基于BP神经网络的干旱区多组分径流模拟
2021-04-21韩子晨
韩子晨,王 弋*,贺 斌
(1.华北电力大学水利与水电工程学院,北京 102206;2.广东省科学院生态环境与土壤研究所,广东 广州 510650)
新疆作为中国西北的战略屏障,是一带一路的重要核心区和战略资源的重要基地,同时由于地处亚洲中部干旱区,水资源匮乏,分布不均,降水量少,蒸发损失较大,因此水资源的管理与规划显得尤为重要。对开都河这一干旱区多组分径流的模拟结果可以作为预防洪水、干旱预警、环境保护、水电站运行和水资源分配等领域的重要参考。
径流模拟的数学模型有很多,但对于具体流域的径流模拟各不相同,需要考虑不同气候环境、地理条件等因素具体确定,并通过分析、建模和检验等步骤判断径流模拟的准确性和适用性。随着近几十年来计算机技术发展迅猛,计算机在功能上更加齐全,运算速度更快,因此凭借计算机高速计算能力而得以发展的人工智能技术,如机器学习、模拟退火算法、支持向量机等,在包括水文学的诸多领域有了交叉与结合。使用人工智能技术从大量的实测数据中建立的模型可以称为数据驱动模型[1]。对于事先假设一个模式而后用实测数据进行生硬拟合的模型驱动模型,这种建模方式不考虑数据内蕴含的物理意义和规律,只针对数据本身进行分析、研究,从而总结出数据本身所存在的规律[2]。张少文等[3]于2005年通过遗传算法优化人工神经网络,建立黄河上游径流预测模型,与传统预测模型相比,预报精度较高。李娇等[4]于2013年应用人工神经网络技术对泉州市山美水库来水量进行月时间尺度的模拟,模拟结果的误差均在允许范围内且精确度较高。Agarwal等[5]于2004年在印度拿麦达河应用梯度下降优化技术预测径流,结果优于线性传递函数的模型。Boulmaiz等[6]于2016年在人工神经网络中引入EKF算法来改善非线性的输入数据问题,提高了预报精度。
以人工神经网络为代表的机器学习正处于一个蓬勃发展的状态,运用人工神经网络的方法为水文计算提供了便捷的途径,但现有研究仍存在许多不足:神经网络参数的选择还只能依靠经验性的公式和大量重复性的实验,流域情况发生变化时模型如何推广;人工神经网络本身只是充当了一个水文模拟的工具,当更加深刻地研究水文规律和解决水文问题时需要与实际的水文意义相结合;西北干旱区流域面积大、流域地形复杂、气象站与水文站数量稀少,以及河流补给类型为冰雪融水和降水混合补给型等特点,这造成了数据获取的困难,从而制约了模型的效果。
在水文模拟领域通过采用新的技术理论、获取更多的信息源来提高模拟的精度,这是水文模拟领域发展的趋势。本研究尝试应用人工神经网络技术,考虑气候等因素的影响,将人工神经网络与水文模型相结合,对干旱区内陆目标流域径流过程进行分析、模拟与预测。
1 研究区域概况及方法
1.1 研究区域概况
本论文的研究背景是新疆维吾尔自治区开都河流域。开都河流域位于新疆维吾尔自治区天山南坡,焉耆盆地北缘,流域面积22 000 km2,山区流域平均海拔3 100 m,流域地形复杂,河流发源于天山中部海拔5 000 m的萨尔明山的哈尔尕特和扎克斯台沟,流域介于82°52′~86°55′E,41°47′~43°21′N 之间,山区流域平均海拔3 100 m,流域地势北高南低,地形复杂。出山口以上流域集水面积约1.9×104km2,从河源至入湖口全长560 km,是唯一能常年补给博斯腾湖的河流。开都河属于冰雪融水和降水混合补给型河流,春季季节性积雪融化补给河流,夏季则以高山冰雪融水和山区降水补给为主,雨雪降水混合占径流总量的45.3%,冰川融水占14.1%,流域内年降水量分配不均,受季节影响明显,连续最大4个月降水量发生在5—8月;蒸发年内分布不均,全年蒸发量约为680 mm,多年平均径流量约35.31×108m3,4—9月丰水期径流量占全年径流量的73.8%,10至次年3月枯水期径流量占全年径流量的26.2%。因此开都河具有干旱区的代表性和典型性,流域概况具体见图1。
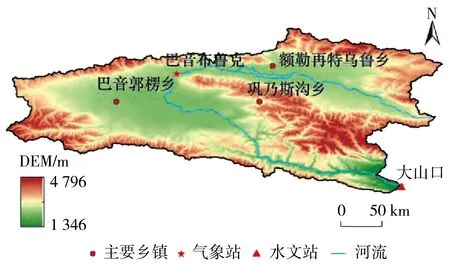
图1 开都河流域
1.2 研究方法
1.2.1BP神经网络
BP神经网络的结构包括输入层(input layer)、隐含层(hidden layer)和输出层(output layer)[7],其中隐含层可以为一层或多层。BP神经网络有以下特点。
a)网络为多层结构,相邻两层的每个神经元都与邻层所有的神经元连接,而同一层的神经元之间不存在连接。这样的网络结构,使BP神经网络可以完成复杂的计算工作。
b)网络的激活函数可微,例如常用的Sigmoid函数和线性函数。Sigmoid函数根据映射后的区间范围又可分为Log-Sigmoid函数和Tan-Sigmoid函数,它们的数学表达见式(1)[8]:
(1)
其中x的取值为任意实数,函数的输出区间分别为[0,1]和[-1,1],为网络的分类工作提供便利。
c)网络采用误差反向传播算法(Back-Propagation Algorithm)。BP算法的原理为,有监督学习中,实际输出与期望输出差值的均方值作为误差信号可以沿网络反向传播,在传播的过程中网络的每一层权值都会得到调整,这个过程将重复至误差低于目标值后神经网络学习结束[9]。
这种算法可以有效地训练具有优秀非线性拟合能力的多层前向神经网络,所以多年来该算法一直受到研究人员广泛的关注[10]。
1.2.2SRM原理
Snowmelt-Runoff Model(SRM)是由Martincc和Rango等人在1980s开发的,最初主要用于湿润和半湿润地区,后通过应用发现该模型对于干旱区的流域也有着很好的效果。
SRM在开发之初的目的就是为了解决山区流域融雪径流模拟的问题。这个水文模型的基础为度日因子法,模型需要的数据为日平均气温、日降水和积雪覆盖率[11]。因开都河流域的积雪覆盖率数据的获取较为困难,所以直接以度日模型计算冰雪融水量,将其代替积雪覆盖率为BP神经网络增加一个输入。
度日模型的建立依靠的是冰雪消融与气温之间存在的线性关系,该模型的优点在于气温作为其主要输入,比别的气象因素较容易获取,整个模型的计算较为简单。虽然模型存在如无法描述冰雪融化的物理过程的缺点等,但因其简单易用,还是被广泛地应用于相关研究中。度日模型的一般形式如下[12]:
M=DDF·PDD
(2)
式中M——某时段内冰川或积雪的消融量,mm;DDF——冰川或积雪的度日因子,mm·d-1·℃-1,开都河流域高程变化较大,经过高程分带,选取平均高程带的度日因子0.35为代表;PDD——某一时段内的正积温,其取值通常由式(3)计算[12]:
(3)
式中Tt——某天的日平均气温,℃;Ht——逻辑变量,其取值规则为,当Tt>0℃时,Ht=1,当Tt≤0℃时,Ht=0。
1.2.3自相关系数法
对于一组依次排列的变量,它们之间相关关系的强弱通过各阶自相关系数反映,所以可以把开都河的日均流量当作这样的一组变量,然后选择某一天的日均流量,再分别计算其前几天的日均流量与该天日均流量的自相关系数大小,便可以使用这几日的日均流量作为输入进行模拟。
自相关系数的计算公式见式(4)[13]:
(4)
式中xt——第t天日均流量;x——年均流量;n——径流序列长度;k——步长。
2 结果与分析
开都河流域所处地区的气候类型为温带大陆性气候,全年平均气温为-4.16 ℃,平均最大积雪深度为12 cm,高寒气候特征显著。开都河的补给类型为冰雪融水和降水混合补给型,其年径流量约35亿 m3,全年径流量年内分布不均匀:春季的河流补给来源为冰雪融水,多年平均春季(3—5月)径流总量近8亿 m3;夏季的河流补给来源则包括冰雪融水和山区降水,多年平均夏季(6—8月)径流总量约为15.5亿 m3;冬季流域平均气温在0℃以下,基本没有冰雪融水来补给河流,降水的形式为降雪,只能以积雪的形式积累在流域,河流主要依靠地下水补给。开都河流域面积大,且流域内气象站与水文站数量较少,河流的补给来源较复杂,这些不利条件给径流模拟带来了很大的困难。本文将采用BP神经网络研究开都河的径流模拟。
2.1 流域模型的主要影响因子
初始的BP神经网络的输入是日平均气温和降水,为了确定哪一个在模型中起决定作用,因此,把日平均气温和降水分别作为神经网络的输入,分析得到的图像结果[14]。
将日降水作为输入,得到的结果见图2。可以从模拟结果图中看到,预测日均流量的实线与实测日均流量的虚线吻合度较差,特别是在冬春季节,模拟成功的只有在两曲线的交点及其附近。
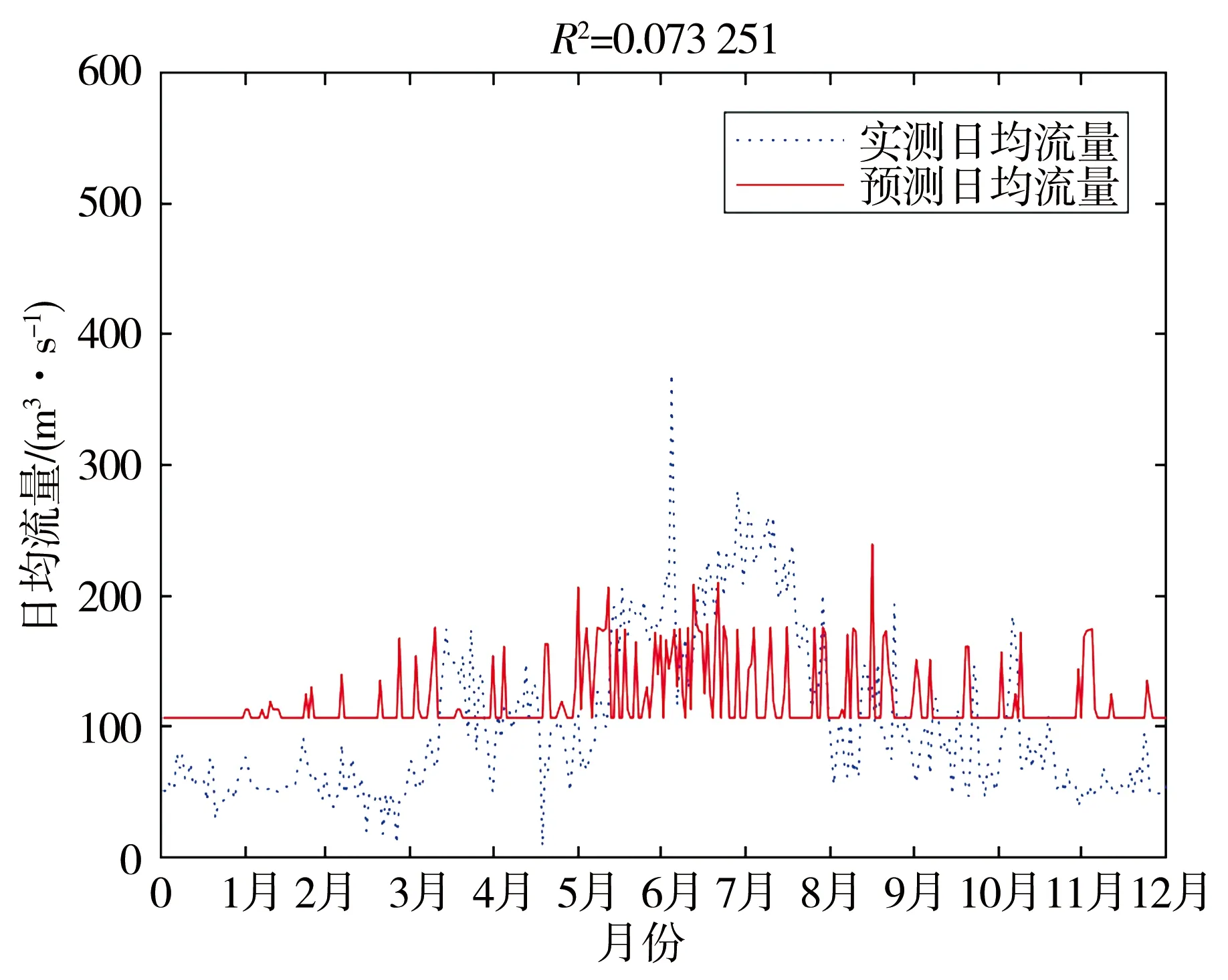
图2 日降水作为输入的模拟结果(2012年)
将日平均气温作为输入,得到的结果见图3。可以从模拟结果图中看到,预测日均流量的实线与实测日均流量的虚线整体吻合度相较于把日降水作为输入时有了很大的提高与改善。
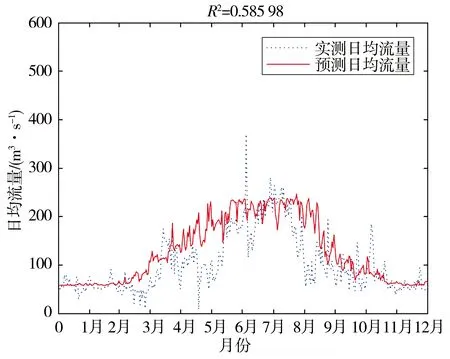
图3 日平均气温作为输入的模拟结果(2012年)
通过对图像的分析,可以得到结论,日平均气温是流域模型的主要影响因子[15]。因此对这个BP神经网络的径流模拟模型的改进,应该围绕气温进行[16]。
2.2 基于SRM原理改进的BP神经网络
根据开都河流域的气候与水文特点,本文基于SRM的原理来对BP神经网络进行改进后,将日平均气温、日降水及日冰雪消融量作为神经网络的输入,得到的结果见图4。
图4 基于SRM原理改进后的模拟结果(2012年)
根据图4所示,夏季和冬季的模拟效果较好,春季的模拟效果较差,分析可能的原因如下。
a)开都河夏季的河流补给主要依靠冰雪融水和山区降水,开都河冬季的河流补给主要依靠地下水,由于开都河流域的主要影响因子气温在这2个季节幅度较小,因此这2个时段内河流补给较为稳定,不易受到偶然因素的影响而使河流的日均径流量发生较大幅度的波动。
b)春季的径流来源主要依靠冰川和积雪的融水,决定冰川和积雪消融量的影响因子为气温,而在春季的气温并不稳定,再加上开都河流域山区地形复杂,海拔变化剧烈,气温无法稳定地保持在0 ℃以上[17]。这种气温的不稳定性有时甚至会造成春汛洪水超过夏季洪水。除此之外,大山口水文站在春季的实测日均流量存在异常,原因有可能是巴音布鲁克草原牧草在这个时段为发芽期,需要大量用水,也有可能为上游水库调度导致流量变化,使得实测日均流量非自然流量。
因此,基于当前BP神经网络的径流模拟模型的实际表现情况,以及该地区人民生产生活的需要,该论文研究的时段集中在汛期。现选取2012年7月16日至8月15日期间共计31 d的数据,作为神经网络的测试集,结果见图5。开都河7月16日至8月15日BP神经网络的日均流量模拟详细结果见表1。
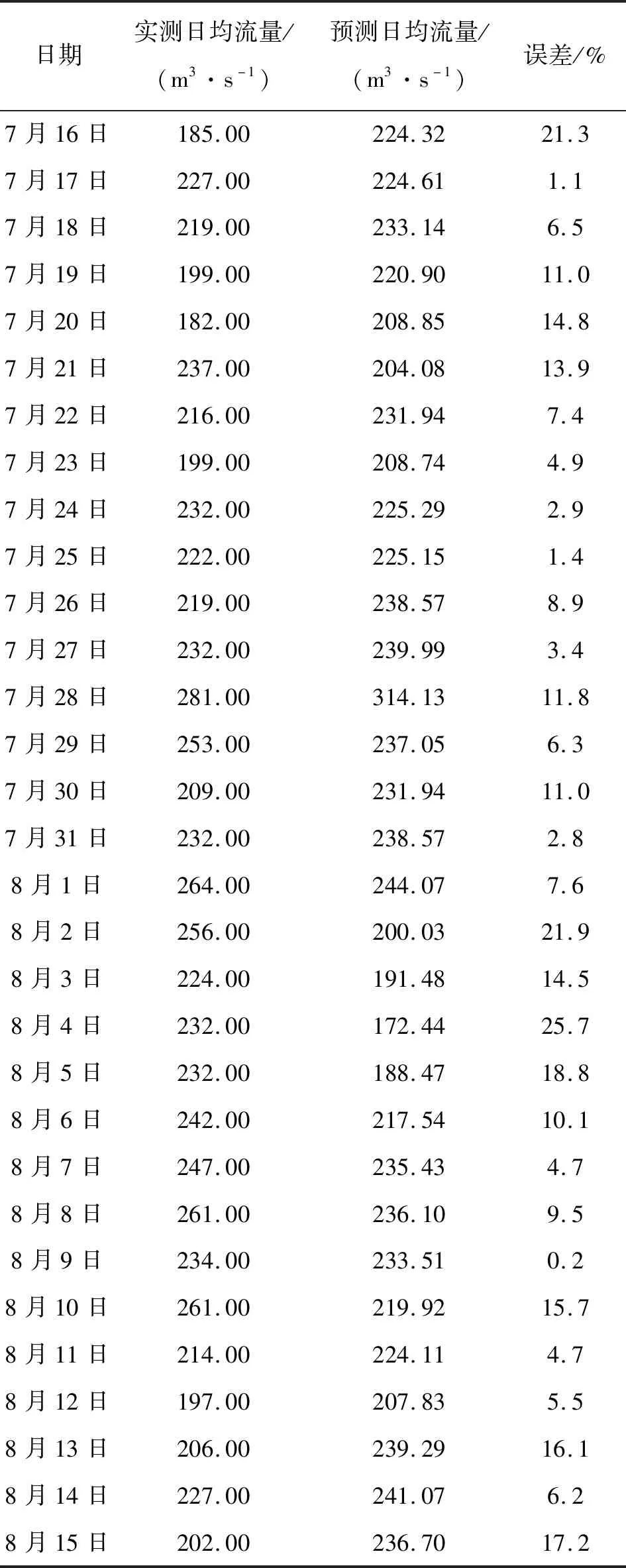
表1 实测、预测日均流量对比
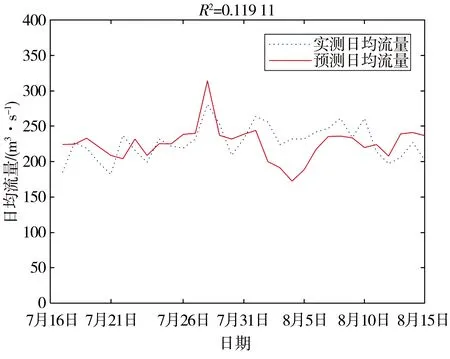
图5 2012年7月16日至8月15日的径流模拟结果
从表中数据可得出,31个测试样本数据中,误差在20%以内的有28个,超过20%的则有3个,根据《水文情报预报规范》中的规定[18],预报结果合格的标准为误差不超过20%。由此计算可得,BP神经网络对开都河7月16日至8月15日期间的预报精度为90.32%,精度达到评定标准甲级。
2.3 基于自相关系数法的模型
研究了将日平均气温和降水作为输入的BP神经网络径流模拟模型后,接着建立基于自相关系数法的BP神经网络径流模拟模型,用日均径流作为模型的输入,最后根据模拟结果做进一步的分析与对比。
根据计算结果,选取前1、2、3、4、5 d的日均流量作为输入,当天的日均流量为输出,从而建立了基于自相关系数法的BP神经网络径流模拟模型,模拟结果见图6。
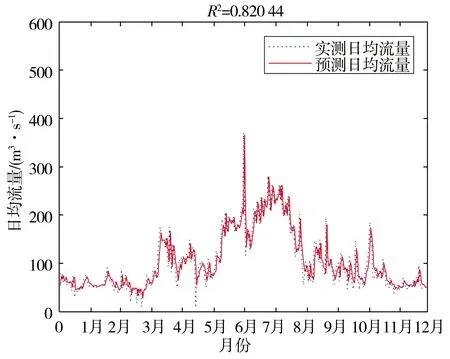
图6 基于自相关系数法的模拟结果(2012年)
根据模拟结果,全年的预测日均流量的实线与实测日均流量的虚线整体吻合度很高。在366个测试样本数据中,误差在20%以内的有244个,由此计算可得,基于自相关系数法的BP神经网络对开都河2012年的预报精度为66.67%,精度达到评定标准丙级。
2.4 分析
根据模拟结果,2种BP神经网络径流模拟模型都可以便捷地进行径流模拟,但两者存在不同之处。基于SRM原理改进的模型以日平均气温、降水以及冰雪融水作为输入,有明确的物理意义,基于自相关系数法的模型以日均径流为输入,模型的底层逻辑为数据本身之间的联系。两者相比较,基于自相关系数法的模型模拟精度高,但基于SRM原理改进的模型可以进行更大时间广度的模拟。因此,基于自相关系数法的模型适用于较短时间内的径流模拟,基于SRM原理改进的模型适用于较大时间尺度上的径流模拟。
3 结论
径流模拟的结果可以作为预防洪水、干旱预警、环境保护和水电站运行等领域的重要参考,但是由于径流模拟问题的复杂性和艰巨性,虽然现有许多模拟方法,但仍不满足实际应用的需要。自人工神经网络出现以来,尤其是近10年中,其发展速度令人惊喜,这为径流的快速模拟找到了一条新的途径。本论文中研究了BP神经网络在径流模拟中的应用,并取得了如下的成果。
a)建立了基于BP神经网络的开都河流域径流模拟模型,确定了日平均气温是模型的主要影响因子,并根据SRM这一融雪径流模型的原理,通过度日因子法为网络增加了冰川和积雪的消融量的输入,模型的性能有了改善,模型的物理意义也得到了加强。
b)运用自相关系数法,将经过处理的日均流量序列作为神经网络的输入,相较于以日平均气温、日降水和日冰雪消融量为输入,全年日均流量的模拟结果的精度提升很大,尤其是对于后者无法有效模拟的3—5月这一时段的日均流量。
