基于物联网的种鸭育成测定数据平台的设计与实现
2021-04-18刘庆武付美艳张万民
刘庆武 付美艳 张万民


摘 要:对种鸭育成期的养殖过程中的数据进行人工处理存在强度大、效率低甚至数据错误等问题。采用软件即服务的模式,参照Lambda数据处理架构,将物联网技术与生物统计技术相结合,设计并实现种鸭育成测定数据平台,通过非介入、动态、实时的方式采集、分析与处理数据,充分挖掘数据的价值,为种鸭精准饲养和科学化管理提供必要的数据支撑。
关键词:种鸭;育成测定;物联网;生物统计;Lambda;数据平台;平滑处理
我国肉鸭消费具有多元化特点,瘦肉型与肉脂型北京鸭、优质小体型肉鸭、番鸭与半番鸭的年出栏量超过35亿只,产值约1000亿元。[1]肉鸭养殖在解决粮食危机、提高农民收入、保障优质蛋白供给以及促进农村稳定等方面发挥了重要作用。种鸭是肉鸭生产的基础,只有种质优良、体质健壮的种鸭,才能生产出更多的优质商品鸭苗。育成期是父母代种鸭生长中最重要的时期,也是决定种鸭能否获得高产、稳产的关键。这一阶段饲养的特点是对种鸭进行限制性饲养,即有计划地控制饲喂量(量的限制)或限制日粮的蛋白质和能量水平(质的限制)。[2]当前我国种鸭养殖分散、信息化水平低、基础设施投资不足,且应用企业引进的管理系统以单机版为主,各系统缺乏统一的接口而互不通用,造成信息孤岛,致使已有的信息化投入不能产生规模效应。[3]
物联网是基于计算机互联网的延伸与扩展,它是利用RFID(射频识别)、传感器等技术随时随地捕获物体的标识信息,通过各种通信网络进行可靠传输与信息共享,并借助智能的数据处理技术进行挖掘与分析,最终实现智能化控制与决断的覆盖世界上万事万物的“Internet of Things”。[4-5]
采用软件即服务(SaaS)模式,构建基于物联网的种鸭育成测定数据平台,将物联网技术与生物统计技术相结合,根据种鸭育成期的养殖过程的数据,通过生物统计分析与处理得到精准的饲料需求,为种鸭精准饲喂和科学化管理提供必要的数据支撑。
一、设计
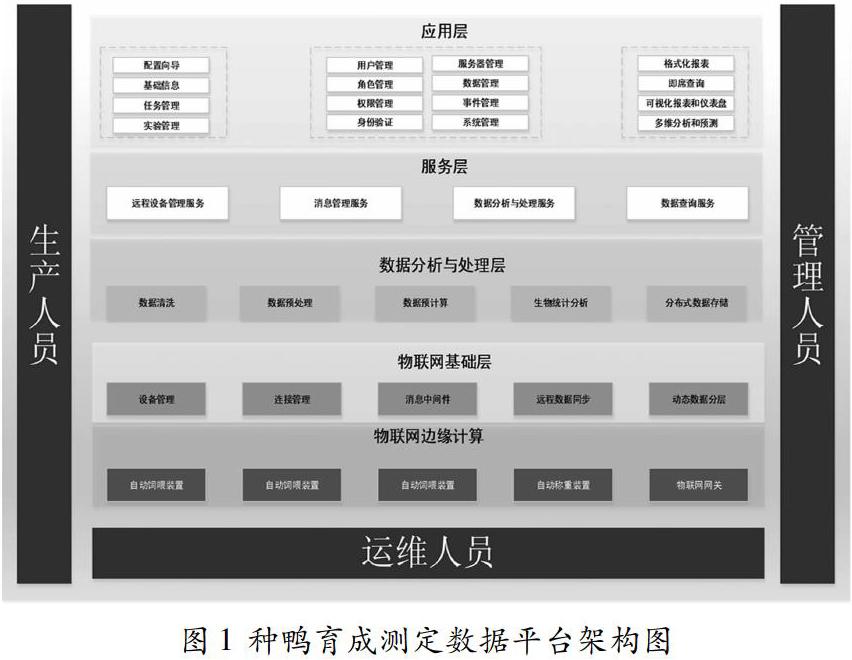
体系结构:遵循开放性、扩展性、安全性和可靠性等设计原则,种鸭育成测定数据平台采用“统一支撑平台框架、多个平台应用模组”的架构,如图1所示。
(1)物联网边缘计算(IoT Edge):是平台的数据来源,包括自动饲喂装置、自动称重装置、饲料余量监测以及物联网网关。通过物联网网关(IoT Gateway,可以是Rasberry Pi、Smart Phone、Local PC、Remote Server等)实现测定装置的互联互通以及实时数据缓存。
(2)物联网基础层(IoT Foundation):在物联网客户端的物理基础上,使用设备管理和连接管理功能实现设备集成,创建并且提供安全可靠的数据链路;通过消息中间件(MQTT、Kafka等)和远程数据同步获取育成测定数据;根据访问数据的频次,实现不同“温度”数据的动态分层存储。
(3)数据分析与处理层(Data Analyse and Process Layer):是平台的核心层,包括数据清洗、数据预处理、数据预计算、生物统计分析与分布式数据存储。数据清洗用于删除原始采食数据集和原始称重数据集中的无关数据、重复数据,平滑噪声数据,处理缺失值和异常值;数据预处理包括与企业管理信息系统的数据集成,对采集时间、采食量以及称重值的规范化处理。还需要利用基本属性构造出新的属性,例如个体日增重、个体日采食量、个体日累积采食量、个体日料肉比、个体日采食次数、个体日采食时长、个体日采食效率等。数据预处理一方面提高了数据质量,另一方面让数据更好地适应数据分析与处理的需要;另外,数据分析与处理层还包括生物统计中常用的假设检验和置信区间估计方法(参数假设检验、非参数假设检验、Bootstrap方法等),常用的回归方法(线性回归分析、非线性回归分析等)以及数据的分类、聚类分析(逻辑回归、支持向量机、随机森林的分类方法、K-Means等)。同时,将预处理后数据、预计算与统计分析的结果做进一步分布式存储。
(4)服务层(Serving Layer):包括远程设备管理服务、消息管理服务、数据分析与处理服务与数据查询服务。通过屏蔽不同类型设备的技术参数,为上一层(应用层)提供标准、统一的设备管理接口;通过屏蔽底层数据存储的差异性,为应用层提供标准、统一、方便、安全的数据查询接口;使用消息管理服务协调远程设备管理服务、数据分析与处理服务以及数据查询服务的协同作业。
(5)应用层(Application Layer):与服务层的统一标准不同,应用层提倡定制化与百花齐放。从数据源到数据采集、数据清洗、数据预处理、数据预计算、数据存储、数据服务,最终到数据应用,数据的价值只有在应用层才能真正得以体现。
应用层主要包括集中管理控制台CMC(Central Management Console)、企业配置向导与商业智能BI(Business Intelligence)。其中,集中管理控制台是基于Web的管理工具,用于执行大部分日常管理任务,例如角色管理、用户管理、权限管理、身份认证、数据管理和服务器管理等;企业配置向导是企业用户使用平台功能的前提和基础,包括注册企业基本信息、创建企业账号信息(包括企业管理员和任务管理员)、完善养殖企业的组织机构信息(包括养殖场信息、栋|舍信息、栏|圈信息、企業品种信息、企业品系信息、企业饲料信息以及企业个体信息等)、实验管理以及任务管理等;商业智能提供格式化报表、即席查询、可视化报表和仪表盘以及多维分析和预测等多种可视化数据分析与探索工具。
二、数据处理架构
参照Lambda架构设计思想,将数据处理架构分为批处理层(Batch Layer)、实时处理层(Speed Layer)、服务层(Serving Layer)。Lambda架构最重要的特征有:
(1)容错性:即使出现故障,仍然能够实际满足需要(如果出现故障,数据不会丢失,可以从主数据集重新计算);
(2)横向扩容:当数据量/负载增大时,可以通过增加更多的硬件资源来保证性能。也就是通常所说的线性可扩展,采用Scale out(即通过增加机器的个数)而不是Scale up(通过增强机器的性能);
(3)低延迟的读写过程:采用并行计算,尽量缩短了系统响应的延迟时间;
(4)快速查询:需要能够方便、快速地查询所需要的信息。
平台数据处理架构如图2所示:
(5)批处理层。输入的新数据将被导入批处理层和实时处理层。在批处理层,输入数据将被添加到Master数据集。批处理层对Master数据集进行迭代计算。当批处理层对全部数据进行批处理计算后,可以得到批处理视图,并且通过数据查询服务对外提供标准、统一、方便、安全的数据查询接口。批处理层通过定时任务的方式更新批处理视图,以保证数据的高容错性。
(6)实时处理层。实时处理层负责实时处理增量数据,通过实时计算更新实时视图,弥补了批量视图更新的较高延迟。
(7)服务层。服务层的任务是根据查询条件为用户查询提供支持。服务层随机访问视图,将批处理视图和实时视图的结果结合起来,最后反馈给应用层。
三、关键技术
个体称重数据的平滑处理方法。在育成测定应激期内,个体间存在不同程度的应激反应,也会出现多只挤入称重装置的现象。不可避免地导致干扰成分混杂进个体称重数据,通常这些干扰成分往往呈现非线性、非平稳性和非光滑性等特点,给后续数据分析和处理带来了误差甚至会导致错误。
为了从称重数据快速、高效地提取有用的特征信息,必须对称重数据进行平滑处理,即消除或抑制干扰成分的影响。使用局部加权回归散点平滑法(locally weighted scatterplot smoothing,LOESS),拟合一条连续的曲线,以该曲线作为基准,偏离较远的则标记为异常值点。MATLAB是美国Mathworks公司开发的应用软件,具有强大的科学及工程计算能力。[6]它不但提供了专门用于数据平滑处理的smooth函数,而且通过MATLAB引擎可以调用MATLAB中大量的数学计算函数,完成复杂的计算任务,从而简化用户程序设计的任务。
个体称重数据平滑处理流程图如图3所示。
(1)从历史称重数据表和实时称重数据内存表中获取指定个体的历史称重数据和实时称重数据,合并成完整的个体称重数据集;
(2)从平台配置信息中分别读取两次平滑处理的SPAN值(即窗宽值)与基于参照称重值的上下相对浮动范围;
(3)使用MATLAB引擎,调用封装后的smooth函数(MATLAB提供了多种调用格式,实际使用Z=smooth(Y,SPAN,METHOD),其中Z为平滑处理后的个体参照称重数据;Y为个体称重数据,SPAN为窗宽值,取0.2;METHOD为平滑方法,取lowess,即加权线性拟合,一阶回归)对个体称重数据集进行第一次平滑处理;
(4)遍历个体称重数据集,逐一判断该值是否偏离设定1允许的范围。如果已偏离,则标记为异常称重数据(只作标记,不删除)。遍历后,筛选出第一次平滑处理后新的个体称重数据集(不含已标记异常值的称重数据);
(5)重复(3)~(4),得到经过两次平滑处理的个体称重数据集。
四、分布式关系型数据库
种鸭育成测定数据平台在SAP的SQLAnywhere网络数据库的基础上,通过横向扩展的方式,构建“集中管理系统数据库—企业基本信息数据库—企业育成测定数据库”的三级、分布式关系型数据库。
(一)集中管理系统数据库(CMC System Database)
CMC系统数据库用于存储与维护种平台运行的所需公共基础信息,包括:币种信息、国家信息、区域信息、时区信息、语言信息、畜种信息、品种信息、品系信息、设备制造商信息、设备类型信息;企业信息、角色信息、权限信息、用户信息、用户个性化信息;企业基本信息数据库的路由信息、系统参数信息和服务器信息。
(二)企业基本信息數据库(Enterprise Master Database,Scalable)
企业基本信息数据库用于存储与维护养殖企业基础信息,包括养殖场信息、栋舍信息、栏圈信息、生物个体信息、群组信息、群组成员信息、设备信息、测定任务信息、饲料信息、饲料价格变动信息、原料信息、原料价格变动信息等;在育成测定过程中必要的操作信息,包括:个体健康状态标记、个体淘汰、更换饲料、更换个体耳标;以及企业育成测定数据库路由信息。
(三)企业育成测定数据库(Enterprise Slave Database,Scalable)
企业育成测定数据库用于存储与维护在育成测定过程中生成的原始数据、预处理后的数据、预计算以及生物统计分析的计算结果,包括:原始称重数据、原始空腹称重数据、原始采食数据、原始环境数据、原始设备状态数据、预处理后的称重数据、预处理后的采食数据、预处理后的环境数据、个体日结数据、群体日结数据、设备报警信息等。
五、防错与出错处理
在参照Lambda架构的基础上,通过多级分布式存储和基于生命周期的动态管理相结合的方式存储和维护育成测定过程中的数据(包括原始数据、预处理后的数据、日结数据以及生物统计分析数据),不仅可以启动、结束育成测定任务,而且可以暂停(支持多次)、重启(支持多次),有效地避免人为操作失误或其他未知原因造成的异常和错误。
另外,种鸭育成测定平台以“事件”的方式按照预设的事件类型,详细记录事件发生源、事件类型、是否已启用报警、事件的文字描述、事件发生的时间以及处理结果。
六、应用案例
种鸭育成测定数据平台配合中国农业科学院北京畜牧兽医研究所先后完成北京鸭Z10(测定起止时间:2019-09-01 11:48:51~2019-09-26 05:56:56,测定鸭只数量:38),Z78(测定起止时间:2020-05-27 16:04:41~2020-03-25 11:45:24,测定鸭只数量:483)以及Z4(测定起止时间:2020-04-07 17:09:06~2020-04-30 03:29:37,测定鸭只数量:407)的育成测定任务。一方面提高了养殖企业的自主智能化程度,大大降低人力成本和劳动强度;另一方面改变了养殖场传统的人工处理方式,彻底解脱了管理人员烦琐的、重复的、甚至不准确的手工汇总统计工作,为种鸭育成期的精准饲养和科学化管理提供必要数据支撑。
参考文献:
[1]侯水生.我国水禽产业技术的发展战略[J].水禽世界,2011(6):8-9.
[2]张武鹏.育成期种鸭的饲养管理技术[J].养殖与饲料,2007(1):17-18.
[3]韩红莲,张敏.发达国家畜牧业物联网模式对我国的启示[J].黑龙江畜牧,2015(5)28-29.
[4]沈彦君.物联网技术在智能图书馆中的应用[J].国家图书馆学刊,2012,21(02):51-54.
[5]王艳军,吕志勇,黄蕾.基于物联网传感器的城市交通状态预测[J].武汉理工大学学报,2010,32(20):108-111.
[6]张亮均,等.MATLAB数据分析与挖掘实战[M].北京:机械工业出版社,2015(6):7-8.
作者简介:刘庆武(1977— ),男,山东济宁人,硕士,工程师,研究方向:软件技术生物统计;付美艳(1980— ),女,山东平度人,硕士,副教授,研究方向:计算机应用技术;张万民(1959— ),男,山东寿光人,硕士,教授,研究方向:物联网软件工程。
