软件定义无线接入网络的组件化研究
2021-04-25徐海东易辉跃
徐海东 王 江 易辉跃①
①(上海无线通信研究中心 上海 201899)
②(中国科学院上海微系统与信息技术研究所 上海 200050)
1 引言
传统的无线接入网络基于专用硬件进行构建,网络硬件设备复杂,部署和维护困难,且不利于扩展。为了解决这个问题,基于软件定义的各种接入网技术应运而生。比较著名的有中国移动提出的基于实时云型基础设施的无线接入网(Cloud-Radio Access Network, C-RAN)[1],C-RAN的室内基带处理单元(Building Base band Unite, BBU)基带池处理完全基于软件无线电实现[2]。根据基带运行平台的不同,可以将软件定义接入网络分为基于通用处理器平台及基于DSP平台两类。IBM提出的无线网络云[3]属于前者,中国科学院计算技术研究所提出的超级基站[4]属于后者。近年还涌现出了很多基于通用处理器的无线接入网络开源软件,以4G长期演进技术 (Long-term Evolution, LTE)为例,有法国EURCOM组织的露天接口 (Open Air Interface, OAI)[5]和爱尔兰SRS公司(Software Radio Systems limited)的srsLTE[6,7]。上海无线通信研究中心也曾经在OAI开源软件的基础上进行过进一步完善,实现了能够支持数十个商用终端接入,体积只有手掌大小的LTE全功能软基站[8]。文献[9]将软件定义接入网络应用到车联网中。
软件定义网络的灵活性很强,可以满足各种客户化的编排要求。但是软件定义的系统也可以非常复杂,不易开发与维护,这就背离了软件定义网络的初衷。于是虚拟化、切片化、组件化的概念应运而生,这其中,组件化是虚拟化和切片化的基础,是软件定义网络发展的必然趋势。进入5G时代,随着通信速率进一步提高,物理层的处理压力陡然加大,软件定义网络还面临DSP或通用处理器的计算瓶颈,也迫切需要进行组件化改造,以利于采用分布计算技术或者硬件加速技术。另一方面,由于5G需要满足增强型移动宽带(enhanced Mobile BroadBand, eMBB)、海量机器类通信(massive Machine Type Communications, mMTC)、超可靠及低时延通信(ultra-Reliable and Low-Latency Communications, uRLLC)等不同场景的应用需求[10],也需要对接入网进一步分割,实现端到端的网络切片,以达到网络的灵活弹性。
本文首先分析了无线接入网络架构的现状,接着分析了无线接入网络组件化面临的问题,并提出了一种组件化架构的无线接入网络,此架构由有源天线单元(Active Antenna Unit, AAU)、射频单元(Radio Unit, RU)、分布单元(Distributed Unit,DU)、集中单元(Centralized Unit, CU)、集中控制单元(Centralized Control Unit, CCU)等5种基本通信单元组成,在此基础上可以构建易部署、可切片的软件定义无线接入网络。本文还实现了基于该架构的试验原型,试验原型的测试结果表明,这种组件化方案在提供高度灵活性的同时,还能够显著提升软件定义无线电接入网(Radio Access Network,RAN)的处理能力,有效降低通用公共无线接口(Common Public Radio Interface, CPRI)[11]流量。
2 无线接入网架构现状与组件化难点
从4G到5G,无线接入网的基站从eNodeB的BBU和远端射频单元(Remote Radio Unit,RRU)两级架构演化为gNodeB的CU, DU, AAU 3级架构[12],网元变得更小、更多了,反映了无线接入网络组件化的发展趋势。然而,5G接入网架构存在以下问题,不利于采用软件无线电方法实现:
(1) 集中式的CU存在时延问题。5G的uRLLC场景,需要在1 ms的极短时间内响应,而集中式的CU传输路径长,时延难以达标。
(2) DU的计算量大,且难以分割,不利于引入分布式计算或FPGA硬件加速引擎等机制。DU横跨物理层、MAC层以及RLC层等多个协议层次,功能结构复杂而庞大,处理时延要求高,分割难度大。
(3) CPRI接口流量巨大,对承载网是非常大的负担。类似C-RAN的集中式架构都存在这个问题。特别是在5G eMBB场景下,随着空口带宽和天线数量的增加,CPRI接口流量比4G LTE成倍增加。按照5G标准,空口带宽1 GHz,天线数256情况下,CPRI接口流量将达到12800 Gbps[12]。
从以上分析不难看出,物理层的分割是接入网组件化的重点和难点所在。3GPP各方经过长期的研究和讨论,在TR38.801协议文档列举了物理层分割的Option7.1, Option7.2和Option7.3等多种选项[12]。爱立信、华为、诺基亚等设备厂商在CPRI接口的基础上推出了eCPRI(evolved CPRI)接口规范[13],给出了ID, IID和IU等多种物理层切割选项,由各个厂商在实现eCPRI接口的时候选择。然而,由于物理层的复杂性,无论是3GPP还是eCPRI规范都未能形成最终的标准,各个厂商的实现不尽一致。
同样是从改造CPRI接口的缺点出发,中国移动提出了下一代前传接口(Next Generation Forward Interface, NGFI)方案,其思路是将切分后的传输流量与小区公共流量和天线端口解耦[14,15],中国移动还将NGFI方案与C-RAN架构相结合,提出了基于CU-DU的C-RAN架构[16]。在这个方案中,运营商有两种选择,其一是把DU与RRU放在一起,其二是把DU与CU放在一起。其缺点是,要么消耗CPRI接口流量,要么降低集中式网络的运营优势,两者不能兼得。这种情况在5G中尤为明显,巨大的CPRI接口流量导致DU必须要与RRU部署在一起。而DU计算消耗要比CU高一个数量级,云资源池如果仅能集中CU的计算消耗,那么所占的比例是很小的,C-RAN的集中性优势将被削弱,与集中性优势相捆绑的能耗节省、运维成本降低等好处将大为减少。
文献[17-19]提出了在C-RAN接入网中共享基站的分布式缓存降低传输流量的方法,可以在一定程度上缓减传输压力。但是这类方法的效果取决于缓存的命中率,与实际网络应用场景相关性较大。
与5G接入网组件化架构演进困难重重、裹足不前情况不同的是,5G对核心网进行了全面的重构,彻底改变了过去几代核心网以点到点的信令控制为主、各种业务紧密耦合的设备形态,变成了一种全微服务架构的、完全组件化的系统[20,21],非常值得接入网借鉴。
3 组件化的无线接入网协议处理架构
为了更好地适应软件定义接入网络切片化、虚拟容器化的趋势,合理的组件化架构应该满足以下要求:(1)组件的粒度应该尽量小,符合微服务的特点,便于编排和调度。(2)组件间的消息流量应该尽可能得低,减少拆分引起的额外处理消耗。(3)组件的功能应该具有独立性,与其他组件耦合性小,便于可编程FPGA实现硬件加速并替换,也便于使用分布式处理技术进行负荷分担。
图1是本文的组件化接入网络架构。该架构由CCU, CU, RU, DU和AAU等5种组件组成,其中CCU和RU是新增的组件。CCU是集中控制单元,根据功能又可以细分为移动管理CCU、负载管理CCU、干扰协调CCU、切片管理CCU等。RU是射频处理单元,负责物理层底层的处理。CU和DU依然保留,但是功能有一些调整。CU和DU还可以分裂为多个,以支持接入网切片。图1中物理小区的CU和DU都分裂成了3个运行在不同计算节点上的功能组件,对应3个切片,可用于5G的3种应用场景。通过将计算消耗负荷分担到多个计算节点,软件定义基站的整体处理能力将大大提升,更容易满足5G的速率要求。
组件化方案将为接入网的切片化提供更为有效的途径。目前5G网络切片主要是核心网切片[22],接入网切片不具备差异处理能力和完善的隔离机制[23,24],各个设备厂商一般通过给予不同业务的DRB不同调度优先级的方法来实现接入网切片功能,这是3G和4G早就有的业务QoS技术,与完全隔离、高度差异化的网络切片还有差距。组件化的切片将提供更好的隔离性,并且更容易实现不同业务切片的差异性。
3.1 CU与DU切分方案分析
从3GPP发布的TR38.801文档可以看到,3GPP提出了Option1到Option8共8种CU和DU拆分选项,最后选择了Option2作为5G标准[12]。按照这个方案,CU与DU在PDCP层与RLC层之间进行分割。如图2所示,CU包括RRC和PDCP的功能,DU包括RLC,MAC以及PHY的功能。
3GPP将RLC协议实体放在DU中主要考虑的是时延因素。因为在3GPP 5G的网络架构中,CU是一个集中式节点,对上通过NG接口与核心网(NGC)相连接,对下控制和协调多个小区。如果将RLC放在CU,那么对于低时延业务,CU与DU之间的传输时间就会影响时延目标的达成。
然而,采用Option2选项之后,RLC协议实体划入DU,使得DU的实现过于复杂。按照传统的做法,物理层一般会采用FPGA进行加速处理,然而RLC协议的加入,极大地增加了工程实现难度。
如前文所述,在本文的方案中,负载管理、切换管理、干扰协调等控制和管理功能由专门的CCU组件负责,这样,CU不再必须是集中节点,可以与单个DU共点部署,时延就不再是问题。因此,本文的方案将CU与DU的切分点从Option2下移到Option4,也就是说将RLC协议层从DU移到CU,这样DU的实现更为简洁,更容易用可编程FPGA器件实现并进行组件化替换。此外,RLC协议的AM和UM模式有很好的消息包顺序保证机制,可以解决CU和DU之间数据包的乱序问题。从消息流量来说,选项Option4与Option2差别不大,仅增加了RLC协议帧头的开销。
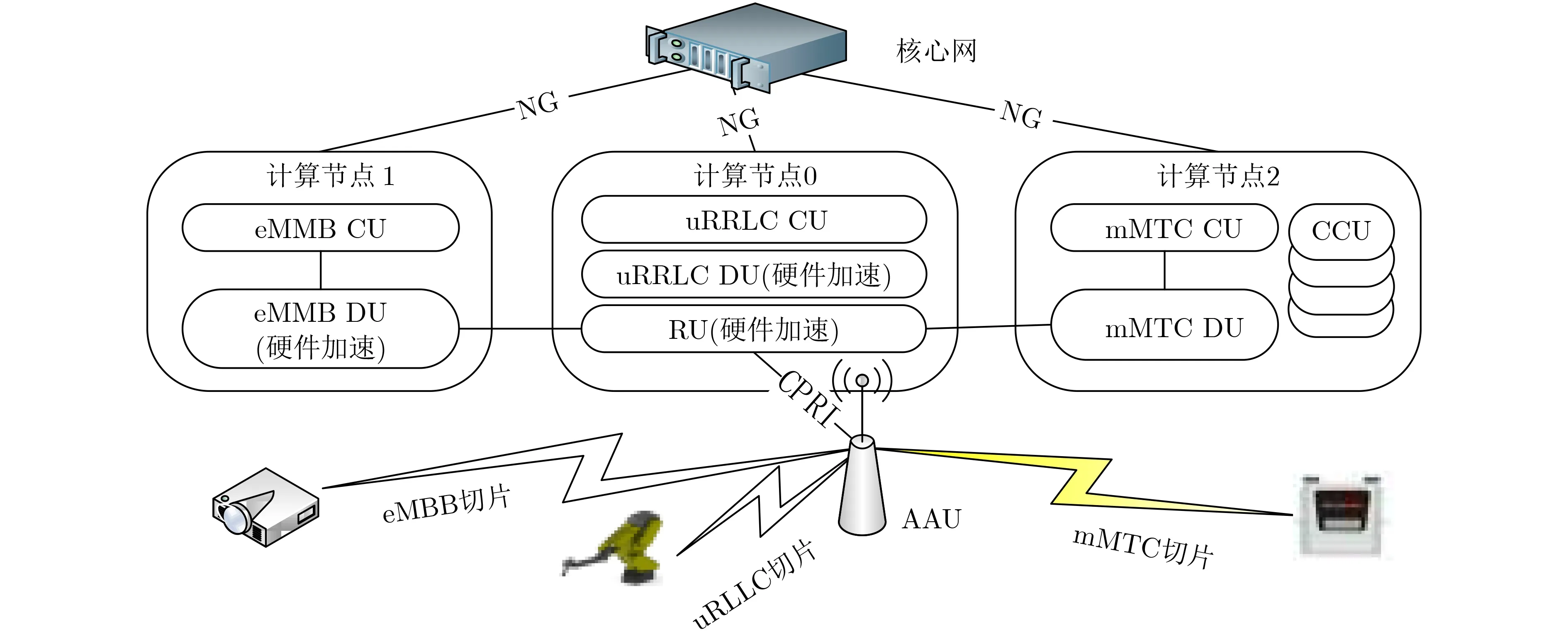
图1 组件化、可切片的分布式软基站架构
3.2 DU与RU切分方案分析
DU与RU的切分在物理层中进行,是组件化的重点和难点所在。3GPP在TR38.801文档中讨论了物理层中间拆分的可选方案Option7。对于上行业务的物理层切分,3GPP在TR38.801文档的Option7方案中给出了Option7.1和Option7.2两个子选项。本文另外给出了Option7.1a和Option7.3选项,作为对比分析方案进行比选。对于下行流程的切分,Option7共给出了3个子选项:Option7.1,Option7.2和Option7.3。具体切分点的位置如图3所示。
决定RU和DU拆分方案的重要因素是RU和DU之间的交互消息流量和时延。拆分点越低,流量越大,时延要求越高。表1为以单天线、正常循环前缀的LTE FDD为例所做的各拆分方案流量分析。
表1中,除了Option8选项为RU与RRU的边界,不作考虑之外,其他都是RU和DU切分的可选方案。
(1) RU与DU下行切分选项Option7.1, Option7.2和Option7.3的比较。
Option7.1选项位于映射模块与iFFT模块之间,传输的是去除循环前缀的频域数据。
Option7.2位于预编码与层映射之间,对于下行来说传输的为各信道调制、预编码之后的数据,应用层满负荷情况下流量比Option7.1略小,主要是因为下行参考信号、下行同步信号、PCFICH、PHICH、PBCH等不包括Option7.2在内,这些是在信道映射阶段产生的。Option7.2接口流量的计算如式(1)
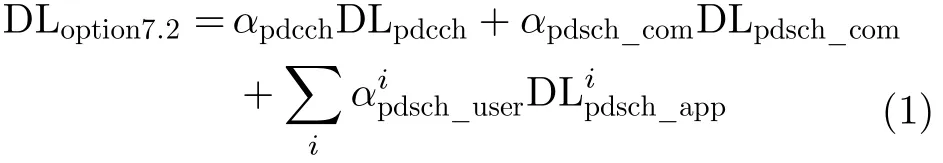
其中,第1项为PDCCH信道的流量,第2项为PDSCH信道公共信息的流量,第3项为PDSCH信道用户流量。其中, αpdcch, αpdsch_com和αpdsch_user,i分别为各项对应的调制系数; D Lpdcch, DLpdsch_com和D分别为各项对应的调制前流量。D为用户的调制前流量,它和用户应用层净流量关系如式(2)

图2 CU和DU拆分选项

图3 DU和RU拆分选项
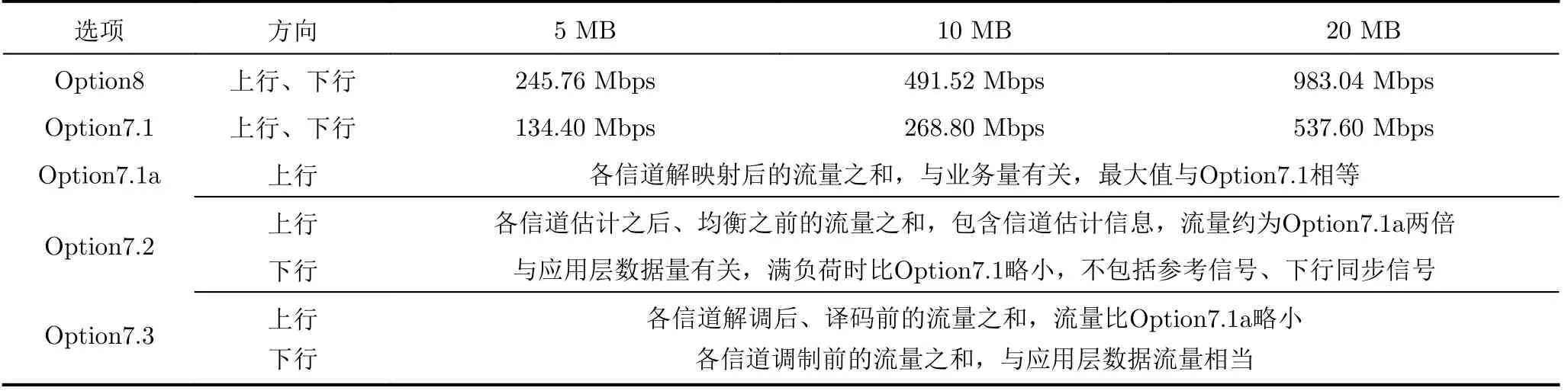
表1 拆分方案流量分析,以LTE单天线、正常循环前缀为例
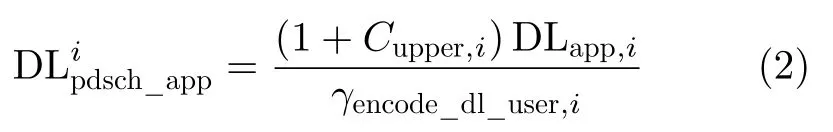
其中, γencode_dl_user,i为用户i的信道编码码率,在LTE中是指Turbo编码的码率,在5G中是指LDPC编码的码率; DLapp,i为用户i 的应用层流量;Cupper,i为用户上层协议的开销。调制系数是指调制后与调制前的位宽比。
Option7.3位于下行编码、扰码与调制之间,相当于eCPRI规范的ID选项,其流量为编码、扰码模块处理后的比特数据,其计算公式为

对比式(1)和式(3)可知,Option7.3接口的流量比Option7.2明显下降,是较佳的切分方案。
对于多个DU按照载频进行切分的多切片场景,Option7.3方案也是可行的。此时,RU同时接收多个DU切片的数据,将各切片的PDSCH信道数据调制、加扰后映射到PDSCH信道对应的载频,将各切片的DCI数据调制并综合后映射到PDCCH信道对应的载频。
(2) RU与DU上行切分选项Option7.1a, Option7.2和Option7.3的比较。
Option7.1a选项位于解映射与信道估计之间,相当于eCPRI规范的IU选项,是解映射模块处理完之后传递给信道估计模块的流量。在满负荷情况下,Option7.1a选项的流量与选项Option7.1相等。在没有满负荷情况下,计算流量的方法如式(4)
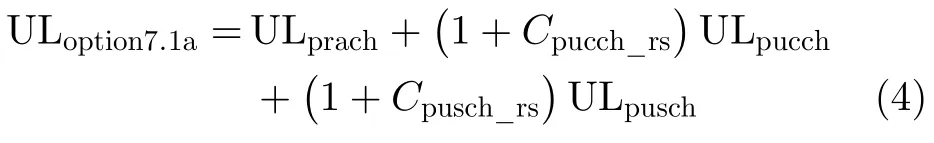
其中,第1项U Lprach为PRACH信道流量;第2项为PUCCH信道流量,Cpucch_rs为 参考信号开销,ULpucch为加参考信号前的流量;最后一项为PUSCH信道流量,其中 Cpusch_rs为参考信号开销,U Lpusch为加参考信号前的流量,该流量可根据用户应用层的流量按式(5)计算

其中, ULapp,i为用户i应用层上行消息的净流量,αpusch_user,i为 用户i信道调制的调制比,γencode_ul_user,i为用户i上行信道编码的码率,Culsch,i为用户i ULSCH传输信道的开销,Cupper,i为i用户上层协议的开销。
Option7.2选项位于信道估计与均衡之间,是信道估计模块处理完之后传递给信道均衡模块的流量。信道估计会对PUSCH信道中参考信号进行估计,并根据插值算法为每一个载频产生一个信道估计值,作为信道均衡模块的输入信息。此时需要将每一个载频的信道估计值连同未作均衡的数据一起从RU发送到DU,流量需要增加近1倍,其流量计算公式为

Option7.3选项位于调制与译码之间,是调制模块处理完之后传递给译码模块的流量。LTE的Turbo译码一般采用最大后验概率(MAximum Posteriori, MAP)算法[25],或对其简化的Max-Log-Map算法,都是软判决译码算法,对软信息宽度有要求,软信息宽度越大,译码效果越好。为此,需要将调制之后的信息完整地送入Turbo译码器,由此可知Option7.3选项上行流量的计算公式为
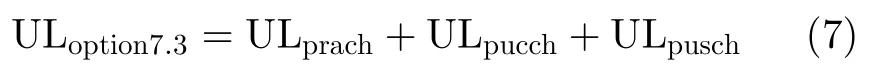
比较式(4)和式(7)可知,Option7.3选项的流量相当于Option7.1a的流量除去上行参考信号开销,流量降低并不是很明显。5G数据信道采用LDPC编码,常用的译码算法是最小和算法[26],也是一种软判决译码算法,面临的问题与LTE是一样的。
把RU-DU切分点放在Option7.1a的一个重要好处是RU在这个点可以很容易地实施切片数据分离,RU在信道解映射的同时顺便把上行数据按载频分配给各个切片对应的DU。另外,Option7.1a把处理开销非常大的译码和均衡模块从RU分解出去,对分布式软基站整体处理速率的提升将较为有利。
综上,本文选择Option7.1a作为DU和RU上行的拆分方案,选用Option7.3作为下行的拆分方案。
4 试验原型实现与性能测试
4.1 组件化无线接入网原型设计方案
为了验证组件化的无线接入网络的可行性,本文开发了组件化的原型系统,并重点对组件化之后CU, DU, RU等组件的处理开销和组件间流量进行了测试。组件化的基站原型以LTE软件定义基站为基础,将其在功能上拆分为RU, DU和CU等3个组件进行实现。图4为本文的原型基站模块图。
从图4可见,RU负责物理层底层处理,上行包括时域到频域的变换、解映射等功能模块,下行包括下行信道调制、信道映射和OFDM时域信号生成等功能模块。DU负责物理层高层和MAC层协议处理,上行包括信道估计、信道均衡、解调、解扰、译码和MAC上行处理等功能模块,下行包括MAC调度、MAC下行处理、PDSCH信道编码、DCI调度信息生成、PHICH信息生成等功能模块。CU负责高层协议处理,包括RLC, PDCP和RRC等协议处理模块。
4.2 组件化试验原型性能测试
本实验所用的测试机器是Z230工作站,处理器为至强E3 1226v3型号的4核CPU,内存容量为32 GB。终端与核心网同样采用软件定义模块进行模拟,操作系统是Ubuntu14.04.03 LTS版本,并加载low-latency 3.19低时延内核。本文的试验原型使用的是LTE FDD模式,空口带宽为5 MHz。软基站上行支持16QAM,最大速率5 Mbps,下行支持64QAM,最大速率14 Mbps。
4.2.1 组件间流量测试
图5是上、下行数传时CU, DU, RU 3大组件间的数据流量变化情况。图5(a)为上行数传1 Mbps到5 Mbps时的组件间流量,图5(b)为下行数传从1 Mbps到14 Mbps时的组件间流量。
从图5(a)可知,在上行数传时,随着上行速率从1 Mbps上升到5 Mbps, DU~CU的流量从1.2 Mbps上升到5.9 Mbps,这个数值相当于在应用层流量的基础上增加约20%的各协议层开销。随着上行传输速率的加大,RU~DU的流量逐步增加,在上行速率为5 Mbps时,RU~DU的流量为114 Mbps。而传统 CPRI接口下行流量是固定的,5 MHz空口带宽情况下,不管有没有上行业务,流量都是固定的245.76 Mbps。这表明,通过组件化方案可以动态地控制上行流量,在没有上行业务或上行业务量较小时流量比较少。
从图5(b)可见,在下行数传时,CU~DU,DU~RU的流量与应用层的数传流量大致相当,与前面理论计算相吻合。其中,CU~DU由于处在更高的协议层次,流量比DU~RU稍小。在下行14 Mbps时,DU~RU的流量只有20.1 Mbps,相对于传统的CPRI接口流量245.76 Mbps,压缩了10倍以上。
从图5(a)和图5(b)都可以看到,RU~DU的流量即使在上行数传速率为0时,也保持在14.7 MB,这是PUCCH信道、PRACH信道产生的与上行速率大小无关的固定流量,可以由式(4)右侧的前两项确定。

图4 组件化的原型基站模块图

图5 CU, DU和RU组件间流量测试结果
4.2.2 组件化与非组件化对比测试
表2为组件化与非组件化两种系统的对比测试数据。从测试结果可以看到,时延相关的指标两种方案的差异不是很明显,而内存与CPU开销指标差异较大。组件化方案内存和CPU的开销有一定程度上升,这是由于组件间消息收发的处理需要额外内存和CPU处理资源。

表2 组件化与非组件化对比测试结果
4.2.3 基于组件化的C-RAN架构与基于CU-DU的C-RAN架构的比较
接入网组件化之后,具有更为灵活多样的组网实施方式,将其与C-RAN架构相结合便是可行的实施方案之一,这将为运营商提高更为丰富的组网选择。表3是当下行速率为10 Mbps时组件化的C-RAN方案与传统CU-DU架构的C-RAN方案的比较,相关数据基于前面测试数据推算而得。从表3可以看到,在非理想前传条件时,采用DU部署在中心资源池的组件化方案相对于传统CU-DU方案优势明显,此时站址传输流量仅是后者的1.35倍,而中心资源池的计算集中度却是后者的35.60倍。这表明组件化方案在不显著增加传输开销的情况下依然能够保持C-RAN架构的集中化优势,这将为C-RAN架构在5G应用场景中继续发挥运维简化、能耗降低等优势创造条件。

表3 组件化C-RAN方案与CU-DU C-RAN方案比较(以10 Mbps下行传输为例)
5 结束语
本文针对软件定义方法实现5G接入网的问题,提出了一种新的组件化方案,该方案是一种由CCU, CU, DU, RU和AAU等组件构成的分布式软基站架构。本文通过对各种物理层切分选项的组件间流量进行理论分析之后确定了切分方案,并按此方案实现了试验原型。软件定义无线接入网的组件化架构既有利于通过分布式计算技术或者硬件组件加速技术克服软件定义接入网的计算能力瓶颈,又有利于降低CPRI接口流量,实现基于组件的RAN切片。从前面的比较也能看到,组件化方案与CRAN架构相结合还能充分发挥C-RAN架构集中度高的优势,在集中度与传输开销之间获取平衡,降低接入网的运维成本和能耗。
