新冠舆情、民众情感与城市公共交通
2021-04-23赵彦勇周家静赵洪宸
赵彦勇,周家静,厉 海,赵洪宸
(南京审计大学 统计与数学学院,江苏 南京211815)
一、引言
2019 年12 月底,武汉市疾控中心经过检测发现了一种原因不明的肺炎病例。2020 年1 月11 日,我国出现首个新冠肺炎患者死亡病例。2 月3 日,武汉市正式实施《传染病防治法》规定的“甲类传染病疫区封锁”措施,各类公共交通停止运营,此时全国累计确诊病例已超过2 万人。2 月16 日,全国累计确诊病例超过7 万人。2 月20 日,武汉市新增治愈病例首次大于新增确诊病例。4 月8 日,武汉正式解除离汉通道管控,逐步恢复各类交通的正常运行。6月11 日,北京市新增1 例本土病例,结束了连续五十多天无新增病例的现状。6 月14 日,北京新增本土确诊病例36 例。7 月8 日,北京单日治愈人数创新高。7 月中下旬以来,辽宁省大连市与新疆自治区乌鲁木齐市相继发生了聚集性疫情。截至7 月底,全国确诊病例714 例,累计治愈出院病例78 989 例,累计报告确诊病例84 337 例。新冠肺炎发生以来,疫情变动成为了每个中国人关心的话题,引起了社会各阶层民众的关注。随着网络的普及,网络交流软件成为人们了解新冠肺炎疫情、自由发表言论的平台,“疫情”“确诊”“防控”等话题屡屡被推上关注的制高点。2020 年2 月份以来,为了打赢这场“战疫”,党中央和国务院、省市各级政府均要求企业延迟复工,并采取了严格的交通管制措施。各省市不仅严格控制外来车辆的进入,而且城市内部也停止了大部分公共交通的运营。城市轨道交通作为便利、快速、安全的交通工具,具有覆盖面广、站点多、客流密集的特点,更容易引起疫情的传播。为此,10 个城市采取了不同程度的交通管控措施,上海、重庆、南京等关闭部分站点。交通运输部门采取班次停运或车次调整的措施,来控制因公共交通出行而引发的病毒交叉感染。
民众对新冠肺炎疫情的高热情和长时间讨论,对于研究疫情舆情有重要的意义。通过对大众情感进行分时段研究,能够很好地了解社会心理变化,预测未来的民众情绪,对各级政府部署防控工作具有重要的现实意义。国内已有许多关于舆情数据的分析,例如,陈兴蜀等(2020)[1]通过抓取微博评论,研究了与“新冠肺炎数据”话题相关的舆情时空演化。孙宇婷等(2020)[2]利用网络指数,运用空间计量、可视化与回归分析等方法研究得出,东、西部地区民众对疫情的关注度差异较大,人口流动、社会经济等因素在不同程度上影响着民众对疫情的关注度。此外,特定时间出现的有关疫情的新闻也会引起公众情绪的波动,存在“情绪脉冲效应”(张放、甘浩辰,2020)[3]。本次突发性事件引起了城市交通运输的停滞和居民出行的不便,但也推动了运输部门远程办公的广泛应用,并增加了小汽车的限购配额(王宇、许定源、石琳,2020)[4]。种鹏云和尹惠(2020)[5]通过建立系统动力学模型、张毅等(2020)[6]通过构建病毒易感度评估模型研究了交通运输对疫情传播的反馈作用。冯旭杰等(2020)[7]分别对运输服务、企业经营和应急处置进行了定性分析,提出恢复城市轨道交通面临的挑战。其中,周艾燕等(2020)[8]指出在常态化防控下,如何提升交通运输综合执法能力就是一项挑战。
通过有关新冠肺炎疫情的文献梳理可知,大多数学者在对舆情进行时空分析时很少结合当下的热点话题,并且在对交通出行的分析中倾向于使用文献调查的研究方法。本文综合以往研究,在舆情分析中结合微博热点时事,关注现实话题。此外,关于新冠肺炎疫情对交通出行影响的大多研究缺少定量分析,而本文不仅直观分析了各市研究时段的出行变化情况,而且将新冠肺炎疫情期间网络舆情与交通出行二者相结合,建立了计量模型进行研究。
本文主要使用Python 软件抓取了2020 年1 月1 日至7 月31 日微博新冠肺炎话题下的用户评论数据和城市轨道交通日客流量数据进行研究。首先,我们对爬取的文本进行jieba 分词。接着,采用SnowNLP 库进行情感分析,得出10 个城市的日平均情感得分图,再使用数据可视化工具pyecharts,将各城市的微博评论情感得分图与地铁日客流量分布图进行比对。在舆情演化分析和交通出行特征分析的基础上,建立面板回归模型,探讨网络舆情对交通出行的影响。网络舆情分析得出,各城市居民在研究时段内对新冠肺炎疫情基本持积极态度,2020 年2 月民众情绪最低迷,与“新冠肺炎”“确诊病例”等相关的搜索词获得了较高的关注度。交通出行分析得出,2020 年1 月23 日后各城市日客流量均出现剧降,此后上海地铁运营在各城市中恢复速度最快。城市日客流量的增速对民众的平均情感得分具有显著的积极作用,日客流量的上涨侧面反映出交通出行的自由灵活,长期被“封闭”的情绪得以释放,民众情感得分显著提高。
二、数据挖掘与分析
(一)理论研究
网络爬虫,是一个按照事先给定的规则,自动地、循环地抓取网页数据信息的脚本或者程序。由于它们能根据限制条件自动采集所访问页面的信息,以供搜索引擎做进一步的处理,从而让用户能更方便快捷地获得需要的信息,因此目前应用比较广泛。许多网站的运维人员常常用它来更新网站内容,也有一些数据分析人员或者专家学者使用网络爬虫来进行数据的分析和挖掘。
网络爬虫整个工作由控制器、解析器和资源库配合完成。控制器控制着整个爬取活动的进行,它根据从URL 栈中获取的网页链接,给各爬虫线程分配工作任务。解析器主要用来下载网页,并对下载后的页面做进一步处理,承担了爬虫工作的主要部分。资源库主要用来存取网络爬虫爬取到的数据信息,当数据量比较大时一般用数据库来存储,并提供生成索引的目标源。
网络爬虫爬取的网页链接集合一般由两部分组成:一是由人工准备的、比较重要的目标网站链接集;二是从第一部分的链接中获取的子链接,因为一个网站中往往包含许多链接。但是,在对这部分链接进行筛选时需要非常严格,互联网络庞大复杂,一旦出错将导致整个爬虫程序失败。有了初始的URL 集后,网络爬虫便可以开始数据的抓取。前面提到网页中一般含有其他的链接,从现有的网页便可以获取一些新的链接,那么可以把这种网页之间的结构关系看成是一个森林,每个种子链接URL 就是森林中相应树的根节点。这样,爬虫系统就可以使用各种搜索算法遍历整个网页,通常爬虫工作者会使用广度优先搜索算法来收集网页信息。首先网络爬虫系统会把种子URL 存放在下载队列中,然后依次从队列首部取出一个URL 并用解析器下载该链接的网页。这时候还会获得一些新的URL,将这些新获取的URL 加入到下载队列中。接着再从下载队列首部取出一个URL,进行网页的下载和信息收集,之后取URL 再解析,如此反复进行,直到遍历了下载队列中所有链接或者满足某种限制条件后就结束整个爬虫过程。
(二)数据采集
微博作为网民分享简短实时信息的重要网络平台,数据开放程度较高。基于此,本文决定爬取微博新冠疫情话题下的用户评论,并对其进行情感分析。目前,微博一共有三个站点,分别是“https://weibo.cn”“https://m.weibo.com”“https://weibo.com”,三个网站的爬取难度由易到难。由于爬取新冠疫情话题下的用户评论需要用到微博中的高级搜索功能,而“https://m.weibo.com”网站并不包含该功能,所以予以排除。“https://weibo.com”的高级搜索入口为“https://s.weibo.com”,筛选条件包括类型、用户、时间、地区,这里的时间是以小时为单位的。鉴于可得微博的数量,“https://weibo.com”在一天时间内获得的最大微博数量为24 000 条,是“https://weibo.cn”的24 倍。此外,由于本文需要获取不同城市用户的微博评论,因此最终选择对“https://weibo.com”进行爬取。
通过高级搜索功能,以“新冠疫情”为关键词,并按照本文选择的10 个主要城市对搜索结果进行划分,分别得到了10 个城市微博用户对新冠疫情的评论。在爬取过程中,本文对2020 年1 月1 日至7 月31 日(共计213 天)的评论按照热度由高到低,以每一天为一段,共计213 段,进行爬取。每个城市每一天可以爬取评论1 000 条,每个城市共计爬取用户评论213 000 条。
本文使用Python 语言的request 库对页面信息进行获取,要抓取到微博的数据,首先要登陆微博,而微博检测用户是否登陆,就是检查用户这次request 请求携带的cookie。为此,本文通过登陆微博,获取了cookie 并保存,在request 中加入包含微博账号cookie 信息的headers 以实现模拟登陆,即可实现对微博页面的爬取。基于request 库所获取的页面信息,本文通过BeautifulSoup 库和正则表达式相结合的方式,提取了页面中的所有评论,并将每条评论以天为单位依次存储在csv 文件中,经过去重,得到最终的评论信息,部分评论如表1 所示。

表1 抓取微博的部分评论
(三)研究内容与结果分析
1.微博用户综合情感。情感分析是指利用自然语言处理方法和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程。因特网上产生了大量对于人物、事件、产品等的评论信息,从中可以提取到用户的情感态度,包括赞成和否定。对于微博博文的内容,本文采用Python 的SnowNLP 库进行情感分析。SnowNLP 库自带了一些训练好的字典,可以方便地处理中文文本内容。SnowNLP 的分析过程是先读取已分好类的文本,再对文本去停用词和分词,计算每个词出现的频数。然后通过bayes 定理计算正面和负面的先验概率,对要进行判断的文本进行切分,计算每个词的后验概率,最后选择概率较大的类别。由此可以对大量的微博文本进行情感分析,得到10 个城市每天的平均情感得分,再用matplotlib 进行绘制,从而更加清晰地反映民众对于新冠肺炎疫情的态度变化。
使用SnowNLP 分析得到的结果在0~1 之间,如图1 所示。若结果大于0.5,则表明情感偏向正面;若结果小于0.5,则表明情感偏向负面。
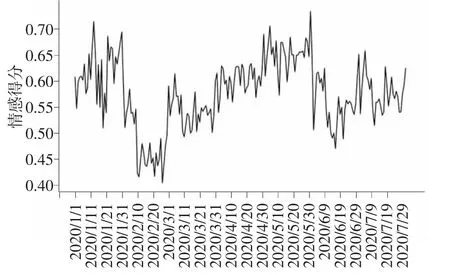
图1 综合平均情感得分折线图
由图1 可知,2020 年1 月1 日至7 月31 日期间,民众对于新冠肺炎疫情整体持正面态度。从得分的走势来看,民众对新冠肺炎疫情的情感态度大致可以分为五个阶段。第一阶段为2020 年1 月1 日至2 月9 日,该时期内民众情绪波动较大,但情感得分都在0.5 以上。1 月1 日“华南海鲜批发市场休市整治”的信息居于微博热议话题中,前两日的情感得分有小幅下降。随后“不明原因肺炎未有发现明确人传人证据”等信息缓和了民众的情绪,情感得分逐步上升。1 月23 日,“武汉封城”登上微博热搜榜首,此举措令民众意识到问题的严重性。之后农历新年到来,“疫情拐点将出现”的信息再一次缓和了民众的情绪。第二阶段为2 月9 日至2 月29 日,该时期内民众情绪略呈现负面,情感得分一直维持在0.5 以下。2 月初每日公布的新增感染病例逼近万人,并且各城市陆续采取交通和外出限制,长期封闭在居所是导致民众产生负面和恐慌情绪最主要的原因。第三阶段为3 月1 日至6 月13 日,该时期内民众情感得分在0.5 以上,波动较小。3 月国内疫情逐渐好转,且部分地区解封的消息让民众情绪趋向正面。然而,5月29 日召开的两会没有确定GDP 增长的量化指标,这可能导致民众对未来经济发展缺乏信心,情感得分因而大幅下跌。第四阶段为6 月13 日至6 月21 日,该时期内民众情绪略偏向负面,情感得分在0.5 周围波动。6 月12 日北京发生的疫情让情感得分下降到0.5 以下,随后在0.5 左右出现波动。随着疫情迅速受到控制,情感得分也逐渐回升。第五阶段为6 月21 日至7 月31 日,该时期内民众情绪波动较大,但情感得分都在0.5 以上。7 月中旬乌鲁木齐发生疫情时,我国居民对疫情已经能够以平常心对待,因而情感得分变化不大。同时可以看出,北京作为首都,发生疫情对全国民众的情绪影响较大,而其他地区发生疫情对全国民众的情绪影响相对较小。总的来说,民众对于新冠肺炎疫情的态度大致经历了五个阶段,情绪状态大体偏向正面,可以推测未来也会持续地趋于正面。
2.各城市微博用户的平均情感得分。本文对2020年1 月1 日至7 月31 日各城市网民的情感值取平均值,得出各城市网民的平均情感得分,具体见表2。
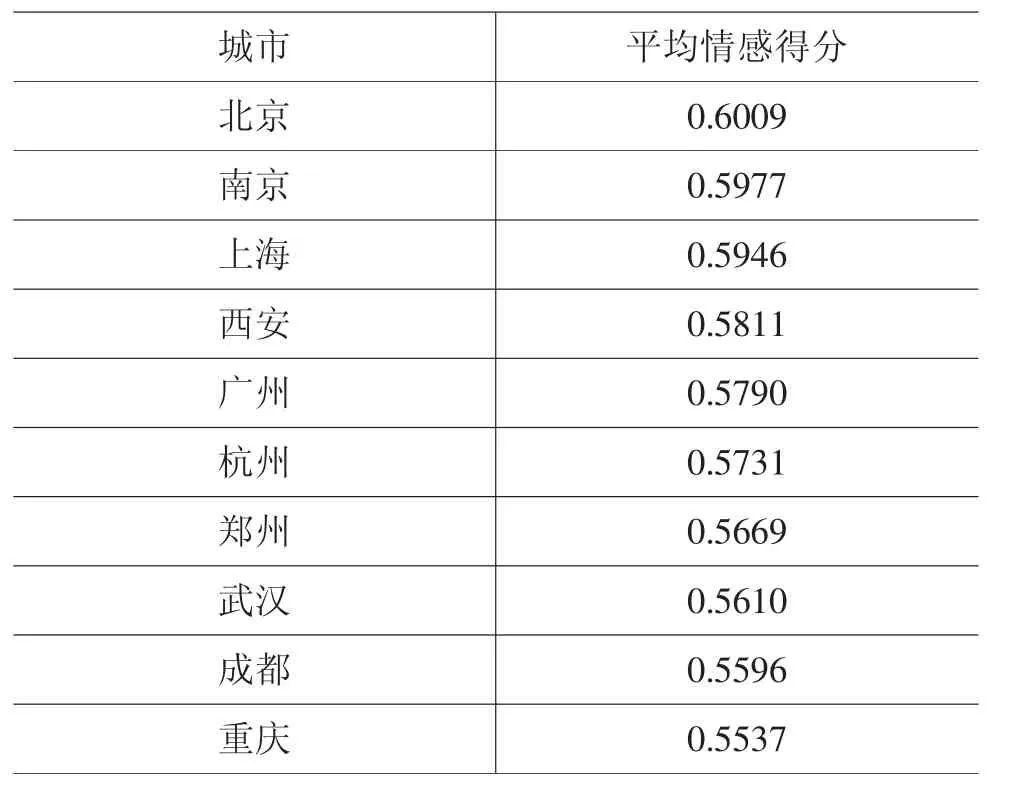
表2 各城市网民的平均情感得分
由表2 可知,武汉、成都、重庆等城市的情感得分均值较低,处于0.548~0.566 之间。可以看出,情感得分较低的城市大多数处于我国的中西部地区,原因可能是这些地区经济发展程度相对较低,民众对外交流机会少,武汉市作为中西部地区的交通枢纽,与这些城市的交通联系更为便捷。
武汉“封城”时间为2020 年1 月23 日,仅用1月1 日至7 月31 日期间的平均情感得分不能够准确地反映出疫情初次爆发时民众的情绪变化。为此,本文以1 月23 日武汉“封城”的时间作为起始日期,2 月10 日全国各地开始启动复工的日期作为结束日期,再次计算了19 天内网民的平均情感得分,相关结果见表3。

表3 武汉“封城”事件下各城市网民的平均情感得分
由表3 可知,在这段时期内,新冠肺炎疫情受到大众的广泛关注,其中武汉作为疫情爆发的城市,受疫情影响最为严重,市民的情感得分最低,为0.541 1。其他城市在该时期内的情感得分均高于全时期内的情感得分,可能是因为,该阶段民众虽然已经意识到疫情的严重性,但此时正处于农历新年,过新年的快乐氛围高于人们对疫情的担忧,此时武汉市以外的其他市民可能仍未意识到此次疫情的威胁性和严重性。
3.微博用户关注话题。为了解疫情期间热度较高的话题,本文将2020 年1 月1 日至7 月31 日微博关于新冠肺炎疫情的评论经过分词后得到词频,将词频位列前十的高频关键词绘制成柱状图进行展示,如图2 所示。
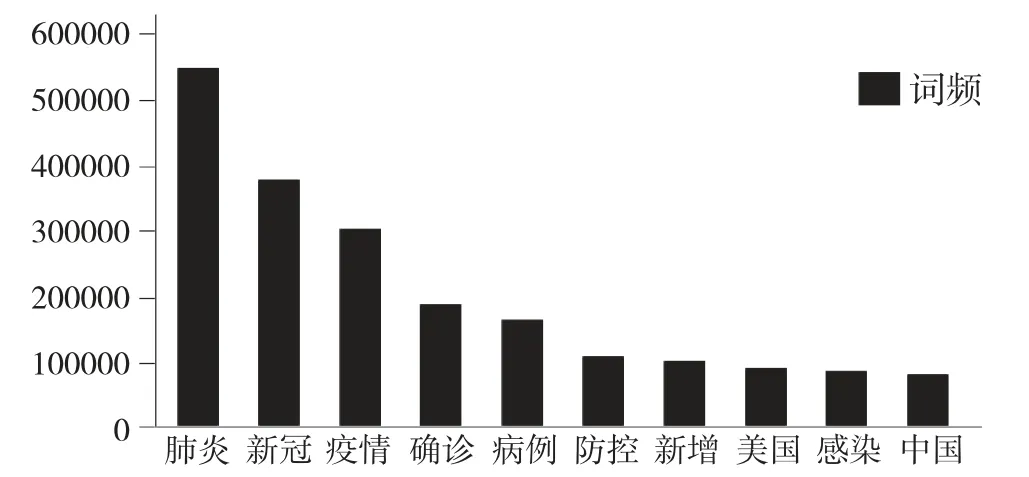
图2 微博评论高频关键词
如图2 所示,出现频数最高的是“肺炎”一词,此外出现频数较高的还有“新冠”“疫情”“病例”等词汇,这些词汇直接反映了民众对于此次疫情发展变化的高度关注。同时,关注度排名第六位的词为“防控”,反映了民众对战胜疫情的迫切心情。虽然目前国内的疫情得到了控制,但从国内外疫情发展来看,依然不能松懈。

图3 微博评论词云图
为了更直观地分析民众对于新冠肺炎疫情的关注度,本文绘制了词云图,如图3 所示,词频由字体的大小体现。“肺炎”“新冠”“疫情”“确诊”“病例”等词突出,说明关于此次疫情的话题以新冠肺炎为核心,民众非常关心每天确诊了多少病例。其次,“市场供应”“人均收入”“权益”“底层”“工作岗位”等词语得到清晰呈现,表明市场需求不足导致供给市场中商品滞销,企业出现亏损,失业现象加重,收入减少,引发了大众对民生权益的关注。“美国”“伦敦”和“佛罗里达州”等词语的出现,说明了我国居民对国外疫情的持续关注。
4.文本聚类。首先本文基于TF-IDF 对微博评论文本进行K 均值聚类。TF-IDF 的主要思想是,如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF 实际上是TF*IDF。TF 是指词频(Term Frequency),表示词条在文档d 中出现的频率。IDF是指逆向文件频率(Inverse Document Frequency),其主要思想是,如果包含词条t 的文档越少,也就是n 越小,IDF 就越大,说明词条t 具有很好的类别区分能力。
K 均值聚类是迭代动态聚类算法中的一种,其中K 表示类别数。K 均值聚类算法通过预先设定的K 值及每个类别的初始质心对相似的数据点进行划分,并通过划分后的均值迭代优化获得最优的聚类结果。

图4 聚类结果图
图4 是设定K=5 并通过聚类得到的结果,一行代表一个类别,每行中的词是此类别的关键词。可以看到:第一类的关键词包括“新冠病毒”“武汉”“世卫”“美国”等,说明这个类别下的评论可能是在讨论新冠肺炎病毒起源的问题;第三类的关键词包括“病例”“确诊”“新增”“报告”等,说明这个类别下的评论可能是在讨论新冠肺炎每日新增的数量;第二、四、五类的关键词包括“时间”“浏览器”“手机”等,这可能是微博评论中显示的发布时间以及发布微博评论所采用的方式,包括电脑浏览器、手机客户端等。
从上述结果来看,聚类的效果不是很好,因此接下来本文使用LDA 模型生成文本主题。LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型是指文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到的。
LDA 可以用来识别大规模文档集或语料库中潜藏的主题信息,它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。

图5 LDA 模型图
图5 是使用LDA 模型生成的微博评论文本中重要性排名前十的主题,其中关键词前面的系数代表此关键词在该主题中的重要性程度,程度越高,系数越大。可以看到:第一个主题应该是呼吁民众在新冠肺炎疫情肆虐的情况下戴好口罩;第七个主题应该是每天有多少境外输入的确诊病例;第八个主题关注的是美国新冠肺炎的确诊病例数量;第九个主题表明新冠肺炎疫情下中国在行动,即我国政府在疫情下发挥了巨大的动员能力,将国内疫情控制好并向国外提供了必要的援助;第十个主题与刚才聚类得到的第一类结果相似,可能是在讨论新冠肺炎病毒起源的问题。
总体来看,我国民众在新冠肺炎大流行时关注的话题主要有新冠肺炎起源、戴好口罩做好自身防护、我国在抗击疫情中的表现、国外疫情发展。
三、城市交通出行特征分析
(一)数据采集
新冠疫情爆发期间,市民的日常公共交通出行受到了严重影响。2020 年1 月23 日,武汉实施了“封城”措施,城市内的各类公共交通停运,客运、火车、飞机也暂时关闭了对外的通道。同一时间内,全国其他各个城市也对其下辖的公共交通部门进行了严格管制,城市公共汽车、出租车、网约车经营企业是城市公共交通疫情防控的第一责任单位。
在这样的情形下,为保障必要的外出,地铁成为了民众快捷出行的最佳选择。基于此,本文决定采用地铁客流量来反映疫情期间的公共出行状况。受限于交通信息每日数据的可获得性和公开性,本文最终获取了国内10 个城市在2020 年1 月1 日至7 月31 日期间的地铁日客流量信息(杭州市地铁客流信息仅搜集到1 月1 日至4 月30 日的数据),信息来源于各个城市轨道交通微博账号的每日客流量披露,包括北京、南京、重庆、西安、成都、武汉、上海、杭州、广州、郑州10 个城市。
(二)研究内容与结果分析
为了更加直观地反映出本文所选取的10 个城市在2020 年1 月1 日至7 月31 日的客流量变化情况,本文将此期间内各个城市的地铁客流量绘制成折线图,如图6 所示。
从图6 可以清晰地看出,在疫情爆发前的2020年1 月上旬,上海、广州、北京作为10 个城市中人口最密集的3 个城市,地铁开通的线路最多,地铁客流量明显高于其他7 个城市。1 月下旬,恰逢春节返乡,新冠肺炎确诊病例开始大幅增加,而1 月23 日的武汉“封城”事件则是媒体与公众对新冠肺炎疫情引发关注的重要标志。折线图中所反映的地铁客流变化情况也与疫情的发展状况大致趋同,所有城市的地铁客流同时从1 月21 日开始呈现坠崖式下跌,并于1 月23 日跌至谷底。
2020 年1 月23 日,武汉“封城”措施实施后,全国各地的民众都对新冠疫情的严重性有了更清醒的认识。随后不久,各省市政府下达了交通管制、出行限制的指示,城市交通几近瘫痪,日客流量急剧下降。虽然只有武汉市的地铁停运,但从图6 中可以看出,所有城市的地铁客流量都出现了明显下降。3 月初到4 月底,国内疫情得到有效控制,民众对战胜新冠肺炎疫情的态度更加积极,社会复工复产,各城市的地铁开始稳步运营。在3 个地铁交通最发达的城市(上海、广州、北京)中,上海的地铁运营恢复最快,明显高于其他两个城市。武汉作为重点防疫城市,虽然3 月27 日以后地铁恢复营运,但高强度交通管制使其日客流量恢复情况在全部10 个城市中仍处于较低的位次。6 月11 日,北京市在50 多天没有发现新的本地感染病例的情况下,突然确诊了1 例本地感染病例。6 月17 日,北京市提升应急响应至二级,关闭多个农贸市场,同时调整公共交通限流比例。由于政府相关措施的出台以及市民对新冠肺炎的警惕,6 月11 日以后北京市的地铁客流量出现大幅下降。截至6 月底,北京每个周末的地铁日客流量均少于200 万人,这在图6 中有明显的体现。7 月7 日之后,北京疫情得到较好控制,再无本土病例出现,地铁也开始逐渐恢复至正常的运营状态,但客流量相对之前明显减少,北京市需要时间来恢复居民的外出信心。
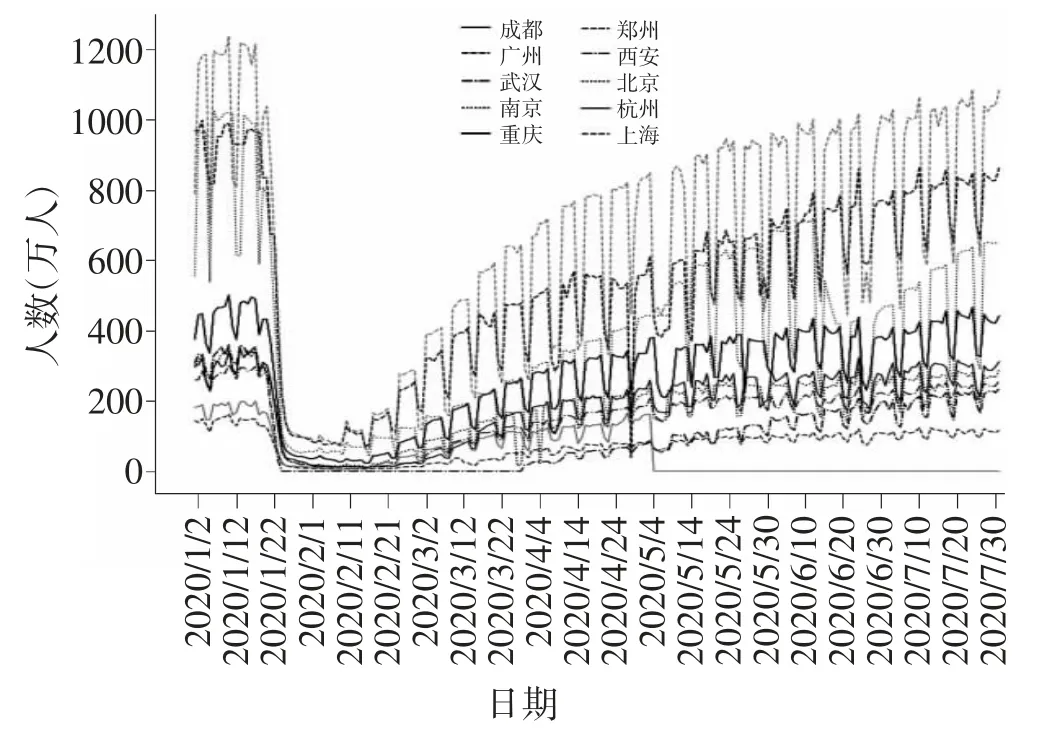
图6 各城市地铁日客流量变化折线图
四、舆情演化对城市交通出行的影响
民众情感得分与地铁日客流量的分析显示,二者之间存在内在的联系。接下来我们对其进行建模实证分析,民众情感得分和各城市的地铁日客流量数据前文已做了详细阐述,各城市的总人口和生产总值数据分别来自各市统计局公布的月度统计数据。
(一)数据预处理
考虑到部分变量存在少量缺失值,本文以线性插值方法来填补缺失数据。该方法假设变量是线性匀速变化的。假如与x(通常为时间)相对应的y缺失,而最临近的两个点分别为(x0,y0)与(x1,y1),且x0<x<x1,则y对x的线性插值为由于武汉市地铁停运期间,日客流量为零,取对数无意义,因此本文采取对所有数据加1 后再取对数的处理方法,然后使用线性插值补齐缺失值。
(二)误差相关性检验
本文获取的研究数据是典型n小T大(n=9,T=213)的长面板数据。在短面板模型中,一般假设{εit}独立同分布,也就是不存在随机扰动项的自相关。但是对于长面板模型,因为T较大,所包含的信息量较多,{εit}很可能存在异方差和自相关。记个体i的扰动项方差为,那么我们考虑{εit}的以下三种情形:(1)如果,那么{εit}存在组间异方差;(2)如果存在Cov(εit,εis)≠0(t≠s,∀i),那么{εit}存在组内自相关;(3)如果存在Cov(εit,εjt)≠0(i≠j,∀t),那么{εit}存在组间同期相关。因此,我们需要针对这些情况对数据进行检验。
1.组间异方差检验。Wald 检验原假设为“不同个体的扰动项方差均相等如果原假设成立,那么其中为σ2的一致估计量为的一致估计量,eit为εit的残差。如果每个个体的扰动项相互独立,那么构造如下的Wald 统计量:
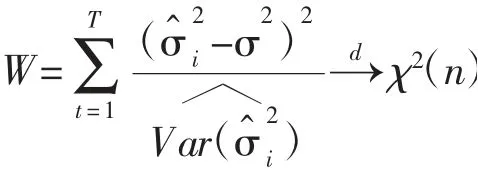
组间异方差检验结果如表4 所示,可以看出,沃尔德统计量为110.84,P 值接近于零,因此强烈拒绝同方差的原假设,即面板模型的随机扰动项存在组间异方差。

表4 组间异方差检验结果
2.组内自相关检验。组内自相关Wald 检验的原假设为“不存在组内自相关(Cov(εit,εis)=0;t≠s,∀i)”。给定个体i,首先对面板回归方程进行一阶差分,如果扰动项εit不存在组内自相关,那么我们可以推导得出Δεit的方差为,自协方差为,那么自相关系数为-0.5。我们也可以说Wald 检验的原假设为“ρ=-0.5”。检验结果见表5。

表5 组内自相关检验结果
分析表5 的检验结果可知,由于P 值近似为零,在1%的水平上显著,故拒绝原假设,认为该数据的随机扰动项存在组内自相关。
3.组间同期相关。组间同期相关LM 检验的原假设为“不存在组间同期相关(Cov(εit,εjt)=0;i≠j,∀t)”。根据残差计算的不同个体扰动项的相关系数矩阵见式(1)。
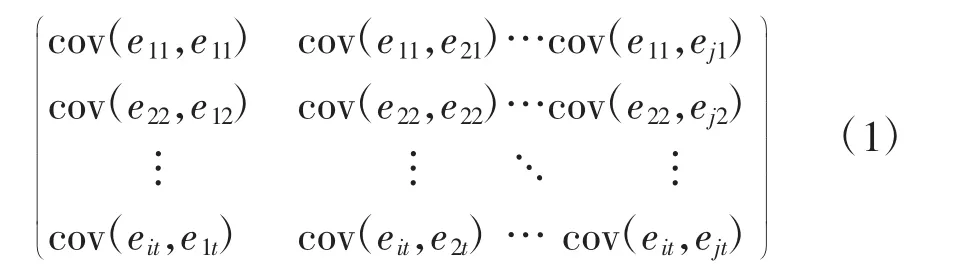
如果该矩阵非主对角线元素均接近于零,我们就可以认为{εit}不存在组间同期相关。相关系数矩阵如式(2)所示,检验结果在表6 中给出。


表6 组间同期相关检验结果
分析相关系数矩阵可知,非主对角线元素的值偏离零值较远,这说明不同个体在同期的扰动项存在显著的相关性,并且LM 检验的结果也拒绝了不存在组间同期相关的原假设。
(三)模型建立
由前文对各城市居民情感得分的分析可知,2020 年2 月9 日至2 月29 日,居民的整体情感得分均值一直处于0.5 以下,2 月份民众情感达到最低谷。同样,前文对各城市地铁日客流量的研究也显示,各城市的地铁客流量从1 月20 日开始大幅滑落,1 月24 日至2 月24 日达到最低谷,之后虽然有所上升,但增速缓慢。截至2 月末,各城市的地铁客流量仍远低于疫情爆发前。鉴于客流量与情感得分处于低谷的时期高度重合,本文提出假设:疫情期间,居民的出行状况会直接影响其情绪变化。
在前文数据处理的基础上,本文首先绘制了各城市2020 年1 月1 日至7 月31 日微博用户的情感得分与地铁日客流量的散点图,结果如图7 所示。
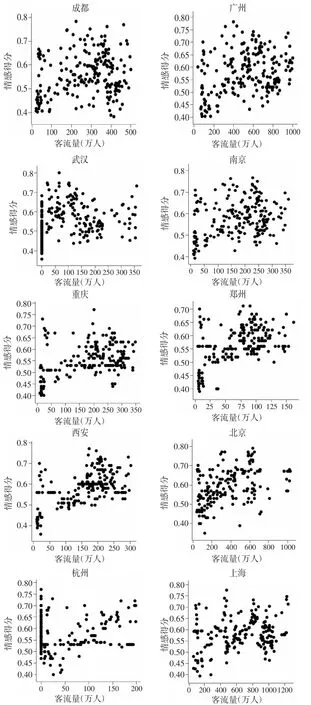
图7 民众情感得分与日客流量散点图
由图7 可知,随着情感得分的提高,大部分城市的地铁日客流量存在递增的趋势,因此,本文建立长面板回归模型来研究民众情感得分和地铁日客流量的关系。模型中选取被解释变量为各城市的民众情感得分(scoreit),核心解释变量为各城市的地铁日客流量对数值(lnpassenit),控制变量为各城市取对数后的总人口(lnpeopleit)与生产总值(lngdpit),i表示城市,t表示时间。面板回归模型表示为:
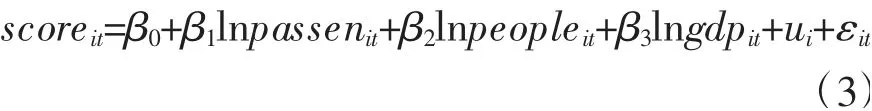
其中:ui为个体固定效应,体现各城市异质性的不可观测项;εit是既随时间又随个体改变的随机扰动项。
(四)模型检验和结果分析
1.单位根检验。存在单位根的面板数据通常是不平稳序列,会导致伪回归和t 检验不再有效。在常用的面板单位根检验方法中,HT 检验适合短面板数据,LLC 和Breitung 检验要求每位个体的自回归系数相同,但在前文的检验中,组间同期相关的自回归系数并不相等。综合考虑,本文选取IPS 检验和费雪式检验分别对各变量进行单位根检验,相关检验结果见表7。表7 的单位根检验结果表明,不论是IPS检验还是费雪式检验,日客流量对数和民众情感得分均在1%的水平上为平稳时间序列。
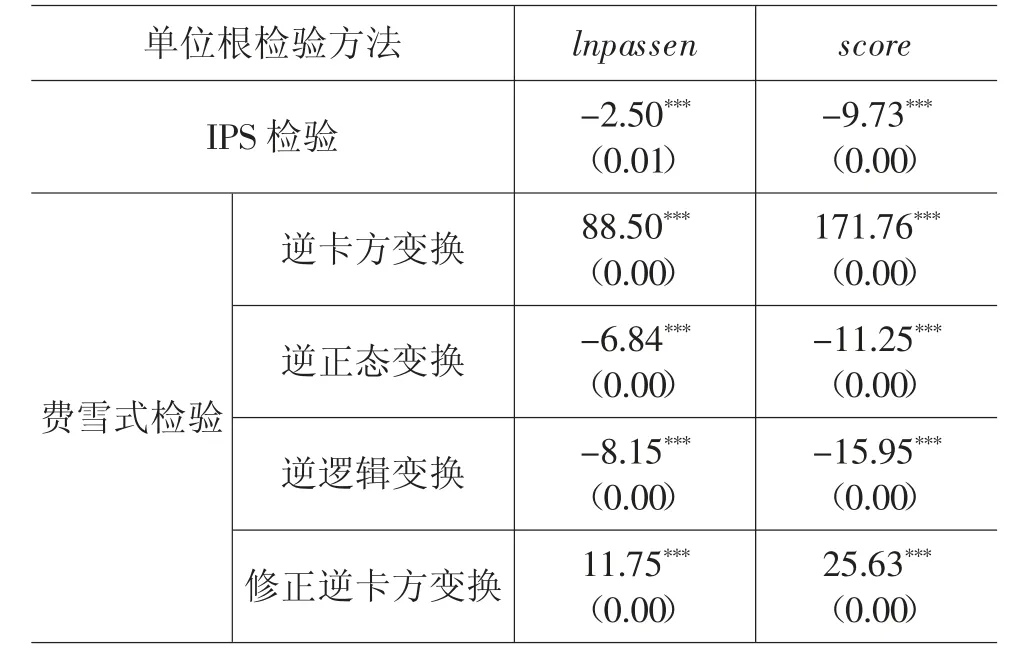
表7 单位根检验结果
2.协整检验。协整检验考察变量间是否存在长期均衡关系。本文采用Kao 检验、Pedroni 检验两种方法分别进行协整检验。表8 的检验结果表明,无论Kao 检验还是Pedroni 检验,研究变量均通过了1%的显著性水平检验,表明可以拒绝原假设,认为变量间存在长期稳定的协整关系。
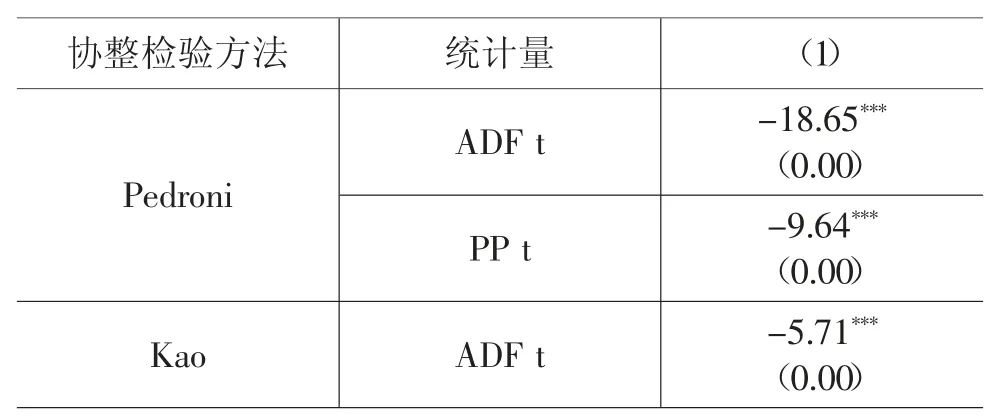
表8 协整检验结果
3.结果分析。由前文的检验可知,该模型的随机扰动项存在组间异方差、组内自相关和组间同期相关,为此,本文使用更为全面的可行广义最小二乘估计(Feasible Generalized Least Squares,FGLS)进行分析。首先对模型(3)进行最小二乘估计,然后使用残差{eit}来估计εit的协方差矩阵,以此进行FGLS 估计,结果见表9。
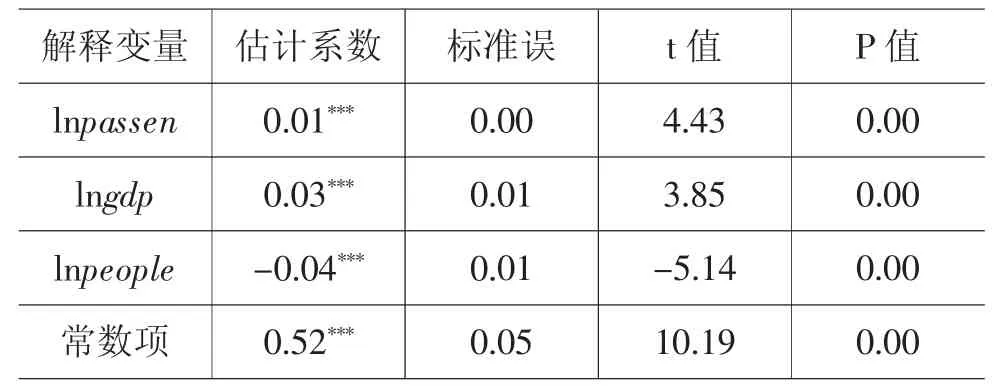
表9 回归分析结果
由表9 可以看出,地铁日客流量每上涨1%,民众的情感得分平均提高0.01 分,并且该结果在1%的水平上显著。民众对于疫情情感态度的变化最直接地体现在是否可以外出,能否实现外出自由。隔离封闭的环境与单调的工作生活均会增加民众内心的孤独感,甚至导致抑郁、焦虑,所以,交通出行的自由反映在日客流量的增加上,将变成情绪释放的“闸口”。城市地铁日客流量的增加,也侧面反映了民众“敢出门”的心理,而“敢出门”是百姓对于国家疫情防控工作的信任。通过控制变量的分析可以得出,城市生产总值每增加1%,民众情感得分会平均提高0.03 分;城市总人口每增加1%,居民对新冠肺炎疫情的情感得分会平均降低0.04 分。GDP 反映一个地区的综合经济实力,随着GDP 的增加,大众对于应对疫情会更加积极。相反,如果城市居民过多或者说一个城市的居民数量在疫情期间不断上升,那么人口流动的不确定性将会带来居民的恐慌情绪,并且人口越密集的城市,感染肺炎的概率越大,情感得分越低。
(五)进一步分析
本文使用爬取的民众情感得分代表大众面对疫情时的情感态度,使用地铁日客流量数据反映城市交通状况,分析发现,在研究时段内,外出通行对公众情感态度的变化产生了积极影响。由于疫情防控的逐渐常态化,前文的分析不易把握情感态度与交通出行间更为具体的关系,因此接下来我们将进行分时段研究。
2020 年6 月7 日,中国发布《抗击新冠肺炎疫情的中国行动》白皮书,其中指出,中国抗击疫情的艰辛历程分为五个阶段。第一阶段:迅即应对突发疫情(2019 年12 月27 日至2020 年1 月19 日)。湖北省武汉市监测发现不明原因肺炎病例,第一时间报告疫情,中国迅速采取行动,开展病因学和流行学调查。第二阶段:初步遏制疫情蔓延(2020 年1 月20日至2 月20 日)。全国新增确诊病例快速增加,中国采取阻断病毒传播的关键一招,坚决果断关闭离汉离鄂通道,武汉保卫战、湖北保卫战全面打响。第三阶段:本土新增病例数逐步下降至个位数(2020 年2月21 日至3 月17 日)。中共中央作出统筹疫情防控和经济社会发展、有序复工复产的重大决策。第四阶段:取得武汉保卫战、湖北保卫战决定性胜利(3 月18 日至4 月28 日)。以武汉市为主战场的全国本土疫情传播基本阻断,离汉离鄂通道管控措施解除,武汉市在院新冠肺炎患者清零。第五阶段:全国疫情防控进入常态化(4 月29 日以来)。境内疫情总体呈零星散发状态,局部地区出现散发病例引起的聚集性疫情,境外输入病例基本得到控制。
白皮书发布的“抗击疫情”五个阶段同本文的情感得分和交通日客流量阶段划分相呼应,随着国家抗击疫情的举措越来越完善,城市交通出行也在慢慢恢复,民众情感渐趋稳定。基于此,本文进一步分析了五个阶段内情感得分与民众交通出行之间的关系。
将疫情爆发时间划分为五个阶段,由于各阶段T值仍大于n,我们研究的各阶段数据依旧是长面板数据,{εit}很可能存在异方差和自相关。因此,对各阶段的数据进行组间异方差检验、组内自相关检验和组间同期相关检验,检验结果分别见表10、表11和表12。
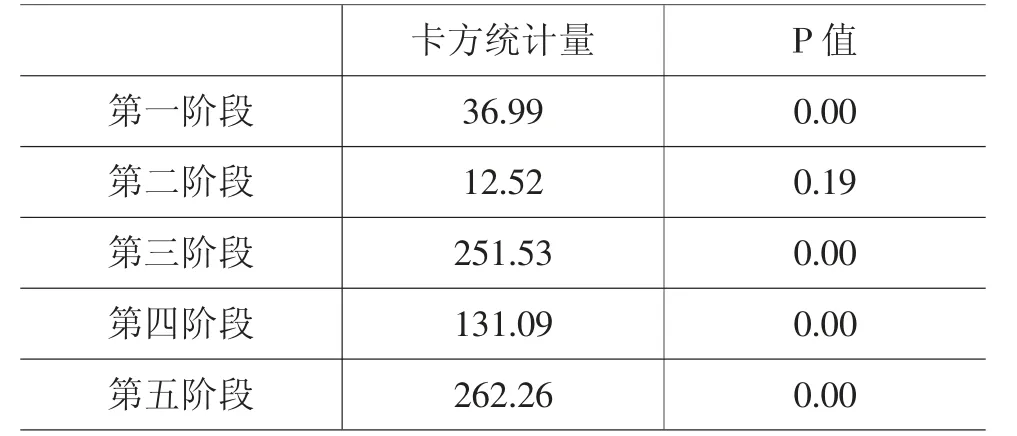
表10 分阶段组间异方差检验结果
表10 的检验结果可知,有且仅有疫情蔓延初步遏制阶段的P 值大于10%,检验结果接受原假设,即不存在组间异方差。其他阶段的P 值接近于零,均拒绝原假设。
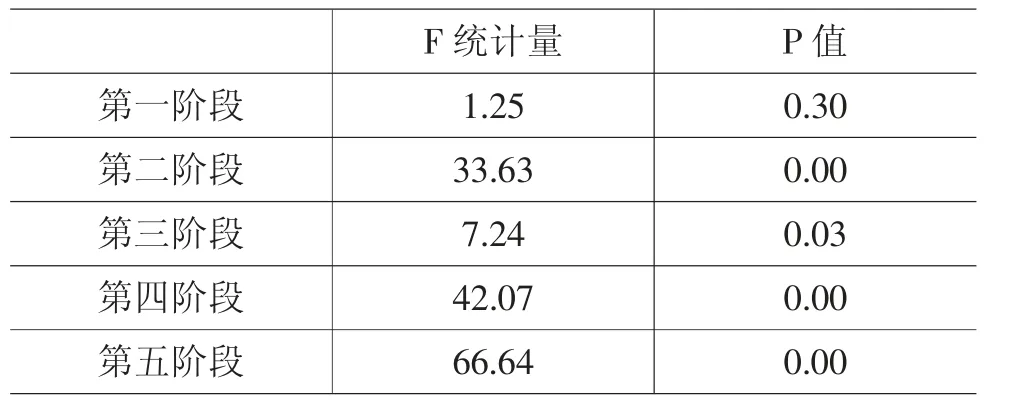
表11 分阶段组内自相关的检验结果
由表11 的检验结果可知,国家采取措施迅速应对突发疫情阶段的P 值为0.3,远大于10%的显著性水平,因此接受随机扰动项不存在组内自相关的原假设。其他四个阶段的P 值近乎为零,拒绝原假设。由表12 的LM 检验结果可知,各阶段卡方统计量对应的P 值均近似等于零,因此拒绝随机扰动项不存在组间同期相关的原假设。
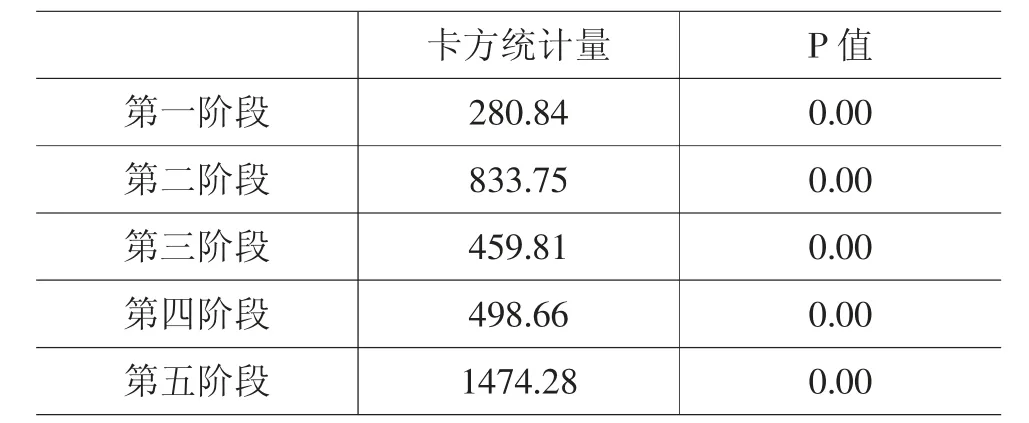
表12 分阶段组间同期相关的检验结果
由上述检验结果可知,不同阶段模型的随机扰动项具有不同的特征,因此,在建模时所采用的估计方法也存在差异。当模型(3)的扰动项存在组间异方差或组间同期相关时,最小二乘估计依然是一致的,因此只要使用面板校正标准误(Panel-Corrected Standard Error,PCSE)进行估计即可。本文的第一阶段模型使用PCSE 方法进行参数估计,其他阶段模型使用全面的FGLS 方法进行估计。全面的可行广义最小二乘估计(Feasible Generalized Least Squares,FGLS)同时考虑了组间异方差、组内自相关和组间同期相关,结果如表13 所示。
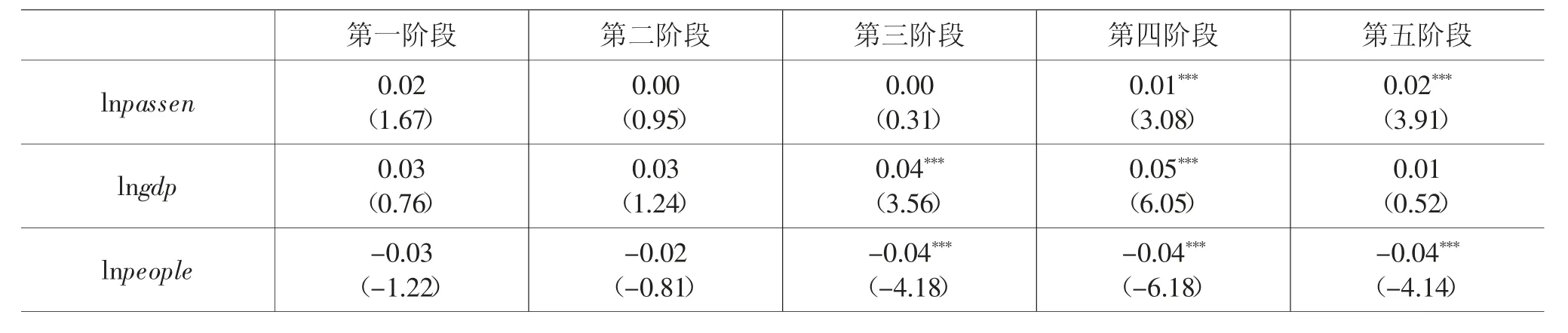
表13 分阶段回归结果

(续表13)
表13 的回归结果反映了不同阶段地铁日客流量与民众平均情感得分之间的关系。分析得出,2020年1 月1 日至3 月17 日,地铁日客流量并未对市民的情感得分产生显著影响,这是由于第一阶段为疫情爆发的初期阶段,绝大多数民众对疫情的重视程度还不够,日常出行作为一种生活常态对情感态度的影响并不显著。在第二阶段和第三阶段,各省市政府下达了交通管制、出行限制的指示,城市交通几近瘫痪,日客流量急剧下降。在禁止出行的情形下,地铁日客流量寥寥无几,交通出行对居民情感态度的影响不显著。自第四阶段开始,地铁日客流量每上涨1%,城市居民的情感得分平均增加0.01 分和0.02分。抗击疫情的后期,我国已经积累了不少经验,居民在应对疫情方面也更加自觉和自律。3 月中旬到4月底,国内疫情得到有效控制,社会复工复产,离汉离鄂通道管控措施解除,各城市的地铁乘次逐渐恢复稳步运营。封闭了近两个月的民众在国家复工复产的号召下,外出意愿较为强烈,并且对抗击疫情的态度更加积极。第五阶段全国疫情防控进入常态化,境内疫情总体呈零星散发状态,境外输入病例基本得到控制。这意味着外出通行再次恢复成生活常态,随着地铁日客流量的提升,大众的情感也更为积极。此外,第五阶段的影响程度要高于第四阶段,这是因为在3、4 月份,虽然工作开始恢复,但民众对于疫情仍有担忧和顾虑。然而,随着连续每日新增病例为零,防控工作进入常态化,我们对战胜疫情的信心明显增加了,外出通行对情感得分的影响程度达到最大。
五、主要结论
本文主要探究了2020 年1 月1 日至7 月31 日全国主要10 个疫情爆发城市的民众情感趋势、关注话题和城市交通状况,并探讨了网络舆情与交通出行之间的联系,得出了四个主要结论。
第一,民众的情感经历了起伏,但是大部分时段仍持积极态度。第一阶段为2020 年1 月1 日至2 月9 日,前期国内居民对于此次疫情了解较少,虽然情绪存在波动,但是均高于0.5,大部分人还未意识到这次疫情的严重性。第二阶段为2 月9 日至2 月29日,随着确诊和死亡病例的剧增,各级政府实施交通管制,大部分居民被限制在固定的区域内活动,导致社会产生了更多的消极情绪。第三阶段为3 月1 日至6 月13 日,该时期国内疫情好转,各城市陆续解封。第四阶段为6 月13 日至6 月27 日,北京突发确诊病例,再次引起社会关注,人们因担心疫情反弹而释放出更多负面情绪。第五阶段为6 月27 日至7 月31 日,整体情感得分大于0.5,居民对待疫情的态度更加从容。研究还得出,我国中西部省份在研究时段内的情感得分更低。从武汉“封城”到各城市启动复工这段时期内,由于农历新年的影响,我国居民仍持有较高的情感得分。
第二,城市地铁日客流量与微博舆情的时段划分相一致。武汉“封城”后不久,各省市政府下达了交通管制的指示,城市交通几近瘫痪,日客流量急剧下降,这种情况一直持续到2020 年2 月底。3 月初到4月底,社会复工复产稳步开展,各城市的地铁乘次开始有序运营,其中上海的地铁运营恢复最快。6 月11日北京市新增确诊病例,随后,北京市恢复社区封闭管理,调整公共交通限流比例,控制上座率,地铁客流量出现大幅下降。
第三,研究期内,交通出行对大众情感产生了积极影响。地铁日客流量每上涨1%,民众的情感得分平均提高0.01 分。日客流量的上涨侧面反映出交通出行的自由灵活,长期被“封闭”的居民压抑的情绪得以释放。城市生产总值越多,居民情感得分越高,表明政府会花费更多的人力、财力用于疫情防控,让居民居住在放心的环境中。城市人口越多,越容易引发民众恐慌,表明人口密度的增加和人口流动会加大感染疫情的风险。
第四,依据《抗击新冠肺炎疫情的中国行动》白皮书,本文将2020 年1 月1 日至7 月31 日划分为五个阶段。前三个阶段(1 月1 日至3 月17 日)的地铁日客流量对民众情感得分的影响不显著,可能的原因是疫情初期,交通封闭,居民外出受限。在第四阶段和第五阶段(3 月18 日至7 月31 日),地铁日客流量平均每增长1%,居民情感得分平均上升0.01分和0.02 分。随着疫情防控常态化,民众更注重日常防范,城市交通有序恢复,居民外出也越来越放心,大众对于战胜疫情越来越有信心。越到后期,地铁日客流量反映的交通出行情况对居民情感的影响越大。
