基于大数据的决策支持平台建设研究
2021-04-23宋梦佳何淳真
王 瑞,宋梦佳,刘 磊,康 莹,何淳真
(西安应用光学研究所,西安 710065)
0 引言
随着“大数据”时代的来临,大数据相关技术在社会各领域中发挥了重要作用,大数据成为继物联网、云计算技术之后的热点话题。对大数据技术的研究,已经成为当前重要的技术研究领域。企业已建立了大量的应用系统,例如ERP、BPM、OA、PDM 等,这些应用系统的深入应用,产生了大量的基础数据。其次,企业设备监控和管理产生的数据也呈指数型增长。此类海量基础数据的管理与可靠存储以及实现数据共享和关联分析,将海量基础数据通过大数据技术转化为有价值的知识来提升企业决策能力,是现代企业亟需解决的问题。
当前绝大多数企业在大数据技术应用方面涉及极少,数据存储也都是采用传统的大型服务器,这种大型服务器一般价格十分昂贵,存储方式采用的是磁盘阵列,数据库也是传统的关系型数据库。而大数据技术能处理TB 级海量数据,设备利用率较高,对设备的依赖性较小,可同时处理结构化和非结构化数据,这些优势都为大数据分析打下了基础,使数据分析不仅仅停留在数据的展现而更侧重于对海量的历史数据进行分析、挖掘与预测,这样才能为企业的管理层提供准确的决策依据[1]。
1 研究背景
大多数企业随着信息化的发展已经建立相应决策分析系统,但是随着企业数据量与日俱增,现有的系统渐渐已经不能满足企业的需求,逐渐地暴露出了一些问题,具体有如下几个方面[2]。
数据分析方法单一。传统的决策分析系统侧重于数据的展现,数据源大部分还是靠业务人员整理后上传,从应用系统提取的数据较少,这样就会导致对数据分析挖掘的能力较弱,同时也无法跨系统跨数据库联合分析。
数据处理和查询能力低下。面对数据量较大、数据复杂度较高的情况,无法对数据进行清理、转换,不具备实时和高速处理分析能力。其次,面对指数级增长的数据缺少快速响应复杂的分析与查询。
传统数据库的技术下的储存能力和方式有限。当前,数据的范围只能是结构化的数据,不能对TB 级的数据进行处理,更不能对高级别数据分析有所支持。企业的大数据包括管理数据、运维数据、生产数据、运营数据等,这些数据既有结构化数据,也有非结构化数据,例如图片、视频等。
不具备数据监控和风险预警功能。由于数据采集能力较弱,无法实时采集系统及设备的运行数据,无法监控关键环节的数据,不能快速定位业务异常点。因此,面对企业日益增长的数据分析需求,只有建设基于大数据的决策支持平台,才能彻底解决企业现有的问题。
2 大数据分析与传统决策分析的区别
传统决策分析主要是偏重对现有系统中的数据进行有效整合,通过可视化技术进行多维分析。而大数据是从提取的海量数据中,通过不同的算法将这些来自不同系统、格式的数据经过处理后进行分析,通过算法寻找数据之间隐藏的关联性。总而言之,大数据分析更侧重猜测、发现、印证的循环逼近过程。大数据技术和以往的信息产出方式相比具有三个明显的特征:数据量大、非结构化和实时性。以往企业先是对数据进行收集,之后再进行分析,现在大数据分析可随时进行,这样有助于迅速实现数据分析并调整企业战略[3]。大数据分析与传统决策分析的区别主要有以下几点。
数据来源。大数据之前,企业只能使用结构数据。大数据技术的应用使得企业深度使用大量非结构数据成为可能:视频资料、音频资料、图片、文本、推送信息等。对大数据的分析工具而言,也是以非结构数据分析为主。
思维方式。大数据相对于传统分析方式既有继承,也有发展。传统分析更倾向于对现有、共性的事物的展现和描述,帮助决策者了解宏观统计趋势,适合经营、运营类指标,而大数据分析更倾向对历史数据的挖掘和对未来的预测。
工具角度。传统分析主要应用的是ETL、数据仓库、OLAP、可视化报表技术,这些技术属于展示和应用层的技术,但是这些技术不能对海量数据进行很好的处理。大数据分析随着不断的发展逐渐形成一个较完整的技术体系,例如海量结构化、非结构化数据的ETL 问题可以用Hadoop、流处理等技术解决。高效读取的问题可以用redis、HBASE 等方式解决,在线分析的问题可以用Impala 等技术实现。
成本方面。对于大多数企业来说、大规模数据的处理在以往的花费是巨大的,大数据的出现为大企业与中小型企业提供了更多的平等机会。大数据解决方案的廉价性与增长性能够为更多的企业提供服务。
3 系统实现
3.1 基于大数据的决策分析平台架构
大数据分析平台主要从企业采集相关的业务数据,这些数据不仅仅包括信息系统中结构化数据,还包括大量的非结构化数据。采集过程中,为了预防大量噪声数据进入大数据分析平台中,需将数据进行初步的过滤。采集的数据将存入基于云计算技术的分布式存储系统中,并通过相关的计算系统对数据进行分布式计算。通过挖掘分析提取出有用的信息展现给用户。因此从数据被采集、转换、存储、分析、应用的角度对大数据分析平台内部技术构件进行抽象,将大数据分析平台分为数据源、数据存储与计算层、挖掘分析层、数据展现与访问层,数据分析系统的体系架构如图1 所示。
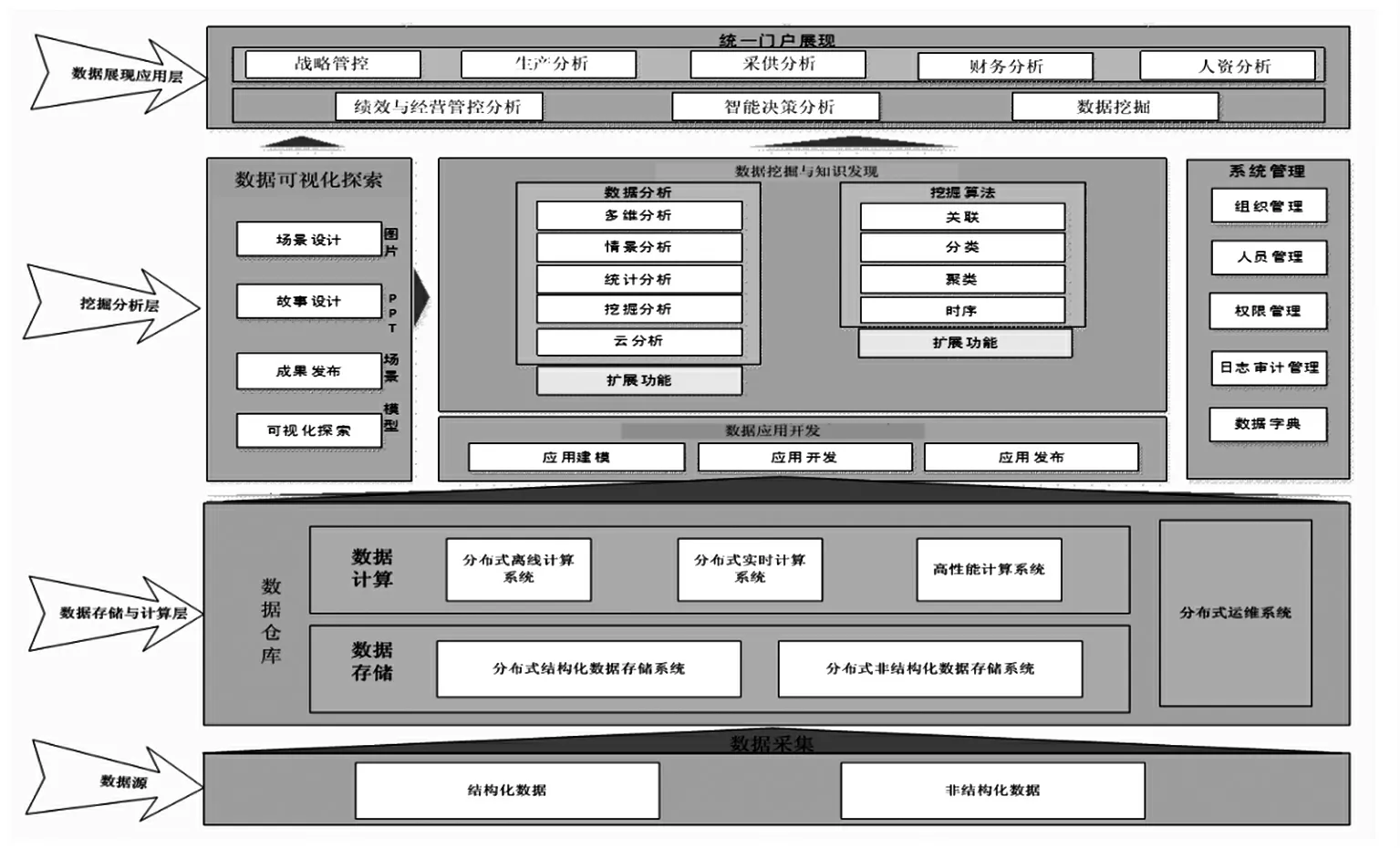
图1 大数据分析平台架构
3.2 平台功能模块介绍
3.2.1 数据源
结构化数据:能够用数据或统一的结构加以表示,如数据库数据、表格数据等。
非结构化数据:无法用数字或统一的结构表示,如所有格式的办公文档、文本、图像、图片、XML、HTML、各类报表和音频、视频信息等。
3.2.2 数据存储与计算层[4]
数据存储:分布式结构化数据存储系统。HBASE 是一个基于HDFS、列存储数据库,提供海量数据存储能力。优点:分布式存储、扩展性强,数据的实时写入性能高,容灾能力强,大规模数据下检索性能高。相对硬件成本低。和HIVE 结合,可以使用类SQL 语句进行查询。缺点:只支持单索引查询(单KEY),对KEY 的设计要求很高。关系型数据库可以导入HBASE,但是不具备关系型数据库之间的关系。
HIVE:是一个在Hadoop 上构建数据仓库的软件。优点:分布式存储和处理、扩展性强,容灾能力强,相对硬件成本低,支持类SQL 的HQL 语言。缺点:不支持实时写入,只能批量写入,无法修改数据。关系型数据库可以导入HIVE,但是不具备关系型数据库之间的关系。
分布式非结构化数据存储系统:HDFS 是Hadoop 的分布式文件系统。其优点是分布式存储、扩展性强,数据的实时写入性能高,容灾能力强。相对硬件成本低。类Windows 文件管理方式,比较便捷。
MongoDB:是一个介于关系数据库与非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。Mongo 支持的查询语言非常强大,它几乎可以实现类似关系数据库单表查询的绝大部分功能,并且还支持对数据建立索引。通过内存映射文件提高访问效率,支持完全索引,分布式数据库,支持MapReduce。
数据计算:分布式离线计算系统。HADOOP 是一个能够对大量数据进行分布式处理的软件框架,能够实现在大量计算机组成的集群中对海量数据进行分布式计算。它的框架最核心设计就是MapReduce 与HDFS。MapReduce 提供了对数据的计算,HDFS 提供了海量数据的存储。优点:高可靠性、高扩展性、高效性、高容错性、低成本。
SPARK:是UC Berkeley AMP lab所开源的类Hadoop MapReduce 的通用的并行计算框架,Spark 基于MapReduce 算法实现的分布式计算,拥有MapReduce 所具有的优点。但不同于MapReduce 的是Job 中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark 能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce 的算法。Spark 提供的数据集操作类型有很多种,不像Hadoop 只提供了Map 和Reduce两种操作。Spark 通过提供丰富的Scala,Java,Python API 及交互式Shell 来提高可用性。
分布式实时计算系统:Storm,实时流处理框架。弥补了Hadoop 里所不能满足的实时要求。Storm 与Hadoop 的对比。Hadoop 在本质上是一个批处理系统。数据被引入Hadoop 文件系统并分发到各个节点进行处理。当处理完成时,结果数据返回到HDFS 供始发者使用。Storm 支持创建拓扑结构来转换没有终点的数据流。不同于Hadoop 作业,这些转换从不停止,它们会持续处理到达的数据。
高性能计算系统:内存计算实质上就是CPU 直接从内存而不是硬盘上读取数据,进行计算、分析,是对传统数据处理方式的一种加速。内存计算非常适合处理海量的数据,以及需要实时获得结果的数据内存计算相比传统的方法的优势是:充分发挥多核的能力,可以对数据并行的处理,并且内存读取的速度成倍数加快,数据按优化的列存储方式存放在内存里面。GPU 英文全称Graphic Processing Unit,一般存在于计算机的显卡中,计算机中GPU 的出现是为了把CPU 从复杂的图形运算中解放出来,进行其他更重要的工作。特点为具有多处理器结构、并行处理数据能力、存储器存取速度高。CPU 与GPU 对比:GPU 拥有自己独立的子存储系统——显存,而且GPU 对显存数据的访问速度比CPU 对系统主内存数据的访问速度更快。CPU 将更多资源用于缓存及流控制,GPU 将更多资源用于数据计算。
分布式运维系统:Intel Hadoop Manager,安装、配置、管理、监控、告警。
3.2.3 挖掘分析层
数据可视化探索平台(Tempo-DataInsight)[5]:以可视化、图文交互的方式实现数据源连接、数据加工处理、数据分析和结果展现的过程,能够完成数据观察、操纵、研究、浏览、探索、过滤、发现、理解,从而有效地发现隐藏在信息内部的特征和规律。
数据分析与挖掘平台(Tempo-PlutoDM):通过科学的数据挖掘方法建立模型,并对模型进行评估、调优,挖掘出对用户有价值的知识成果,以可视化的方式将数据挖掘的知识结果展示给用户,从而帮助研究所从海量数据中发现规律、获取商业洞察力、创造商业价值。
数据应用开发平台(Tempo-DataAppDev):通过拖拽方式将通用构件进行图形化组装,完成数据建模、表单设计、业务逻辑开发、系统调试,并且在开发中提供数据挖掘算法、数据分析模型集成、数据可视化、高维可视化等组件,快速构建基于Web 的研究所级数据应用系统,提升数据的价值发现与利用。
3.2.4 数据展现应用层
通常以管理驾驶舱或管理看板的方式,面向企业的战略、总体经营以及各专业提供多个管理驾驶舱或数据看板,将图表化的分析数据推送给领导角色,使之比较直观、间接地了解企业的经营状态。管理驾驶舱提供多种图表类型,以满足趋势分析、数据对比、指标偏离预警、构成分析等不同类型的分析需求,并提供数据钻取等交互操作。
4 结语
本文结合大数据技术构建了大数据分析平台,提升了企业数据高效存储与高性能处理能力,通过数据分析和挖掘提取对企业有价值的知识成果,并以可视化的方式将数据挖掘的知识结果展示给用户,从而帮助企业从海量数据中发现规律、获取商业洞察力、创造商业价值,为以后基于大数据的信息化建设奠定了坚实的基础。
