基于Mask R-CNN算法在轨道扣件缺陷检测中的应用
2021-04-19倪费杰林群煦闫笑颜徐群华吴月玉江旭耀
倪费杰,林群煦,闫笑颜,徐群华,吴月玉,江旭耀
(五邑大学 轨道交通学院,广东 江门529020)
0 引言
随着我国轨道交通的快速发展,国内铁路里程的不断增加,无论是客运还是货运,铁路运输起到其他运输方式无法代替的作用,然而铁路的安全与养护与列车的安全运行有着至关重要的关系。扣件确保了钢轨与钢轨及钢轨与轨枕之间的可靠联结,保持了钢轨的连续性与整体性。扣件能够阻止钢轨相对于轨枕的纵向移动、确保轨距正常,并在机车车辆的动力作用下充分发挥缓冲减振功能,减缓线路残余变形的积累。但列车在行驶过程中产生剧烈振动、雨水对扣件的腐蚀等因素,都可能产生扣件缺陷,甚至由此引发列车脱轨事故的发生。因此,亟需一种迅速且能自动化检测扣件缺陷的方法。
目前,国内扣件缺陷检测方式仍然以人工巡检为主,以巡检列车检测为辅,主要原因是尚缺少高效准确的扣件检测算法,且多数算法不稳定[1]。在国外的高速巡检列车中,美国ENSCO公司的T10型检测列车、英国的NMT综合巡检列车和法国的IRIS320型综合巡检列车都基本实现了对扣件图像的采集和检测任务[2]。近年来随着神经网络与深度学习(Deep Learning)的快速发展,小目标缺陷检测技术越来越成熟,并且相关的研究已经应用到识别有砟轨道区域、轨道塞钉[3]等零部件的检测,并取得了良好的检测效果。
针对人工巡检效率低下、成本较高、准确率难以保障的问题,本文采用Mask R-CNN网络实现对轨道扣件的缺陷检测,从而实现轨道扣件的自动化检测。
1 扣件缺陷检测系统简介
本文建立的缺陷检测系统主要由扣件图像采集系统、缺陷识别系统组成。其中图像采集系统由可在轨运行的检测小车、高速工业相机、相机支架与补光灯支架组成。其中检测小车速度为2 m/s,扣件所在区域尺寸为350 mm×150 mm,综合考虑扣件所在区域、不同扣件的生产和测量误差,选取不同扣件的平均误差0.2 mm来计算所需工业相机的分辨率。计算公式如下:
相机分辨率=检测区域的面积÷(检测精度×检测精度)。
所以相机分辨率约为131万。为了提高系统的精准度和稳定性,减少干扰像素点被误认为缺陷的概率,一般工业界取缺陷的面积在3~4个像素以上,因此在选择相机时应在上述结果的基础上乘以4,故选取500万像素的工业相机。
缺陷识别系统以TensorFlow、Keras架构为基础,使用Python语言编写Mask R-CNN算法。
2 Mask R-CNN 算法
Mask R-CNN[4](结构简图如图1)是2017年He Kaiming首次提出,该网络是在分类与回归2个分支的基础上增加了一个Mask分支进行语义分割。
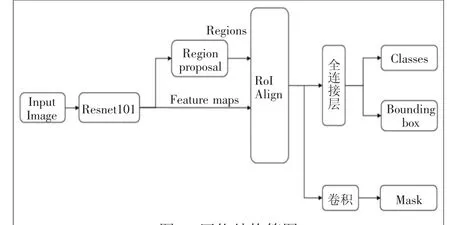
图1 网络结构简图
Mask R-CNN中定义的损失函数是一个多任务的损失函数:

2.1 主干特征提取网络Resnet101
本文介绍的Mask R-CNN网络,以Resnet101[5]为主干特征提取网络。如图2所示,首先将输入的图片使用Zeropadding(零填充),将图片大小统一为1024×1024,经过卷积、Batch Normalization(批归一化)、Relu函数等一系列操作提取特征,以提取到的C2、C3、C4、C5等4个有效特征层为基础建立FPN。
2.2 特征融合模块
本文利用Mask R-CNN算法实现对扣件与扣件缺陷的实例分割任务,采集校内轨道扣件图像,建立一个扣件数据集。扣件图像经过主干特征提取网络后得到不同维度的特征图,随后由FPN对特征图进行特征融合,最后由RPN对融合后的特征进行分类、回归及掩膜生成。
2.2.1 FPN模块
FPN[5]是传统CNN网络对图片信息表达输出的一种增强,改进了CNN网络的特征提取方式,使最终输出的特征可以更好地表示输入图片各个维度的信息。使用主干特征提取网络中依次缩小了4、8、16、32 倍 的C2、C3、C4、C5的结果构建FPN。如图3所示,它的基本流程为:由上至下对C2、C3、C4、C5进行卷积操作,对不同维度生成特征,随后由下至上从C5进行上采样,与C4卷积后的结果相融合,把融合后的结果上采样,再与C3卷后的结果融合,重复上述过程一直到C2;完成上述特征融合操作后,得到P2、P3、P4、P5,再将P5经过一次pool_size为1×1、步长为2的最大池化操作,得到P6,从而实现多尺度特征融合。

图2 ResNet101主干特征提取网络
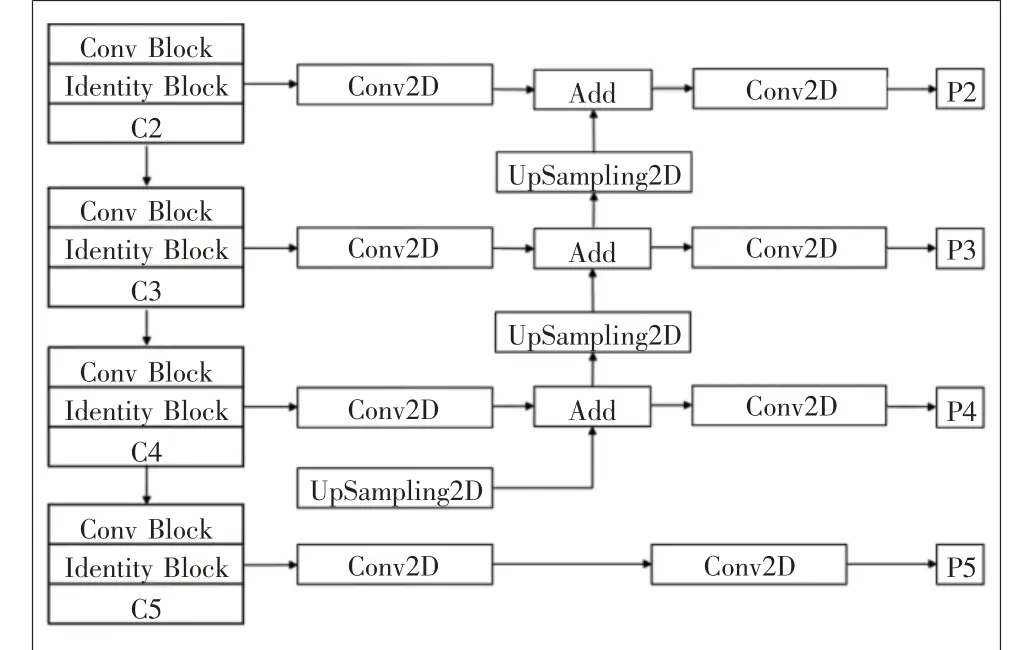
图3 金字塔特征提取网络结构
2.2.2 RPN模块
RPN首先由Faster R-CNN提出,其主要作用是提取候选框。把FPN提取到的P2、P3、P4、P5、P6作为RPN网络的有效特征层,上述有效特征层在图像中时就是特征图,首先对特征图进行一次通道数为512、卷积核大小为3×3的卷积。对于特征图上的每一个点(即锚点,anchor point),生成具有不同尺度和宽高比的RoI,随后进行NMS(非极大值抑制)筛选出得分较高的RoI。然后将这些RoI输入到两个网络层中去,其中一个网络层用来分类,使用通道数为6、卷积核大小为1×1的卷积预测公用特征层上每个网格点上的每个预测框内是否包含了物体(即这个RoI里面的特征图是否属于前景);另一个网络层输出4个位置坐标,使用anchors_per_location×4的卷积预测公用特征层上每个网格点上的每个先验框相对于真实物体框的偏移。
获得上述4个位置坐标后使用RoI Align,解决了RoI Pooling操作中2次量化造成的区域不匹配(mis-alignment)的问题,并且提升了模型的检测精度。主要是取消了量化操作,使用双线性差值的方法(如图4)获得坐标为浮点数的像素点对应的图像数值,从而将特征聚集的过程转化为一个连续的操作。
若已知点Q11=(x1,y1),Q12=(x1,y2),Q21=(x2,y1),Q22=(x2,y2)。
在x方向的线性插值为

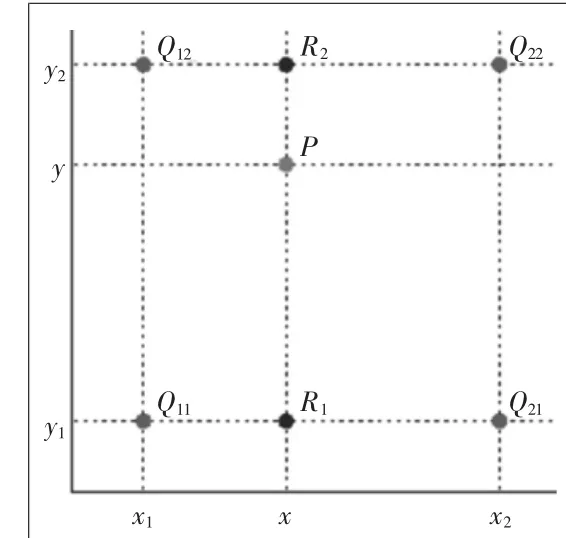
图4 双线性差值示意图
遍历每一个候选区域并对候选框进行双线性插值操作,保持浮点数边界不做量化;将候选区域分割成k×k个单元,每个单元的边界也不做量化;在每个单元中计算固定4个坐标位置,用双线性插值的方法计算出这4个位置的值,然后进行最大池化操作(如图5)[7]。
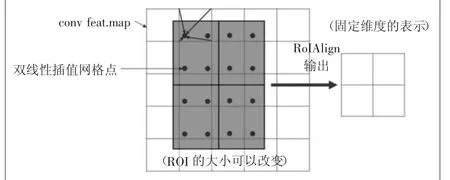
图5 RoI Align示意图
对经过RoI Align的RoI进行一次通道数为1024、卷积核大小为7×7的卷积和一次通道数为1024、卷积核大小为1×1的卷积。以上两次通道数为1024的卷积是用于模拟两次通道数为1024的全连接,然后再分别通过全连接层和softmax及全连接层和Rshape操作,分别得到建议框内物体类别和建议框的调整参数,经过参数调整后的建议框就是最终的预测框。
在mask分支里,其首先对经过RoI Align的RoI进行resize操作后,使其卷积核大小为14×14、通道数为256,对其进行4次通道数为256、卷积核大小为3×3的卷积,进行一次反卷积将面积扩大1倍,再进行一次通道数为num_classes的卷积,最后mask模型再对像素点进行分类,获得语义分割结果。
3 试验
3.1 试验运行环境
本试验是在Ubuntu18.04.3系统中运行,电脑处理器为Intel Core i7-9700,显卡为NVIDIA RTX 2060,内存为16G,试验框架为TensorFlow与Keras。
3.2 网络训练
本试验数据集来源于校内轨道,通过高速工业相机采集扣件图片。其中常见的扣件缺陷包括扣件断裂、扣件缺失、扣件螺母松动引起的扣件旋转等3种缺陷。因此本文自制了包括正常轨道扣件在内的4类数据集,分别是正常扣件(koujian)、断裂扣件(duanlie)、扣件缺失(queshi)、扣件旋转(xzhuan),各类样本如图6所示。

图6 正常扣件与缺陷扣件
上述缺陷扣件图像共采集150余张,正常扣件图像400余张,对缺陷扣件图像进行镜像、高斯模糊等操作后扩展到600张,其中各类缺陷各占200张。随机取出扣件图像420张、正常扣件280张组成训练数据集,再将剩余的180张缺陷扣件与120张正常扣件样本组成测试数据集。使用Labelme工具对数据集图像进行标注并以json文件存储。
使用Mask R-CNN网络训练时,学习率设置为0.001,训练50个epoch,每个epoch迭代250次,训练过程总计12 500次。损失函数曲线图如图7所示,横坐标表示训练的epoch的次数,纵坐标表示损失函数的计算结果。该曲线从第10个epoch损失函数曲线就已经趋于稳定,充分证明了本网络的优越性能。同时,也证明了本网络能使用较少的数据集就可以训练出一个相对理想的模型。实验结果如图8所示,预测框能够准确地预测、标记缺陷种类与扣件位置,并且也能通过语义分割较准确地分割出扣件形状。
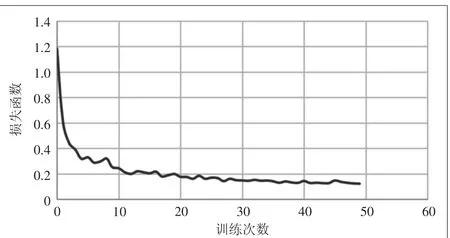
图7 损失函数图像

图8 部分实验结果样例
4 结语
本文实现了Mask R-CNN 网络在铁路扣件缺陷检测领域的应用,把采集到的正常扣与进行数据增强处理的缺陷扣件组成数据集,按照7:3的比例分为训练集和测试集。并且对该网络的结构及部分重点算法原理进行了简单分析,本文试验验证结果表明,相较于其他算法,不仅可以通过预测框分辨出缺陷类别,也可以通过语义分割后的图像形状分辨出缺陷种类。在不影响检测精度的条件下,进一步提升检测速度与语义分割的精度是后续主要的研究方向。
