基于HGSVMA模型的露天矿卡车行程时间动态预测研究
2021-04-17顾清华马平平闫宝霞卢才武
顾清华,马平平,闫宝霞,卢才武,陈 露
(1.西安建筑科技大学资源工程学院,陕西 西安 710055;2.中国有色金属工业西安勘察设计研究院有限公司,陕西 西安 710043;3.西安建筑科技大学管理学院,陕西 西安 710055)
近些年,在许多露天矿中已经开始应用露天矿卡车调度系统[1-3],并通过不断优化卡车调度系统[4],来降低运营成本和提高采矿效率[5]。卡车调度系统的运行是基于卡车调度模型和卡车动态调度规则,而这些动态调度规则严重依赖于精确的卡车行程时间预测[6-8]。所以,精准的卡车行程时间预测是提高卡车调度效率的重要途径。
多年来,国内外学者一直致力于研究露天矿卡车行程时间预测。孙庆山[9]提出的多型号卡车运输的矿山路段运行时间统计模型,利用统计的卡车行程时间的平均值作为预测值,其难以准确有效地预测行程时间;张莹等[10]采用非平稳时间序列ARIMA模型对道路运行时间、电铲装车时间等时间参数进行预测,这类模型只考虑路段距离长短对行程时间预测的影响,存在预测精度低、实时性差的问题;白润才等[11]提出了多影响因素下的神经网络(ANN)行程时间预测函数模型,考虑了道路状况、卡车类型和卡车装载状态等因素,证明了行程时间预测函数是复杂的非线性函数关系;李建刚等[12]建立的基于模糊神经网络推理系统(ANFIS)的实时动态预测模型,提高了网络模型的精度和收敛速度;ERARSLAN[13]开发了一个计算机辅助系统来估算不同阻力的速度,通过道路长度除以卡车速度得到卡车行驶时间;王强等[14]利用stat:Fit软件对露天矿卡车调度关键时间参数的概率分布进行了研究,结果显示道路运行时间符合正态分布,电铲装车时间符合对数正态分布,卸载时间可看做一个稳定的常数;薛雪等[15]针对卡车行程时间实时性,预测精度不足的问题,提出了一种基于最小二乘支持向量回归(LS-SVR)的选择性集成学习算法,解决了露天煤矿实时调度中的行程时间预测问题;孟小前[16]针对是否需要将路径进行划分来预测行程时间的问题,建立BP神经网络和支持向量机SVM模型进行对比研究,研究结果表明分路段情景下的模型可以取得更好的预测效果,且SVM模型的精度高于BP模型;SUN等[17]将机器学习方法与大数据相结合预测露天矿卡车调度时的实时链路行程时间,其考虑气象特征因素影响后,预测精度提高了5.13%。
上述预测模型各有其自身的特点,但在行程时间预测的精度和实时性方面仍有所欠缺,本文在以上成果的基础上,采用具有完备理论体系的支持向量机(support vector machine,SVM)作为建模理论基础,利用遗传算法优化支持向量机的惩罚函数C、核参数g和损失函数ε。在此基础上建立了基于HGSVMA模型的露天矿卡车行程时间预测模型,选取卡车状态、速度、载重量、路面坡度、路面类型、起终点长度、转弯次数、时段和是否降雨作为自变量,行程时间作为因变量。采用HGSVMA模型进行训练预测,并将该模型的预测结果与GS-SVM模型、PSO-SVM模型和GA-SVM模型的预测结果进行对比分析。
1 HGSVMA模型
1.1 支持向量机
SVM算法最初于20世纪90年代由CORTES和VAPNIK提出[18],该算法用于回归预测的主要思想是建立一个分类超平面作为决策曲面,将样本数据映射到高维特征空间进行线性回归,从而求解出多影响因素下的最优回归函数。
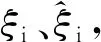
(1)
通过引入拉格朗日函数可将其转换为以下对偶形式,见式(2)。
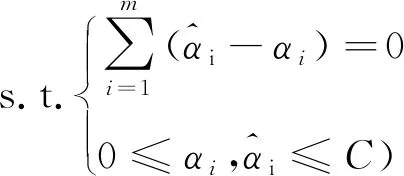
(2)
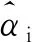
考虑特征映射,将支持向量机的核函数K(xi,xj)=φ(xi)×φ(xj)代入得到式(3)。
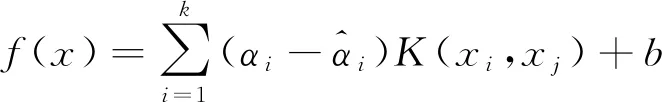
(3)
本研究选择径向基核函数(RBF)进行预测。径向基核函数表达式见式(4)。
K(xi,xj)=e-g‖Xi-X‖2
(4)
式中,g为核函数参数。
1.2 基于遗传算法改进支持向量机
首先,利用训练样本数据集对SVM模型进行训练,得出预测值与实际值之间的平均绝对误差;然后将该误差的倒数作为算法适应度函数,通过遗传算法的选择、交叉、变异进行迭代寻优,在迭代过程中,搜索SVM的关键参数C、g和ε;最后,建立基于HGSVMA模型的露天矿卡车行程时间预测模型进行预测。 其基本流程如图2所示,基本步骤如下所述。
1) 初始化参数。种群规模M,种群中个体的交叉概率Γ,变异概率ψ,最大迭代次数T,惩罚函数C、核参数g和损失函数ε变化范围。
2) 初始化种群。首先利用遗传算法先生成一个种群,将这个种群中的每个个体进行解码再生成SVM的初始化参数。
3) 建立SVM模型计算行程时间预测结果,计算预测值与真实值之间的误差。
4) 计算个体适应度值Fi,见式(5)。训练SVM模型,以真实值与预测值误差绝对值平均值的倒数即平均绝对误差(MAE)的倒数作为适应度值。
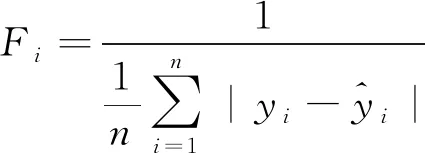
(5)
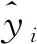
5) 执行选择操作,采用精英个体保留策略将优良个体直接保存下来。首先,从步骤4中计算的适应度值中选择适应度值最高的个体直接遗传到下一代群体中;其次,再计算剩余个体的适应度总和S(式(6)),以及个体的选择概率Pi(式(7));最后,通过计算个体的累积概率,按照轮盘赌的方式选择被选个体进入子代种群(式(8))。
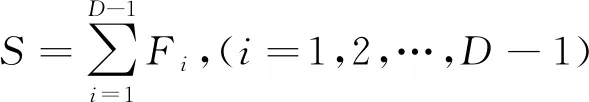
(6)
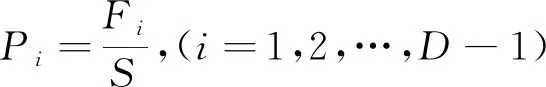
(7)
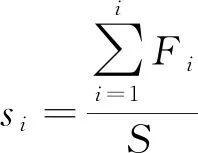
(8)
6) 执行交叉操作,采用次序交叉策略对基因加以替换重组而产生新个体。首先,随机选择一对染色体(父代)中基因片段交叉的起止位置(相同位置);其次,生成与被选中的基因和父代在同一位置的子代;最后,找出选中基因在另一个父代中的位置,然后在子代中依次放置其余基因。如图1所示。

图1 次序交叉策略实例Fig.1 Example of sequential crossover strategy

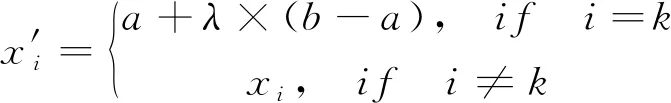
(9)
式中:λ为[0,1]之间的随机数;a和b分别为个体xi的下界和上界。
8) 对训练个体进行选择、交叉、变异操作后得到的新一代进化种群个体,经过反编码得到SVM新参数,输入到SVM行程时间预测模型中进行预测,得到预测结果。
9) 如果预测结果与实际值之间的误差达到设定的精度或达到最大迭代次数,算法终止,输出预测结果;否则,返回步骤三循环执行,直到满足条件,算法终止。
HGSVMA模型流程图如2所示。
2 实证分析
2.1 数据样本
研究以构建河南某大型露天矿卡车调度模型为背景,并为解决卡车在车流规划模型中的行驶时间预测问题展开。本研究根据文献[9]和文献[10]选取卡车状态x1、速度x2、载重量x3、路面坡度x4、路面类型x5、起终点长度x6、转弯次数x7、时段x8和是否降雨x9共9个因素作为输入变量,行程时间作为输出变量。
在卡车智能调度生产系统平台中,选取该矿区2018年8月5辆电动卡车的1 478 746条历史GPS轨迹数据为基础数据,并在中国气象局(CMA)57077号监测站提取该月的气象数据。为了消除各数据特征间由于量纲不同、原始样本数量级之间较大差异和算法的收敛速度不同所造成的影响,对特征影响因子进行线性归一化处理,利用式(10)将影响因子统一映射到[0,1]区间内;通过数据预处理总共得到3 410组数据,将数据集进行随机排序,按7∶3比例分为训练数据集和测试数据集,带入模型中进行训练预测。数据见表1。
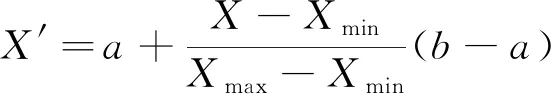
(10)

图2 HGSVMA模型流程图Fig.2 Flow chat of HGSVMA model

表1 行程时间预测示例数据Table 1 Example data of travel time prediction
卡车状态x1分为空车和重车,分别用0和1表示;路面坡度x4可以在[-8,+8]中取值(“+”表示上坡;“-”表示下坡);路面类型x5分为干线和半干线两种类型,分别用0和1表示;降雨x9分为无降雨和有降雨,分别用0和1表示。
2.2 模型评价指标
本文选取3项评价指标对预测结果进行评价对比,分别为绝对误差(MAE)、平均绝对百分比误差(MAPE)和平均平方误差(MSE),其评价指标公式为式(11)~式(13)。其中,MAE和MAPE评价算法的精度,MSE评价算法的稳定性。
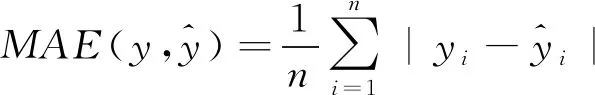
(11)
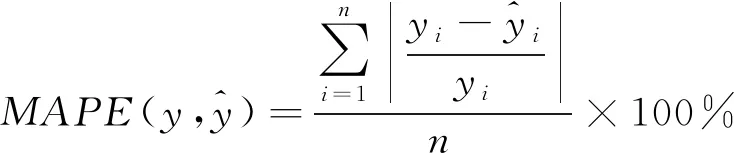
(12)
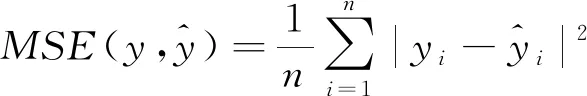
(13)
2.3 模型参数选取
本研究使用Matlab9.4.0.813654(R2018a)进行仿真实验,选取SVM模型的核函数为径向基核函数。设置模型参数如下:初始化种群规模M=20,个体的交叉概率Γ=0.4,变异概率ψ=0.1,最大迭代次数T=100,学习因子c1=1.5,c2=1.7;惯性权重0.6;交叉验证参数5;惩罚函数C变化范围[0,100];核参数g变化范围[0,1 000];损失函数ε变化范围[0.01,1]。
2.4 模型预测结果
根据建立的HGSVMA露天矿卡车行程时间预测模型,HGSVMA模型在经过100次进化计算得到的最佳适应度曲线如图3所示。
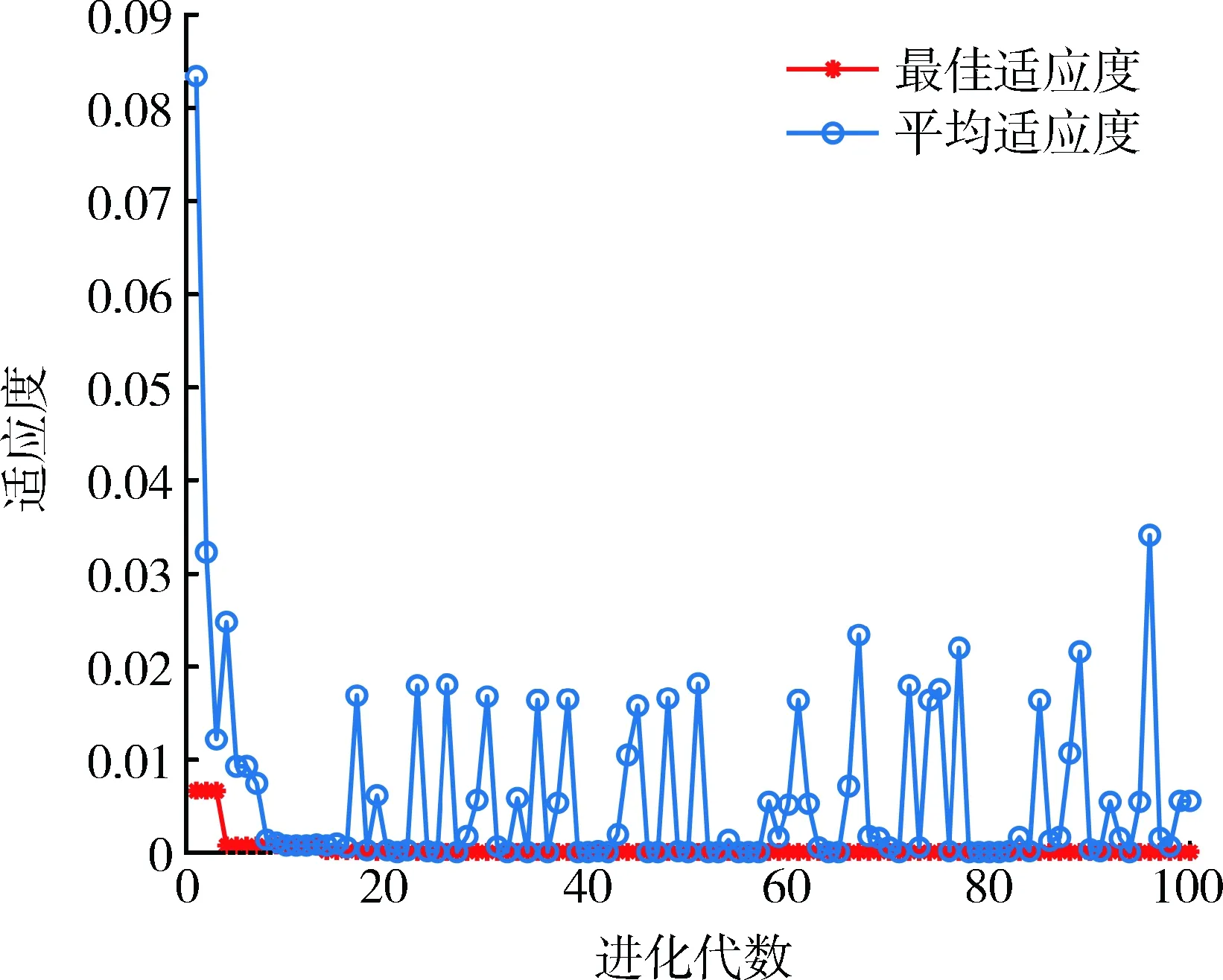
图3 适应度曲线Fig.3 Fitness curve
由图3可知,迭代曲线最佳适应度在进化到5代后就逐渐趋于平稳,说明改进后的算法能克服标准SVM不能克服的过学习问题,可认为近似达到最优解,此时适用于HGSVMA模型的最佳惩罚项C、核函数参数g与损失函数参数ε的值分别为62.60、0.77和0.01。将这三个参数代入SVM模型中,对测试数据集进行预测,得到测试结果如图4所示。
由图4(a)为HGSVMA模型的预测拟合效果,图4(b)为每一样本数据与HGSVMA模型预测结果之间的绝对误差值,可以看出其绝对误差介于0~0.06之间,误差相对较小。表明HGSVMA模型可以较好地拟合测试数据集。
为验证改进的参数优化算法对模型拟合精度和收敛性的优化效果,同时与GS-SVM、GA-SVM和PSO-SVM三组模型用于露天矿卡车行程时间预测的性能进行比较,其部分预测结果见表2和图5。
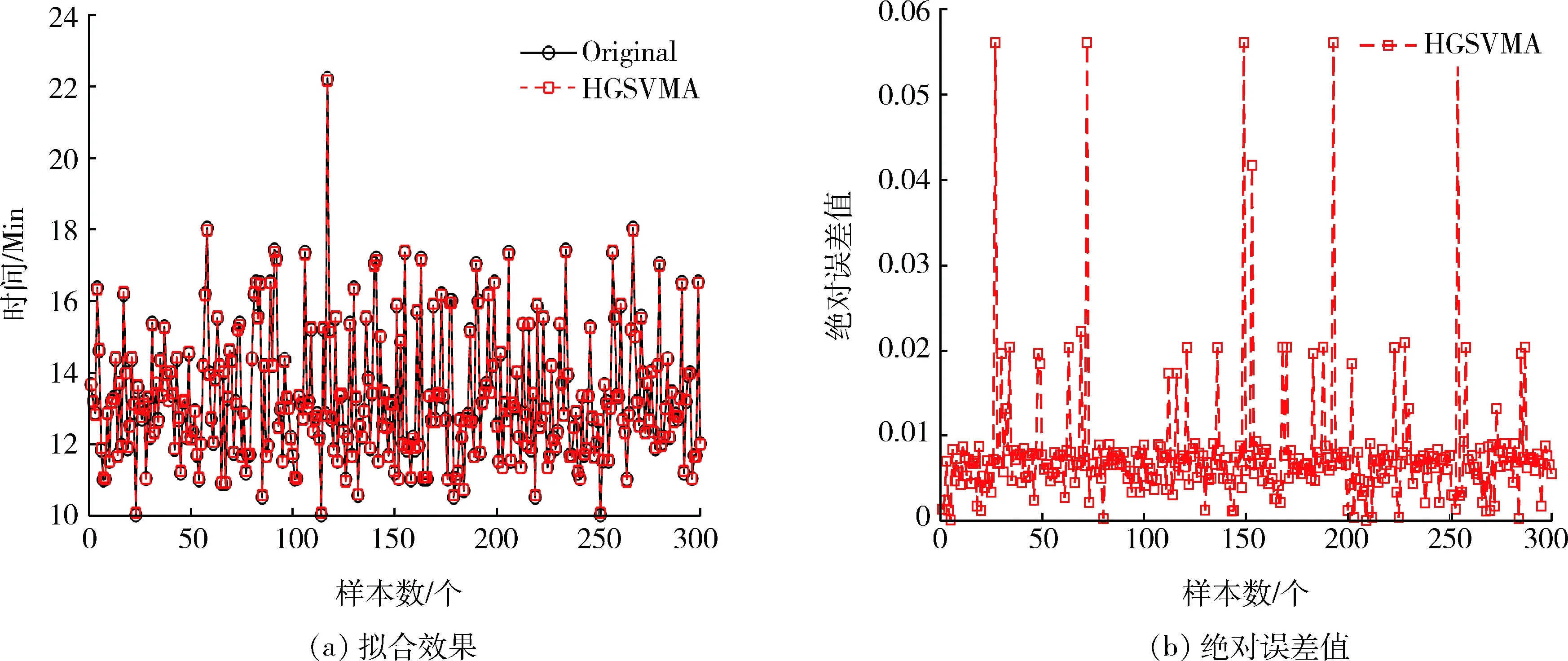
图4 HGSVMA模型预测结果Fig.4 Prediction results of HGSVMA model
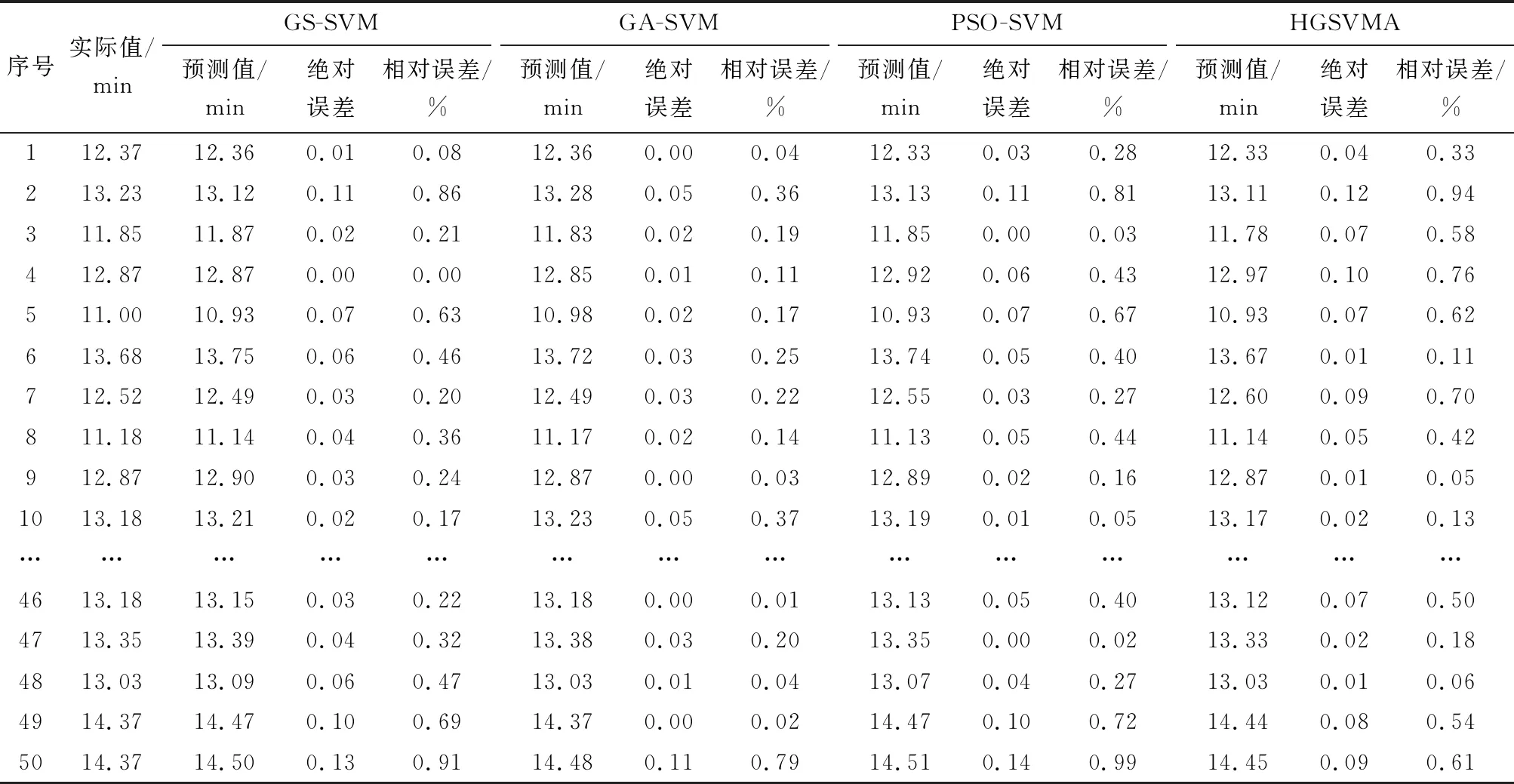
表2 不同预测模型回归结果比较(部分)Table 2 Comparison of regression results of different prediction models(part)
图5(a)为HGSVMA模型和GS-SVM模型、GA-SVM模型和PSO-SVM模型对测试数据集的拟合效果;图5(b)为每一样本数据与不同模型预测结果之间的绝对误差值。从图5可以看出,HGSVMA模型的绝对误差值相对最小,而PSO-SVM模型的误差值最大,GS-SVM模型次之。表明HGSVMA模型可以较好地拟合测试数据集。
为了进一步比较模型预测性能的优劣,通过使用模型计算得出的MAE、MAPE和MSE评价指标值见表3。
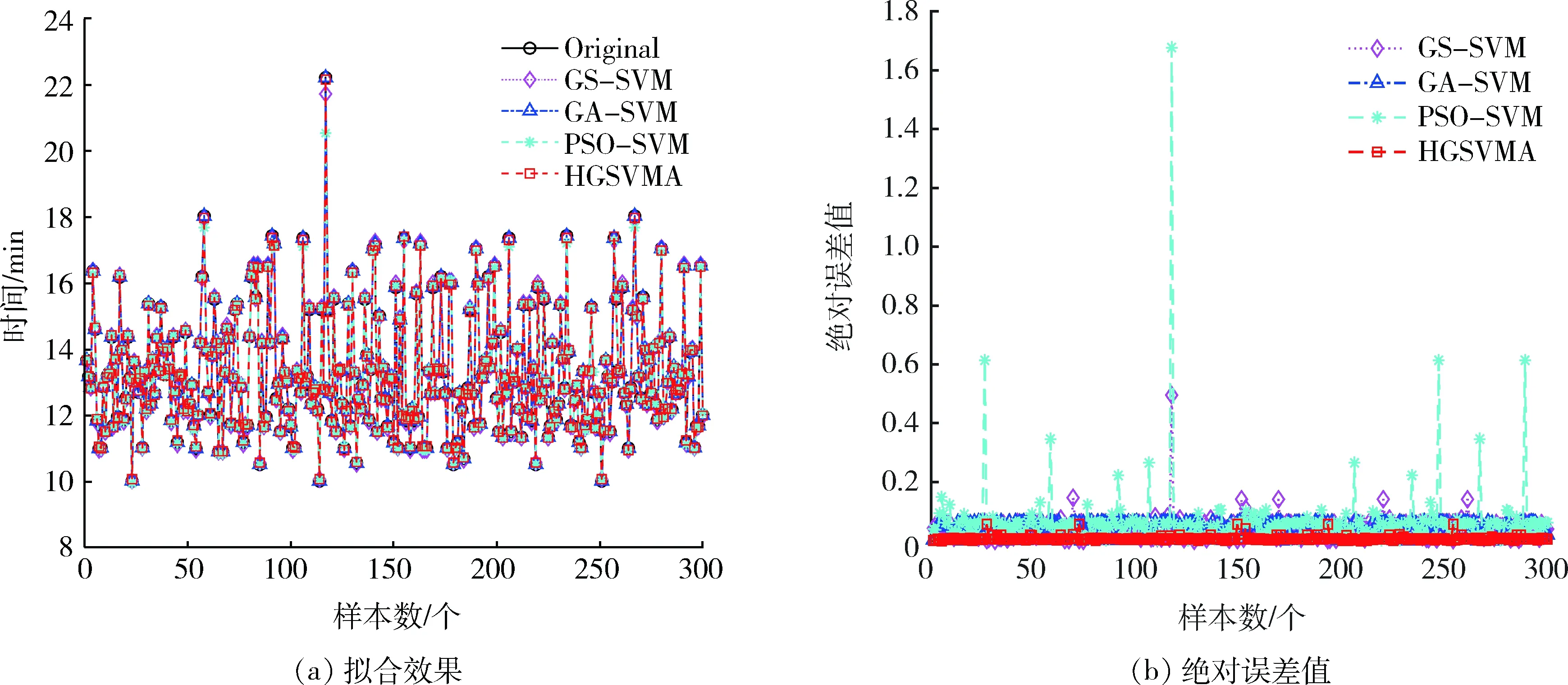
图5 不同模型预测效果(部分)Fig.5 Prediction results of different models(part)

表3 预测结果比较Table 3 Comparison of prediction results
预测精度方面,通过比较表3中各模型的MAE和MAPE值可知,HGSVMA模型精度最高,GA-SVM模型次之,MAE和MAPE指标均较GA-SVM模型提高了81.67%和81.17%。表明HGSVMA模型可以明显提高预测露天矿卡车行程时间的准确性。
预测可靠性方面,通过比较表3中各模型的MSE值可知,HGSVMA模型的可靠性最高,GA-SVM模型次之,HGSVMA模型的可靠性较GA-SVM模型提高了10.45%。表明HGSVMA模型可以明显提高预测露天矿卡车行程时间的可靠性。
为进一步验证模型在行程时间预测方面的实时性,对样本数据集进行了100次的重复实验,并记录实验的运行时间。最后50次实验的运行时间如图6所示。
由图6可以看出,GS-SVM模型和PSO-SVM模型的运行时间随机性相对较大,而GA-SVM模型和HGSVMA模型的运行时间相对较平稳。由于在露天矿卡车实时调度过程中,调度系统需要平稳运行,并且响应时间要尽量短。因此,基于HGSVMA模型可以很好地满足这些条件,以解决卡车行程预测问题。

图6 样本数据重复实验运行时间Fig.6 Sample data repeated experiment run time
3 结 语
针对露天矿卡车行程时间预测问题,本文利用遗传算法全局并行搜索优化的特点,对SVM参数进行寻优,建立了基于HGSVMA模型的露天矿卡车行程时间预测模型。利用从某大型露天矿卡车调度系统所采集的卡车行程时间进行仿真模拟,结果表明:HGSVMA模型与GS-SVM模型、PSO-SVM模型和GA-SVM模型相比,其MAE、MAPE和MSE指标平均提高了78.71%、84.13%和60.58%,表明HGSVMA模型具有很高的预测精度。下一步拟将本文的露天矿卡车行程时间预测模型应用到露天矿卡车调度系统中,这将有助于提高露天矿卡车的调度效率。
