迭代更新250 K次结束。在测试过程中,使用集束搜索(beam search)进行解码,并设置beam size为4,长度惩罚因子α为0.6,测试集中报告结果的模型来自开发集上性能最高的单个模型。
3.2 实验结果
表1给出了神经机器翻译在英语到德语小规模数据(NMT_small)与大规模数据(NMT_big)上的性能。单词级别语义分析实验与句子级别语义分析实验均使用两个翻译实验的编码器。表2给出了单词级别语义分析实验结果,分别比较了基准模型(Baseline),使用小规模数据(NMT_small)、大规模数据(NMT_big)上神经机器翻译编码器(NMT_encoder)的模型之间的性能。

表1 神经机器翻译BLEU值

表2 单词级别语义分析实验结果
从表2可以看出,使用固定神经机器翻译编码器参数的模型的性能在大规模数据上比小规模高出4.91个F1值,但与基准模型相比仍然低了17.84个F1值。这一结果说明,神经机器翻译模型的编码器能捕获到一定的单词级别的语义信息,并且随着训练语料的增加,编码器能够捕获到单词级别的语义信息也随之增加,这与表1中的神经机器翻译的实验结果相符合;另一方面,实验结果说明,神经机器翻译模型的编码器在捕获单词级别的语义上还有进一步的提升空间。
表3给出了句子级别语义分析的实验结果,同样比较了基准模型、使用小规模数据与大规模数据的神经机器翻译编码器的模型之间的性能。从表3可以看出,在语料规模较小时,使用固定神经机器翻译编码器参数的模型的性能与基线模型相差3.07个F1值,而在语料规模较大时,与基线模型相比,高出2.61个F1值。这一实验结果说明,神经机器翻译模型的编码器能捕获到相当多句子级别的语义信息,并且随着语料数量的增加,捕获到的语义信息量会随之增加,与神经机器翻译的实验结果、单词级别语义分析实验结果保持一致。值得注意的是,在大规模语料上,神经机器翻译的编码器比基线模型的编码器能捕获到更多的语义信息。
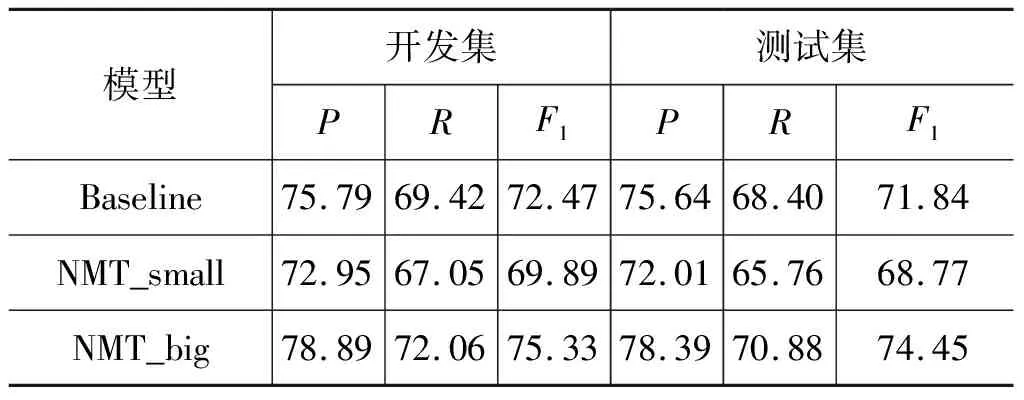
表3 句子级别语义分析实验结果
3.3 实验分析
本节将深入探讨神经机器翻译编码器捕获的语义信息。假设神经机器翻译编码器能够捕获到充分的句子级别的语义,那么一般情况下同样能对单词的语义产生足够的理解。然而,3.2节语义分析实验结果说明,基于大规模翻译语料,神经机器翻译编码器能学习到较强的句子级别语义信息,而在单词级别语义的学习上还有进一步提升的空间。
图3给出了一个基于NMT_big编码器的语义分析结果例子。从中可以看出,句子级别语义分析模型能较好地恢复编码器中捕获的句子级语义,但是单词级别语义分析过程却将单词“Elsevier”和“N.V.”的语义标签错误地预测为“ElRather”和“Federal”。从单词级别语义分析的实验上看,存在一种可能的情况,神经机器翻译编码器能够捕获单词的语义信息,然而在捕获的单词语义信息中,存在部分语义信息对预测AMR图中对齐信息不能发挥直接作用。

图3 单词级别和句子级别语义分析结果示例
为了克服这一问题,本文对语义分析实验进行了微调,即不再固定神经机器翻译编码器的参数,而是在训练语义分析任务的解码器时,同时也对编码器参数进行更新,表4给出了对单词级别语义分析微调后的实验结果。从表中可以看出,神经机器翻译编码器微调后的模型准确率与召回率较之前有明显的提升,在小规模数据上比基准模型高2.53个F1值,在大规模数据上比基准模型高3.78个F1值,且在大规模数据上的F1值比小规模数据高1.25,证明在神经机器翻译编码器能够捕获到的单词级别语义信息中,有部分语义信息是基准系统的语义分析编码器无法完全学习到的。结合3.2节的实验结果,说明了神经机器翻译编码器能够捕获到单词级别与句子级别语义信息,并且通过微调能够提升编码器对单词级别语义信息的学习,使得编码器捕获更多的语义信息。

表4 单词级别语义分析微调后实验结果
类似地,本文对句子级别语义分析同样进行微调。实验结果如表5所示,神经机器翻译编码器在小规模数据上的性能提升较为明显,较微调前提升5.14个F1值,超过了基准系统2.07个F1值,在大规模语料上的神经机器翻译编码器F1值更是达到了75.54,超过基准系统3.7个F1值。句子级别语义分析实验结果同样能够证明,机器翻译编码器能够捕获到语义信息。
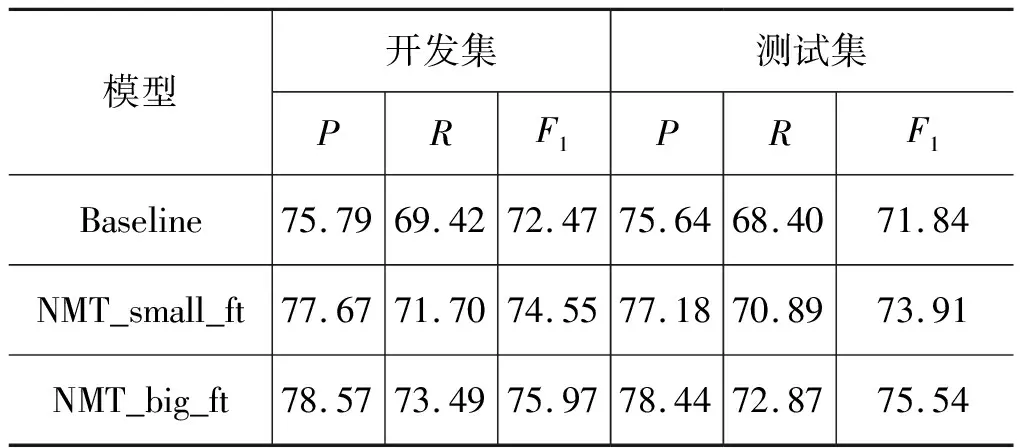
表5 句子级别语义分析微调后实践结果
3.4 句子级别语义分析实验结果对比
从3.3节的实验结果分析得出,使用神经机器翻译编码器参数并基于AMR分析任务进行微调,可以得到较好的分析性能。此外,本文使用以下两种模型集成方法进一步提升性能:①将训练过程保留的最后10个模型参数平均,记为NMT_big_avg;②对训练过程中保留的最后5个模型输出的概率值求平均,记为NMT_big_avg_multiple。
表6比较了相关工作与本文的AMR分析性能。与其他使用非BERT外部资源的相关工作相比,本文方法取得更佳的语义分析性能;与使用BERT的相关工作相比,本文模型简单,并且集成方法取得的性能与其差距较小。

表6 与其他模型性能的比较
4 语义分析和神经机器翻译联合学习
从第3节中可以得知,神经机器翻译的编码器在学习语义上存在潜在的提升空间。本节尝试利用AMR中的语义信息辅助神经机器翻译编码器学习语义,提高翻译性能。
为了使编码器融合更多语义信息,本文在机器翻译任务中联合了AMR解析任务,使用神经机器翻译编码器与AMR解码器解析AMR序列。联合学习模型如图4所示,神经机器翻译与AMR解析共享编码器、独立解码器,在模型训练的每一步中,共享编码器分别联合神经机器翻译解码器(shared encoder-NMT decoder)训练机器翻译任务、联合AMR解码器(shared encoder-AMR decoder)训练AMR解析任务。这里,机器翻译的部分warmup_step参数设置为4 000,learning rate设置为1.0,其余保持与3.1.3节设置一致。
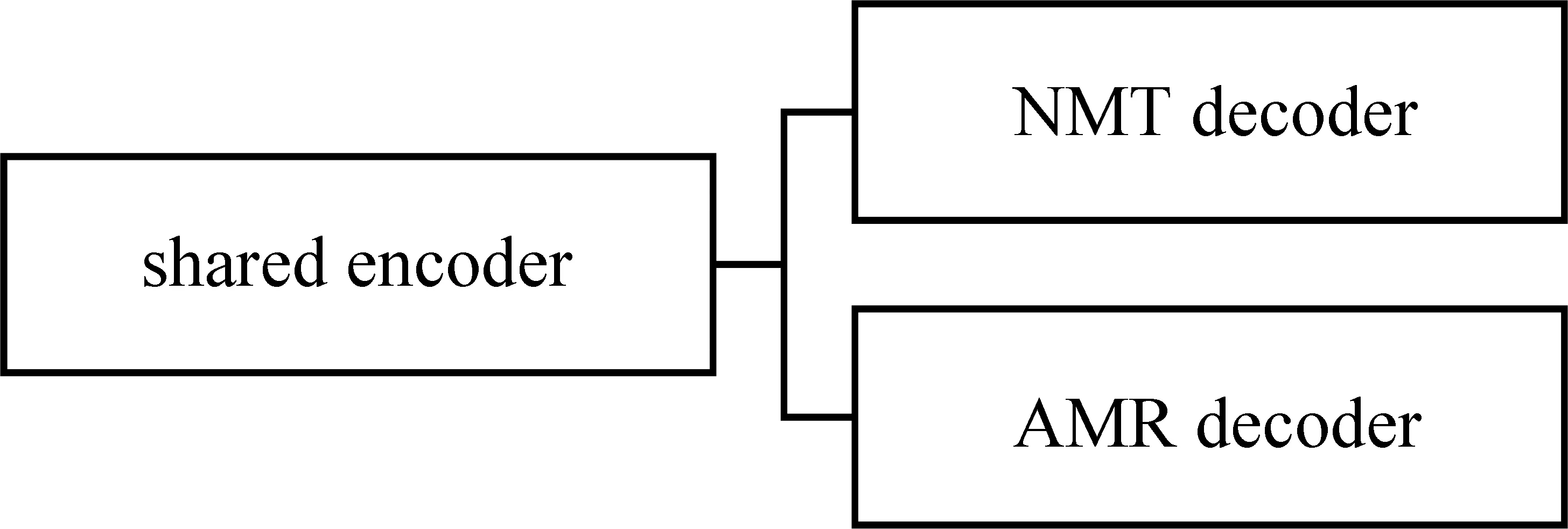
图4 联合学习模型
实验结果如表7所示,在小规模数据上,联合学习模型(Joint_small)比纯神经机器翻译模型(NMT_small)提高了1.17个BLEU值,而在大规模语料上,联合学习模型(Joint_big)比并纯神经机器翻译模型(NMT_big)低了0.92个BLEU值。

表7 神经机器翻译模型与联合学习模型机器翻译的结果对比
实验结果表明,在小规模语料上,神经机器翻译编码器捕获到的语义信息有限,可以利用AMR辅助神经机器翻译学习语义信息、提高翻译性能,这一结论与3.3节的分析保持一致;而基于大规模翻译语料,联合学习中神经机器翻译性能甚至出现下降。综上所述,本文总结了两种可能的原因:
(1)目前AMR还无法做到表示完整的语义。例如,AMR侧重的是描述某个句子内部存在的概念(concept),以及它们之间的语义关系,但同时忽略了时态、名词单复数等信息。神经机器翻译编码器已经能够从大规模的机器翻译语料中捕获到较强的句子级别语义,而AMR中缺失的部分语义反而会影响编码器捕获完整的语义信息。
(2)在大规模数据中,由于联合学习的两个任务语料差距较大,AMR训练语料大小仅为36 K,而机器翻译训练语料大小高达4.5 M。联合学习容易造成模型过拟合AMR分析任务,因此影响了翻译的性能。
5 总结
本文利用了AMR图中包含的单词级别语义与句子级别语义设计实验分析神经机器翻译编码器能否学习到语义信息,并试图利用AMR中包含的语义信息辅助神经机器翻译、提高翻译性能。语义分析实验的结果表明,神经机器翻译编码器能够在很大程度上捕获单词级别与句子级别上的语义,但在单词级别语义的学习上,还有进一步提升的空间。融合语义的神经机器翻译实验表明,在小规模语料中可以通过AMR中语义信息提高神经机器翻译性能,在大规模语料上利用AMR中语义信息提高神经机器翻译性能还存在一定的困难。在未来的工作中,将进一步探索如何在大规模语料中利用AMR中语义信息提高神经机器翻译性能。
