书目框架(BIBFRAME)国内外研究与实施进程的调查与思考
2021-04-23杨静,张婕,王蓓
杨 静,张 婕,王 蓓
(金陵图书馆,江苏 南京 210019)
书目框架(BIBFRAME)是由美国国会图书馆(Library of Congress,LC)联合Zepheira公司于2011年联合发起的“书目框架先导计划”,旨在开发一种基于关联技术的替代MARC的书目数据格式。一方面,使书目数据能够融入互联网环境中来发挥价值,避免成为“信息孤岛”;另一方面,是实现更多书目数据的关联发布,有利于用户获取知识更加立体和多元。
2013年1月,BIBFRAME1.0模型发布,同时提供了具体的元数据方案,并联合德国国家图书馆、大英图书馆、联机计算机图书馆中心(OCLC)等机构进行了大量的研发和测试,于2016年1月发布了BIBRRAME2.0模型。该版本发布后吸引了更多国家申请加入测试,目前,其官网发布了BIBFRAME2.0与MARC21之间相互转换工具、转换规范、BIBFRAME编辑器、BIBFRAME2.0词表等。
1 BIBFRAME2.0书目框架模型
BIBFRAME2.0书目框架模型将所要描述的信息分为三个核心级别:Work(作品)、Instance(实例)和Item(单件),三者共同构成了BIBFRAME2.0的三个层次,分别是Work(作品)代表的内容层次,Instance(实例)代表的载体层次和Item(单件)代表的单件层次,再通过定义相关的类、属性、关系来对文献资源进行富含语义的关系揭示(见图1)。
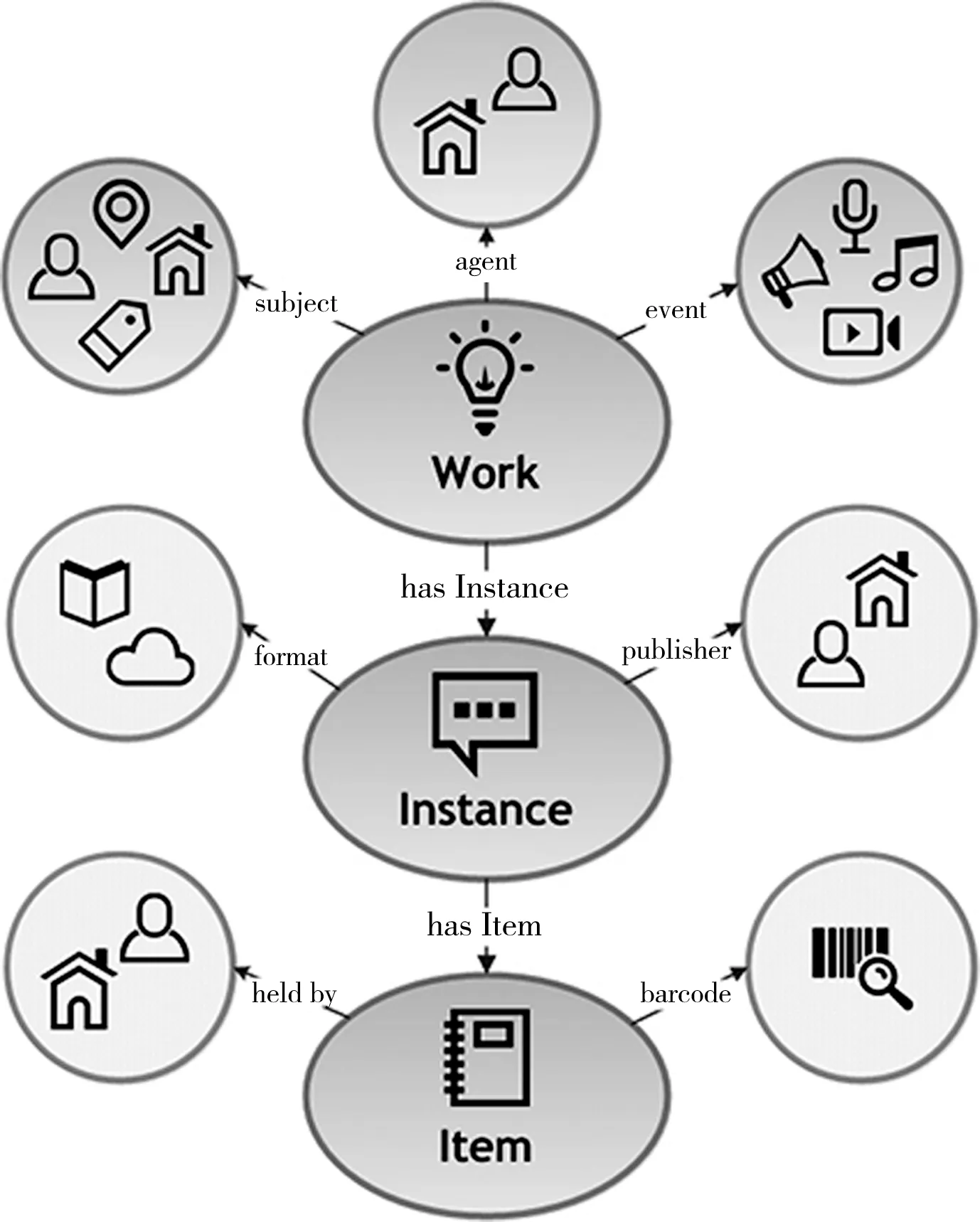
图1 BIBFRAME2.0书目框架模型
Work(作品)层是一个抽象的实体,它集中的是不同名称以及不同表达方式的同一作品,可以描述文本、地图、数据集、静态图像、动态图像、音频、乐谱、舞谱、物体、多媒体、混合资料等11种创作型作品资源类型,帮助用户识别和查找作品的更多表达形式。
Instance(实例)描述的是载体层次,是Work(作品)的具体化表现,因为一个作品很可能包括很多实例,它可以在不同分面上(如出版日期、语种、出版者、版本)产生新的数据集合。这一层聚合了不同的载体(包括印刷型、手稿、档案、触摸及电子型5种资源类型)可以帮助用户实现更广泛的查找。
Item(单件)通常为图书馆馆藏信息的描述,如借阅状态、副本信息等,该信息可以帮助用户直接获得所需资源。Item(单件)具有held by(持有者)和barcode(条形码)等属性,其中,held by(持有者)可以是个人也可以是图书馆,barcode(条码)是用户检索用的标识符,如索书号、条形码、位置标记等。
2 BIBFRAME书目框架在国外的发展及研究进程
目前,BIBFRAME2.0已进入测试推广阶段,根据其官网公布的测试登记信息,在BIBFRAME1.0版本阶段有9家机构参与,在BIBFRAME2.0阶段又有9家机构加入,这些机构的类型包括国家图书馆、高校图书馆、专业图书馆、图书馆系统服务商、开源网络平台,所在地覆盖美国、德国、英国、匈牙利、埃及、古巴。测试内容有MARC到BIBFRAME转换、BIBFRAME编辑器的测试和工具开发、BIBFRAME在非英语环境下的运行测试、BIBFRAME书目数据的关联发布等。
2.1 美国LD4系列项目
由梅隆基金资助的“图书馆关联数据LD4”系列项目始于2014年,每两年建立1—2个项目,2014—2016年开展LD4L 2014项目,由斯坦福大学、康奈尔大学和哈佛大学合作,旨在建立一个学术资源语义信息储存(SRSIS)模型,数据来源包括MARC、MODS(元数据对象描述模型)、EAD(编码档案描述模型),这样不仅在图书馆内部,还可以通过可扩展的关联开放数据网络吸纳档案馆等其他机构的元数据。2016—2018年开展2个项目:LD4L Labs和LD4P,吸收了更多高校图书馆的参与,如普林斯顿大学、哥伦比亚大学、艾奥瓦大学等。其中,LD4L-Labs专注于加强关联数据创建和BIBFRAME编辑工具、探索关联数据关系的可视化、BIBFRAME本体开发和URI持久化的工作,以帮助图书馆使用关联数据来改善对资源信息的发现、使用和理解。LD4P专注于跨域本体建模和元数据生成;特定领域的本体建模和元数据生成;加强和扩展BIBFRAME本体,以涵盖多种格式(如书籍、音乐、地图、视频等);参与关联数据相关工具的开发,推动更广泛的图书馆参与进来,确保可持续和可扩展的环境。2018—2020年开展LD4P2项目,相关完成度还没有公布,但是其官网公布了第二阶段的7大目标。
(1)由一个学术图书馆的核心小组,创建BIBFRAME表示的关联数据连续馈送池。
(2)开发基于云的沙箱编辑环境,以支持更多的参与图书馆(LD4P合伙人)创建和重用关联数据。
(3)开发用于以标识符自动增强MARC数据的策略、技术和工作流程,使其尽可能清晰地转换为关联数据。
(4)开发用于创建和重用关联数据及其支持标识符作为图书馆核心元数据的策略、技术和工作流程。
(5)通过与Wikidata协作,更好地将图书馆元数据和标识符与Web集成。
(6)使用基于关联数据的发现技术增强广泛采用的图书馆发现环境建设。
(7)通过开发一个名为LD4的组织框架来协调持续的社区协作。
2020年年中,新项目LD4P3(2020—2022年)获得批准,该项目的目标是closing the loop(闭环),为元数据的创建、共享和重用创建一个完整循环的工作模型。
2.2 欧洲图书馆界BIBFRAME的发展方向
2.2.1 将书目数据由MARC格式转换为BIBFRAME格式。匈牙利国立塞切尼图书馆(National Szechenyi Library)于2017年向美国国会图书馆申请开展BIBFRAME项目,该馆将书目数据由MARC格式转换为BIBFRAME格式,并上传至LOD(关联开放数据)云中,在转换中注重主题、作者、作品、出版者、实例、关联人物等实体,同时还为实体赋予URI,与BNF(巴克斯范式)、ISNI(国际标准名称识别码)、VIAF(虚拟国际规范文档)、LC NAF(国会图书馆名称授权文档)等已有词表进行关联与聚类。芬兰国家图书馆虽然没有选择BIBFRAME,但它利用BIBFRAME作为中介工具,将其书目数据从MARC转换为最终目标Schema.org(由谷歌、微软和雅虎共同推出的一个协作组织,为网络上的结构化数据标记创建并推广一套通用模式,Schema.org有一套专为图书馆书目数据设计的扩展版SchemaBibEX),其步骤是利用MARC2BIBFRAME工具将MARC数据转换为BIBFRAME格式,再利用SPARQL构造检索式从BIBFRAME格式转换为Schema.org。
2.2.2 规范文档的整合与关联数据化应用。德国国家图书馆作为BIBFRAME1.0时代就参与实施的成员之一,它致力于以BIBFRAME格式实现全部在线书目数据的关联数据发布,在BIBFRAME 1.0时代德国国家图书馆就持续将该馆数据从Pica+(荷兰图书馆自动化中心,一种元数据格式)转换为BIBFRAME。该图书馆重点关注整合规范文档(主要是德语系)的建设及关联数据的应用。作为德语系国家BIBFRAME的积极倡导者,德国国家图书馆广泛召集其他图书馆、博物馆、档案馆等机构共同参与规范文档的建设,并且协同各机构提供关联数据服务,目前,德国国家图书馆已经实现了人物名称、地理名称、作品、机构、会议、专业术语方面的整合,共有 1 500 万条记录。在建设过程中,德国国家图书馆建立了规范文档(主要是德语系)本体、自定义的RDF元素集复用了现有词表中的一些元素,使两者之间具有映射关系,给本体中的实例赋予一个URI,通过RDF三元组实现链接。
2.2.3 创建BIBFRAME2.0的联合目录系统。2012年,瑞典国家图书馆启动了LibrisXL系统,该系统以BIBFRAME2.0模型为核心,参考美国国会图书馆的映射方案,采用KBV词表自建本体,可以说 LibrisXL系统是首个正式使用基于BIBFRAME2.0的联合目录系统。该系统可以使万维网理解图书馆的书目信息,各搜索引擎和Wikidata也可以更直接地引用和参考LibrisXL的书目数据,这使图书馆的书目信息真正搭上了互联网,创建了访问利用图书馆书目的新途径。另一方面,图书馆也可以利用关联数据链接到其他文化机构领域,引用其他的关联数据集来完善自身目录。
2.3 其他国家BIBFRAME的发展领域
2.3.1 古巴何塞·马蒂国家图书馆。2014年,古巴开始实施国家数字图书馆计划,参与此项工作的机构和单位包括古巴何塞·马蒂国家图书馆、古巴历史协会、古巴国家档案馆、古巴语言文学协会、古巴艺术公司、美洲之家、古巴国务委员会历史事务办公室等。该计划旨在建立一个能与互联网相连接的国家数字图书馆,通过该网络将古巴全国所有的图书馆和重要机构连接在一起,实现资源共享。
由于古巴何塞·马蒂国家图书馆的OPAC系统只收录了1998年以后的书目信息,1998年以前的仍保留在卡片式目录中。因此,该馆的BIBFRAME之路将分为两部分,对于1998年以后的书目信息,古巴何塞·马蒂国家图书馆利用美国国会图书馆提供的BIBFRAME转换器,将现有的MARC格式转化为BIBFRAME格式,而对于存放在卡片目录中的书目信息,该馆首先将卡片目录数字化,创建一个虚拟的卡片图像目录或CIPAC(卡片图像公共检索目录),基于BIBFRAME1.0的模型,古巴何塞·马蒂国家图书馆将这些卡片图像作为注释类来进行处理,即BIBFRAME1.0模型中注释类的封面艺术属性,这将探索出一条可将卡片式目录跨越式转化为BIBFRAME格式之路。
2.3.2 埃及亚历山大图书馆。埃及亚历山大图书馆作为中东最大的阿拉伯语图书馆之一,宗旨是成为生产和传播知识的中心,并成为不同文化和民族之间对话和理解的场所。该馆联合美国国会图书馆共同开发阿拉伯语的BIBFRAME转换器,使大量阿拉伯语的书籍、古籍珍本、手稿、地图的MARC格式转换为BIBFRAME格式。
2.4 BIBFRAME官方最新进展
2021年6月28日,美国图书馆协会夏季年会召开BIBFRAME更新论坛,披露了BIBFRAME的最新进展。
首先是BIBFRAME 100的进展。在2021年1月24日召开的冬季会议上,美国国会图书馆宣布“BIBFRAME 100”计划,即从2021年开始,将原来“100名编目员,每周2天使用BIBFRAME编目”提升为“全部350名编目员,每周5天使用BIBFRAME编目”,但夏季论坛将目标调整为“成功达成80%—90%的编目员使用BIBFRAME编目”。
其次是介绍接下来的重要任务:1)使系统更加强壮,将关联数据平台MarkLoqic 8升级至MarkLoqic 10,合并内部BFDB和外部ID两个分支数据库,这项任务预计在2021年7月底到8月初完成。2)重新开发编辑器,2021年4月将切换至新的BIBFRAME编辑器,并在6月分发给所有参与测试的伙伴。3)继续优化BIBFRAME与MARC之间的双向转换。4)一些其他主要任务,如协调MARC的题名规范和BIBFRAME Hubs,默认新增Hub类为Work(作品)的子类,发布了BIBFRAME本体的2.1版本。
3 国内对BIBFRAME的研究和应用情况
国内关于BIBFRAME在应用领域的研究主要集中在基于BIBFRAME本设计和构建,正式落地实施的项目较少,仅有上海图书馆的家谱知识服务平台和华东师范大学数字方志集成平台建成并开放使用。
3.1 基于BIBFRAME2.0的高校科研数据的本体构建
我国高校的科研数据管理和共享平台建设正处于起步阶段。崔旭、赵希梅认为各个平台和研究机构之间还未形成一套行之有效的协调合作机制。邢文明、刘兹恒认为各平台的元数据标准不一致,使不同学科的数据格式难以统一,数据处理和组织规范化还有待加强。朱玲、聂华认为各平台、各机构之间的数据关联程度不高,缺乏对数据的深度揭示,数据关联价值未能充分体现。由此看来,高校科研机构的相关学者对科研数据平台在使用中的不足之处已有关注。
关联数据在知识发现、规范控制和资源关联方面有着独特优势,可以完善高校科研数据平台在这方面的不足。司莉在对科研数据本体描述规范以及BIBFRAME模型研究的基础上,提出基于BIBFRAME的类和属性对科研数据进行本体构建的思路,利用本体建模方法,通过手工方式实现科研数据共享平台元数据与BIBFRAME2.0的类和属性进行映射和转换,通过关联数据形式为数据添加语义层,构建RDF形式的语义数据存储库。
3.2 基于BIBFRAME2.0的档案类资源本体构建
档案类的资源大多以汇集资料的形式存在,档案资源的描述不仅仅是内容和载体,还要揭示档案之间的级结构关系,这是档案本体构建中的重要内容之一。苗青、许磊等以复旦大学图书馆藏当代中国社会生活资料为例,对档案领域的OAD本体(Ontology for Archial Description,档案描述本体)和EAC-CPF本体(与档案有关的人、机构和家族的本体)进行研究,发现这两种本体模型可以全面描述档案的属性特征并且揭示其层级关系,但是应用场景不够宽泛,不能兼容对其他类型资源的描述,如图书、影像资料等,认为BIBFRAME更具有通用性,既有对资源通用属性的定义,也有对档案类资料特有的属性定义,最终选择以BIBFRAME2.0为基础,引入OAD本体中的部分语义词构建适合档案类的本体模型,从人物、地点/地理位置、时间/空间、事件、物品等多角度揭示资源特征,以关联数据方式整合馆藏档案资源,为学者研究提供支持。
3.3 基于BIBFRAME2.0的书信本体构建
书信是在通讯不发达时代人们之间表达情感、沟通交流的必备工具,写信人在书信中会记录一写当时事件、生活细节、社会面貌,甚至表达一些看法,特别是名人书信,具有可靠的史料价值,是绝佳的历史佐证材料。但是,大多数名人的书信都散落在民间收藏者或者机构中,许多并没有正式出版,一些有条件的研究机构将所藏名人书信进行数字化,只能简单检索,查阅起来不方便。为了实现书信资源的数字化保存与快速查找,挖掘书信资源中的信息和关联,刘荣江、肖明结合书信本体中应包含的类和属性,复用BIBFRAME2.0模型和词表中适合书信资源的类和属性,用Protégé软件为古文献学家王重民的相关书信建立了书信本体,使用Neo4j图数据存储书信本体以及可视化查询。但该本体仅有选取王重民相关书信的单一数据,数据量还不够大,后续需要补充更多类别的书信资料来验证该模型的可行性。
3.4 上海图书馆家谱知识服务平台
2014年底,上海图书馆发布了中国家谱知识服务平台(https:∥jiapu.library.sh.cn)。该平台以《中国家谱总目》收录的、包含608个姓氏的,来自中国香港、澳门、台湾地区和日本、韩国、德国等国家的收藏机构所藏的5.4万余种家谱目录为基础,析出姓氏608个,先祖名人7万余个,谱籍地名 1 600 余个,堂号3万余个,以关联数据技术为基础,设计BIBFRAME家谱本体,提取姓氏、人、地、时、机构等实体并赋予URI,将CRMARC转换为BIBFRAME格式。
该平台有以下特点:1)建立全球家谱联合目录。用户可以直观地了解某一家谱在全球各个收藏机构的收藏情况,同时,在上海图书馆开放数据平台上以LOD(关联开放数据)的方式公开发布整理的规范数据,如中国历史纪年表、地理名词表、机构名录,促进数据的重用和共享。2)基于万维网的规范控制。该平台利用关联数据技术,使用URI作为规范数据的唯一标识符,实现基于万维网的唯一标识和统一定位。3)支持书目控制的可持续发展。该平台不仅是一个展示系统,还是一个可写的、支持众包的平台,可以开放给相关经过认证的专家学者、社会团体登录该平台,修改、发布新的知识,发现数据冲突和错漏时及时修改,保证家谱书目控制的可持续发展。
3.5 华东师范大学数字方志集成平台
华东师范大学开发的数字方志集成平台以异构数字方志数据为基础,力求为人文学者提供统一的数据资源管理、大数据分析、可视化展示和智慧型服务的人文研究环境建设思路。
传统的数据库仅仅是储存资源,而数字方志集成平台基于BIBFRAME2.0书目数据模型的“作品—实例—单件”三层结构设计方志本体模型,底层数据应用关联数据技术,将方志资源中的数据、事实和其他知识点进行细粒度描述,并重组方志书目数据,在万维网上提供一致、开放和标准的开放数据服务,充分与互联网上的数据关联、融合。例如,通过作者可以关联开放的人物传记资料库,不仅在检索过程中按需求实现外部数据对本地数据库的有效补充,还通过可视化展示,将生动的图谱展现出来,极大地丰富了知识发现的角度,使数据真正“活了起来”。目前,该平台已完成一期建设,即将开启二期建设。
4 BIBFRAME在中国应用前景的思考
BIBFRAME诞生的初衷就是为了取代MARC成为新的书目数据格式,因为它满足关联数据时代的资源描述特征,使书目数据能够融入互联网环境,发挥其价值,避免图书馆成为“信息孤岛”,自其发布以来,就受到了业内的广泛专注。各国在选择实施的方向上也有所不同,目前,BIBFRAME项目尚未结束,BIBFRAME2.0并不是其最终版本,截至目前,LC官方在BIBFRAME开发进程中已经制订了新的任务,一些策略、技术和工作流程都在不断改善中,如重新开发BIBFRAME编辑器以及后续大量的测试,词表中一些类和属性的删减,新本体的发布等。虽然LC在2021年1月的冬季会议推出“BIBFRAME 100”计划,即“全部350名编目员,每周5天使用BIBFRAME编目”,但在不到半年后的夏季论坛上将目标调整为“成功达成80%—90%的编目员使用BIBFRAME编目”,这说明BIBFRAME的整体进展是比较缓慢的。此外,从我国的BIBFRAME应用研究进展中可以看出,国内研究人员主要选择部分馆藏文献或者某一主题数据库,采用BIBFRAME的模型初步构建资源本体,如上海图书馆和华东师范大学更是成功构建了家谱平台和方志平台的示范性项目并开放使用,这是国内图书馆“智慧服务”领域突破性的探索和尝试。BIBFRAME相较于MARC而言,优势明显,前景广阔,但未来它在中国的本土化进程中,无论是从技术上还是人们对新事物接受程度上来说,都还有很长一段路要走。
