基于密度聚类的高铁覆盖智能测评方案研究
2021-04-27林俐许盛宏
[林俐 许盛宏]
1 引言
随着高铁的快速发展,人们在利用高铁出行的同时,希望能享受稳定的、高质量的移动业务服务,因此高铁用户成为各运营商重点关注的用户群体。高铁用户作为运营商的优质客户,业务需求量较大,需要重点保障高铁沿线移动网络覆盖质量,以便快速提升客户感知,提升业务核心竞争力。
2 现有解决方案
目前,高铁密闭车厢GPS信号屏蔽严重,导致GPS定位困难且不准确,4G网络的用户测量记录MR的AGPS记录也无法使用。路测设备在隧道无法获取GPS信号,不能进行测试位置打点,使得高铁隧道覆盖采用路测的方式也难以评估,导致分析问题片面且准确性不高,同时采用人工进行路面测试,导致消耗大量人力和物力,工作量很大且效率低下。
目前技术方案采用高铁用户识别实现覆盖评估,实现流程如图1所示。首先获取网络信令并按用户分组,通过人工配置高铁沿线小区,当用户经过小区数量满足一定条件的,同时经过相邻小区时间差也满足一定条件的,则确定为高铁用户,通过所有高铁用户的对应时间段的信令分析高铁整体覆盖质量。此方案存在两个问题:第一是需人工及时维护高铁沿线小区清单,否则就会导致出现错漏,影响高铁用户判断的准确度;第二是没有用户记录的具体位置导致无法打点,无法分析质差路段,只能得到整条高铁的线路情况,无法全面进行高铁质差路段的细致评估分析。

图1 目前高铁覆盖测评方案的实现流程
3 智能测评方案
3.1 总体实现思路
针对目前的高铁4G网络覆盖测评需要路面测试,导致工作量很大且效率低、分析问题不全面、不准确等问题,提出了基于密度聚类的大数据高铁覆盖智能测评方法。首先自动识别高铁站台一定范围的基站小区作为站台小区,满足一定条件的用户作为稳定用户,然后通过稳定用户经过的小区得到整个高铁沿线的小区,并将满足一定条件的用户作为非稳定用户,最后通过相关规则计算所有高铁用户每条记录的经纬度,并按线段聚合后采用聚类算法输出连片问题区域,实现了高铁覆盖的精准测评。具体实现步骤如图2所示。
3.2 相关算法研究
(1)线路分段

图2 高铁覆盖智能测评的实现流程
为了实现高铁线路的精细化测评,需要将高铁线路分段采用固定步长进行分段,即从线路起点处开始划分,并采用较短的步长,否则过长的线段,将覆盖指标进行均值计算导致测评结果比较粗糙,不利于发现隐藏问题。线路分段可采用开放地理空间联盟(OGC)制定WKT格式进行存储。线路分段编码包括高铁线路编码和分段编码,分段编码对每一个分段按切段顺序进行顺序编码,每条MR根据定位点所落在线路分段标记上分段编码,便于对线路每一分段做指标汇聚及连续路段问题分析。在实际应用中,高铁线路可以参考高铁MR分布密度进行线路分段的设定,一般推荐采用的分段长度为20 m。
(2)空间几何算法
通过用户MR中的时间提前量TA可以估算出用户与基站小区的距离,1个TA表征的距离大概78.12 m,以基站小区位置为圆心,TA距离为半径,当与线路相切只有一个交点时,则以切点作为用户MR位置点,如果TA距离大于基站到线路距离会出现多个交点,则以最接近基站小区覆盖方向的交点作为定位点,如图3所示,当出现两个交点A和B时,将这两个点和圆心分别相连得到线段D1、D2,且D1和D2长度都为78.12*TA m,同时根据基站小区的方位角θ得到射线D3,此时D1、D2分别与D3计算得到两个夹角α和β,以夹角最小的线段在线路上的端点作为定位点,如图3所示,其中夹角最小(β)的线段为D2,则以其在线路上的端点B作为此条MR位置点的经纬度。
(3)聚类算法
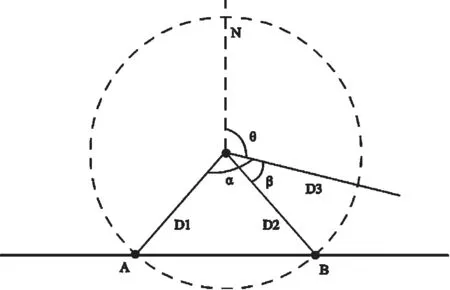
图3 MR位置点经纬度计算示意图
聚类是人工智能中机器学习的一种重要无监督算法,可以将数据点归结为一系列特定的组合。聚类算法包括划分、层次、密度、网格等算法,其中密度聚类算法最为代表的为DBSCAN。为了自动获取高铁连片问题区域,需要通过聚类分析高铁覆盖数据,由于高铁连片问题区域数量是不固定的,推荐采用DBSCAN密度聚类算法。DBSCAN算法原理,如图4所示:数据集中每个点是待分析对象,从中任意取点A,如果A点是核心点(A的邻域半径ε内对象点的个数大于密度阈值minPts),则以A点为核心点搜索,找出A点密度可达的对象点,即找出一个密度互连的最大集合,把集合内的所有对象点都标示为同一簇;如果A不是核心点(如图中N点),没有其他对象点从N点密度可达,那么N点被标示为噪声点。
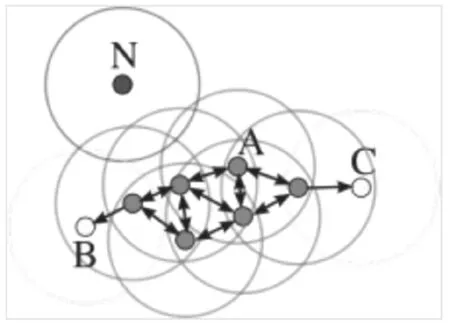
图4 密度聚类DBSCAN算法原理
假设高铁线路采用20 m分段,为了实现问题线段的连片,当DBSCAN算法的邻域半径ε设置为1,密度阈值minPts设置为10,即表示相邻分段直接编号是连续的,相邻分段之间编号差值为1,将会获得连续至少200 m问题线段连片的区域;当DBSCAN算法的邻域半径ε设置为2,密度阈值minPts设置为8,即表示相邻分段之间编号差值小于等于2,至少有8个线段连片构成,将会获得至少160 m问题线段连片的区域,如图5所示。

图5 基于密度聚类算法实现线段连片效果
3.3 关键技术实现
(1)MR和用户号码的关联
无线测量报告MR是无法获取用户号码的,为了通过用户分析识别高铁用户,从而实现对高铁覆盖测评,首先需将MR记录关联到用户号码,由于MR所使用的会话id标识为核心网给用户分配了会话标识,在核心网就会存在会话id和用户号码的对应关系,可通过和LTE核心网CHR(呼叫历史记录)或者S1-MME信令记录的关联,会话id会在一定时间周期内重复使用,需要结合时间窗口进行处理,具体步骤如下:
步骤1:抽取CHR中时间、基站号、会话id、用户号码4个字段,并按时间timestamp排序。如表1所示,CHR字段的基站号(enodeid)、用户号码(msisdn)、会话id(mmeues1apid)表示当前时刻用户在MME侧S1接口上的唯一会话连接标识。

表1 核心网的CHR信令记录
步骤2:读取每条MR,根据MR中的基站号、会话id筛选CHR中等值记录,并找出CHR信令时间小于MR记录时间,且时间最接近MR记录时间的CHR记录,并把其中用户号码作为该条MR用户号码。如表2所示,第一行MR中enodeid 为48**33,mmeues1apid为364911931在表1中时间比它小,且时间最接近的是B号码,故将其作为此条MR的关联号码。同理,可以得到其他MR的用户关联号码,如表2最后一列所示。
(2)高铁稳定用户识别
把一段时间内接入过不同高铁站台的基站小区,且平均移动速度大于150 km/h的用户作为高铁稳定用户,其中高铁站台基站小区,可直接筛选高铁站台位置周边一定范围内的基站小区。例如,根据高铁站台100米范围内查找基站小区,得到部分高铁站台与小区对应关系,如表3所示。

表2 用户无线测量报告MR记录
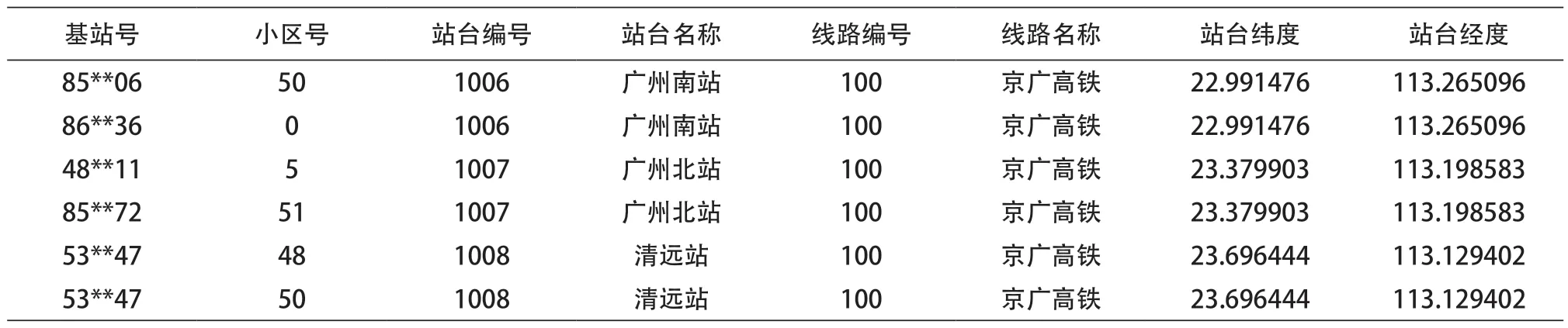
表3 基站小区与高铁站台对应关联表
按用户对MR数据分组,每个分组按时间进行排序,按顺序判断接入小区是否站台小区,如果判断有两个不同高铁站台小区,则计算两个站台小区之间距离及历时,从而计算出用户的平均移动速度,判断速度是否满足速度门限,如果满足则认为该用户是高铁稳定用户,并保留经过不同站台之间所有MR记录,继续按时间顺序判断其他时段是否满足速度门限,提取该用户对应时间段的所有MR记录。如表4所示,已关联用户号码与小区位置MR,包含D和E的两个用户,其中接入过站台小区的只有D用户,在12点48分时刻接入85**72,51小区,属于广州北站小区,在12点57分时刻接入53**47,50小区,属于清远站小区,历时8分53秒,根据两个站台小区经纬度距离计算大约35.942公里,则根据距离与历时得到用户的平均速度为242 km/h,远大于稳定用户速度门限150 km/h,则把1867554用户作为高铁稳定用户,并记录其在12:48:50至12:57:44之间的所有MR。

表4 已关联用户号码与小区位置的MR
(3)高铁沿线小区识别
由于覆盖高铁小区与高铁线路距离远近不一,如将高铁线路附近一定范围判定为高铁沿线的覆盖小区,可能会有所错漏,需要人工进行周期性检查维护。为此,根据上面步骤识别出高铁稳定用户,将所有高铁稳定用户的对应高铁时间段的所有MR记录,通过高铁线路、基站小区编号去重,即可自动获得该高铁线路沿线的基站覆盖小区。如表4所示,稳定用户D在高铁时间段内除站台两个小区外,还经过了85**20_22和53**98_19两个小区,则把这两个小区作为高铁线路的沿线覆盖小区。
(4)高铁非稳定用户识别
在准确得到高铁线路沿线基站小区的情况下,高铁非稳定用户识别方法与稳定用户识别基本相同,只是不要求接入两个不同高铁站台小区,可以站台与沿线小区,或者都是沿线小区,但两个小区距离需要满足大于10公里,因为距离过短计算速度误差过大,最终计算得到用户移动平均速度还需要大于150 km/h。如表4所示,用户E在12:52:21接入85**20_22小区,在12:56:10时刻接入53**98_19沿线小区,时间差距为228秒,距离差距大约为17公里满足大于10公里门限,计算得到用户移动速度大概268 km/h满足速度门限150 km/h,则认为该用户为高铁非稳定用户,并记录其在12:52:21至12:56:10之间的所有MR。
(5)高铁用户MR定位
根据上述步骤得到高铁稳定用户和非稳定用户在高铁线路上的MR,还没有计算MR的具体位置,可通过MR中的TA值及小区的覆盖方位角估算MR的具体位置。根据上述的线段分段算法,高铁线路按20米分段固定长度分段并进行线段编码。如表4所示,假若要计算E用户在12:52:21时刻接入85**20_22小区的具体位置,从表中可以看出此时MR的TA值为5,则可以估算与小区的距离为78.12*5=390.6 m,以390.6 m为半径来画圆,通过上述空间几何算法,如图6所示,可以计算该高铁线路和该圆相交B点所在的20 m线段编号1121895就为该MR所落在线段。

图6 小区452791_11对应MR与高铁线路相交定位
(6)覆盖问题区域连片
基于上述步骤已经把高铁每条MR都关联上了20米分段,按线段编码分组统计每个分段覆盖质量RSRP均值指标及主接入小区,从而得到高铁每个分段的指标数据。假设弱覆盖判断门限为小于-105 dBm,则可以将20米线段的RSRP均值小于-105 dBm的线段都找出来,然后根据上述密度聚类DBSCAN算法,邻域半径ε设置为1,密度阈值minPts为10,输出高铁线路的弱覆盖连片区域,如图7所示,分段上标识为RSRP均值,黑色边框包含的区域都是连续小于-105 dBm的分段。
图7 覆盖问题连片区域示意图
4 方案应用验证
4.1 高铁用户获取
由于高铁稳定用户的MR获取条件比较苛刻,必须要求用户在不同时刻有接入不同高铁站台的基站小区,而MR采集也是抽样采集,可能用户在站台的时候出现漏采,为此需要增加高铁非稳定用户的识别,尽量将所有的高铁用户都能识别出来,使得高铁覆盖测评更加全面、准确。如表5所示,增加非稳定用户,使得高铁线路有效测评长度有10%以上提升,为高铁分析提供更加全面的分析数据。

表5 增加非稳定用户测评长度提升效果
4.2 覆盖测评验证
基于本方案实现的高铁覆盖智能测评试验系统,根据高铁线段覆盖质量RSRP值进行分档,不同分档渲染不同颜色,实现通过不同颜色等级呈现高铁覆盖质量的优劣,总体效果如图8所示。
为了验证本方案是否准确有效,将高铁测评结果和人工路测DT进行对比分析,如表6所示,两者得到的覆盖率只差1%左右,从而验证了本方案测评的准确性,而隧道测评得到覆盖率相差较远,DT测试长度较短,覆盖率较高,是由于DT在隧道卫星信号差,导致隧道测试的数据采集有所缺漏,从而也证明本方案比传统DT测试更加全面。

图8 主要高铁线路覆盖质量智能测评结果概览图

表6 系统智能测评试验结果与DT路测结果对比
为了更加直观呈现隧道测评对比,选取京广高铁清远英德新塘村附近隧道,如图9所示,其中虚线表示隧道,对比可以发现DT测试在隧道中收不到GPS,存在测试点缺失,而系统通过上述算法模型可以计算得到而不会缺失。从表6中也可以看出,隧道占用整个高铁线路大约30%,且覆盖率相对较低,需要重点优化,而本方案能够提供更加全面的测评数据,支撑网络优化,提升高铁用户网络体验。

图9 DT和系统对隧道覆盖测评对比
5 结束语
为解决高铁覆盖测评的工作量大且效率低、分析问题不准确等问题,本文通过4G网络全量MR的大数据分析,提出了高铁覆盖智能测评方案,并通过方案试验结果与路测的结果对比验证了技术方案的有效性,实现及时、全面、准确的高铁覆盖测评,使得高铁覆盖网络优化效率大幅提升,高铁路测费用大幅下降,同时能有效提升高铁用户感知,具有良好的推广应用价值,推动无线网络优化的数字化转型。后续结合强化学习技术不断提升测评准确性,进一步实现高铁线路测评结果的智能诊断功能,更有力支撑高铁覆盖网络的智能优化。
