基于神经网络融合模型的源代码注释自动生成
2021-04-22周其林刘旭东
周其林, 王 旭, 刘旭东
1. 中国人民大学新闻传播实验中心, 北京 100872 2. 北京航空航天大学计算机学院, 北京 100191 3. 北京航空航天大学大数据科学与脑机智能高精尖创新中心, 北京 100191
0 引 言
研究发现,在软件维护和演化过程中,开发者会耗费大量的时间来阅读和理解源代码片段,为了节省时间,开发者通常采用阅读功能性注释或仅阅读关键代码两种策略[1]. 但这两种方法并不总是高效,SourceForge、GitHub、Google Code等超大规模的软件库上包含海量的软件和信息[2],里面众多代码片段缺少相应的功能注释,自动生成源代码的注释可以帮助开发者了解代码功能,实现关键代码的快速定位.
代码注释自动生成是一种面向软件代码的自然语言生成系统 (natural language generation),使用程序语言片段作为输入,生成该代码片段相应的功能注释. 传统的代码注释生成遵循自然语言生成的一般模式,工作流程包括两个部分:内容选择与文本生成. 内容选择部分检索当前代码片段最相关的文本,注释生成部分使用检索到的文本内容生成代码注释[3]. 内容选择常采用关键词抽取[4]、主题模型[5-7]等方法,这个阶段的文本生成并不过分强调生成注释的流畅性,对代码功能的准确表达是更重要的目标,注释的表示形式有以关键词组合[4],以主题词和关键词作为代码注释描述[6]等方式.该类注释生成方法存在较大缺陷,一是生成的文本注释可读性不好、流畅度差,二是缺少对代码词法、语法等深层信息的利用.
随着深度学习的兴起,基于神经网络的代码注释生成模型得到快速发展,性能全面超过传统注释生成方法. IYER等[8]在 2016年第一个提出将添加注意力的循环神经网络模型CODENN用于注释生成. CODENN将代码视作单词 (Token) 序列挖掘词法语义,通过顺序生成目标单词得到相应注释文本. ALLAMANIS等[9]在2016年使用基于注意力的卷积模型生成平均长度为3个词的短注释,该方法生成的文本注释太短不能全面表达给定代码片段的功能语义. 在代码的语法信息利用方面,HU等[10]于2017年将抽象语法树遍历得到语法序列,再使用基于注意力的Seq2Seq模型生成注释,该模型在利用语法信息生成注释方面进行了尝试.
相比传统方法,上述基于神经网络的代码注释自动生成方法取得了较好的结果,但它们缺少对源代码词法和语法信息的深度挖掘,包括源代码中标识符的特殊构成方式以及两者的融合表征等. 因此,如何更有效利用源代码的词法和语法信息指导注释的自动生成是本文的研究重点.
针对源代码注释自动生成任务,本文基于编码器(Encoder)-解码器(Decoder)框架开展研究,Encoder是针对输入代码片段的功能语义编码器,学到的语义编码向量需要能够更加全面准确的表达代码片段的功能;Decoder是生成功能注释的自然语言解码器,利用编码器学到的功能语义编码向量,使用循环神经网络序列生成符合功能语义的自然语言注释,在编码器和解码器中,通过维护源代码单词字典和自然语言单词词表,并对其中的每个Token进行Embedding计算得到词向量,Embedding得到词向量的过程参与模型训练.
1 基于词法信息的注释生成模型
通过利用编码器-解码器神经网络架构,注释生成模型将源代码片段视作Token序列,并进一步将标识符拆分为SubToken,然后将源代码序列进行词嵌入表征(Embedding)后得到编码向量序列X=(x1,x2,…,xm).经过LSTM循环编码得到编码向量序列H=(h1,h2,…,hm),Encoder循环编码得到语义编码向量序列C=(c1,c2,…,cm),ct=ht+1,C是学习到的语义功能编码,是对代码片段词法语义的向量表达. 最后,考虑到不同单词对语义贡献的权重差异,采用注意力机制进行解码从而生成注释.
1.1 标识符切割
标识符切割算法:蛇形命名法直接基于下划线分割即可,对于匈牙利命名法和驼峰命名法基于命名法规则设计正则表达式进行切割,通过命名法规则将标识符Tokeni切割为(Ti1,Ti2,…,Tit),最后将切割后的Token序列按照原有位置组合得到SubToken序列,在输入代码片段中使用SubToken序列替换掉原有Token,将新的子标识符代码序列输入编码器-解码器序列生成框架,用于训练生成代码注释.
1.2 基于注意力机制的注释生成
解码器采用循环神经网络LSTM进行序列解码得到注释文本. 注释生成从开始标识符
yt=Attention(context,h′t)
(1)
得到注释文本序列Y=(y1,y2,…,yn),基于词表检索yt得到相应单词从而组合生成注释.
为了考虑解决长距离依赖问题,同时照顾到源代码单词对语义贡献的权重差异,本模型添加了注意力机制,注意力机制计算LSTM编码器中间状态序列(h1,h2,…,hm)的向量加权和ct,计算公式如下:
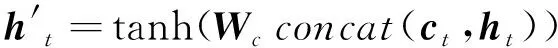
(2)

(3)

(4)

以团队为基础的学习(team-based learning,TBL)的教学模式是由美国Oklahoma大学Michaelsen教授于70年代创立[5],与传统以授课为基础的学习有着明显的不同,TBL不再以教学为主体,而是以学生为中心,是一种以团队为基础,提倡学生自主学习,着重提高学生分析和解决问题的能力,更好地激发学生的学习潜能,将学生培养成终身学习者为目标的新型教学模式,这种教学模式,尤其适合进行分组的病理实习课。
(5)

2 基于语法信息的注释生成模型
上一节基于词法信息的序列生成模型,将源代码视为Token序列,序列生成的假设是有限前序依赖,认为当前的Token只受到位于其前面位置Token的影响. 实际上对代码而言,不同Token之间的相互依赖关系与语法结构相关. 从语法分析角度看,代码片段的抽象语法树AST(abstract syntax tree)体现了Token在语法层面的依赖关系,这种依赖关系是程序功能的重要依据. 因此,可以基于抽象语法树AST进行语法信息的捕捉并生成相应的注释.
本节在编码器阶段利用AST的依赖关系构建得到堆栈序列,接着对堆栈序列使用循环神经网络进行编码,从而得到源代码的语法结构信息.
为了利用源代码语法信息,使用ANTLR4[11]得到源代码片段的语法树AST,为了将其转化为堆栈序列,本文基于深度优先遍历设计了AST堆栈序列生成算法AST_LDR. 首先,使用词法解析程序得到对应代码片段的Token序列,然后递归下降遍历语法树AST,在每条文法规则子程序前后加入括号输出和节点输出,即可解析得到该语法片段对应的堆栈序列.

算法1:AST堆栈序列生成算法AST_LDR输入:AST树Tree输出:对应的递归系列Rs1: Initialize: Set Rs = [ ]2: if(tree!=NULL)3: Rs+=tree.data4: if(tree -> left):5: Rs+=‘(’6: Rs+=AST_LDR(tree)7: Rs+=‘)’8: if(tree->right):9: Rs+=‘(’10: Rs+=AST_LDR(tree)11: Rs+=‘)’12: Return Rs
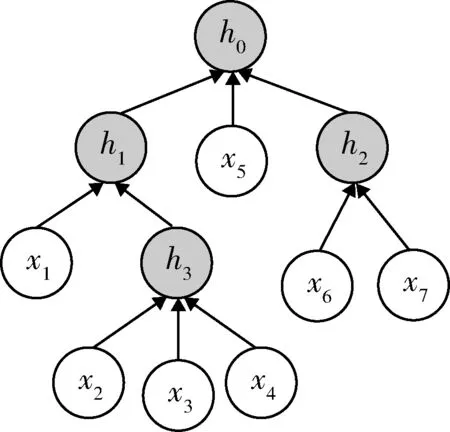
图1 抽象语法树序列生成Fig.1 Token sequence generation using AST
图1所示的语法树AST利用AST堆栈序列生成算法AST_LDR得到的堆栈序列Rs.
Rs:h0(h1(x1h3(x2x3x4))x5h2(x6x7)).
在编码器阶段,使用LSTM循环神经网络对上述代码堆栈序列进行编码. 由于堆栈序列利用抽象语法树的依赖关系进行构建,因此可以有效捕捉源代码的语法信息. 接着,使用全局注意力机制和LSTM循环神经网络进行注释的解码生成.
3 词法语法融合模型
本文3.1和3.2节中设计的模型分别从词法、语法的角度挖掘了代码片段的功能语义,均在一定程度上挖掘了代码片段的功能,本节设计一个词法、语法功能语义融合的功能语义编码器,学到更全面的功能语义编码向量,然后利用融合得到的编码向量进行注释文本的序列生成.
3.1 语义融合框架
利用3.1和3.2节中的词法和语法编码器Lexical Encoder(code)和Syntax Encoder(AST),可以分别得到两种编码向量,结果如下:
Hcode,Ccode=Encodercode(Code)
(6)
Hast,Cast=Encoderast(Ast)
(7)
Cmulti=lstm(Ccode,Cast)
(8)
如图2所示,两个编码器得到的语义编码向量Ccode、Cast通过LSTM门控记忆单元融合得到功能语义编码向量Cmulti. 然后,针对得到的融合编码向量Cmulti,使用LSTM循环解码生成注释序列.
ht=LSTM(ht-1,yt-1,Attn)
(9)
式中h0=Cmulti,y0=emb(′

图2 融合注释生成模型网络结构Fig.2 Neural network fusion model architecture
3.2 融合注意力机制
本模型使用注意力机制对两个解码器的各个状态进行加权求和,计算方法如下:

(10)
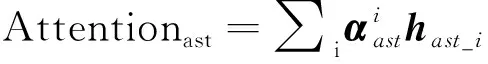
(11)

(12)

(13)
其中,分别计算词法编码器的注意力编码和语法编码器的注意力编码,然后将两者的注意力编码向量和隐藏层进行拼接,再使用一个线性层变换维度,从而得到注释生成阶段的隐藏层编码. 最后使用LSTM 循环神经网络进行注释的解码生成.
4 数据获取
在基于神经网络的源代码注释自动生成方法中,训练数据的有效获取是研究工作的基础. 由于开源社区GitHub等拥有大量真实的项目源代码,这些代码和其对应的注释可以用于构造数据集,图3是一则选自GitHub的真实Java代码片段,该方法上方的注释描述了代码功能,其中注释的第一条语句描述可以作为本段代码的功能注释标注.

图3 Java代码片段及其注释Fig.3 one Java code fragment and its comment
在已有工作中,HU等提出的模型TL-CodeSum[12]使用了GitHub中2015—2016年创建且Star数至少为20的Java项目代码构建数据集. 该数据集共计87136条数据. 由于该数据集重复度较高,本文将TL-CodeSum数据集去重后再按照8∶1∶1划分训练集、验证集、测试集,去重后的数据集命名为MiniTL,MiniTL共有数据71494条.
5 模型训练
本文在数据集MiniTL对模型进行训练,损失函数使用负对数似然函数.所有模型中代码和注释的Embedding维度均设为400,词法和语法两个编码器的功能语义编码向量维度设为400,语义编码融合向量维度设为400,输入序列长度设为1000,注释文本序列长度设为30,编码器Encoder的词表大小设为50000,解码器Decoder的词表大小设为30000. 优化算法使用随机梯度下降算法SGD进行训练使得损失函数尽量小,学习率设为0.95,将Batch大小设为64,最终训练50轮次.使用Titan XP进行训练,比较不同方法的性能.
6 评测指标
为了评估源代码注释的生成质量,本文使用自动测评指标BLEU、METEOR、召回率、准确率、F1-Score测评注释生成质量. 其中,BLEU (bilingual evaluation understudy) 是IBM在2002年提出的一种基于n-gram共现的机器翻译自动评测方法[13]. METEOR是2005年由LAVIE提出的基于召回率的自然语言评测指标[14].同时计算最优候选注释与人工注释之间的召回率、准确率、F1-Score,综合这些指标评估自动生成的注释和人工注释之间的相似性、度量模型的注释生成质量.
7 实验结果
表1显示了3段代码通过不同的注释生成模型生成的质量对比,与真实注释文本比较可以看出,基于神经网络的注释生成模型都具有较好的可读性. 同时直观看出本文提出的融合模型Multi-NN对代码片段功能的描述更准确,验证了融合词法和语法信息对代码功能语义表征起到的重要作用.
本文使用指标BLEU4、METEOR、准确率、召回率、F1-Score进行评测,这些指标从不同角度体现了注释的生成质量,值越高表示注释生成的质量越好,评测结果如表2所示.
从表2中可以看出应用了命名法切割算法的SubCode2NL模型注释生成效果有较大提升,在各个指标上均优于直接使用Token序列的Code2NL模型,同时SubCode2NL优于CODENN模型,并且在多个指标上优于TL-CodeSum模型,验证了命名法切割算法的有效性. 同时对比Code2NL和基于词法信息的注释生成模型AST2NL得知,仅利用抽象语法树捕捉语法信息生成注释的质量相对较差,和CODENN模型生成质量相当. 对比本文提出的Multi-NN融合模型可知,融合了词法和语法信息的神经网络融合模型在各个性能指标上表现最优.
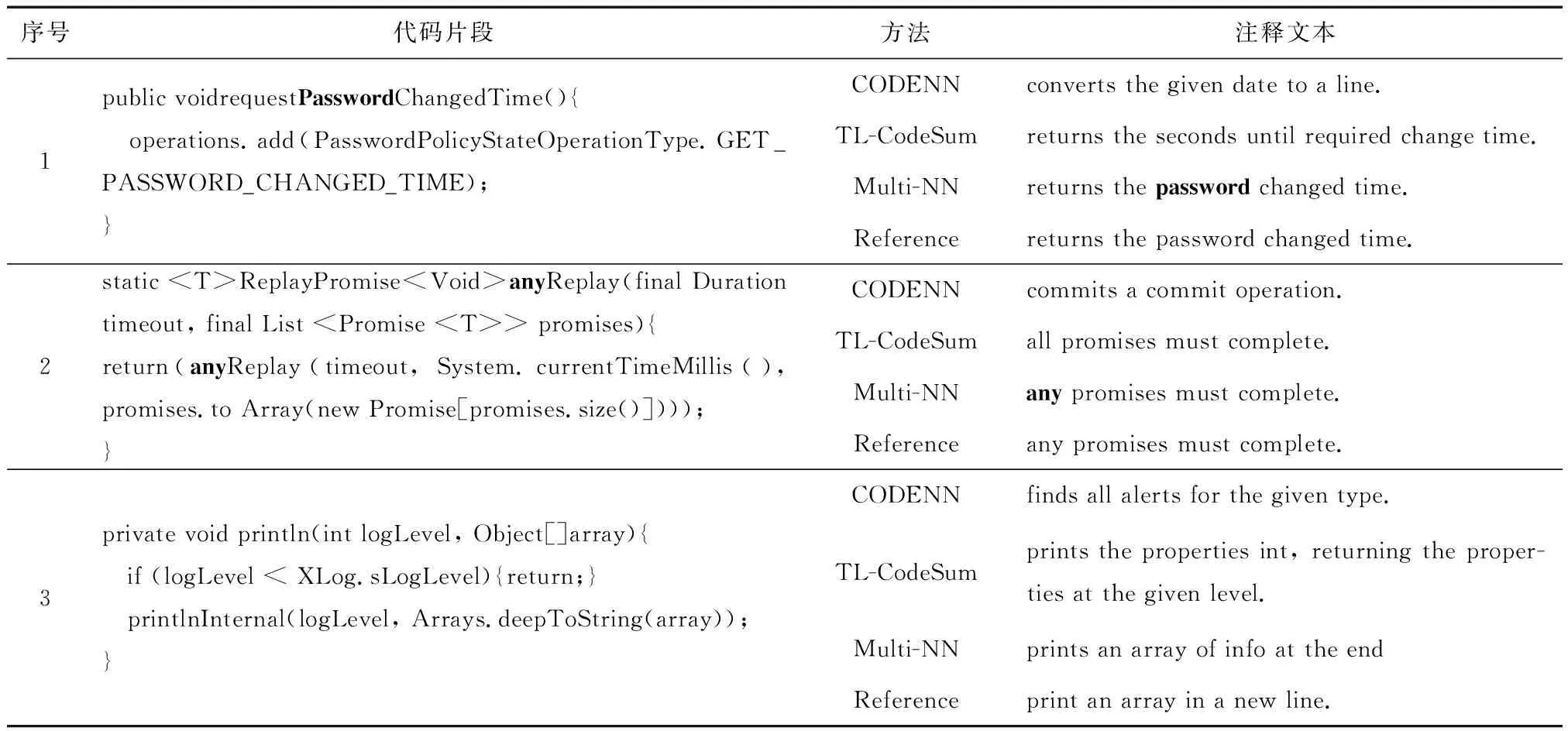
表1 不同模型的注释生成结果对比Tab.1 Comments generation results comparison
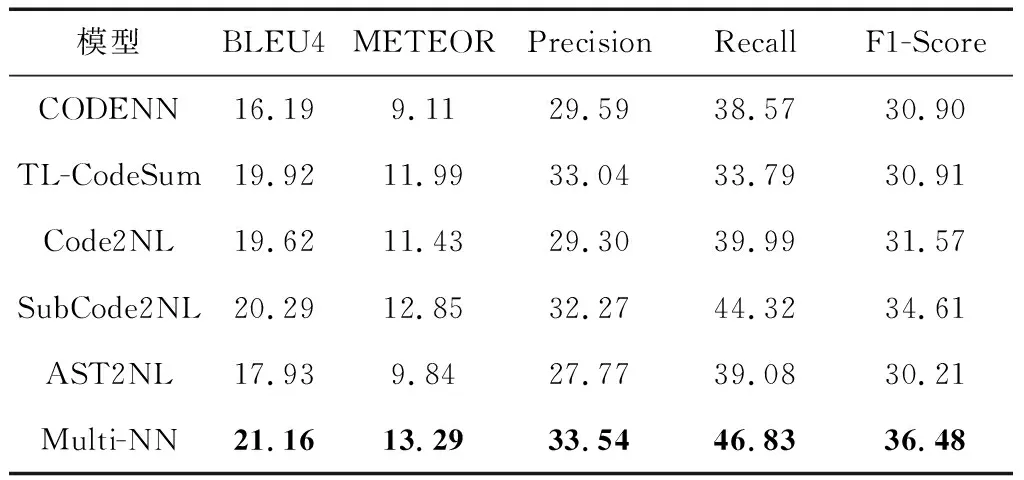
表2 不同模型的评测结果(百分数)Table 2 Evaluation results %
8 结 论
源代码注释自动生成是一个非常具有挑战性的任务,当前的研究在词法信息挖掘、融合词法和语法信息这两个方面都存在较大局限. 本文设计的命名法切割算法可以有效捕捉词法信息,同时基于抽象语法树的依赖关系编码实现了对语法结构信息的挖掘,本文设计了基于神经网络融合生成模型,实现了对词法和语法信息的混合编码,通过实验验证发现,合适的融合机制确实能够获得质量更高的混合编码向量,生成的注释在BLEU4、METEOR等测评指标上均实现了显著提升.
