基于 K-Means 聚类算法的城市轨道交通站点分类及客流特征分析
2021-04-22盖靖元
夏 雪,盖靖元
(1. 沈阳市规划设计研究院有限公司,辽宁沈阳 110004;2. 辽宁省交通运输事业发展中心,辽宁沈阳 110005)
1 研究背景
城市轨道交通因其运量大、速度快、准时、安全等特点,对满足高峰时段集聚的出行需求、缓解道路拥堵、节能减排有着不可估量的作用。截至2020年6月30日,中国内地开通城市轨道交通的城市已有41个,运营线路总长度为6 917.62 km[1]。城市轨道交通建设正处于突飞猛进的发展时期,而交通站点作为联结周边城市空间的重要节点[2],其分类对于研究不同类型站点的周边土地利用差异、客流变化规律、城市空间布局优化、新线路站点客流预测等都有着非常重要的作用。
国内已有部分学者对城市轨道交通站点分类开展研究。例如:徐威、郑长江等人[3]采用K-Means聚类算法将苏州市轨道交通站点分为一般站、商业区站、交通接驳站、居住区站、综合交通枢纽站5类;李国强、杨敏等人[4]利用站点客流数据和兴趣点(POI)数据将南京市轨道交通站点分为居住密集型、岗位密集型、混合型和枢纽型4类;邓评心、郑长江等人[5]采用主成分分析、多元线性回归等方法,定性和定量相结合的方式将城市轨道交通站点分为4类。但部分学者[3-12]在进行城市轨道交通站点分类时受数据来源的限制,对站点聚类因素的考虑相对有限。
本文以沈阳市已开通的3条城市轨道交通线路(截止到2020年4月分别为1号、2号和9号线),共67个站点(其中9号线皇姑屯站尚未开放)为例,从人口分布、开发强度、公交接驳、路网长度分布、站点位置属性、站点客流数据六大维度进行聚类分析;基于站点聚类成果,叠合多样化数据,分析总结出各类站点客流的普适性规律,为后续站点的周边基础设施完善、站点客流预测、车站运营组织方案做出指导。
2 基于K-Means聚类算法的站点分类研究
2.1 K-Means 聚类算法
K 均值聚类算法(K-Means clustering algorithm)是一种迭代求解的聚类分析算法,通过逐次更新各聚类中心的值,通过迭代得到最理想的聚类结果。K-Means是聚类算法中最常用的一种,其最大的特点是简单、易理解、运算速度快,适用于连续型的数据。本次聚类拟采用的数据以连续型数据为主,适用于K-Means聚类算法。具体算法步骤[13]如下:
(1)选取K个对象作为初始的聚类中心;
(2)计算每个对象与各初始聚类中心之间的距离,将其划分至距离最近的聚类中;
(3)全部对象被分配后,重新计算每个聚类的聚类中心,重复进行对象分配,直至满足终止条件。
2.2 聚类因素选取和数值标准化
2.2.1 选取原则
选取城市轨道交通站点聚类因素基于以下原则。
(1)明确城市轨道交通站点的影响范围,是因素数值标准化的前提。
(2)城市轨道交通站点作为城市交通网络的重要节点,受现状条件与地理位置的影响,站点在区域内承担不同的作用并呈现出差异化特征,选取的因素应能够反映站点在网络中的位置特征。
(3)城市轨道交通作为居民出行的方式之一,其吸引力取决于站点周边的开发业态、开发强度、接驳设施、路网可达性等,选取的因素应能够反映站点周边各类设施的服务水平。
(4)选取的因素应能够反映站点自身特性,如早晚高峰进出客流量或客流比例等。
2.2.2 聚类因素选取
根据《城市轨道沿线地区规划设计导则》[14],本文以站点周边800 m的区域作为城市轨道交通站点影响区,同时综合考虑因素的选取原则,选定如下六大类数据作为站点聚类分析的变量因素。
(1)基于社区的人口分布数据。本文基于沈阳市现状街道社区人口数据,通过ArcGIS软件,叠加人口数据与城市轨道交通站点800 m覆盖范围生成站点覆盖的人口分布数据。
(2)基于兴趣点(POI)的开发强度数据。POI数据一般包含数据名称、地址、经纬度等信息,具有更新速度快、数据来源可靠等优势。由于缺乏详细的土地利用及岗位数据,本文基于高德地图的POI数据,分别选取餐饮、购物、教育、金融、医疗、公司企业、政府办公7类数据代表城市轨道交通站点周边的开发强度或岗位分布水平,如表1所示。
(3)基于POI的公交站点数据。本文利用高德地图的POI数据,统计出城市轨道交通站点800 m范围内的公交站点数量,用以表征站点周边公交接驳换乘水平。
(4)基于地理信息系统(GIS)的路网长度数据。站点范围内的路网长度是对城市轨道交通站点可达性的体现。一般来说,站点周边道路网长度越长,在一定程度上体现的站点周边路网体系越完善,站点可达性越高。本文利用沈阳市道路交通网GIS数据,统计出站点800 m范围内的道路网长度。
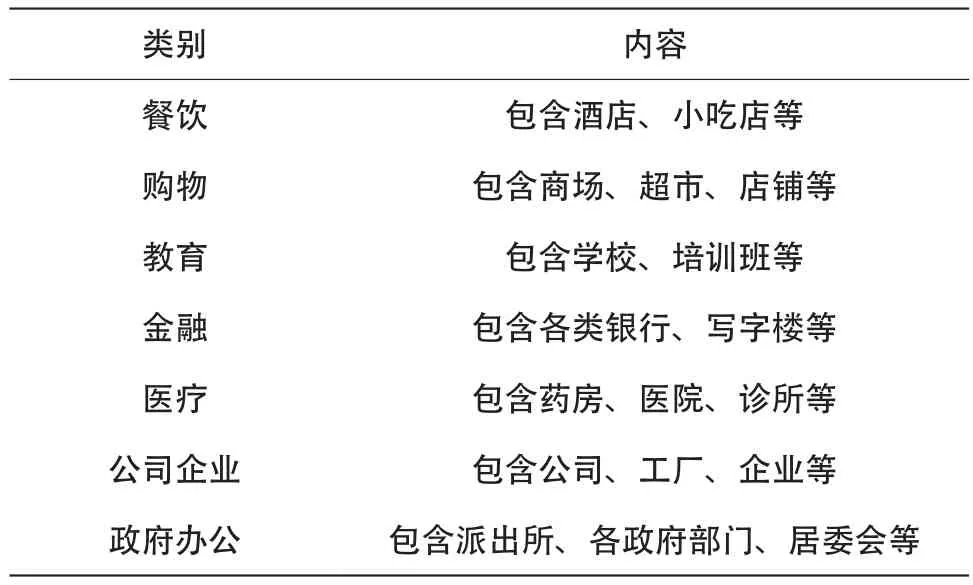
表1 基于POI数据的开发强度一览表
(5)基于三层维度的站点位置数据。城市轨道交通站点所处区位对站点周边空间的开发规模、开发业态及交通设施配套产生较大影响。本文分别从站点在城市空间、轨道线网、城市交通网3个维度入手,对站点的位置属性进行赋值。其中:城市空间位置依据沈阳市四环的城市空间结构中心开发强度高、外围开发强度较为滞后的特点,将站点区位分为1、2、3、4四个等级,数字分别代表站点处于几环内;轨道线网位置依据站点在轨道线网中的位置,将站点分为终点站、换乘站、一般站3类,分别用1、2、3进行赋值;城市交通网位置将800 m覆盖范围存在铁路、大型公交换乘枢纽的站点定义为交通枢纽站,赋值1,其他站则为0。
(6)基于城市轨道交通自动售检票系统(AFC)的站点客流数据。AFC通过记录乘客进出站时间、站点编号等信息,分析出各站点全天不同时段上下客流信息。本文以AFC客流数据为依据,分别选取早高峰/晚高峰进站客流占全天进站客流比例、早高峰/晚高峰出站客流占全天出站客流比例共4项数据作为站点差异化的客流特征。
综合以上,本次共选取六大类数据、17个具体因素作为站点聚类分析的初始输入要素,如表2所示。
2.2.3 聚类因素数值标准化
不同评价指标具有不同的量纲,会影响数据分析的结果,为消除指标之间的量纲影响,需要进行数据标准化处理[3],以解决数据指标之间的可比性。本文采用Z-score方法进行数值标准化处理,即将每一变量值与其平均值之差除以该变量的标准差,标准化后各变量的平均值为0,标准差为1,从而消除了量纲和数量级的影响。

表2 站点聚类因素一览表
2.2.4 因子分析
在聚类分析中,选取的因素较多,虽然能够增加聚类效果的可靠性,但由于指标间经常存在一定的相关性,使得观测数据呈现的信息存在重叠现象。而因子分析是一种从多个变量指标中选择出少数几个综合变量指标的多元降维统计方法,能够消除相关因素信息重叠的影响[15]。
本文将17个因素的标准化数值进行因子分析,利用统计产品与服务解决方案(SPSS)软件计算得到KMO(Kaiser-Meyer-Olkin)和巴特利特球度检验结果。其中,KMO=0.846,处于0.8~0.9之间;巴特利特球度检验结果显著性= 0,小于0.05,说明因素之间存在很大程度的相关性,适合进行因子分析。通过因子分析,从17个因素中提取出3个公共因子作为K-Means聚类算法的输入变量。结合实际情况,最终选取K值为5类时的聚类结果作为沈阳市轨道交通站点分类结果。
2.3 沈阳市轨道交通站点分类结果
根据聚类结果将站点划分为居住型、商业商务型、综合开发型、产业型、交通枢纽型五大类,如图1所示。
(1)居住型。共40个站点,主要体现为站点覆盖人口较多,用地业态以餐饮、购物、教育等生活型服务为主,早高峰进站比例明显高于出站比例。
(2)商业商务型。共11个站点,主要体现为用地业态中生活型服务和岗位型服务较为丰富,早高峰出站比例明显高于进站比例。
(3)综合开发型。共5个站点,主要体现为站点人口覆盖密集(800 m覆盖人口在3万人以上),生活型服务和生产性服务较为丰富,处于二环核心区以内,高峰时段进出比例较为均衡。
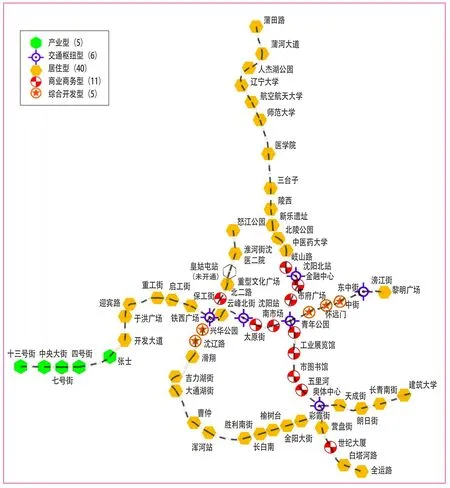
图1 沈阳市轨道交通站点分类
(4)产业型。共5个站点,主要体现为站点覆盖人口少,周边用地业态以公司企业和工厂等岗位型服务为主,处于外围环路,公交站点分布较少,早高峰出站比例明显高于进站比例。
(5)交通枢纽型。共6个站点,包含城市轨道交通换乘站、铁路枢纽站和公交枢纽站,该类站点生活型服务较为丰富,高峰时段进出比例较为均衡。
3 基于站点分类的客流特征分析
3.1 居住型站点客流特征分析
(1)居住型站点高峰时段进出站比例受站点覆盖人口影响较小,基本稳定在一个区间。居住型站点早高峰进站比例集中在12%~25%之间,出站比例集中在5%~12%之间,早高峰进站比例明显高于出站,这与居住型站点早高峰居民高强度通勤出行需求有关,如图 2 所示。晚高峰时段受各单位通勤时间的差异、居民休闲娱乐需求的影响,晚高峰进出站比例较早高峰低,出站比例略高于进站比例(出站比例集中在8%~14%之间,进站比例集中在4%~10%之间),如图3所示。
(2)早高峰进站量和晚高峰出站量与居住型站点覆盖人口成正比关系,如图4所示。对早高峰进站量、晚高峰出站量与覆盖人口进行比值分析,发现其比值主要在一个区间内浮动,早高峰进站量与人口的比值集中在5%~15%之间,晚高峰出站量与人口的比值集中在0~10%之间,如图5所示。
3.2 商业商务型站点

图2 居住型站点早高峰进出站客流比例与站点覆盖

图3 居住型站点晚高峰进出站客流比例与站点覆盖
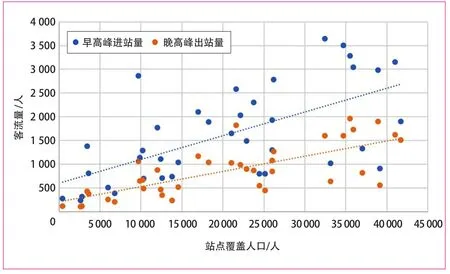
图4 居住型站点早高峰进站量、晚高峰出站量与站点覆盖人口关系
(1)商业商务型站点早高峰出站比例和晚高峰进站比例是一天中的峰值。商业商务型站点因站点周边公司企业、办公等岗位型用地较多,早高峰出站比例和晚高峰进站比例是一天中的峰值,其中早高峰出站比例主要集中在12%~20%之间,晚高峰进站比例主要集中在10%~15%之间,如图6所示。
(2)站点周边POI点位越多,早高峰出站客流占比相对更大。由于岗位型POI点位数量仅显示周边公司企业数量,未能直接计算岗位的规模和数量,因此只能初步表示岗位的密集程度。对岗位型POI点位和客流比例进行叠加分析发现,如图6所示,站点周边POI点位越多,早高峰出站客流比例相对更大,在一定程度上能够为今后站点客流预测作一定参考。
3.3 综合开发型站点
综合开发型站点的定位为周边各类生活型和岗位型服务设施丰富、人口密集、处于核心区、道路可达性强、公交接驳水平高的站点,如表3所示。该类站点早晚高峰的进、出站比例较为接近,集中在8%~13%之间,未体现出明显的高低差距,这与站点周边用地开发种类丰富,客流产生量和吸引量都较高有关,如图7所示。
3.4 产业型站点
产业型站点的定位为站点800 m范围内覆盖人口少,周边用地业态以公司企业或工厂等岗位型设施为主,处于外围环路,如表4所示。通常而言,受岗位型用地强客流吸引力影响,产业型站点应体现出早高峰出站比例远大于进站比例的情况。但本次归类的产业型站点情况比较特殊,该类产业型站点位于外围的经济技术开发区,800 m范围内以公司企业为主,800~2 000 m内存在大量的住宅小区。受经济技术开发区与主城区之间常规公交、道路等设施不足的限制,较多的住宅小区居民倾向于高峰时段通过公交、慢行接驳等方式到达地铁进行出行,导致本次分类的产业型站点呈现早晚高峰进站和出站比例相差不大的现象,如图8所示。因此,外围站点因周边交通设施不便,在分析或预测站点产生吸引客流量时应扩大站点辐射范围,将接驳客流量也纳入考量。

图5 居住型站点早高峰进站量、晚高峰出站量与站点覆盖人口比例
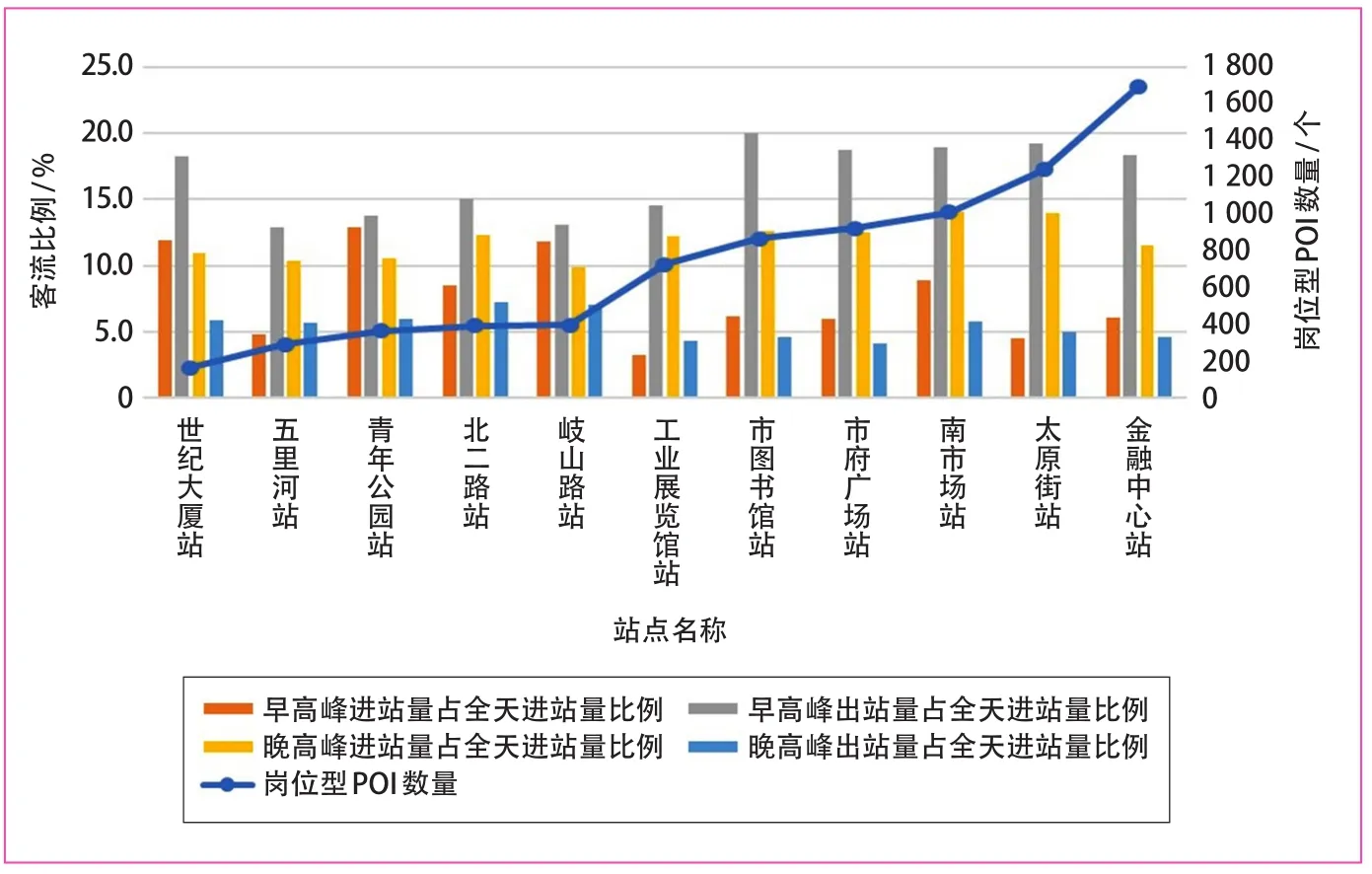
图6 商业商务型站点客流特征
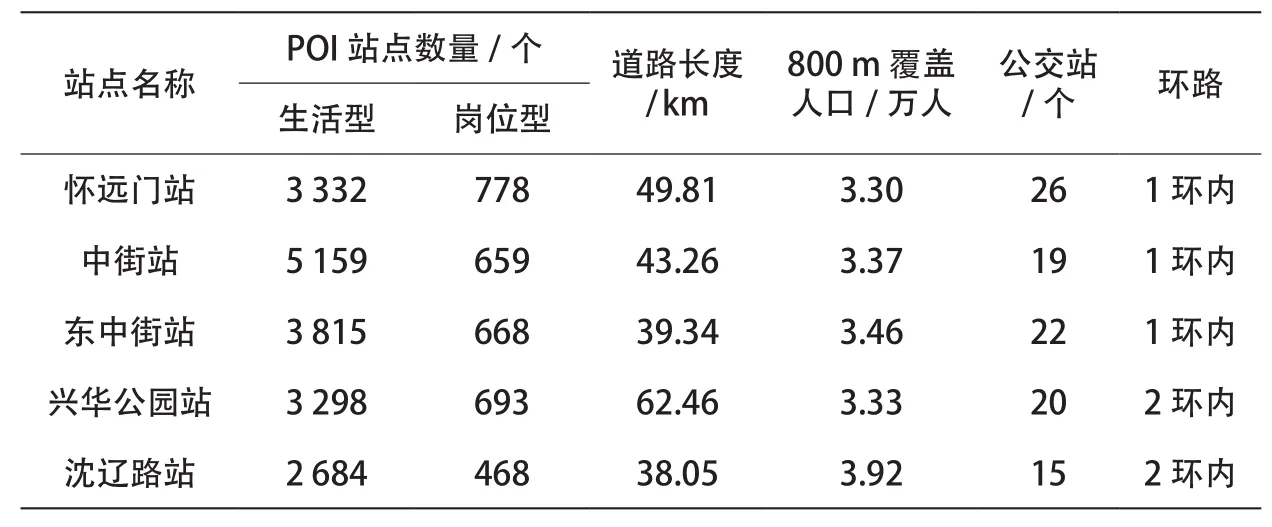
表3 综合开发型站点周边设施表

图7 综合开发型站点客流特征

表4 产业型站点周边设施表

图8 产业型站点客流特征
3.5 交通枢纽型站点
枢纽型站点进出站客流不但受周边用地布局的影响,还受接驳客流的影响。由于对外交通枢纽站(机场、火车站等)客流出行时间分布上较为分散,与通勤早晚高峰重叠度较低,因此该类站点早晚高峰客流特征受接驳客流影响较小,而换乘站则相反,受接驳客流影响较大。
由此次分类的交通枢纽型站点可以看出,如图9所示,沈阳站、沈阳北站2个铁路枢纽站早晚高峰进出站客流占比存在较大差异,其中沈阳站紧邻太原街商圈、沈阳北站紧邻北站金融商贸区,两者在客流特征上更接近商业商务型站点。青年大街、铁西广场、奥体中心作为地铁线路的换乘站,滂江街作为公交与地铁的换乘站,其早晚高峰进出站客流所占比例接近。
4 结语
本文结合AFC、POI、ArcGIS等多样化数据采集方式,从人口分布、开发强度、公交接驳、路网长度分布、站点位置属性、站点客流数据六大维度入手,多源融合选取了17个站点聚类因素;通过K-Means聚类算法,将沈阳市现状3 条城市轨道交通线路67个站点划分为居住型、商业商务型、综合开发型、产业型、交通枢纽型五大类;在站点分类的基础上,融合人口、POI点位等数据对站点早晚高峰时段的客流特征进行叠加分析,总结出沈阳市各类站点高峰进出站客流普适性规律,可为后续站点周边基础设施完善、站点客流预测、车站运营组织方案做出指导。
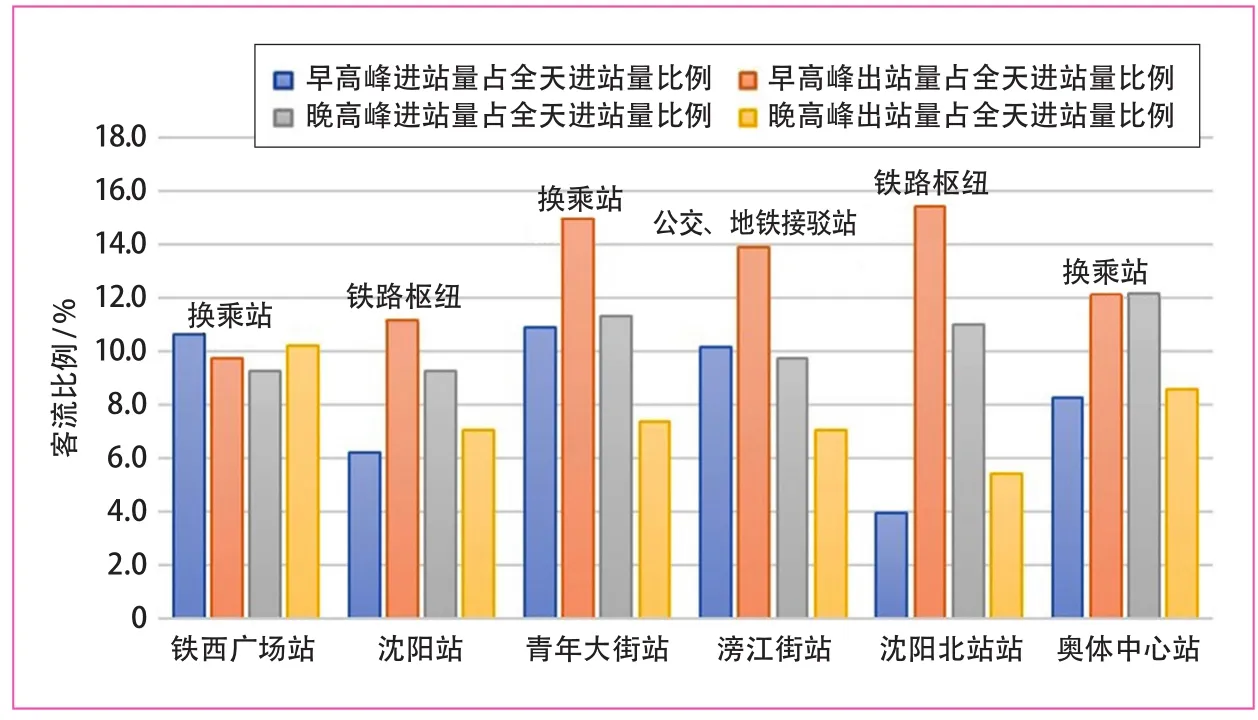
图9 交通枢纽型站点客流特征
