基于SPSS Modeler质量控制关键点的监控与应用
2021-04-20蔡清秀李超于海岐崔福祥李海峰赵文涛
蔡清秀,李超,于海岐,崔福祥,李海峰,赵文涛
(鞍钢股份有限公司鲅鱼圈钢铁分公司,辽宁 营口 115007)
鞍钢股份有限公司鲅鱼圈钢铁分公司炼钢部(以下简称“炼钢部”)设计年产钢坯650万t,生产钢种覆盖船板、磨具、管线、汽车板等29大系列588个牌号。炼钢部为保证重点钢种质量受控,通过统计大量的质量数据,分析确定了恒拉速、出钢氧值、Als烧损等21个涉及转炉、精炼、连铸各工序的质量控制关键点。由于关键点数据来源于各工序各自独立的生产报表内,传统的作法主要是手工方式,利用关键字将各EXCEL报表内所需要的数据通过筛选、复制、粘贴等方式提取到一个报表内,进而形成跨工序的新EXCEL报表。这是一个繁杂的工作,效率和准确性取决于操作者对软件的掌握熟练度。为保证质量控制关键点监控的时效性,减轻工程技术人员手工数据提取过程的劳动强度,炼钢部建立了基于SPSS Modeler的数据挖掘模型,将数据提取过程固化在SPSS Modeler数据流中,实现数据的自动化提取。同时由于建立了各工序数据的关联,可以实现跨工序生产履历查询,并利用关键点数据对现行质量过程控制标准进一步优化,实现质量管理的提升与改进。
1 数据的读取
炼钢生产是一个异常复杂的过程,每天都会产生海量数据,涉及到设备、生产、质量、安全、环保等各个方面。质量控制关键点数据是从这些海量数据中,抽取出的质量控制方面相对比较重要的记录数据,是长期生产总结的成果,表1为关键点工艺参数及提取模式。

表1 关键点工艺参数及提取模式Table 1 Process Parameters for Key Points and Mode of Extracting Them
这些数据存放在MES终端导出的《转炉熔炼记录信息表》、《LF 精炼信息》、《RH 精炼信息》、《连铸浇铸信息》、《连铸作业图表》等7个文件内。将关键点数据按照一定的逻辑先后顺序从上述图表中抽取出来是数据读取阶段的主要任务,主要完成以下几方面工作:
(1)由于导出Excel文件字段格式不标准,部分图表需完成字段重建工作;
(2)理清生产逻辑关系,按照逻辑关系将各个图表中的记录关联在一起,建立数据集合;
(3)过滤掉与质量控制关键点无关的字段。
图1 为 Excel源节点对话框。SPSS Modeler通过源节点对数据进行读取,支持数据库、可变文件、固定文件、SAS文件、Statistics文件、Excel等数据存储格式文件的读取。读取Excel文件使用Excel源节点进行导入。
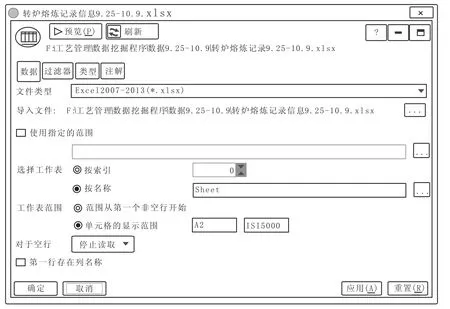
图1 Excel源节点对话框Fig.1 Dialog Box for Excel Source Node
数据导入后通过过滤器和类型选项卡对数据进行字段过滤和字段重建。对于任务(2),通过考察工艺路径特点,按图2所示的①~⑥逻辑关系载入各电子表,进行数据预处理。
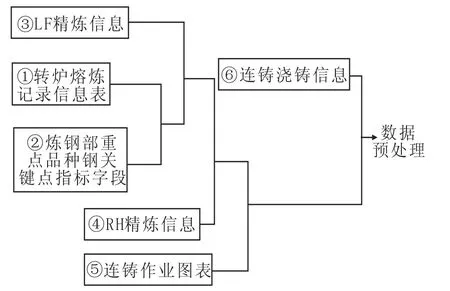
图2 各电子表格载入顺序Fig.2 Loading Orders for Individual Spreadsheet
经过上述分析后,确定数据读取过程的数据流见图3。由图3看出,数据读取过程通过“熔炼号”将各工序生产报表关联在一起,实现了跨工序数据的整合,建立了全工序数据集合,为跨工序数据分析、全工序生产过程履历查询做好了充分的准备。
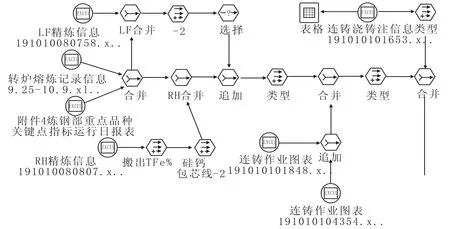
图3 数据读取过程的数据流Fig.3 Data Stream for Reading Data Process
2 生成数据流
数据经过合并、字段过滤后,仍属于原始数据,需要进一步处理。此环节需要解决数据类型转换、数据筛选、字段衍生、字段重排、字段进一步过滤以及字段汇总等问题。
2.1 数据类型转换
由于电子表是通过MES终端导出表格,存在大量按文本格式存储的数值型数据,需要通过导出节点,使用“to_number(ITEM)”函数进行批量处理。导出节点数据类型转换功能实现对话框见图4所示。

图4 导出节点数据类型转换功能实现对话框Fig.4 Dialog Box Display by Exporting Changeover Function for Types of Node Data
2.2 数据筛选与字段衍生
由于数据存在缺失、异常等情况,需要对数据进行筛选,去除异常值,确保分析使用的数据更加稳定。另外,对原始数据加工计算过程中会衍生出新字段,这就是字段衍生。数据筛选和字段衍生是数据预处理的重要方法。二者主要通过导出节点,使用条件函数进行处理。由于处理字段较多,以衍生字段“增氮”为例予以说明。导出节点数据筛选和字段衍生功能实现对话框见图5。由图5看出,“增氮”作为评价保护浇铸好坏的重要指标,如果不好,钢水浇铸过程会出现显著增氮现象,导出原始图表并不包含“增氮”字段,需要通过计算成品氮含量与精炼搬出氮含量之差作为“增氮”字段,但根据专业判断,搬出氮含量和成品氮含量都不可能为0,所以计算前对数据进行筛选。

图5 导出节点数据筛选和字段衍生功能实现对话框Fig.5 Dialog Box Display by Exporting Functions for Node Data Filtering and Fields Deriving
本对话框实现功能如下:如果成品氮含量与精炼搬出氮含量都不为0,则输出二者之差 (单位:10),否则输出空值(即 undef)。
2.3 字段重排
为实现输出数据具有较好的逻辑上的可读性,可使用字段重排节点实现字段重新排序,图6为字段重排功能实现对话框。

图6 字段重排功能实现对话框Fig.6 Dialog Box Display by Exporting Function for Field Rearrangement
2.4 数据汇总
连铸机浇铸过程中,采用多炉钢水连续浇铸方式,即连续浇铸的若干罐次(熔炼号)组成一个浇次。评价浇次质量则需要对浇次内若干罐次的指标进行汇总计算,这一过程需使用“汇总”节点进行数据处理。图7为数据汇总功能实现对话框。由图7看出,数据汇总节点功能可实现数据的求和、平均数、最小值、最大值、标准差、中位数、计数、方差、第一分位数、第四分位数等统计指标的计算。

图7 数据汇总功能实现对话框Fig.7 Dialog Box Display by Exporting Function for Summarizing Data
2.5 生成数据流
SPSS Modeler的设计思想是尽量用简单方式进行数据挖掘,尽可能的屏蔽数据挖掘算法的复杂性和软件操作的繁琐性,目的是使用先进的数据挖掘技术解决问题而不是软件操作本身。因此,SPSS Modeler将节点依次连接构建数据流实现数据挖掘过程,可以清晰的看到数据是如何被加工处理的,而且方便选择执行部分还是全部数据处理过程。对经过读取、合并的数据流进行字段过滤以及数据类型转换、数据筛选、字段衍生等一系列节点连接后,自然形成数据流,见图8。数据流形成后,实现关键点数据按要求的数据格式进行输出、提取,为后续的质量数据分析提供重要帮助。
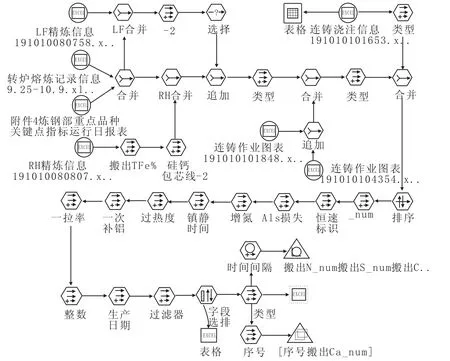
图8 数据流功能实现Fig.8 Function Display for Data Flow
3 数据应用实例
质量控制关键点数据是质量控制方面高度浓缩的高质量数据,可提高数据的应用价值,举例如下。
3.1 关键点数据运行情况监控
提取的关键点数据,可针对特定的指标绘制分布图、直方图、散点图、网络图等,从而实现数据运行情况的监控。图9为SPSS Modeler图形选项卡输出的S含量趋势图例。
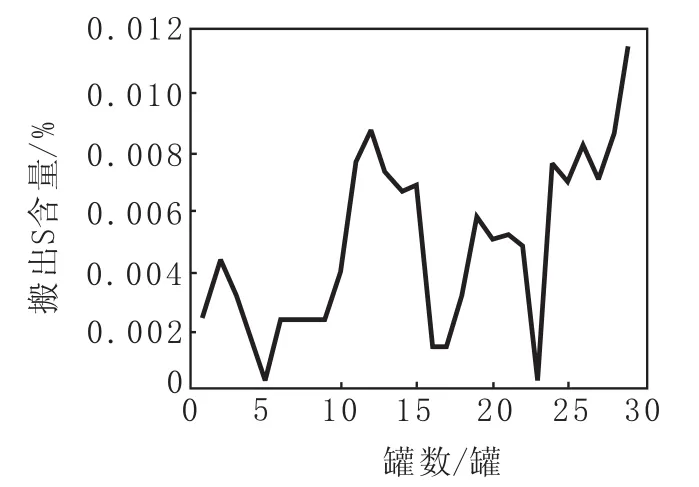
图9 SPSS Modeler图形选项卡输出的S含量趋势图例Fig.9 Trend Legend for Content of Sulfur Output from Tab of SPSS Modeler Graphics
根据图9可以掌握冶炼过程中S含量的变化趋势,采取相应措施以满足生产需要。
3.2 关键点数据进一步挖掘应用
对关键点数据采用SPSS软件进一步挖掘,可实现对过程参数的进一步优化。例如有客户反馈部分钢种存在夹杂缺陷,为寻找影响夹杂缺陷的原因,对关键点数据进一步挖掘,图10为夹杂缺陷率与部分控制参数关系。由图10看出,夹杂缺陷率与关键点数据终端RH-OB升温幅度、是否加入改质铝线段、RH终点氧含量以及转炉出钢氧含量存在较大的相关性。具体分析如下:
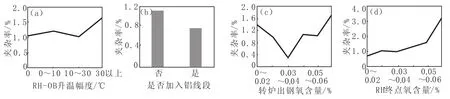
图10 部分控制参数与夹杂率的关系Fig.10 Relationship between Some Control Parameters and Inclusion Ratio
(1)RH-OB升温幅度在30℃以下,夹杂缺陷率基本保持在1.2%左右,但如果高于30℃,则会升至1.6%左右,所以生产中要严格控制RH-OB升温幅度;
(2)改质铝线段的加入也会对夹杂缺陷率产生影响,加入改质铝线段与否会直接导致产品的夹杂缺陷率相差0.3%左右;
(3)转炉终点氧含量与夹杂率存在高-低-高的关系,即转炉终点氧含量小于0.03%时夹杂率较高,0.03%~0.04%时最低,大于0.06%时,夹杂率显著增加。分析认为,转炉终点氧含量小于0.03%时,转炉存在补吹操作,会增加夹杂缺陷的产生,所以转炉终点氧含量要控制在0.03%~0.06%。
(4)RH终点氧含量是几个因素中影响较大的一个,在RH终点氧含量小于0.06%时,夹杂缺陷率与RH终点氧含量存在简单的线性关系,即随着RH终点氧含量的升高,夹杂缺陷率从0.6%升至1.6%。但高于0.06%时,夹杂缺陷率急剧上升,由1.6%升至3.3%,所以RH终点氧含量要尽可能控制在较低水平,尤其不能高于0.06%。
4 结论
(1)通过采用SPSS Modeler软件,将数据提取过程固化在数据流中,实现数据的自动化提取,不仅提高了工作效率,更有利于数据监控和分析,有利于质量问题的解决。
(2)通过关键字段将各工序生产报表关联在一起,建立了跨工序数据集合,有利于跨工序数据分析和全工序生产过程履历查询。
(3)对关键点数据进一步挖掘,可对现行质量控制标准进一步优化,提高生产质量管理水平。
