基于深度学习的驾驶员安全带检测研究与实现
2021-04-25陈鸿彬程楷泳林梓泓连晓茵刘培杰陈键宇
陈鸿彬,程楷泳,林梓泓,连晓茵,刘培杰,陈键宇
(华南农业大学数学与信息学院,广州510642)
1 研究背景
1.1 相关背景
近年来,随着国民生产总值的提高,人们变得越来越富裕,大多数人会选择购买机动车来提高自己的出行效率。据统计[1],机动车的数量呈逐年上升趋势,截止到2019 年上半年全国机动车保有量已达3.4 亿,如图1 所示。虽然机动车在一定程度上方便了我们的出行,但是随之而来的道路拥堵问题也变得不容忽视,因此,越来越多的市民选择乘坐公共交通工具出行。加之,人们环保意识不断提高,政府大力提倡低碳生活,公交车出行已经成了一种大众认同的出行方式。与此同时,公交车司机肩负着全车乘客的安危,如何规范司机的行为、降低事故发生率就显得尤为重要。
当两车相撞时,驾驶员不系安全带的死亡率为75%,而系安全带的生还率为95%。作为车内最有效的保护措施之一,佩戴安全带驾驶一直是我国法律明文规定的驾驶行为,但目前对驾驶员是否佩戴安全带的问题仍以人工筛查为主。但是传统的检测方法存在效率低下、准确率不高、易受人为因素干扰、需要耗费大量的人力物力等问题,实现未系安全带检测的智能化处理逐渐成为研究的热点。

图1 2014到2019年上半年全国机动车保有量
深度学习是近年来人工智能领域取得的重大突破,它在语音识别、计算机视觉、图像与视频分析、多媒体、教育事业[2]等诸多领域的应用取得了巨大成功。与传统的图像处理相比,深度学习对数据集的表达更高效和精确,提取的抽下行特征鲁棒性更强,泛化能力更好。
因此,把深度学习运用到驾驶员是否佩戴安全带的检测也逐渐称为研究的热点。
1.2 国内外研究现状
目前,国内外主要的安全带检测方法有以下几种:
(1)通过安装传感器的方法对安全带佩戴进行检测识别,如在卡座中安装传感器进行检测[3],系统判定只有当安全带卡扣插入安全带卡座并且锁定的情况才是安全带正常佩戴的情况。但是驾驶员经常有假佩戴的行为出现[4],例如先将安全带卡扣扣好,然后再坐在座椅上。
(2)通过在坐垫和靠背上安装压力传感器来进行辅助检测,但这种方法不能直接检测出驾驶员是否佩戴安全带,准确率不高[5]。
(3)基于灰度积分投影的方法对安全带进行检测识别[6]。通过道路监控的方式采集的驾驶员图像,对安全带佩戴进行检测。但是该方法需要具有反光性能的安全带,不具有普遍适用性。
(4)以Guo 等人为代表提出的基于图像处理的传统方法[7],该方法将边缘检测和霍夫直线变化相结合,检测安全带的两条长直线边缘,从而实现对安全带的检测。但是该方法受缺乏鲁棒性,而且对图像的质量要求较高,因此较难推广。
(5)以Chen 等人为代表提出的基于AdaBoost 的安全带检测系统[8],该方法通过Haar 特征提取和模型训练,用加权级联的方法把各种弱分类器变成一个强分类器[9],最后经过高斯混合模型的后处理得到安全带的精确检测结果。虽然该方法与传统方法相比,检测精度和鲁棒性有了一定提升,但是其检测精度还达不到可推广应用的地步,对图像质量的要求仍较高,安全带检测的误报也较多。
1.3 主要研究内容
本文旨在实现对公交车司机是否系安全带的智能检测,即通过对车内视频资料的处理和分析,定位安全带的位置,通过图像处理识别出公交车司机是否系安全带,对不按规定佩戴安全带的公交车司机给予一定的惩罚,从而规范公交车司机行为,降低事故发生率。
2 算法基础
2.1 算法分析
传统机器学习存在以下几个弊端:
(1)训练机器模型需要有大量的数据,这些数据往往需要人工标注[10],耗时耗力。
(2)庞大的训练数据难以获取。
(3)数据分布差异
在大多数情况下,面对某一领域的某一特定问题,都不可能找到足够充分的训练数据。但是,得益于一种技术的帮助,从其他数据源训练得到的模型,经过一定的修改和完善,就可以在类似的领域得到复用,这一点大大缓解了数据源不足引起的问题,而这一关键技术就是迁移学习(Transfer Learning)[11]。
迁移学习是将一个领域的已经成熟的知识应用到其他的场景中。用神经网络的角度来表述,就是一层层网络中每个节点的权重从一个训练好的网络迁移到一个全新的网络里,而不是从头开始,为每特定的任务训练一个神经网络。假设现有一个可以高精确度分辨猫和狗的深度神经网络,而想新训练一个能够分别不同品种的狗的图片模型,你需要做的不是从头训练那些用来分辨直线,锐角的神经网络的前几层,而是利用训练好的网络,提取初级特征,之后只训练最后几层神经元,让其可以分辨狗的品种。节省资源是迁移学习最大意义之一,举图像识别中最常见的例子,训练一个神经网络来识别不同的品种的猫,你若是从头开始训练,你需要百万级的带标注数据,海量的显卡资源。而若是使用迁移学习,你可以使用Google 发布的Incep⁃tion 这样成熟的物品分类的网络,只训练最后的Soft⁃max 层,你只需要几千张图片,使用普通的CPU 就能完成,而且模型的准确性不差。对于数据集本身很小(几千张图片)的情况,从头开始训练具有几千万参数的大型神经网络是不现实的,因为越大的模型对数据量的要求越大,过拟合无法避免。这时候如果还想用上大型神经网络的超强特征提取能力,只能靠迁移学习。
以上所提及的迁移学习模型在这里采用的是GoogLeNet(Inception V3),Inception V3 将7×7 分解成两个一维的卷积,既可以加速计算,又可以将1 个卷积拆成2 个卷积,使得网络深度进一步增加,增加了网络的非线性(每增加一层都要进行ReLU)。我们在使用这个模型的时候不修改bottleneck 层之前的参数,只需要训练最后一层全连接层就可以了。如图2 和图3所示。

图2

图3
具体思路:
(1)从预训练模型以字符串形式读取数据,并解析其中的瓶颈层张量,jepg 格式图像数据张量,预训练图像大小张量[13],然后使用TensorFlow.import_graph_def导入初始图中。
(2)获取训练图像数据,根据读取设置好的文件夹里的图像数据,并以文件夹名称作为该类的名称。
(3)确保训练集、测试集和验证集数据都被缓存。因为我们会多次读取到同一幅图像,我们在预处理过程中为每个图像计算一次瓶颈层值并保存下来,然后在训练期间重复读取这些缓存值,这样子操作可以大大加快速度。
(4)为训练添加新的Softmax 和全连接层。重新训练顶层来识别我们的新类,在这里我们实现的根据是TensorFlow 官方发布的一个操作。
(5)插入用于我们评估结果准确性的标签。
(6)将所有summary 全部保存到磁盘,以便训练完成以后在TensorBoard 显示。
(7)读取命令行指定的一个文件来保存图。
(8)将所有权重设置为初始默认值。
(9)至此构造完了一个图,创建一个Session 对象并启动它。
(10)读取手动设置的迭代次数,进行迭代。
在每次迭代中,获取一批输入瓶颈值,这些值可以通过应用失真每次重新计算,也可以从存储在磁盘上的缓存中计算。
①获取训练图像失真后的瓶颈值,为每个图像重新计算完整的模型。相反,为所要的类别找到随机的图像,运行它们通过变形图,然后运行全图得到每个瓶颈的结果。
②检索缓存映像的瓶颈值。如果没有任何失真图像被应用,可以直接从磁盘检索缓存的瓶颈值,然后选择一个随机集合来自指定类别的图像。
③将训练过程数据保存在filewriter 指定的文件中。
④将加权的训练好的图和标签作为一个常量。
(11)迭代结束训练也完成了。
2.2 实验及系统架构
本模型选用百度安全带分类图片库的图片数据,采用Google 提供的Inception-v3 模型[14]作为预训练模型。本迁移学习方法的具体实现是,不修改bottleneck层之前的参数,替换掉了Inception-v3 模型的最后一层全连接层,以达到识别我们目标分类的目的。操作步骤为:
(1)设置我们写入TensorBoard 摘要的目录。
(2)设置预训练图像。
(3)查看文件夹结构,创建所有图像的列表。
(4)验证我们是否需要应用扭曲操作。
(5)定义新的全连接层和Softmax 层来训练模型以解决新的图片分类问题。
(6)创建评价模型性能指标的计算图并用Tensor⁃Board 可视化平均精度。
(7)按照命令行的要求运行多个周期的训练,每次随机得到一批训练数据进行训练,每迭代几次在验证集上做一次测试以评估模型性能并保存在验证集上最佳的测试精度及相应的模型,同时保存TensorBoard 日志信息。
(8)完成了所有的训练,在一些我们从未用过的新的图像上,运行一个最后的测试评估这样子,我们就训练出一个应用于安全带识别的训练模型。
3 系统实现
3.1 系统架构
在上述算法实现的基础之上,我们完成了安全带识别系统的搭建,采用C/S 架构实现[15],主要分为两个模块:客户端模块、服务器端模块。如图4 所示。

图4
客户端界面用的是JavaFx 进行编写,后台采用的是Java,与服务器之间通过Socket 进行通信,服务器环境采用的是TensorFlow2.0,数据库采用的是MySQL。
3.2 客户端模块
(1)功能设计
客户端负责将选取的视频进行截帧,然后调用服务器端的训练模型进行识别,识别完成之后对结果进行存储,还可进行识别结果的查询。
(2)具体实现
先从本地上选取视频,将选取的视频按照一定的帧率进行截图,并存进指定本机的指定文件夹内。接下来,客户端与服务器端建立Socket 通信,将文件夹中的照片传递到服务器端并调用训练模型进行识别。最后,客户端接受服务器端识别的每张照片识别概率并与预先设定好的概率进行比较,确定出每张照片是否违规,根据比较结果进行展示,将识别结果进行存储。
3.3 服务器端模块
(1)功能设计
服务器端负责将客户端发送的多张图片进行存储,通过调用训练模型进行识别,将识别结果返回给客户端。主要涉及两个功能:
①接收客户端发送的多张jpg 格式图片,识别出图片名字并临时存储到本地图片文件夹中。
②调用训练模型识别多张图片,并将识别结果与图片对应返回给客户端。
(2)具体实现
使用serverSocket 与客户端进行Socket 通信[16],并采用多线程处理客户端的多个请求消息,达到并发处理多个客户端请求的目的。单次通信操作中,使用cli⁃ent.recv()方法接收客户端发来的二进制数据流,首先读取图片张数,读取完图片张数后依次读取每一张图片数据,将其临时存储在图片文件夹中,调用训练模型进行识别,并将结果通过socket 通道以二进制数据流的格式返回给客户端,这样子就完成了单张图片的识别操作。
以下是具体实现过程:
①建立socket 连接过程
首先使用socket.socket()方法建立服务器端sock⁃et,使用bind()绑定目标端口,之后使用listen()方法开始监听,等待客户端的建立socket 请求。当监听到客户端发送来的socket 请求,使用_thread.start_new_thread()方法调用多线程处理客户端消息,主线程继续监听目标端口,因此可以同时处理多个客户端信息。
②接收图片数据流过程
首先,使用struct.calcsize()方法接收图片张数的位数信息,之后用client.recv()方法接收图片张数信息,之后根据图片张数信息使用循环接收图片数据流,存放到服务器端图片文件夹中。具体实现思路如下:
先从客户端socket 中获取获取一个数字长度的字符代表图片张数的位数N,接收成功后,根据图片张数的位数获取N 个字符X,代表图片张数,之后进入X 个循环,每个循环中再有如下的步骤:首先获取一个字符长度的文件名位数Y,再获取Y 个字符的文件名;获取完文件名之后开始获取文件大小位数Z,根据Z 再获取文件大小,此时一个文件的接收完毕。每次接收完图片后清空输入缓冲区。
③调用训练模型进行识别并返回识别结果过程
每次成功接收一张图片数据流并存放到图片文件夹中之后,调用训练模型进行识别,得到识别结果,并使用client.sendall()方法将识别结果返回。
4 效果展示
安全带识别系统的运行如图5 所示。

图5
整个系统客户端界面简洁,功能结构清晰,如图6所示,客户识别即可进行视频的选择并开始识别,此过程需要一定时间,如图7 所示,系统识别完成后则会显示出结果,如图8。
5 结语
总体来说,本系统软件能够基本实现对公交车司机是否系安全带的智能检测,操作简单,易用性强,可移植性强。由于时间仓促,一些技术和设备所限,该系统存在一些不足之处,有待于进一步改进和完善。具体说来有:界面的美观性和检测的效率还需要加强,本系统的训练集还是比较不足,后续会加强训练本系统的识别样本,进一步增强识别准确性。系统设计在不违反系统整体性的基础上,可根据用户的需求进行二次开发,不断完善系统功能,便于系统的不断升级。希望本系统能够帮助规范公交车司机行为,降低事故发生率。

图6

图7
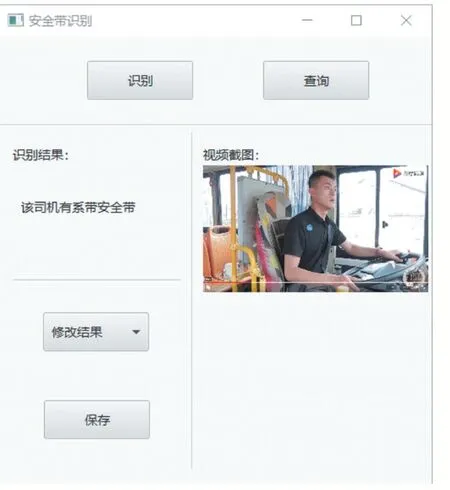
图8
