基于GWO优化SVM的小麦籽粒优劣分级研究
2021-04-21安娟华王克俭何振学
安娟华 董 鑫 王克俭 何振学
(河北农业大学信息科学与技术学院,071000,河北保定)
小麦是世界上种植面积最大的农作物,是我国最重要的商品粮食[1],但是小麦优劣参差不齐,导致种子的质量不高,而且小麦籽粒分级主要依靠人工目测的方式,该方法具有主观性强、随意性大和效率低等缺陷,给小麦分级带来很大的不确定性[2]。因此利用有效的科学技术快速准确地识别小麦籽粒的优劣具有重要的研究意义和价值。
随着信息技术的发展,机器视觉和图像处理等在农业上发挥着越来越重要的作用。Zayas等[3]利用计算机视觉区分小麦品种及非小麦成分,之后又做了各种粮食的分类;Verma[4]采用数字图像处理并结合BP神经网络对大米进行分级,分级准确率达到90%。Paliwal等[5]将5种加拿大小麦和谷糠、麦穗等一些谷物杂质混合鉴定,正确率达到90%。Mahale等[6]采用边缘检测算法提取谷物颗粒区域的边缘,通过计算和分析谷物的大小和形状实现对谷物的分级。Abirami等[7]采用神经网络结合数字图像处理方法对大米颗粒分级的准确率达到96%。Waghmare等[8]通过分析识别葡萄叶片纹理特征,采用多级支持向量机检测分级方法对葡萄霜霉病和黑腐病进行检测和分级,准确率达到96.6%。石小风[9]探索分析基于图像处理技术的小麦品质检测与分级的新方法,建立能够正确识别小麦品种的最优模型,为自动检测小麦所属品种分类提供技术支持。梁良[10]以小麦籽粒优劣分级为目标,通过数字图像处理对小麦籽粒进行特征提取,利用层次分级法和隶属度函数法对小麦籽粒进行了分级,准确率达到93%。冯丽娟等[11]利用稀疏表示法识别小麦品种,准确率达到96.7%,获得了很好的效果。孟惜等[12]通过提取小麦形态颜色纹理特征,利用BP神经网络对单个品种小麦进行识别,然后结合主成分分析法降维研究一次性识别多类小麦品种,最后利用标准粒子群优化算法(particle swarm optimization,PSO)优化权值参数,达到了更好的识别效果。张博[13]通过对经典CNN网络模型进行改进和优化,对小麦籽粒的分类准确率达到了96.3%。张浩等[14]利用计算机图像处理技术能够准确测定小麦籽粒长轴、短轴和投影面积等形态特征,为小麦分级提供了技术支持。
综上所述,国内外学者在农产品上利用计算机视觉技术取得了很多的研究成果,但是在小麦优劣检测分级方面仍然存在速度慢和精度低等问题,需要在此基础上进一步的研究。本文在国内外研究的基础上,针对小麦籽粒检测分级中存在的问题,以航麦8805为研究对象,对采集到的小麦图像预处理获得小麦籽粒的形态、颜色和纹理等特征参数,利用支持向量机建立小麦分级模型,实现小麦籽粒的优劣分级,再利用灰狼算法(grey wolf optimizer,GWO)优化支持向量机(support vector machine,SVM)的两个参数c和σ,将特征参数输入到GWO-SVM算法模型中进行训练和测试,以提高分级的准确率。
1 材料与方法
1.1 小麦籽粒图像获取
研究对象为河北农业大学选育的航麦8805,试验以黑色绒布为背景[15],在光线充足的室内将小麦籽粒均匀地铺在黑色绒布上,用苹果6Plus在距离小麦籽粒8cm处拍照,每幅图像所用的小麦籽粒为20粒,图像以JPG格式存储于计算机中,得到20张小麦籽粒图像,RGB图像的分辨率为3024×4032dpi,从中选择清晰的小麦籽粒图像作为研究对象,共获得302粒小麦籽粒。其中的一张小麦籽粒图像如图1所示。

图1 小麦籽粒RGB原图像Fig.1 Wheat grain RGB original image
1.2 小麦籽粒图像预处理
在图像采集过程中,会受到很多因素的影响,使小麦籽粒图像产生噪声,图像质量下降,对后期籽粒特征提取及籽粒分级产生一定的干扰和影响,因此有必要在对小麦籽粒进行分析之前对采集到的小麦籽粒图像进行预处理。
1.2.1 图像灰度化 由于原始小麦籽粒图像由R、G、B三基色组成,不利于直接对图像进行分割和特征提取,因此需要对其进行灰度化。图像灰度化方法有最大值法、平均法和加权平均法。本文分别使用这3种方法对图像灰度化,试验结果表明使用加权平均法效果最好,加权平均法计算公式为:
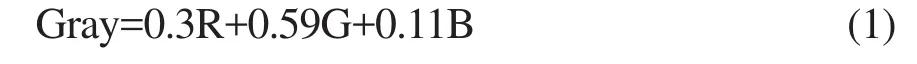
式中Gray为灰度;R、G、B为红、绿、蓝三通道,0.3、0.59、0.11为加权系数,结果如图2-A所示。

图2 小麦籽粒预处理效果图Fig.2 Effect diagram of wheat grain pretreatment
1.2.2 图像滤波 由图2可看出,小麦籽粒形状基本得以保全,但部分细节仍有欠缺,需要进一步处理。首先分别使用均值滤波、中值滤波和高斯滤波对小麦籽粒图像进行平滑降噪。在3种方法中分别使用3×3、5×5、7×7的模板进行滤波,试验表明采用7×7模板的中值滤波效果最好,滤波后的二值图像如图2-B所示。
1.2.3 图像增强 经过滤波处理后的二值化图像变得圆润,但小麦籽粒局部特征不明显,因此需要对其进行图像增强。增强方法为直方图均衡化,图像增强算法有频域和空域两种。其中,频域方法又分为高通滤波、低通滤波和同台滤波;空域方法分为点处理和空间滤波。通过试验结果的对比,本文采用点处理算法,用imadjust函数对灰度图像进行对比度增强,选择阈值参数为0.3和0.5,目的是为了使黑的更黑,白的更白,达到小麦籽粒更加突出的效果,如果增大或缩小阈值都达不到增强的效果,增强后的二值图如图2-C所示。
1.2.4 图像形态学处理 增强后的二值图像还是存在少许的颗粒噪声点,而且小麦籽粒还存在空洞,利用形态学对其进行处理。开运算和闭运算都是形态学中两个非常有用的二次运算,二者的定义分别为:
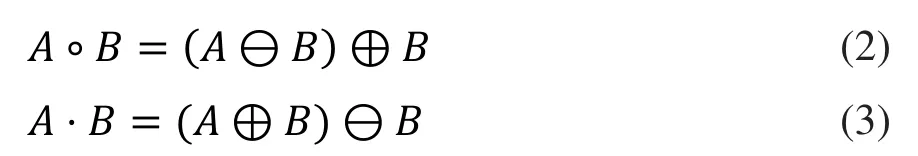
其中A为待处理图像;B为结构元素;⊖ 和⊕分别代表腐蚀和膨胀。
在小麦籽粒图像处理过程中,本文采用开运算,首先采用较小的结构圆对图像进行腐蚀操作,再采用较大的结构圆进行膨胀操作。开运算后图像中噪声基本消除,但小麦籽粒存在空洞,所以对其进行填充操作,最终使小麦籽粒更加完整,处理的结果如图2-D所示。
1.2.5 小麦图像籽粒提取 用bwlabel函数对1.2.4中得到的图像进行标记跟踪,如图2-E所示。采用连通区域重心提取法提取出单个小麦籽粒,用来提取单个小麦籽粒的特征,为后期小麦籽粒分级做准备,如图2-F、2-G、2-H所示。
1.3 特征提取
小麦籽粒的优劣与形态、颜色、纹理特征参数[15-17]有关,通过提取以上特征来判断优劣程度。
1.3.1 形态学特征参数 根据形态学特征可以了解不同小麦籽粒的外形特点,选取面积(area)、周长(perimeter)、长轴(major axis length)、短轴(minor axis length)和椭圆离心率(eccentricity)5个特征。
面积是最自然的区域属性,表示分割得到的籽粒区域中所包含的像素个数,本研究中假设每个像素点的面积为单位1,则面积的计算公式为:

其中,A表示面积,(x,y)表示像素点坐标,R表示小麦籽粒图像中像素坐标点集合。
周长表示籽粒区域的轮廓长度,是按8邻域连通规则来计算的,计算公式为:

其中,P表示周长,Na表示偶数链码数目,Nd表示奇数链码数目。
长轴(短轴)表示与区域具有相同标准二阶中心矩的椭圆的长轴(短轴)长度,用regionprops函数计算。
椭圆离心率表示与区域具有相同标准二阶中心矩的椭圆的离心率,计算公式为:

其中E为椭圆离心率,maj为长轴,min为短轴。
将全部计算结果存储在stats结构阵列中。
1.3.2 颜色特征参数 小麦籽粒颜色是判断小麦籽粒等级的重要特征参数。利用RGB和HSI颜色模型提取小麦籽粒颜色特征参数,具体过程为首先利用1.2节中籽粒分割方法确定籽粒的位置,然后求出每个籽粒的红色分量、绿色分量和蓝色分量的均值和方差,再利用RGB模型和HSI模型的关系求出籽粒的色调、亮度、饱和度的均值和方差,最后整理分析所得的颜色数据,从而得到小麦籽粒的颜色特征参数。
本研究中,需要把小麦籽粒RGB图像转换到HSI颜色模型中,具体转换公式如下:

R、G和B分别表示R、G和B颜色空间的红、绿和蓝分量值;H、S和I分别表示H、S和I颜色空间的色度分量、饱和度分量和亮度分量。
1.3.3 纹理特征参数 采用灰度共生矩阵法,过程为把得到的彩色小麦籽粒图转化为灰度图,然后计算对比度(CON)、能量(ASM)、相关性(COR)和逆差距(HOM)这4个特征。
对比度反映的是小麦籽粒图像的清晰程度和纹理的沟纹深浅,计算公式为:

能量是灰度共生矩阵各元素的平方和,反映的是灰度图像纹理变化的均匀度和纹理的粗细度,计算公式为:

相关性值的大小反映图像中局部灰度的相关性,计算公式为:

逆差距反映图像纹理的同质性,其值的大小表明图像纹理的不同区域间缺少变化,局部非常均匀,计算公式为:
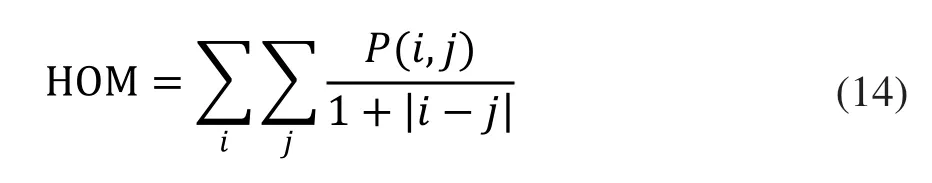
其中,P(i,j)表示图像中灰度值为i的像素相距为d、角度为θ、灰度值为j的像素共同出现的概率。
1.4 分级算法
根据查阅的相关文献和育种专家的指导,将小麦籽粒分为三级,其中形状饱满、颜色明亮、表面光滑的小麦籽粒视为优等小麦,分级时类别标签取值设为2;形状基本饱和、颜色较深、表面略微有褶皱的小麦籽粒视为中等,分级时类别标签取值设为1;形状干瘪、残缺或发病,颜色很深,表面褶皱视为劣等小麦,分级时类别标签取值设为0。首先使用传统SVM算法建立小麦籽粒分级模型,然后用GWO优化SVM参数建立小麦籽粒分级模型来提高传统SVM分级的准确率,最后使用PSOSVM算法[18-19]与其进行对比。
1.4.1 SVM分级核函数 SVM是以统计学习理论为基础逐步发展而来的新型机器学习方法,有训练样本少、训练时间短、精度高等优点。它的原理是通过构建最优分割超平面,使位于超平面一侧的为一类,另一侧的为另外一类,以实现样本的分类。分类函数为:
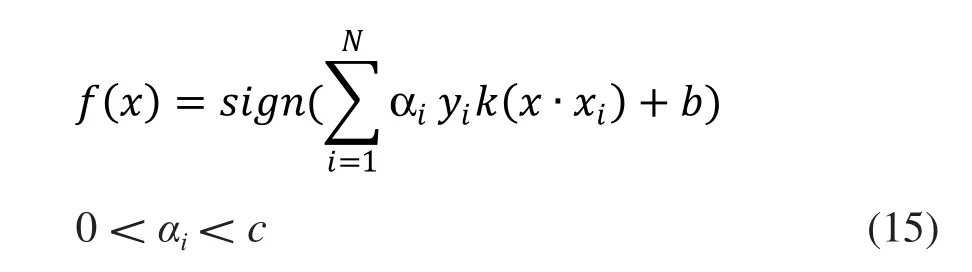
式中:αi为拉格朗日因子;b为根据训练样本所确定的阈值;c为惩罚因子;K(x,xi)为核函数。
采用不同的核函数K(x,xi)可以生成不同的支持向量分类器,常用的核函数有多项式核函数(PKF)、多层感知器核函数(Sigmoid)、线性核函数(Linear)和高斯核函数(RBF)等,核函数的选取往往取决于应用场景的复杂度,对以上几个核函数的试验对比发现对小麦籽粒进行分级时,进行高斯核函数映射后,不仅能够实现将原数据在高维空间中实现线性可分,而且计算方面不会有很大的消耗,同时高斯核函数具有收敛速度快,参数较少等优点,适合用高斯核函数来构建SVM分类器,因此本文选择使用高斯核函数作为核函数K(x,xi),其表达式为:

式中:σ为高斯核函数的宽度。
σ隐含的决定了数据映射到新的特征空间后的分布。σ越大,支持向量个数越少;σ越小,支持向量个数越多。σ间接影响训练样本在高维空间中分布的复杂程度和分类精度,而且高斯核函数中只有σ这一个变量,对参数的优化也相对简单,因此本文选择高斯核函数来构建SVM。
1.4.2 GWO优化SVM算法 在SVM算法的构建中需要对惩罚因子c和核参数σ进行选择,而在实际当中SVM参数的选择对分类精度和性能有很大的影响,一旦选取不当则可能会导致分级效果不理想,但其参数的选择只能依靠模型建立者的经验,目前没有统一的标准。本文使用全局搜索能力及收敛能力都强的GWO对SVM参数进行优化,从而建立GWO-SVM小麦籽粒分级模型。
首先选择算法的适应度函数,由于SVM模型易受惩罚系数c和核参数σ的影响,因此运用GWO算法对SVM参数进行优化选择,选择SVM对小麦籽粒样本分级的错误率为适应度函数,公式为:

式中:right为正确分级样本数量,total为样本总数量。
GWO优化SVM算法[20]主要流程如下:
步骤1:输入小麦籽粒样本数据和样本对应的标签数据,设定SVM的训练集和测试集。
步骤2:设置GWO算法的参数:种群规模N,最大迭代次数T;初始化SVM参数(c,σ)的取值范围。
步骤3:随机产生狼群,每头狼的位置由(c,σ)组成。
步骤4:根据初始参数c和σ,用SVM对训练集样本进行训练,根据公式(17)计算每头狼的适应度函数值。
步骤5:根据适应度值的大小把狼群进行等级排序,α最优,β次之,最后为δ。
步骤6:根据以下狼群算法[21]公式进行狼群个体的位置更新。

式中Dα、Dβ和Dδ分别为狼α、β和δ与猎物之间的距离;C1、C2、C3和A1、A2、A3分别表示 α、β、δ 的系数矢量;Xα(t)、Xβ(t)、Xδ(t)为t时刻猎物位置;X1、X2、X3分别表示狼群的矢量位置;Xα、Xβ、Xδ分别表示猎物的矢量位置。Xp为猎物所处的位置(全局最优解向量),t为当前的迭代次数,X(t+1)为更新后的潜在最优解向量。
步骤7:求出灰狼群个体在新位置的适应度值,重新对狼群个体等级进行划分。
步骤8:以达到最大迭代次数为终止条件,输出α狼的位置即为SVM的最优参数;否则跳转至步骤5。
步骤9:采用输出的最优参数来建立模型,对样本进行测试,输出结果并分析验证。
2 结果与分析
文本中共有302粒样本,根据查阅文献和育种专家指导,将小麦籽粒分为3级,其中优等籽粒数目为150,中等籽粒数目为90,劣等籽粒数目为62。将样本按4∶1的比例分为训练集和测试集。测试集共有61粒,其中有优等小麦29粒,中等小麦20粒,劣等小麦12粒。将狼群数量设置为10,最大迭代次数为100,保证能够全局搜索。用GWO优化后得到最优参数(c,σ),然后构建GWOSVM模型,最后用构建好的模型对样本进行分级。
2.1 分级结果
用GWO-SVM算法和人工实际分级结果进行对比,结果如表1所示。
由表1可以看出,GWO-SVM算法中被正确分级的总数达到了58粒,与人工实际分级结果相比只被分错3个。整体的正检率为95.08%,错检率为4.92%,3种不同等级的小麦籽粒平均正检率达94.41%,错检率为5.59%,由此可见,用GWOSVM算法对小麦籽粒分级是可行的,达到了小麦籽粒分级预期的效果。由表2可以看出,PSOSVM算法模型对小麦籽粒样本分级,优等小麦籽粒、中等小麦籽粒和劣等小麦籽粒被正确识别的个数分别为28、17和10,共计识别个数为55,错误分类共计6粒,总计识别正检率为90.16%,错检率为9.84%。平均识别正检率为88.29%,平均错检率为11.71%。SVM算法模型结果显示,优等、中等和劣等小麦籽粒被正确识别的个数分别为26、15和10,正确分类共计51粒,错误分类共计10粒,整体正检率为83.61%,错检率为16.39%,平均正检率为82.66%,平均错检率为17.34%。其中优等小麦籽粒的正检率最高,因为优等小麦籽粒在形态特征、颜色特征和纹理特征上均具有良好的属性,能很好地与中等和劣等小麦籽粒区分开,所以识别率高。而中等小麦籽粒和劣等小麦籽粒在形态、颜色上容易混淆,所以会导致错分,因此中等小麦和劣质小麦的正检率比较低。

表1 GWO-SVM和人工分级结果对比Table 1 Comparison of GWO-SVM and manual classification results
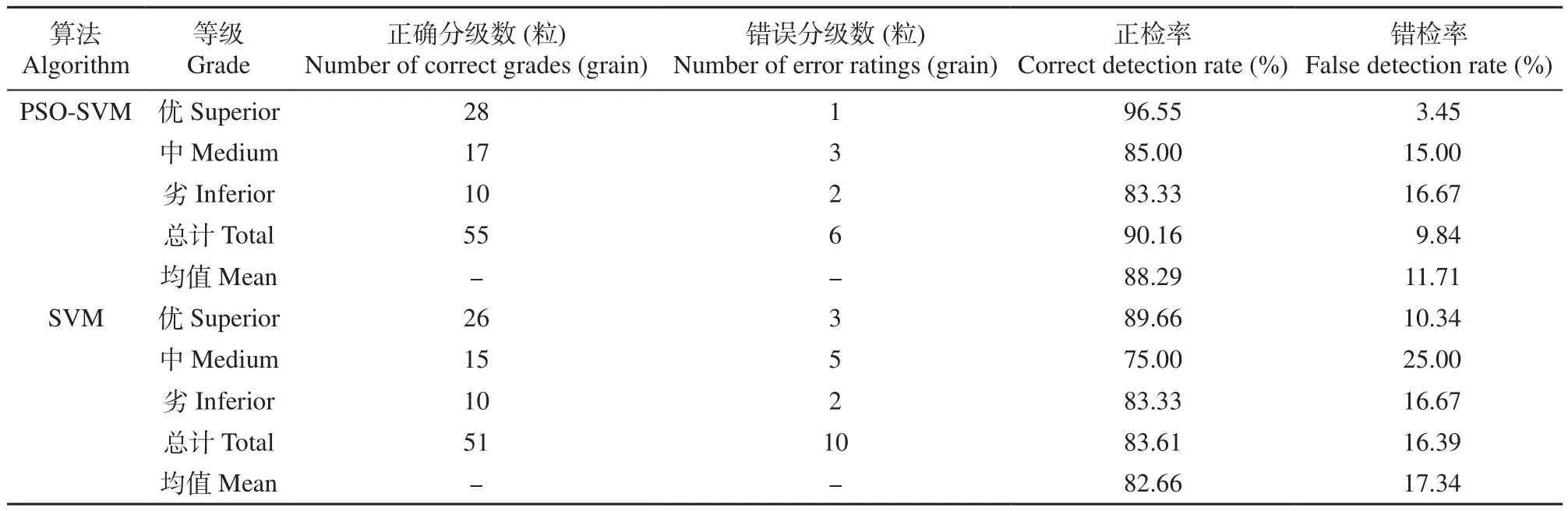
表2 不同算法分级结果Table 2 Classification results of different algorithms
综合以上结果可以得出,GWO-SVM算法正确分级的总数为58粒,而PSO-SVM算法和SVM算法正确分级总数分别是55粒和51粒,GWO-SVM算法的整体正检率和平均正检率都要比PSO-SVM算法和SVM算法高。由此可见,GWO-SVM算法的分级效果要比PSO-SVM算法和SVM算法好。
2.2 算法时间性能比较
分别用GWO和PSO算法对SVM模型中的惩罚因子c和高斯核函数的参数σ进行寻优,以此来优化SVM模型,提高算法的效率,然后进行交叉验证,结果如表3所示。

表3 不同算法时间结果Table 3 Time results of different algorithms s
由表3结果可以看出,无论交叉验证的K值取3、5,还是7,GWO-SVM算法和PSO-SVM算法的时间消耗都要比SVM算法时间消耗大,因为GWO算法和PSO算法在寻找最优参数时会消耗一定的时间。在相同的条件下,GWO-SVM算法在时间消耗上要比PSO-SVM算法时间消耗小,虽然比SVM算法消耗时间大,但是区别不是很明显,对小麦籽粒分级影响不大,可以在接受范围之内。因此,可以得出GWO-SVM算法在速度上也同样有很大的优势。
分级准确率和分级速度的高低决定了分级模型的好坏。在本研究中,GWO-SVM算法模型不仅分级速度具有较大优势,而且在很大程度上提高了分级的准确率。
3 讨论
小麦品种的好坏可以通过对小麦籽粒优劣程度精确量化表示,只有提高国内小麦的质量,才能推动国内农业的发展。但是小麦籽粒优劣参差不齐,对小麦籽粒分级带来很大的不确定性,本文针对小麦籽粒提取了形态特征、颜色特征和纹理特征等共21个特征参数,用于小麦籽粒的分级,试验结果表明,利用这些特征参数对小麦籽粒优劣分级是可行的。
小麦籽粒分级依靠人工目测,效率慢,准确度低,与传统的技术相比,机器视觉检测技术得到了突飞猛进的发展,用机器视觉技术代替繁琐复杂的人工检测过程是自动化分级发展的必然趋势,梁良[10]基于小麦籽粒特征利用层次分级法和隶属度函数法对小麦籽粒进行分级,虽然准确率达93%,但需要人工对其进行阈值的选取,比较艰难繁琐;而王志军等[17]利用人工神经网络实现了小麦籽粒自动分级,识别准确率也达到了93%以上。本研究利用灰狼算法优化支持向量机建立小麦分级模型,在实现自动分级的同时,同样也达到了很好的效果,准确率达95.08%,比前面的研究者准确率有所提高,分级速率也达到了较好的效果。
4 结论
本文研究了基于GWO-SVM的小麦籽粒优劣分级模型并给出了模型的详细步骤。试验结果表明,将GWO算法引入到SVM模型参数的选取上,并应用于小麦籽粒优劣分级上是可行的,正检率达95.08%,提高了小麦籽粒优劣分级的准确率。
