基于非关系型数据库的水文数据分析方法研究
2021-04-27余国倩陶光毅赵天宇
余国倩 ,陶光毅 ,赵天宇 ,刘 冰
(1.山东省水文局,山东 济南 250002;2.山东国基光晔信息科技有限公司,山东 济南 250021;3.南水北调东线山东干线有限责任公司,山东 济南 250019)
0 引言
随着水文事业的发展和信息化技术的进步,水文数据的种类和体量都在快速增长。目前我国积累了大量宝贵的水文资料,如何充分利用这些长期积累的水文资料进行水文分析,以及对分析挖掘的结果进行原始数据溯源,显得非常重要。
水文数据中,分钟降水数据是强降水天气过程、特征研究的基础资料[1]。降水自记纸记录的分钟降水量对于了解和研究长年历史分钟雨量特征及规律尤为重要[2]。利用信息化技术对纸质降水自记纸记录进行数字化,从降水迹线提取分钟降水数据[3–4]会产生海量数据,仅山东省临沂市降水自记纸记录数字化获取的分钟降水数据就约为 2.36 亿个。水文数据中有大量的文字信息需要分析,包括从文本格式水文资料非结构化数据中抽取的文字内容,如水文论文、水资源资料、水文测站测验资料和考证簿,等等。
1 基于非关系型数据库的水文数据分析方法
数据来源于山东省水文局提供的 4 786 个水文测站的基本信息,临沂市 143 个水文测站 1958—2013 年降水自记纸记录数字化获取的约 2.36 亿个分钟降水数据、约 48 万个降水自记纸正面和背面图像文件及人工记录信息。
将水文数据存储在 TRIP 数据库中,将搜索引擎集成在 TRIP 数据库中,分析函数集成在 TRIP 数据库的分析应用程序中。利用 TRIP 数据库存储、索引、中文自动分词、搜索引擎和统计分析功能,在设定的分析范围对水文数据进行分析。分析范围设定的方法与检索条件设定的方法相同,包括:全文分析范围,字符、数值、日期、时间和文本等字段的分析范围。分析范围可以是 1 个或多个字段的数据,使用多个字段设定分析范围时,用逻辑运算符“与”“或”“非”组成合适的连接式。字符字段的整个字段内容分析需设定整个字段内容重复的次数,字符字段中词的分析需设定词重复的次数;数值分析需设定开始值、结束值和间隔值;日期分析需设定开始和结束日期及间隔值(年、月、日);时间分析需设定开始和结束时间及间隔值(时、分、秒);文本字段中词的分析需设定词重复的次数。
按照 TRIP 数据库存储水文结构化和非结构化数据的字段类型基本要求,建立水文测站、分钟降水、降水自记纸图像文件等数据库,分别存储水文测站基本信息、分钟降水数据、降水自记纸图像文件及其人工记录信息。水文测站数据库主要有站码、站名、观测项目、流域、站类等字段;分钟降水数据库主要有站码、站名、起始日、起时间和分钟降水量等字段;降水自记纸图像文件数据库主要有站码、站名、起始日、起时间、虹吸订正后日降水量、正面和背面图像文件等字段。对数据库中所有文字、数值、日期、时间内容进行索引,并将字符字段的整个字段内容作为 1 个词进行索引,索引存储在索引文件中。中文分词采用基于词典的中文分词方法分析进行[14],编制的水文中文分词词典应包括水文基本术语[15]。
2 基于非关系型数据库的水文数据分析结果
2.1 水文观测项目分布
山东省水文测站的观测项目有 13 项,即流量、水位、悬移质、降水、蒸发、冰情、地下水水位、水质、墒情、水文调查、颗粒分析、比降、水温。每个测站的观测项目不尽相同,有 1 项或多项。在水文测站数据库中 13 个观测项目名称存储在“观测项目名称”字符字段。
2.1.1 组配完全相同的水文观测项目分布
使用字符字段的整个字段内容分析的方法,无需知道观测项目和水文测站的名称,只需对观测项目名称字段的整个字段内容进行分析。例如:设定观测项目名称字段的整个字段内容重复的次数大于0,可获得 68 种组配完全相同的观测项目分布,程序运行用时小于 1 s,水文测站组配的观测项目从1 个到 11 个不等,具体分布如表1 所示。点击分析结果中的观测项目组配名称或测站数,可以读取数据库中组配完全相同的观测项目的详细信息,观测项目组配流量、水位、降水的详细信息如表2 所示。
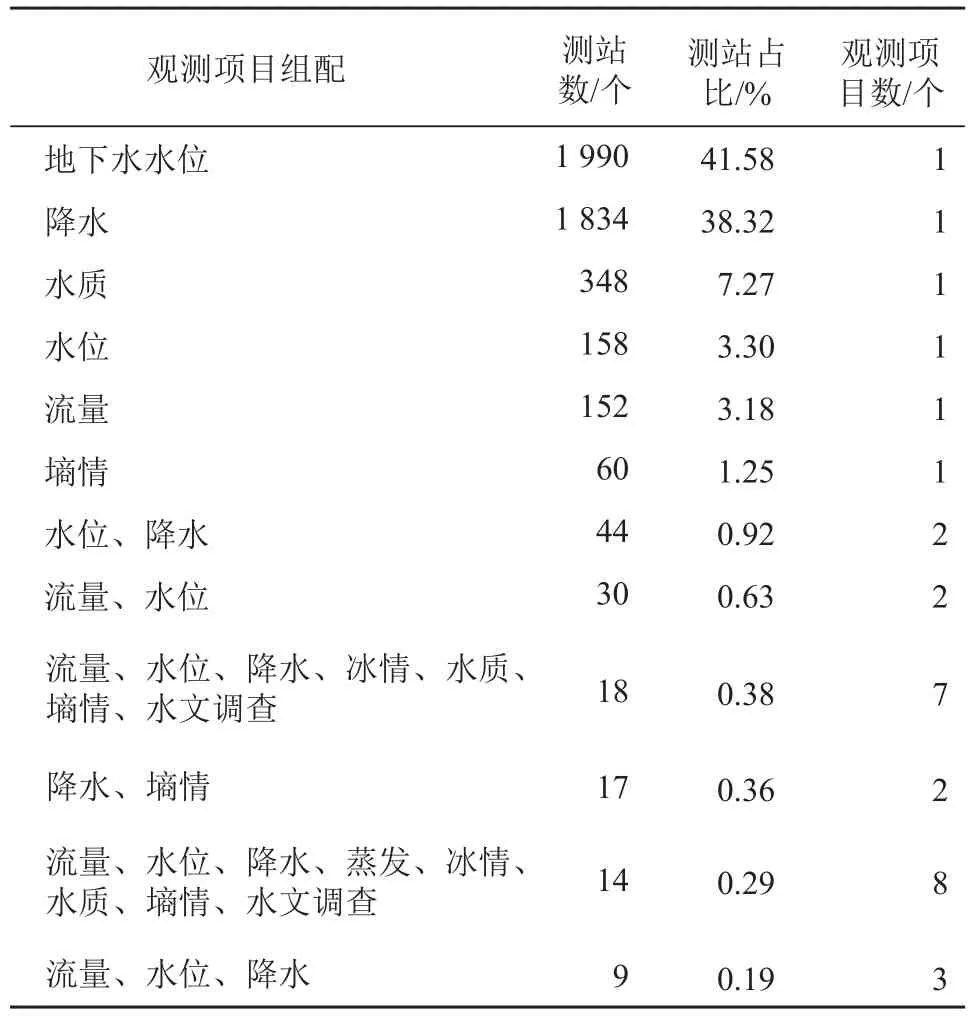
表1 组配完全相同的观测项目分布(按测站数排列前 12 位)

表2 观测项目组配流量、水位、降水的详细信息(按站码排列前 5 位)
2.1.2 水文观测项目分布
应用SPSS 21.00软件进行分析,计量数据与计数数据采用均数±标准差与百分比、率表示,对比方法主要为t检验与卡方χ2分析,P<0.05为差异显著。
使用字符字段中的词分析的方法,无需知道观测项目和水文测站的名称,只对观测项目名称字段的每个观测项目名称进行分析。例如:设定观测项目名称字段中的词重复的次数大于 0,每个观测项目名称必须是中文分词词典中的词,可获得 13 个观测项目分布,程序运行用时小于 1 s,具体分布如表3 所示。点击分析结果中的观测项目名称或测站数,可以读取数据库中每个观测项目的详细信息,墒情观测项目的详细信息如表4 所示。
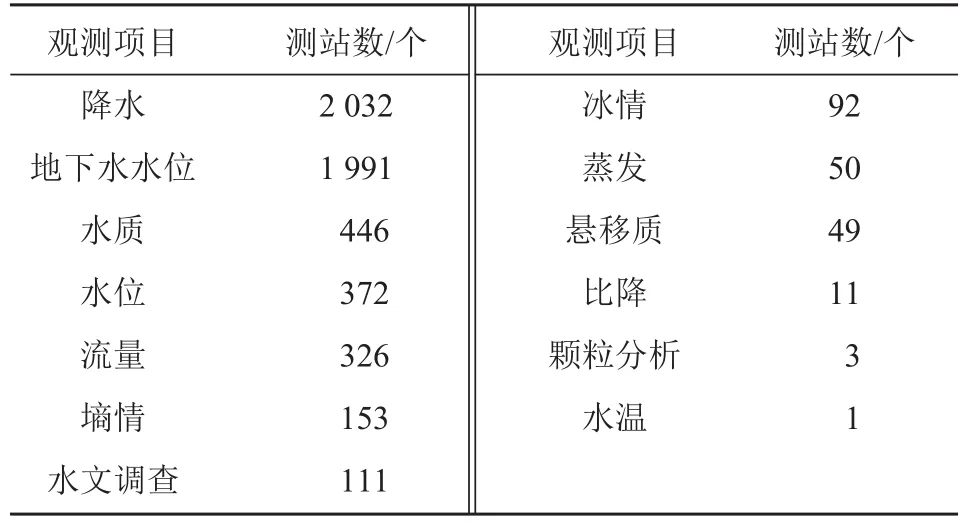
表3 观测项目分布
2.2 降水变化特征统计分析
2.2.1 不同年份降水量分布
设定统计分析的日期范围为每年 5 月 1 日—10 月 31 日,使用数值字段统计分析的方法,逐年对分钟降水数据库中临沂市 143 个水文测站 1958—2013 年的降水量进行统计分析。以 1990 年为例,116 个测站共有 5 707 条降水迹线,约有 822 万条分钟降水记录,程序运行用时约 3 s。对 56 a 的年度统计进行分析,累计运行用时约 168 s。
2.2.2 不同月份降水量分布
统计分析的设定范围为每年汛期 6—9 月,使用数值字段统计分析的方法,逐年逐月对分钟降水数据库中临沂市 143 个水文测站 1958—2013 年的降水量进行统计分析。以 1990 年 7 月为例,116 个测站共有约 229 万条分钟降水记录,程序运行用时约3 s。对 56 a 的 6—9 月进行历年月份降水量统计分析,累计运行用时约 672 s。总体分析如下:7 月降水量最多,其次是 8 月,9 月降水量最少;2005 年9 月比同年其他月份降水量多;1963 年和 1970 年的7 月是历年汛期降水量最多的月份。

表4 墒情观测项目的详细信息(按站码排列前 5 位)
2.2.3 不同时段降水量分布
使用数值字段统计分析的方法,分时段对分钟降水数据库中临沂市 143 个水文测站 1958—2013 年的降水量进行统计分析。采用 5—10 月的降水量,设定统计分析的起时间为整点,1 h 为 1 个时段,平均每个时段约有 974 万条分钟降水记录,程序运行用时约 7 s,对 24 个时段进行统计分析,累计运行用时约 168 s。总体分析如下:临沂市夜(20:00—次日 8:00)降水量大于昼(8:00—20:00)降水量,夜降水量占总降水量的 52.65%,昼降水量占总降水量的 47.35%。
2.2.4 单站单日降水量分布
使用数值字段统计分析的方法,对降水自记纸图像文件数据库中临沂市 143 个水文测站 1958—2013 年的日降水量进行统计分析。设定日降水量间隔值为 50 mm,获得单站单日降水量分布,程序运行用时小于 1 s。点击分析结果中的日降水量或站次可以读取数据库中单站单日降水的详细信息,并对降水自记纸图像文件进行溯源。单站单日降水量为300.1~350.0 mm 的详细信息如表5 所示。
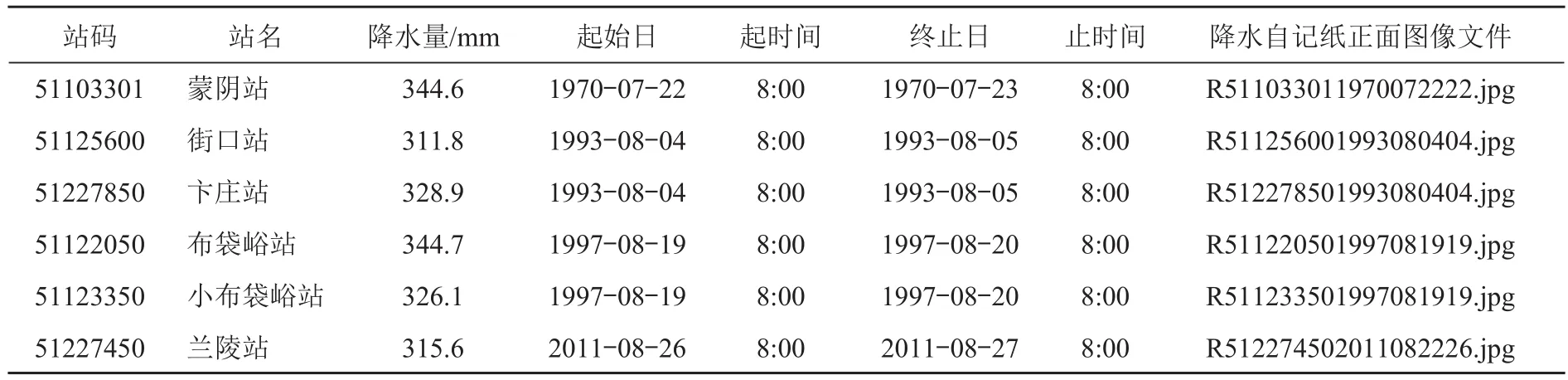
表5 1958—2013 年临沂市单站单日降水量为 300.1~350.0 mm 的详细信息(摘录)
3 基于非关系型数据库的水文数据分析讨论
3.1 水文数据的文字内容分析
将字符字段的整个字段内容作为 1 个词进行索引,索引存储在索引文件中,这样,就将整个字段相同的内容汇聚在一起。对整个字段内容进行分析时,将整个字段内容作为 1 个词进行分析,无需知道组配的观测项目名称,通过分析所有组配的观测项目名称出现的次数,就可获得所有组配的观测项目名称及出现的次数,获得组配完全相同的观测项目分布。
对字符字段中的词进行索引,索引存储在索引文件中,这样,就将字段中相同的词汇聚在一起。使用字符字段中的词分析方法,无需知道观测项目名称,对观测项目名称中的每个观测项目进行分析,就可获得所有观测项目名称及出现的次数,获得观测项目分布。观测项目名称必须是水文中文分词词典中的词。
对文本字段中的词(包括从文本格式水文资料非结构化数据中抽取的词)进行全文索引,索引存储在索引文件中,这样,就将字段中相同的词汇聚在一起。使用文本字段中的词分析方法,无需知道有哪些词,对全部词进行分析,就可获得所有词及出现的次数。词必须是水文中文分词词典中的词。
3.2 站网密度对水文数据分析的影响
本研究使用的数据来自于临沂市 143 个测站,每年参与监测的平均测站数为 61 个,站网平均密度达到 282 km2/站,测站分布在山地、丘陵、平原等不同地形处。水文站网是开展水文工作的基础,其布设是否合理,密度是否得当,直接影响到水文数据的可靠程度和分析的准确性,对水文工作的开展有着广泛而深远的影响[16]。对于站网布设不合理和密度低的区域,按最优站网的要求,调整站网布设同,增加站网密度,使水文站网的整体功能达到最强。
3.3 分钟降水数据对降水变化特征分析的影响
采用信息化技术提取分钟降水数据,处理过程更客观,减少了同一条降水迹线不同人读取时可能产生数值大小的偏差。分钟降水量可以满足降水时空精细化分析要求。
使用临沂市 143 个测站 1958—2013 年的分钟降水量,分析临沂市不同年份、月份、昼夜的降水变化特征,结果如下:2002 年汛期降水量最少,仅为248.3 mm,与张胜平等对 2002 年汛期山东全省平均降水量为 238.0 mm 的分析结果[17]基本相同;2005 年汛期降水量为 838.4 mm,每个月份降水量都较高,尤其是 9 月份降水量达到 252.8 mm,为历年 9 月份降水量最高,与张世功等对 2005 年 9 月份临沂全市平均降水量为 246.4 mm 的分析结果[18]接近;临沂市夜降水量大于昼降水量,夜降水量占总降水量的52.65%,昼降水量占总降水量的 47.35%,与贾艳青等对华北地区昼夜降水量分布的结论[19]基本一致。
3.4 水文数据分析结果的溯源
水文数据溯源是对分析的原始数据进行溯源。历史降水数据溯源须找到降水自记纸原始记录,包括降水自记纸记录的降水迹线和人工记录信息。将临沂市 143 个水文测站 1958—2013 年的全部降水自记纸记录数字化获取的约 2.36 亿个分钟降水数据存入分钟降水数据库,将约 48 万个降水自记纸正面和背面图像文件及人工记录信息,按照匹配关联关系全部装入数据库。降水自记纸正面和背面图像文件及人工记录信息存储在同一条记录,同时自动生成唯一的记录号,高效地将降水自记纸正面和背面图像文件及人工记录信息组织在一起,根据分析结果,可快速读取文件及信息并进行溯源。
4 结语
基于非关系型数据库的水文数据分析方法,充分利用非关系型数据库存储海量水文结构化和非结构化数据,以及对文字信息索引的功能,在硬件低配置的条件下,设定统计分析的范围,快速对水文数据进行分析。对降水变化特征的分析,不是使用摘录的自记降水数据或整编的降水数据,而是使用临沂市所有 143 个测站 56 a 积累的全部降水自记纸记录数字化提取的分钟降水数据,这样能够从不同的角度,更细致地观察和研究降水数据的方方面面,进行新的分析,深入挖掘降水数据的价值。对字符字段的整个字段内容及字符和文本字段中的词进行分析,可以有效用于水文数据中的文字信息分析。
今后的研究中将增加更多的分析功能,深入挖掘水文数据的价值,研究分析水文数据的相关和因果等关系,为管理决策提供科学依据。
