矿区土地复垦历史文献数据挖掘方法及应用研究
2021-04-17胡钰琳张绍良于娅娜侯湖平杨永均公云龙
胡钰琳,张绍良,2,于娅娜,侯湖平,杨永均,公云龙
(1.中国矿业大学公共管理学院,江苏 徐州 221116;2.矿山生态修复教育部工程研究中心,江苏 徐州 221116)
0 引 言
自20世纪80年代大规模开展矿区土地复垦研究以来,我国很多矿区已经积累了大量的复垦数据资料,包括复垦技术、复垦经验、复垦质量、复垦评价和示范工程等信息。这些历史文献不仅可以为矿区未来土地复垦提供直接的、廉价的资料,而且可形成“历史数据链”,为矿区综合治理、系统修复提供决策支持。尤其是其中“反复”的研究区介绍、采样、试验和分析结果等,如果系统归纳、提炼,也就是数据挖掘,可形成该矿区土地复垦和生态修复的“知识”。因此,引入数据挖掘技术不但可节省研究时间,而且可节约研究成本,避免“重复”研究,为大数据时代矿山土地复垦和生态重建的研究提供新的研究“范式”。本文尝试利用数据挖掘技术,结合Python语言编程,对矿区土地复垦历史科技文献开展信息集成和知识发现,并以徐州矿区为例开展实证研究,为矿区土地复垦与生态修复研究探索一条新的途径。
1 矿区复垦信息数据挖掘概述
1.1 研究现状
数据集成、分析、预测、建模和数据挖掘、可视化等是大数据时代的基本技术[1],国内外许多专家已经研发出了许多与数据挖掘有关的软件,取得了长足的进步[2],并应用于经济领域[3]、社会领域[4]和文化领域[5]等。矿区信息数据挖掘已经能实现地质数据特征的表述、对比、联系、聚类以及分析等功能,并且已经有数据挖掘的软件问世[6]。为了从海量的地质信息中找到有效的信息,有学者开发了语义检索模型[7]。然而,数据冗余、数据冲突及其真伪识别等,给矿区土地复垦与生态重建信息集成和知识发现提出了挑战。
1.2 数据特点
数据挖掘就是在大量的、不完全的、有噪声的、模糊的随机数据中,提取隐含在其中的、人们事先不知道的潜在有用信息和知识的过程[8]。矿区土地复垦文献资料是研究人员日积月累形成的重要知识成果,但由于主题不同、内容不同、格式不同等特点,使得信息分散,制约了信息集成的难度和应用价值。
由表1可知,区别于传统数据环境,矿区土地复垦文献资料的数据特点在数据类型、数据筛选、数据挖掘等方面都有极大的不同。由此可见,必须开发有针对性的数据挖掘方法,才能对矿区土地复垦文献进行精准挖掘,才能在大量的历史文献资料中准确快速地识别出矿区基本信息、开采及其影响信息、复垦信息等。
2 矿区复垦信息数据挖掘方法
2.1 数据挖掘步骤
1) 首先根据《现代汉语分类词典》中的分类规则对矿区土地复垦文献关键词进行编码化处理。
2) 利用标签LDA模型改进TF*IDF方法[9],构建关键词-文献矩阵。
3) 以CD_Sim方法访问矩阵计算关键词相似度,建立空间向量模型、应用AP聚类方法确定该矿区土地复垦文献的主题要素。
4) 运用Python可视化编程语言遍历文献,根据聚类结果和其他需要提取的重要信息,进行数据挖掘与集成分析[10-11]。
5) 以文本数据库作为核心结合空间与属性数据库,采用C#可视化编程语言,结合ArcEngine在VS.NET环境中实现GIS的二次开发,建立能够呈现该矿区土地复垦历史数据的信息管理系统。
2.2 关键技术
2.2.1 TF*IDF算法
首先将文献关键词按《现代汉语分类词典》中5个级别层次进行体系分类。由表2可知,以“采矿”和“采煤”的编码“陆三Hb01”为例,两个词语编码位均相同,可认为两词语完全相似,相似度为1;若两个词语的编码位有一位不同,则两词语相似度为0。

表1 数据特点Table 1 Characteristics of data

表2 编码规则示例Table 2 Code rule example
其次,利用TF*IDF算法计算词语重要性,计算见式(1)。

(1)
式中:pij为关键词在待分析文档中出现的数量;TFij为pij与待分析文档中总词语数量pj的比值;IDFi为逆文档频率;N为样本数量;ni为文档中包含词语ti的数量。
根据词语重要性wij构建关键词-文献权重矩阵,在待分析文档中关键词出现的频率利用样本D将频数向量表示出来,则样本D表示为式(2)。

(2)
2.2.2 CD_Sim方法
采用CD_Sim方法计算关键词相似度,其思想为访问关键词-文献矩阵,找到待度量关键词返回其编码,根据公式对编码相似度进行计算,返回关键词相似度。
定义:假设有关键词A的编码为“a1a2a3a4a5”,关键词B的编码为“b1b2b3b4b5”,语义重合度为k1。见式(3)。
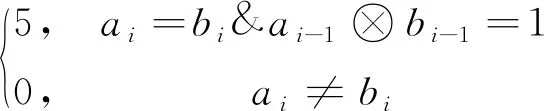
(3)
选取相同的语义长度(即编码后的位数相同),从而方便计算语义重合度。以关键词“生态”“环境”“景观”为例,对其进行编码后计算每两个词语之间k1的值,见表3。

表3 k1计算结果Table 3 Calculated results of k1
分析表3可知,通过语义重合度利用CD_Sim方法对词语之间的相似程度进行一个标准化的衡量计算,见式(4)。
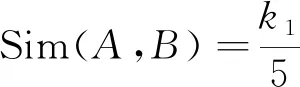
(4)
设文献i中有M个关键词{x1,x2,…,xm}(m=1,2,…,M),文献j中有N个关键词{y1,y2,…,yn}(n=1,2,…,N),smn为第i个文献中的关键词m与第j个文献中的关键词n的相似度。计算文献i与文献j中所有关键词的相似度矩阵,见式(5)。
2.2.3 AP聚类方法
采用聚类分析不仅可以确定文献主题要素,同时检验文本相似度量效果。相比较其他聚类方法,AP聚类可以按照自身特性,选取合理聚类数目进行聚类。根据关键词相似度计算结果,通过AP聚类算法对待聚类文献进行自动聚类,由于不同文献主题包含子主题,根据聚类数目和实际文献数目决定是否继续执行聚类操作,直至聚类数目基本不再变化或者接近于1。
2.2.4 基于Python语言的信息提取
Python语言可以对ArcGIS进行脚本的编写,可快速实现GIS基本功能的编码化[10-11],嵌入Python语言将提高土地复垦历史文献数据挖掘的工作效率。选取Python语言中的PDFMiner模块[12-13]进行解析处理,通过Python语言进行编程,即可在Excel中提取到对应的信息。
2.2.5 ArcGIS二次开发
该系统包括应用层、中间层以及数据层等三层结构。使用COM连接三层结构,这样具有面向对象、可重用性、语言独立、过程透明和版本升级稳健等优点[14]。中间层包括系统的主要功能模块,数据层中包括地理空间数据、属性数据以及文本数据。该系统减少了系统设计与实现之间的相互作用,降低了各层之间依赖程度的同时,也提高了本文系统的可扩展性,使得功能更加连贯,数据可以实时更新。
3 应用研究:以徐州矿区为例
3.1 数据挖掘过程
以中国知网(CNKI)文献库为基础,以“土地复垦”“生态修复”“徐州矿区”“塌陷地”“植被恢复”“土壤改良”等作为文献索引主题词,将时间区间设置为1980—2019年,检索到研究文献518篇。下载文献并利用Python爬取其关键内容,如“题目”“发表时间”“关键词”“摘要”等,形成独立文档,以便计算机自动读取。
利用TF*IDF算法计算词语重要性,构建徐州矿区土地复垦与生态修复历史文献的样本矩阵,文献主题从初值开始不断分词,不断聚类,不断更新,不断替换。
以随机选取的四篇文献为例。对分词结果进行编码化处理,处理结果见表4。据此计算相似度,计算结果见表5。根据关键词相似度计算结果,通过AP聚类方法对关键词进行聚类,并将原始关键词替换为该关键词聚类中心,该替换过程如图1所示。
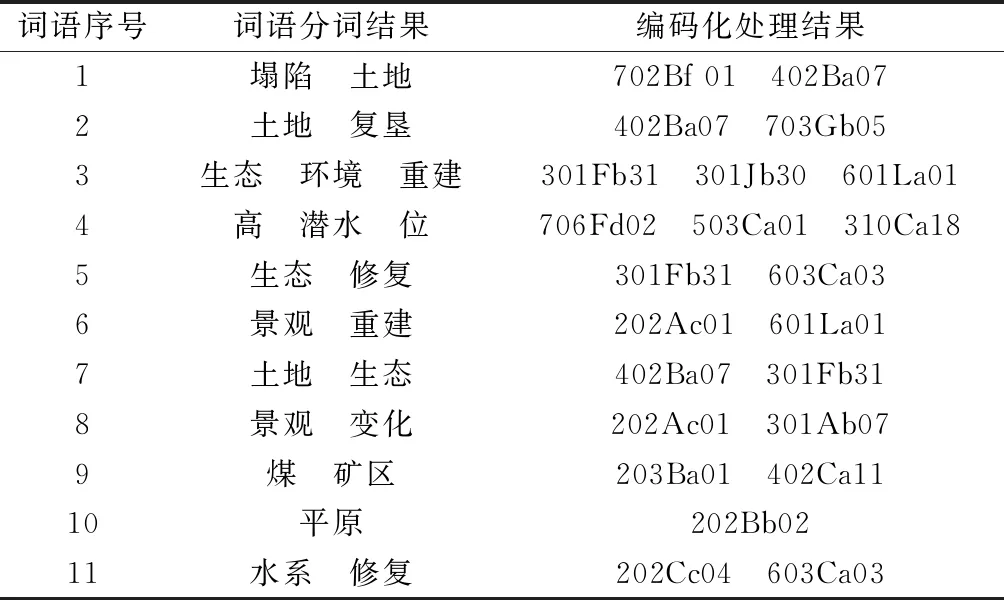
表4 分词与编码化处理结果Table 4 Treatment results of word segmentation and encoding
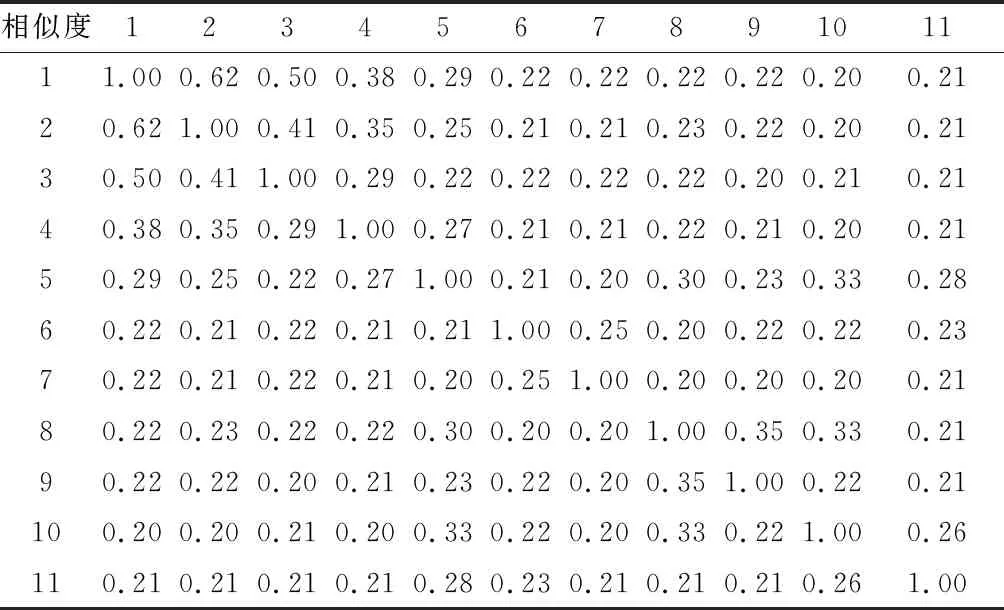
表5 关键词相似度计算结果Table 5 Calculation results of keywords similarity
确定文献的主题要素后,遍历文献找到特定主题要素关键词,将其对应的有用信息提取出来,利用ArcGIS二次开发技术将数据挖掘结果进行综合、集成,建立徐州矿区土地复垦与生态修复信息管理系统并开展时空数据分析。
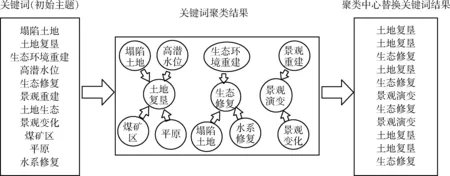
图1 关键词替换实例Fig.1 Keywords replacement example
3.2 数据挖掘结果
3.2.1 研究区域及时间的挖掘结果
结果表明:1995年以后徐州矿区土地复垦的研究逐渐增多,2014年达到高峰,数量最多(图2)。主要研究区域是庞庄矿区、新河-卧牛矿区、义安矿区、垞城矿区、张集矿区、贾汪矿区、大黄山矿区和董庄矿区等(图3)。
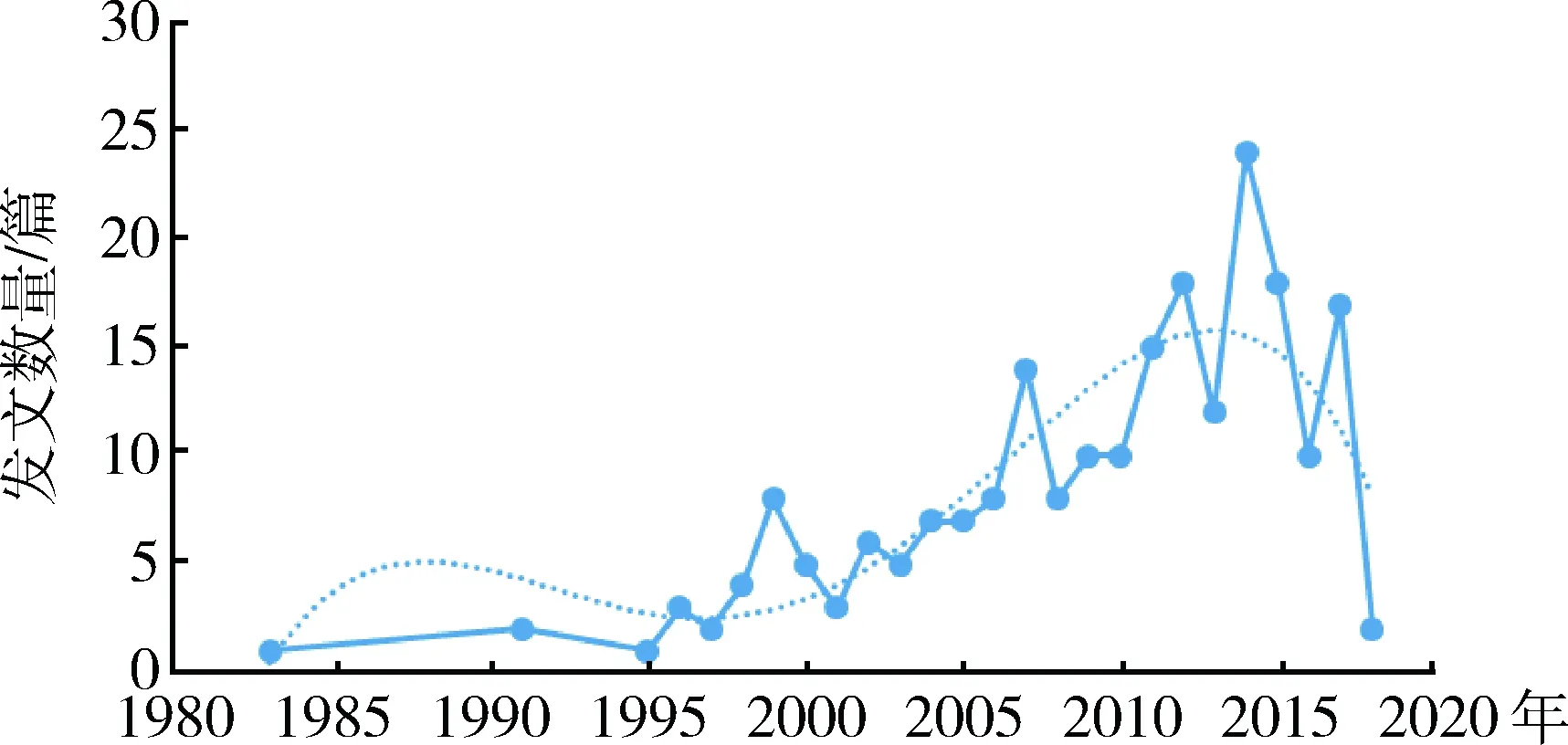
图2 历年研究文献统计Fig.2 Statistics of historical literature
3.2.2 煤炭开采影响的挖掘结果
根据文献主题要素挖掘徐州矿区复垦文献,可以从挖掘结果中发现如下情况。
1) 土壤改良情况。徐州矿区煤炭开采对土壤的理化性质、碳效应均产生了影响,存在重金属污染现象。以土壤理化性质的挖掘结果为例,可见粉煤灰充填方法更适合徐州矿区(图4)。
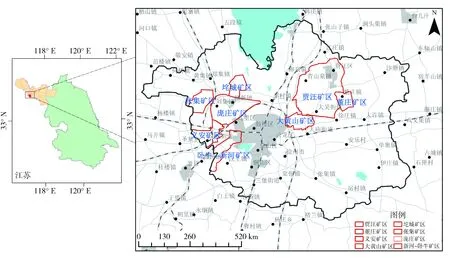
图3 重点区域分布图Fig.3 Key area distribution map
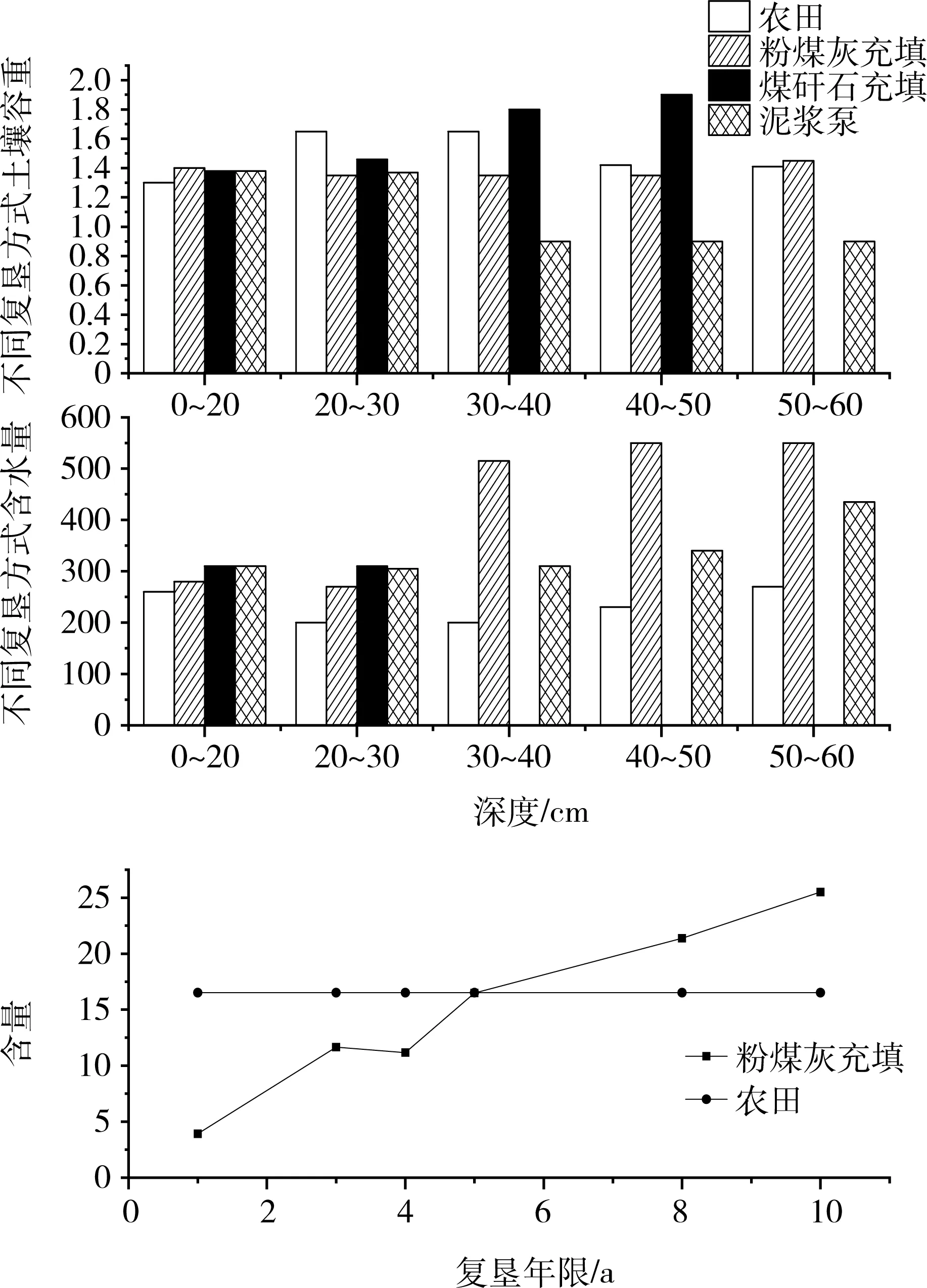
图4 矿区土壤理化特性挖掘情况Fig.4 Soil physical and chemical properties of mining area
2) 水文治理情况。徐州矿区曾发生水害、水资源短缺、水污染、地表水系紊乱等问题。以水污染状况挖掘结果为例,徐州庞庄矿区的权台矿井水中多环芳烃含量较高,因此对其生态修复的治理将更为严峻(表6)。
3) 植被修复情况。徐州矿区植被净初级生产力随煤矿的开采强度增大而下降,但闭矿后逐渐恢复。
4) 景观格局演变情况。景观格局在采矿前后发生显著变化;最主要特征是塌陷积水面积显著增加。
5) 塌陷地情况。挖掘得到徐州市域范围内矿区的历史概况以及塌陷状况。以贾汪矿区挖掘结果为例,其基本信息如图5所示。
3.2.3 复垦技术与示范工程的挖掘结果
结果表明:徐州矿区曾成功开发出了泥浆泵复垦、基塘复垦、煤矸石充填复垦、高效农业复垦、建设用地复垦、生态湿地修复、景观修复、采矿迹地修复、关闭矿山地下水污染防控等技术体系,并得到大面积的推广。
以贾汪矿区的生态修复示范工程为例。贾汪矿区的采煤塌陷地复垦示范工程分布在青山泉镇、贾汪镇、紫庄镇和大吴镇,其中潘安湖生态湿地是近年研究的焦点,采用了“基本农田整理、采煤塌陷地复垦、生态环境修复、湿地景观开发”四位一体的模式。
4 讨 论
运用查准率(precision)、召回率(recall)、正确率T和F值来评判数据挖掘的精度,见式(6)~式(9)。
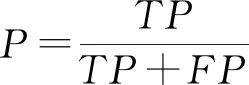
(6)

(7)
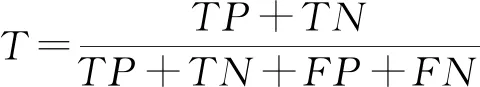
(8)
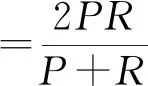
(9)
式中:TP为挖掘文献数量;TN为真无效数量;FN为假无效数量;FP为人工处理的文献数量与挖掘模型得到结果的文献数量的差值;P为对数据挖掘的准确性;R为衡量数据挖掘的相关性;T为数据挖掘结果的正确率;F值为数据挖掘算法的总体性能。
通过整理TP、FP、FN、TN的值,对数据挖掘的结果进行对比分析[15]。以不同矿区评价结果为例,见表7。
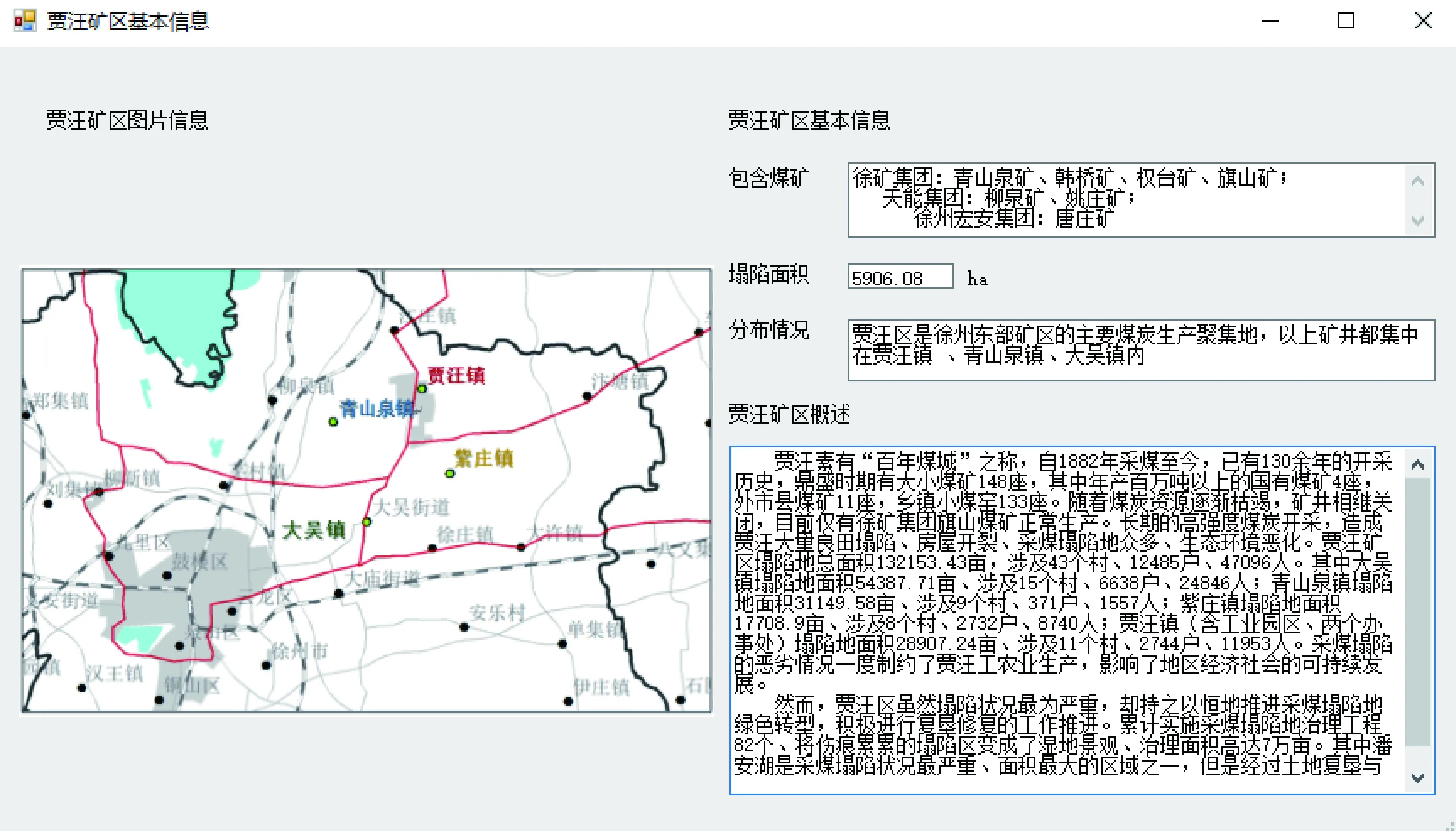
图5 贾汪矿区概况Fig.5 Overview of Jiawang mining area

表6 庞庄矿水样中多环芳烃含量Table 6 Pahs in water samples from Pangzhuang mine

表7 不同矿区挖掘结果性能指标对比Table 7 Comparison of performance indexesof different mining results
从表7可以看出,利用数据挖掘得到的结果比较准确,证明该方法高效可行。通过少量的人工参与,确定了矿区土地复垦历史文献研究的主题要素,避免了“重复”研究,可以弥补人工统计时的无目的性、费时费力等不足,实现矿区土地复垦的信息集成与知识发现。
5 结 语
随着我国对矿区生态环境修复的重视,矿区复垦文献也不断增多,采用数据挖掘技术,可弥补人工统计的不足。另外,矿区历史面貌很难通过现场调查复原,而历史文献较完整记录了其原貌,所以数据挖掘技术可发挥恢复历史“数据链”的特殊作用。本文通过对土地复垦历史文献关键词分词编码化,构建TF*IDF算法和空间向量模型、聚类分析,采用Python语言进行数据挖掘,最后在ArcGIS基础上二次开发,显示数据挖掘结果。以徐州矿区为例,开展实证研究,得到了徐州矿区的塌陷情况、复垦技术以及示范工程等重要历史信息,克服了土地复垦历史文献的数据冗余、数据冲突以及真伪识别等难点。据此表明数据挖掘技术可实现矿区土地复垦与生态重建信息的集成与知识发现,为矿区系统修复、综合治理提供基础数据支撑。
