空间飞行器控制软件的动态自适应演化方法
2021-04-22李青山廉宗民谢生龙
李青山, 廉宗民, 王 璐, 谢生龙,3
1. 西安电子科技大学计算机科学与技术学院, 西安 710071 2. 西安电子科技大学广州研究院, 广州 510555 3. 延安大学数学与计算机科学学院, 延安 716000
0 引 言
现代航天器控制系统有两个显著特点:其对象中存在着大量结构和参数的变化, 造成对象模型的复杂性和不确定性;对控制任务的要求越来越高.因此,满足控制任务要求的最有效途径是使之具备智能自主运行的能力.航天器的自主运行具有可以增加容量、安全性、可靠性、效率和节省费用的特点[1].在当前研究中,空间飞行器在太空中执行任务时需要面对两个问题:(1)资源受限.资源主要分为两种:计算资源和系统资源.计算资源主要是指空间飞行器所携带的计算机资源,包括CPU运算能力、内存资源、硬盘资源、网络宽带资源以及计算机冗余设备与运算环境重构能力等.系统资源主要是指空间飞行器为了完成预定任务,而配备的各类测量敏感器,执行机构,能源组件,有效载荷组件等,需要考虑其数量、安装、冗余备份与组合应用的关系,以及其实时运行的加电、通信、有效性等状态信息.(2)环境影响.环境分为外部环境和内部环境.外部环境是指太空中,对空间飞行器运行及任务执行,直接或者间接产生影响的环境因素.需要考虑天体引力摄动,空间辐射,飞行合作目标及敌方飞行器、空间碎片、不明飞行器等非合作目标的方位.内部环境是指软件系统所处的物理环境,例如CPU、存储器、运行状态和内部参数的变化[2].空间飞行器所处的飞行环境复杂,人工干预难度大,而传统的,现有的自适应演化方法并不一定适合空间飞行器控制软件的自主控制.所以在资源受限的情况下,航天器控制系统软件如何在太空中完成可靠的动态自适应演化是亟待解决的问题.
为了满足空间飞行器控制软件的动态演化需求,本文在3层感知—分析—决策—执行(MAPE)[3]的控制循环的自适应框架的基础上提出3层控制框架,使用基于策略/规则的决策方法和基于强化学习的决策方法完成自适应决策,并加入基于数据驱动的反馈优化方法,实现了空间飞行器控制系统软件在太空作业过程中进行可靠的动态演化.本文中提出的空间飞行器控制软件的框架上下2层均具备有完整的MAPE环节,底层逻辑使用基于策略/规则的自适应决策方法实现系统的快速决策.上层使用基于强化学习的自适应决策方法,进行全局调整并处理未知的上下文情况,完成在线决策.中间层反馈优化Agent实现周期性的数据挖掘,保障策略库的实时性和可靠性.
系统执行的动作是软件系统通过感知、分析环节,获取到具体的自适应事件的信息,而后决策环节为软件系统制定出最符合当前需求的自适应策略,并指导软件系统对自身或者上下文进行调整[4].目前,国内外提出的自适应决策方法主要分为方案选择和状态迁移两种.方案选择主要包括4种算法:(1)基于规则/策略的方法,根据事件信息,选择能够处理这种事件的规则/决策,效率高[5].(2)基于目标的自适应决策方法[6].(3)基于效用函数的决策方法,根据系统效用选择出最优决策[7].(4)基于启发式的决策方法,这些启发式算法会结合强化学习、决策树等修正搜索方向[8].状态迁移具体方法包括:马尔科夫决策过程(Markov decision process, MDP)[9]、采用强化学习算法提供自主决策能力[10]、基于贝叶斯网络的决策方法[11]等.因此,本文在功能Agent中采用基于规则/策略的决策方法,在降低了资源占用的同时,实现了针对事件信息的快速反应;上层逻辑则采用了基于强化学习的自适应决策方法,通过在线学习的方式,解决未知的上下文信息的问题,在线生成策略信息.
基于数据驱动的反馈优化的方式在诸多领域都有着广泛的研究和应用.目前较多依赖于机器学习技术[12]和基于偏好的反馈优化技术[13].而随着深度学习的成熟,各种方法也逐渐应用其中.例如,ELBERZHAGER等[14]结合人类因素在软件工程中影响的思想,提出了基于用户反馈的优化的框架.LI等[15]通过利用反馈优化的方式实现神经网络算法,解决实际追踪应用中的不确定性难题.许相莉等人将粒子群优化算法与用户反馈结合,提出基于粒子群的反馈算法[16].韩嘉祎等[17]在Apriori算法的基础上提出FP Growth算法,他们通过构造FP树来对频繁集构造路径,该算法的只需要对数据库进行2次检索,算法效率显著提升.GEOFFRE等[18]提出的深度信念网络(deep belief network, DBN)是一个概率生成模型,用于观察数据和标签之间的联合分布.本文通过使用基于关联规则的数据挖掘算法作为反馈优化的核心,执行结果通过感知传送到反馈优化模块,进行数据挖掘,对系统运行过程中产生的数据结果进行周期性挖掘,并更新策略库,保证策略执行的可靠性.基于此,该框架保障了空间飞行器控制软件在太空中完成可靠的自适应演化.
1 自适应软件系统介绍
自适应软件系统是通过构建自适应机制实现的,系统在运行过程中可以自主调整系统自身的参数、行为或者结构,从而动态适应系统运行时发生的各类变化[19-20].所以自适应软件的重点是实现自适应机制.具有自适应能力的软件系统可以通过感知外部环境或者内部环境的变化,对当前感知到的事件信息进行分析,做出符合当前需求的决策,进行自身系统的调整,实现系统中既定功能和非功能性的任务,完成自主演化.
1.1 自适应机制的设计
软件系统在执行任务过程中,需要根据环境的变化、用户的需求以及当前资源情况实现调整,所以需要保证系统在运行过程中,不但可以平稳的运行,还需要有效的实现既定的功能性和非功能性的目标,所以软件系统需要实现一种自适应机制对上述内容进行保障.
(1)基于体系结构的方法
该类方法就是以体系结构为中心,将其应用在自适应机制中.Rainbow框架是最著名框架之一,它将自适应软件系统分为体系结构层和管理系统层,管理系统层实现自适应机制控制的调整[21].马晓星等[22]设计了一种在分布式环境下,使用内置运行时体系结构,来保证系统具有自适应能力.
(2)基于需求工程的方法
BERRY[23]提出自适应系统需要建立4个层次的需求工程方法.第一层方法主要建立用户或开发者对于目标问题的描述.第二层主要目标是建立支持自适应的需求功能的方式.第三层侧重于在第二层的基础上,描述工程师的对于问题的决策需求.第四层是实现基于需求工程的软件自适应机制.
(3)基于控制论的方法
在该类方法中,软件的自适应将由基本的控制循环完成实现.KEPHART[24]在MAPE的控制循环中建立一个共享的知识环节,与其他4个环节联通,实现了自适应过程.TZIALLAS等[25]提出了基于Bunge本体和Bunge-Wand-Weber(BWW)模型来构建自主计算系统,实现了系统的自我管理和调整.
(4)基于程序范式的方法
基于程序范式的方法是在软件的代码层面借助程序范式,利用编程的方式实现软件系统的自适应控制,运行中对系统自身的结构和参数进行调整.HAESEVOET[26]采用面向切面的编程(aspect-oriented programming, AOP)技术实现软件的自适应.
(5)反射方法
反射是指软件通过感知环境或者用户需求变化,然后调整系统的结构和行为的一种方式.基于反射的自适应机制会通过在运行中获取软件状态信息和环境状态信息,对系统的结构以及上下文信息进行调整.Frank等[27]提出一种基于镜像反射和服务计划的技术来支持自适应系统的开发.ACAR等[28]介绍增量计算的技术,底层系统以动态依赖关系表示数据合控制之间的依赖,实现系统的动态调整.
(6)其他方法[29-34]
除了上述的几种方法外,还有学者从不同的角度出发构建自适应机制.例如,孙跃坤等[33]提出构建组织员模型和动态组机制,实现分布式系统的自适应.MOCTEZUMA等[34]利用基因型-表型作图和概率分布的策略,开发了一种自适应机制来提高遗传算法对动态组合问题的性能.还有部分学者关注自适应系统的中间构件、如何降低软件开发成本等方面研究自适应问题.
1.2 自适应决策方法
(1)基于策略/规则的自适应决策方法
基于策略/规则的决策方法[5]属于基于方案选择思想的自适应决策方法.该类方法在执行前期需要静态定义大量的策略信息,根据自适应事件的信息建立明确的决策目标,然后利用算法,比较分析获得的事件信息对某种候选策略的满足程度,再选择出最优策略.但是这种方法存在一种缺陷,该类方法一般是在离线状态下进行决策,所以在系统运行前需要静态定义所有的候选策略.一旦预定策略出现错误,那么系统的自适应演化结果就会受到影响.因此,目前也存在一些支持策略离线修正的研究工作.例如:有学者采用马尔科夫决策模型和成本效益评估函数实现自适应策略本身的不断修改与进化[29].
(2)基于强化学习的自适应决策方法
强化学习最早由1954年的Minsky提出,是一种实时、在线的学习方法.通过智能体(Agent)以“试错”的方式进行学习,通过环境交互,完成动作后获得奖赏反馈信息的循环,目标是使智能体获得最大的奖赏.强化学习任务通常用MDP来描述.目前很多学者将强化学习引入自适应等领域,用以解决系统的在线学习和策略选择等问题.MIRCEA[30]提出一种基于强化学习的决策树的构建方法,适用于频繁更改训练集且分类规则随时间变化的问题,使系统可以进行更好的自适应调整.文献[31]提出一种基于强化学习的方法,实现系统在线管理体系结构,该方法可以利用经验自动获取环境变化和配置之间的映射实现自我管理.因为在当前开放环境下存在不确定性和复杂性,所以毛新军等[32]提出基于Agent和组织抽象的方法支持开放环境下软件系统的开发,并借助强化学习的方法解决运行中不可预测的情况.
1.3 基于关联规则的反馈优化方法
关联规则算法可以挖掘出数据之间隐含的关系,利用反馈优化方法将分析得到的关联关系反馈给Agent,对策略库进行更新,保障自适应的演化过程.AGRAWAL等[35]于1993年基于频集理论的递推方法提出了关联规则问题.目前关联规则的主要研究方向有:1)基于数据维度的角度,例如:经典的Apriori算法, PARK等[36]提出的DHP算法, 生效于Apriori算法的剪枝过程中,生成每个事务k+1项集,生成Hash表,改变候选集的生成过程;2)基于数据的抽象层次的角度;3)基于概念层次的角度,学者们提出多种善于发现一层或者多层关联信息的算法,例如:HAN等提出的ML-T2L1及其变种ML-T1LA;4)基于变量类别的角度,在该角度下, 关联规则分为布尔型关联规则和多值属性关联规则.SHAPIRO等首先提出多值属性关联规则挖掘问题.其他关联规则算法:并行挖掘关联规则,图像的关联规则发现算法等.
2 控制软件的自适应演化过程
本文提出3层的自适应控制循环,如图1所示.本文在2层MAPE框架[37]的基础上,采用不同的自适应决策方法进行调整,并且增加一层反馈优化层,用于策略信息调整和系统的主动演进.使用该框架可以解决单层自适应框架在运行过程中面对复杂环境变化时,无法更好进行自适应调整的问题.本框架使用基于策略的决策方法处理局部信息,对感知到的事件信息进行快速决策.但是基于策略的方法无法解决未知的上下文信息,所以使用基于强化学习的方法处理全局变化信息,根据事件信息无法匹配到合适策略,进行在线决策,并更新策略库.保证在资源有限的情况下,空间飞行器系统针对内部和外部环境的变化,可以进行更快的自适应调整.并且框架中加入反馈优化Agent模块,系统可以定期根据捕获到的Agent状态,环境情况,软件参数以及最终的动作信息进行数据挖掘,找到存在关联的数据项,进行分析后,反馈到策略库中进行优化,更新策略库中的规则和约束信息,并且可以更新静态定义和在线生成新策略信息中的并不完全合适的条件信息和约束关系.使得飞行器在太空执行任务时,可以根据外界复杂的环境变化和内部的环境变化信息,进行快速的自适应反应和策略调整.
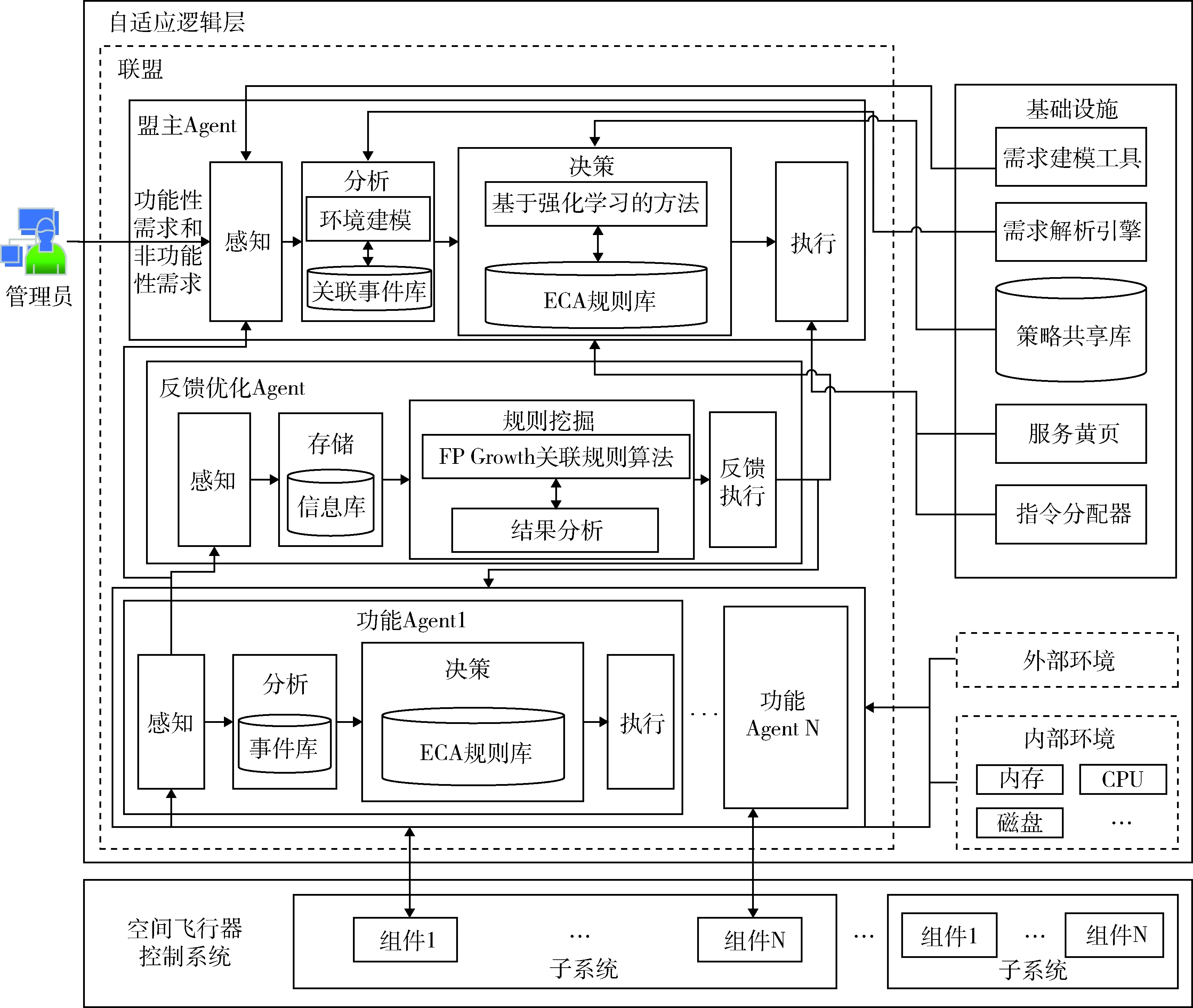
图1 空间飞行器控制软件的自适应框架Fig.1 Adaptive framework of spacecraft control software
面向空间飞行器的自适应框架分为空间飞行器控制系统层和自适应逻辑层.空间飞行器控制层是不具备自适应能力的信息系统,包含信息系统的基本功能,由多个子系统组成,子系统中包含多个组件;自适应逻辑层是使系统实现自适应能力的重要组成,是由盟主Agent、功能Agent以及反馈优化Agent组成的3层控制框架.上层的盟主Agent用于管理系统的全局变化,进行自适应调度和在线策略生成.盟主Agent中包含完整的MAPE控制循环,决策模块包含ECA规则库以及基于强化学习的方法.初始的ECA规则库中包含静态定义的策略,在感知到未知事件信息,无法进行决策时,基于强化学习的方法进行在线决策,并将新生成的决策信息加入ECA规则库中.为了对环境感知到的信息进行决策,分析模块会对环境信息进行建模,分析出事件信息后传递给决策模块.使用基于强化学习的方法进行在线决策生成,降低了系统开销,节省系统资源.并且可以对复杂的运行环境做出及时反应.下层的功能Agent主要用于进行局部调整,该Agent的决策模块主要包含ECA规则库,采用预先定义好的策略库,对分析获取到的事件信息,进行决策.降低了资源占用,并且可以对已知的事件信息做出快速决策反应,实现飞行器的自适应过程.反馈优化Agent感知系统的运行状态、环境信息以及动作执行的状态,并暂时存储在信息库中,当信息库中的数据量达到初始设定的阈值时,再进行关联规则挖掘.规则挖掘模块主要包含FP Growth关联规则挖掘算法以及结果分析,最后得到有效的,精炼的关联信息.因为挖掘得到的结果并不都是有用的,所以在进行结果分析后,选择有效信息进行反馈执行,更新已有的策略库和其中的约束条件信息.
下层的功能Agent使用基于策略的方法可以对空间飞行器系统感知到的局部变化做出快速决策反应,保障飞行器在太空中的任务执行.当上层盟主Agent对全局进行调整,将产生多个决策信息进行选择,然后下层的功能Agent协作执行.当面对未知的上下文状态时,进行在线决策.中层的反馈优化Agent定期对获取到的数据信息进行挖掘,并对结果信息进行分析反馈,保证策略的正确性与实时性,实现空间飞行器系统的动态的可靠的自适应演化.
3 自适应决策与反馈调整的关键技术
3.1 基于策略/规则的自适应决策方法
本文在下层功能Agent中采用ECA规则描述自适应策略,ECA规则语法简单,可以用简洁的语言表述执行过程中策略的触发和执行过程,减少大量的策略解析时间.ECA规则中事件(Event)作为感知环节和分析环节的监控和分析对象.经感知分析环节,对事件相应的策略进行触发,然后将该决策信息的条件(Condition)在下一环节进行比对检测,选取最合适的策略交给执行环节,执行环节实现该策略对应的动作(Action),完成自适应调整.
空间飞行器在太空中执行任务时,将系统状态,环境信息等无法直接观测的信息转化为一组可观测的指标,将系统运行过程中给感知到的环境信息映射为实际的值,映射的信息集合形成实时的系统状态.系统状态S表明一个当前系统可感知到的所有信息转换为指标的数据集,定义为
S={Sid,I},
I={i1,i2,i3,…,in},
其中Sid是系统状态标识,I表示感知到的信息转化得到的指标集合,in是单个属性信息转化得到的指标.
空间飞行器通过感知环境的变化进行自适应调整,将变化信息映射为事件,每个事件都表明一种系统或者环境变化,事件E定义为
E={Eid,Ename,Etype,Econtent,Epriori}
其中Eid为事件的唯一标识,Ename为事件的名称;Etype为事件类型,分为内部变化事件(CPU,硬盘,内存等)和外部变化事件(太阳引力,地心引力,陨石等);Econtent为事件内容,是由感知到的环境信息变换映射到的事件信息,是事件的核心,Epriori表示事件的优先级.
经过感知分析环节,得到事件的信息后触发对应的策略,然后比对该策略的条件信息,Econtent中的条件信息定义为:
Econtent={cid,cname,ctype,cdescription…}
其中,cid为条件的ID信息,cname为条件名,ctype为条件的类型,cdescription为条件的描述信息,还有一些条件的检查对象,运行规则的计算表达式等.
决策环节对决策的条件信息进行核实后,选出最符合满意度的策略,送入执行环节,执行策略对应的动作(Action),动作A定义为:
A={Aid,Aname,Aobject,Atype,Aoperation…}
其中,Aid为 动作的ID信息,Aname为动作名称,Aobject为动作的执行对象,Atype为动作的具体操作类型,Aoperation为具体动作信息,其余动作信息还包括动作的执行条件,也就是上述的对应条件信息等.
一条完整的ECA规则包括事件,条件以及动作信息,并且是一种松散的低耦合的关系,事件、条件以及动作各自定义,然后自由结合,形成完整的ECA规则.所以事件与动作之间的关系会随着系统的需求而动态调整,完成系统在复杂环境下的自适应演化过程.
3.2 基于强化学习的自适应决策方法
本文在盟主Agent中采取基于强化学习的自适应决策方法进行全局变化调整和在线策略学习,该组件处于上层的盟主Agent中,Agent包含基于强化学习的方法和ECA规则库,其中核心为基于强化学习的方法.该方法将强化学习的实时性、在线学习等特点引入到自适应决策方法中,用于发现过期或者规则库中未定义的决策信息.强化学习的基本框架[38]如图2所示.
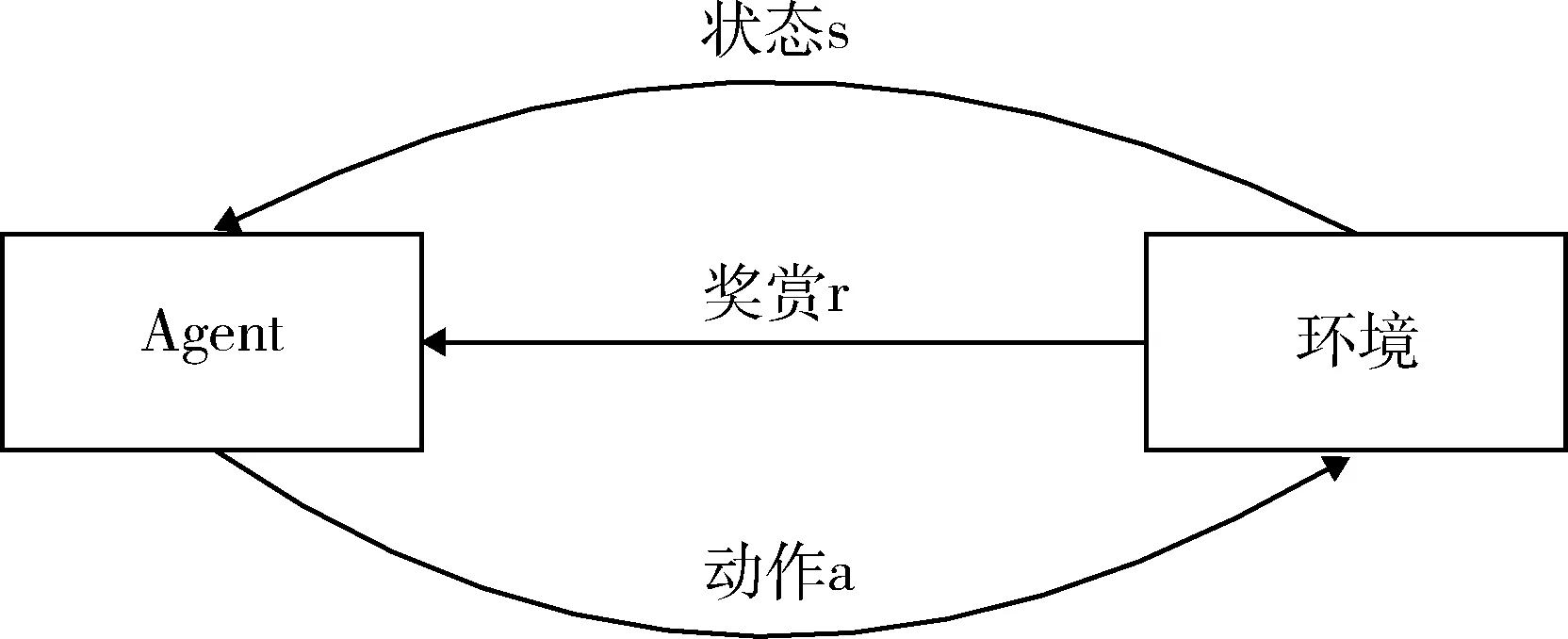
图2 强化学习基本框架Fig.2 Basic framework of reinforcement learning
强化学习过程是一个感知,动作和反馈的重复循环过程.如果Agent的某个尝试动作得到环境的一个正反馈,那么Agent在下次尝试中会趋向于再次选用这个动作.Agent智能体的目标是在每个离散状态下,得到最佳策略,使得期望的折扣奖赏和最大.强化学习的过程是一个重复试探的过程,Agent选择一个a作用于环境,环境接受a后状态s发生变化,同时产生一个r(奖或惩)反馈给Agent,Agent根据反馈信号和环境当前状态s再选择下一个a,选择的原则是使受到正反馈的概率增大.选择的a不仅影响立即反馈值r,而且间接影响环境下一时刻的状态s及最终的反馈值.
Agent智能体作为学习系统,学习过程是通过获取环境的当前状态信息s,并对环境采取试探行为a,然后获取当前环境对于此次试探行为的奖赏r,并更新为新的环境状态信息.如果某动作a导致环境正的反馈信息,那么Agent在试探中就会优先选择该动作;反之,趋势减弱.Agent通过在产生动作和获得的反馈奖赏信息之间不断交互,不断修改从状态到动作的映射策略,最终获得最优策略.所以Agent在线学习一个策略π就是从状态S→奖赏A之间的交互,使得获得的回报值最大.但是Agent采取的动作的长期影响不容忽视,所以需要定义一个目标函数来表明从长久的角度确定什么是优的动作,通常用状态的值函数或状态-动作对的值函数表达此目标函数,函数有以下3种形式:
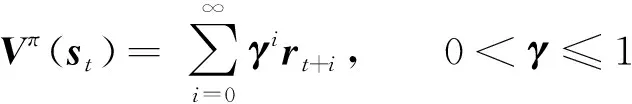
(1)
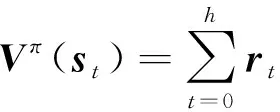
(2)

(3)
其中γ为折扣因子,反映了Agent对未来回报的重视程度,值越大,表示执行该动作得到的回报对Agent越重要.rt是Agent从环境状态st到st+1转移后得到的奖赏值,可以为正、负或零.式(1)是无限折扣模型,是Agent考虑未来的奖赏,以折扣表示,累计在值函数中;式(2)为有限水平回报模型,只考虑未来m步的奖赏和;式(3)为平均奖赏模型,它考虑的是未来长期的平均奖赏.所以确定了目标函数之后,可以根据式(4)确定最优策略.
π*=argmaxVπ(s), ∀s∈S
(4)
强化学习在线策略生成的过程中,根据环境状态s,选择动作a,再获得反馈奖赏r.所以选择生成动作是强化学习的核心要素.目前常用的动作选择策略有ε贪婪策略、Boltzmann分布机制.本文选择ε贪婪策略作为动作选择策略,Agent以ε的概率选择目前已知的最优动作,1-ε随机选择可执行的动作,随着逐渐增大ε值,在保证收敛速度的情况下,也避免了陷入局部最优解的局面.
强化学习通过与环境的交互在线生成策略,可以对复杂环境下的变化信息进行自适应调整.
3.3 基于FP Growth算法的反馈调整技术
控制软件系统在进行反馈优化调整的过程中,可以对感知和收集到的状态信息与决策信息进行挖掘,搜索关联关系以对策略库中的信息进行调整.而传统的Apriori算法和它的优化算法在演算过程中可能会产生大量的候选集.当候选集的长度为1的频集有10000个的时候,长度为2的候选集的数量就会呈指数级的增长,其候选集的数量将会超过107.当生成一个更长的规则时,中间候选集数量会更加庞大.而空间飞行器在独立的空间中进行作业,面临资源受限的情况,所以需要一种比Apriori更节省资源并且速度更快的算法,本文在反馈优化Agent中使用FP Growth算法可以更好的符合这一条件.
FP Growth算法是一种单维的布尔关联规则算法.所以Agent需要对感知到的数据,环境参数,系统状态,硬件变化以及最后执行的动作信息进行映射,映射为离散型的数据量,再进行数据挖掘.FP Growth算法引入FP树构造路径,它采用一种分而治之的策略,读取映射后的事务信息,然后映射到FP树中的一条分支,由于不同的事务会存在相同的元素,所以部分分支可能有重叠,但分支重叠的越多,FP树结构获得的压缩效果越好.第一次读取完数据库后,会产生一棵FP树.随后将产生的FP树分化成一些条件库,每个库和一个长度为1的频集有关,再对这些条件库进行规则挖掘.从而避免重复扫描数据库中的数据,并且候选集数量明显减少,性能相比较传统的Apriori算法要好两个数量级.反馈优化模块的基本的运行流程如下:
(1)感知环节,感知策略执行后的动作信息、系统状态信息以及环境信息,并进行数据处理.
(2)存储处理过后的数据信息,并对当前存储的数据信息量进行计数,当数量到达设置的阈值时,进行数据挖掘的操作.
(3)统计数据集中各个元素出现的次数,将低于最小支持度的元素删除,然后将每条事务信息中的的元素按频数排序,这些元素都是频繁项.
(4)用更新后的数据集,构建FP树,同时更新头指针表.
(5)根据构建的FP树,将其分化为若干个条件库,以长度为1的频繁项为结尾与每个条件库进行关联.
(6)对新生成的条件库进行关联规则挖掘,计算支持度和置信度.
(7)对结果进行处理,保留其中有价值的信息,并分析是否更新规则库中的信息.
通过反馈优化Agent进行数据挖掘后,更新规则库中的信息,使得系统在自适应过程中,面对复杂的环境信息,可以将事件信息与条件进行匹配度更高的比较,可以更加快速的匹配的最合适的策略信息,完成空间飞行器在执行任务时完成可靠的自适应演化.
4 结 论
空间飞行器控制软件在太空中完成自适应演化对人类探索、开发和利用太空意义重大.本文通过引用两种决策方式,对局部和全局变化进行把控调节,并使用一种反馈优化方法进行策略调整.在合理分配资源的基础上,使飞行器完成自适应演化.该方法也可以应用在大规模网构软件下,利用基于数据驱动的反馈优化方法实现自适应系统的主动演化,但是仍需要进行一步研究.作者后续将进一步将软件演化理论和技术应用到自适应演化中,提高航天器控制系统在自适应演化的过程中的可靠性,为航天器进行可靠的自适应演化提供支持和指导.
