立法汉语精准性特征百年历时变化研究
2021-04-27武汉工程大学湖南师范大学郑剑委
武汉工程大学 湖南师范大学 郑剑委
1.引言
精准性是立法语言的本质特征,即“严密、周全、审慎的倾向”(罗士俐 2011:114),也就是说,立法语言应具有简洁凝练、准确明晰的特征(王洁 1999;周子伦 2014),它体现在定量上的精简(“精”)以及定性上的准确(“准”)(1)也有学者指出,准确性是法律语言的根本特征(陆宏哲 1989;谢爱林 2007)。。立法者要用精简的法律语言准确表达法律目的、事实或标准。但是,精和准是精准性的两个矛盾性维度,立法语言无法同时实现精和准的最大化。理论上说,为实现准确性,语言必然周详冗长,由此简洁精练就无法保证;同样,语言越精练,语义就越容易模糊,由此准确性得不到保证。正如杜金榜所言,“法律语言是矛盾的统一体,是各种因素协调的产物”(杜金榜 2004:1)。
法律语言特征的研究文献非常丰富,国内早期研究以经验式描述为主,如潘庆云(1989)、孙懿华、周广然(1997)、杜金榜(2004)。随着语料库被引入语言研究,法律语言研究者纷纷构建法律语言语料库,例如广东外语外贸大学“法律信息处理系统语料库”(2007~2014)、绍兴文理学院“中国法律法规汉英平行语料库”(2009)、圣地亚哥联合大学“英语法律报告历史语料库(1535~1999)”(2016)。法律语言学界也兴起语料库研究潮流,如Janigov(2007)、程乐(2010)、蒋婷(2012)、Marín(2014)、Vogeletal.(2018)。基于语料库的语言特征变化研究文献也并不鲜见,例如,Fanego和Rodríguez-Puente主编的Corpus-basedResearchonVariationinEnglishLegalDiscourse(《法律英语语篇语料库研究》)收录了5篇有关法律语篇历时变化的研究论文,包括法律报告口语体和复杂结构的历时变化研究(Biber &Gray 2019)和法律报告人称代词的演变研究(Rodríguez-Puente 2019)等。
然而,除郑剑委(2017)对比分析大陆、香港和台湾法律汉语“庄重性”的历时变化外,鲜有研究定量分析立法汉语特征的历时演变。本研究在构建中国近现代刑事立法汉语历时语料库的基础上,确立了精准性的两个矛盾性测量变量,即“精”(精简性)和“准”(准确性),通过主成分分析法测定这两个变量各自组成指标的权重,然后采用加权平均测定这两个变量在不同年份的值,分析中国1911年至今立法汉语精准性特征的历时演变,以揭示中国百年来法制发展进程。
2.历时语料库与分析工具
鉴于刑法的颁布和修订在中国近现代很少中断,本文以近现代刑事立法为语料,构建历时语料库,以反映中国立法汉语语体特征的历时变化。该语料库包括中国1911年、1928年、1938年、1951年、1957年、1979年、1997年、2006年、2011年和2015年的刑法。之所以选取这些年份的刑法,是因为中国刑法在这些年份颁布或进行了重要修订:1911年颁布了《大清新刑律》,民国政府1928年颁布了《中华民国刑法》;新民主主义革命期间到社会主义革命初期并没有通行的系统性刑法典,仅颁布了《陕甘宁边区政府惩治贪污暂行条例》(以下简称《惩治贪污条例》)(1938年)、《陕甘宁边区处置破坏抗战分子暂行条例》(1938年)、《破坏边区治罪条例》(1938年)以及《中华人民共和国惩治反革命条例》(以下简称《惩治反革命条例》)(1951年)、《妨害国家货币治罪暂行条例》(1951年)等零散刑事法律;自20世纪50年代初以来,中国开始起草刑法典,于1957年完成《中华人民共和国刑法草案》(俗称“第22次稿”),由全国人民代表大会常务委员会办公厅印制,发给参加一届人大四次会议的全体代表征求意见,但在随后的政治运动中被搁置;1979年正式颁布了《中华人民共和国刑法》,随后不断修订,重要修订为1997、2006、2011和2015年修正案。
笔者首先对语料进行了分词处理(分词软件ICTCLAS 2015),然后用AntConc(3.4.4)检索分析中国刑事法律文本的类符形符比、词语占比和平均句长等指标。“精”和“准”这两个变量的组成指标的权重用主成分分析法(通过SPSS 22.0软件进行分析)确定,变量的值用各组成指标的加权平均计算。
3.近现代立法汉语语体历时流变
3.1 精准性的测量变量
首先,在立法文本中,“精”可以表现为词汇的文言化、句法上的平均句长以及语篇上的代词。具体而言,在精简性立法语言中,简洁凝练的文言词汇被大量使用,例如“他/她/它(们)的”仅需“其”就可以全部替代;在句法上,平均句长越短,文本当然越精简;代词是语篇衔接手段,也是实现精简性的重要手段,立法文本中的代词(包括“之”“其”“此”“该”“他”和“自己”)往往指代前文翔实冗长的规定,例如《刑法》第180条中,“泄露该信息”中的“该信息”指代前文提到的“证券、期货交易内幕信息”。由此,立法语言的“精”(Conciseness)可由词汇精简性变量(Lexical Conciseness,简称LCN)(用文言词“之”占总词数(2)总词数为ICTCLAS 2015分词处理后的形符数。的比例表示)、句法精简性变量(Syntactic Conciseness,简称SCN)(用平均句长(3)平均句长为总词数除以总句数的值。本文以分句(用分号或句号为标志)作为句子单位。之倒数表示)和语篇精简性变量(Discourse Conciseness,简称DCN)(用代词占总词数的比例表示)衡量。
由于LCN(比例数据)、SCN(倒数)和DCN(比例数据)的数据量纲不同,不可直接对比或整合。因此首先对这3组数据进行min-max标准化,全部处理为(0,1)之间的小数。不能直接计算这3个指标的算术平均来代表变量“精”的值,因为不同指标的权重可能并不相同。只有通过确定各指标权重,以求其加权平均才是计算“精”变量之值的科学方法。指标权重的确定方法(简称“赋权法”)有很多,主成分分析法是客观赋权法的一种。本文采用主成分分析法确定3个指标的各自权重,由此测量“精”这一变量的数值。
根据主成分分析法,指标权重等于该指标在主成分线性组合中的系数的主成分方差贡献率加权平均的归一化。采用SPSS 22.0软件对这3个指标的数据进行主成分分析,获得总方差的解释表和成分矩阵(见下页表1、表2)。其中,总方差解释表显示各个因子所能解释的方差比例,比例越高,表示这个因子包含的原变量信息越多;成分矩阵显示3个指标在该主成分之中的负荷。
表1显示,特征根大于1而且方差贡献率高于60%的只有1个主成分。因此,第1个主成分(成分1)基本可以反映全部指标的信息,其他两个成分可以忽略。接着要计算“精”的3个指标的评分系数,以此确定其权重。指标的评分系数等于3个指标的负荷数值除以表1第1列主成分(成分1)特征根的平方根。除了得出总方差解释表(表1),通过SPSS 22.0软件进行的主成分分析法同时得出表示各指标负荷的成分矩阵(表2)。
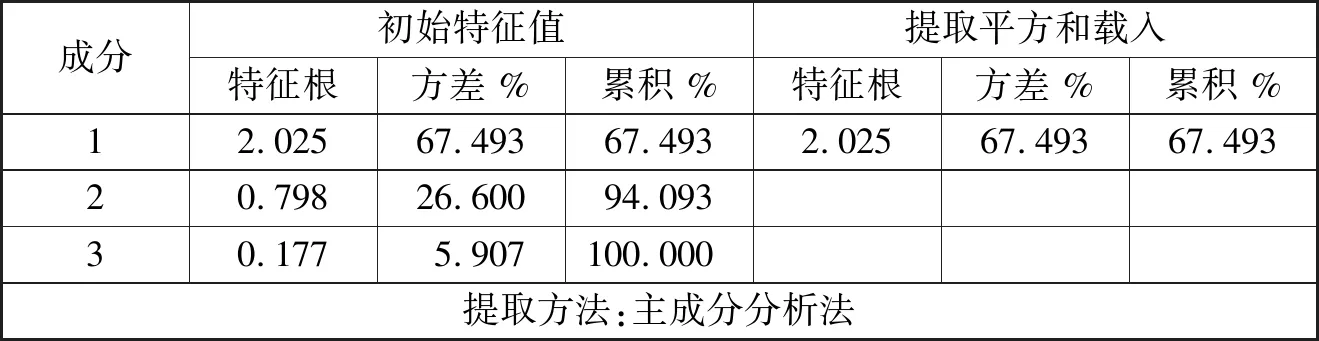
表1 总方差解释表

表2 成分矩阵
根据表1成分1的特征根和表2各指标的负荷数值,计算得出各指标的评分系数(见表3第2列)。然后对各指标的评分系数进行归一化计算,得出该指标在“精”变量中的权重,即指标权重(见表3第3列)。

表3 各指标评分系数和指标权重
表3第3列显示,LCN、SCN和DCN归一化后的指标权重分别为0.386(即38.6%)、0.249(即24.9%)和0.365(即36.5%),获得3个变量的实际数值即可根据各指标的权重大小,采用加权平均算法获得“精”变量的数值。
另一方面,“准”(Accuracy)可表现为句法上的定义条款以及语篇上的重复手段。在立法语言之“准”的实现方面,定义条款能体现立法语言的“准”。定义条款是指“在法律法规中对特定法律术语的内涵和外延进行界定的相对独立的法律条文”,其功能在于“准确地传达立法目的”(赵军峰、郑剑委 2015:110,114),故定义条款在总句数中的占比可作为句子层面准确性的测量变量(Syntactic Accuracy,简称SAC)。语篇上,重复手段是实现“准”的方式,正如杜金榜所述,“为了保证准确性,法律法规常用重复等手段,而非人称代词或指示代词”(杜金榜 2004:13),因此语篇准确性测量变量(Discourse Accuracy,简称DAC)可用类符形符比的倒数表示。总之,立法语言之“准”可用SAC和DAC的加权平均表示,即(SAC*f1+DAC*f2)/2,其中f1和f2分别表示SAC和DAC的权重,计算方法与变量“精”的计算方法相同。首先对SAC和DAC的数据进行标准化处理,然后用SPSS 22.0对其进行主成分分析,确定两个指标的权重均为0.5。
3.2 两个变量值的历时演变
根据表3的指标权重,可用3个指标的加权平均来确定变量“精”的值,即(LCN*0.386+SCN*0.249+DCN*0.365)/3,由此获取1911年、1928年、1938年、1951年、1957年、1979年、1997年、2006年、2011年和2015年中国刑事法律汉语的变量“精”的数值,用曲线图(见图1)表示,反映立法语言精简性特征的历时变化。
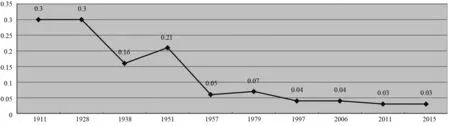
图1 近现代刑事法律语言精简性历时变化
图1显示,中国近现代立法汉语精简性总体下降,主要表现为文言词汇占比的下降(从1911~1928年的0.06左右到1938年的0.039再到1957~2015年的0.0028左右)、平均句长的增大(从1911年的16.88逐渐增至2015年的21.86)和代词占比的降低(从1911~1951的0.02左右降至1957~2015年的0.007以下)。精简性下降最快的时间段为20世纪50年代,集中表现为立法文本半文言语体向白话文语体的转变。由于文言文要比白话文更为简洁凝练,这种转变自然能够解释立法语言精简性的下降。例如,1938年《惩治贪污条例》第7条“犯本条例之罪者,由地方法庭审判,呈边区高等法院核准后执行之”(艾绍润、高海深 2007:87)。属于半文言语体,而1951年《惩治反革命条例》,例如第4条 “其他参与策动、勾引、收买或叛变者,处十年以下徒刑;其情节重大者,加重处刑”(公安部政策法律研究室 1980:96)和《妨害国家货币治罪暂行条例》,例如第4条“意图营利而伪造国家货币者,其首要分子或情节严重者,处死刑或无期徒刑,其情节较轻者处十五年以下三年以上徒刑,均得没收其财产之全部或一部分”(公安部政策法律研究室 1980:67),基本采用了现代白话语体。1957年《中华人民共和国刑法草案》用“的”字句完全取代了“者”字句,且不再使用“之”字(做代词用)和“亦”字等,即完全采用了白话语体,例如第55条“对于反革命分子,应当剥夺政治权利;对于其他被判处五年以上有期徒刑的犯罪分子,在必要的时候,也可以剥夺政治权利”和第107条“以反革命为目的,进行下列破坏、杀害行为之一的,处死刑、无期徒刑或者十年以上有期徒刑;情节较轻的,处五年以上十年以下有期徒刑”(北京政法学院刑法教研室 1980:87,92)。
促成这种转变的原因是中华人民共和国成立初期开展的普通话运动。1954年中国文字改革委员会(即如今的国家语言文字工作委员会)成立,1956年《关于推广普通话的指示》明确要求“以北京语音为标准音、以北方话为基础方言、以典范的现代白话文著作为语法规范的普通话”。这次语文运动也直接影响立法文本的语体标准,具体表现为立法汉语的文言表达大幅度减少,由此精简性水平随之下降。另一方面,立法汉语特征“准”(ACC值)的历时变化可用图2表示。
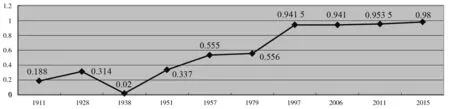
图2 近现代刑事法律语言准确性的历时变化
刑事法律汉语“准”值总体上趋高(见图2)。具体而言,在语篇层面,重复手段占比上升最快。类符形符比越低,单词重复率就越高,而近现代中国刑事法律文本类符形符比从1911年的0.842下降至2015年的0.148,用其倒数表示的语篇准确性(DAC)上升。需要指出的是,1938年的单词重复率要比前后时期低,这是因为这个时间段的刑事法律零散、粗浅且不成系统(赵秉志 2012),难以保持准确性,因此在很大程度上导致1938年“准”值的“低谷”。另一方面,在句子层面,定义条款占比也有所上升,从1911~1938年的0.01上升到1951年的0.027再到1957~2015年的0.035,即句子准确性(SAC)上升。例如,1938年《陕甘宁边区处置破坏抗战分子暂行条例》、1938年《陕甘宁边区政府惩治贪污暂行条例》和1951年《妨害国家货币治罪暂行条例》各包含1条定义条款,1957年刑法草案包含18条定义条款,1979年刑法包含20条定义条款。就政治时代性而言,1928年比1911年准确性更高,这显示出民国刑法相对于封建主义刑法的优越性。此外,改革开放初期准确性上升最快,这与中国法制发展进程紧密相关。新中国初期法制建设摩拳擦掌,也有所成就,20世纪50年代初颁布了《宪法》和《婚姻法》,并完成了《刑法草案》,但反右倾和文革等政治运动使法制建设陷入低谷。改革开放后,搁置了20余年的《刑法》得以颁布,成为中国第一部现代刑法典(赵秉志 2012),这部法律的语言准确性相比以往的刑法典提高了很多。例如,1957年刑法草案第117条的行为模式表述(文字改革出版社 1985:35)“倾覆、破坏有人乘坐的火车、汽车、船只、航空机的”(北京政法学院刑法教研室 1980:94),没有阐明“倾覆”与“破坏”之间的语义关系,而1979年刑法107条的行为模式表述“破坏火车、汽车、电车、船只、飞机,足以使火车、汽车、电车、船只、飞机发生倾覆、毁坏危险”(辽宁大学法律系刑法教研室 1983:157),指出“颠覆”是更严重的“破坏”,同时增加“电车”,表述更为准确。
4.结语
中国近现代立法汉语精准性语体特征具有时变性,整体变化表现为牺牲语言之“精”,换取语言之“准”,即立法汉语逐渐趋向于采用周全的表述严密地阐述立法事实和标准。这种变化折射出近现代汉语的文体变迁,即从封建时期的文言到近代的半文言再到现代的白话,立法汉语用半个世纪的时间实现了彻底的文体革命。同时,这种变化也揭示出中国法制进步的整体趋势,以及中间经历的挫折。
这种趋势与旨在帮助作为法律最终承受者的普通公民更好地理解法律条文的“法律英语平白化运动”(Plain Legal English Campaign)(Kimble 2006;Naudi 2018)相得益彰。刘承宇、汤洪波(2020)指出,法律语言为“法治”之目的,应为普通民众所理解,法律语言“大众化”十分必要。立法语言的浅白化和大众化使法律成为真正意义上能够为民众所理解、所遵守并赖以保护自我的法律。这种“大众化”集中体现在立法语言“精”度的下降和“准”度的提高,中国立法语言的这种特征变化反映出中国法制的趋向成熟。本研究基于刑事法律语料库,借鉴主成分分析法,用词汇、句法和语篇的某些特征来表示“精”和“准”两个测量维度,考察了刑事法律汉语精准性特征的历时变化,揭示了近现代中国立法的语言变化,也反映出中国法制发展历程。同时,这种量化统计方法为文体特征研究提供了新的研究范式,为历史语言学、语料库语言学和语言变体研究提供新的研究方法。
