基于多输出网络的无参考平面图像质量评价研究
2021-04-15林康立钱保军龚有为梁法其王晓虎
沈 暐, 林康立, 钱保军, 龚有为,梁法其, 王晓虎, 刘 浏
(1.中国联合网络通信有限公司 物联网研究院,无锡214000;2.中国联合网络通信有限公司无锡市分公司,无锡214000;3.无锡市公安局 技术防范管理支队,无锡214000)
0 引 言
近年来,随着深度学习的兴起,神经网络广泛地应用于图像处理和计算机视觉等领域,特别是在图像识别、分类的任务方面。深度学习模型需要大量训练数据,且模型参数越多,需求量就越大。现有用于质量评价的图像库规模非常小,由于质量评价与图像识别等任务不同,所以将深度神经网络直接应用于质量评价有难度[1]。Kang等首次将卷积神经网络应用于平面图像质量评价,实现了端到端的无参考模型,将图像分成多个不重叠的补丁,扩充了数据集,满足训练需求[2]。朱睿等针对JPEG2000图像失真,构建了卷积神经网络模型[3]。Cheng等结合图像显著性知识提出评价模型,认为图像中的非显著区域使卷积神经网络预测误差增大,故在将图像分割成不重叠的小块后,去除非显著区域的小块并为其分配权重,将显著区域的小块输入卷积神经网络预测体系,最后采用汇集策略得出图像分数[4]。
深度卷积神经网络在提取特征时,每一层特征的特点都是不同的。浅层网络提取的是纹理、区域等细节特征,深层网络提取的是轮廓、形状和边缘等结构特征。图像失真类型众多,评估不同类型的失真所需要的特征也不同。以往,深度网络的最后一层特征用于分类、回归等任务,而考虑到浅层和深层网络特征对感知失真的影响,本文提出了一种基于多输出卷积神经网络的端到端无参考图像质量评价模型。该模型设计了三个输出,将浅层和深层特征分别回归到主观质量评分上,最后将三个输出的平均分数作为最终质量得分。这种多输出的网络结构,综合了三个学习机的结果,因此具备了集成学习的优点。实验结果表明,本文方法与人类主观评分具有较高的一致性。
1 多输出卷积神经网络算法设计
1.1 不同卷积层的特征分析
深度卷积神经网络的优点是可以通过多层卷积自动提取特征,且不同卷积层提取的特征是不相同的。文献[5]利用特征可视化技术,对不同卷积层的特征进行研究。可视化一幅图像经过多次卷积后的特征图如图1所示,图中左边是每层卷积得到的特征图,右边是每一层的特征图1∶1融合后得到的特征图。图1的第一行是Original image,第二行左侧是Low-level feature maps,右侧是Fused feature map,第三行是左侧是Mid-level feature maps,右侧是Fused feature map,第四行是左侧是High-level feature maps,右侧是Fused feature map。
可以看出,随着层数的加深,卷积核提取的内容越来越抽象,保留的信息也越来越少,特征被不断提取和压缩,最终得到了比较高层次特征。因此,浅层网络提取的是纹理、区域等细节特征,深层网络提取的是轮廓、形状和边缘等关键结构特征。相对而言,层数越深,提取的特征越具有代表性。
传统上,最后一层的特征已用于分类、回归等任务。图像失真类型种类很多,但大致可以分为结构失真(如模糊、JPEG等)和非结构失真(如各种噪声),评价这些失真类型所需要的特征是不同的,有的甚至相互抵触。分析结构失真主要需要轮廓、形状和边缘等结构特征(即深层网络特征),而分析非结构失真则需要纹理、区域等细节特征(即浅层网络特征)。本文提出的多输出卷积神经网络模型,利用不同卷积层提取不同特征,同时使用低层特征和高层抽象特征,正好适应了这种不同失真类型需要不同特征的要求。在噪声类型较多的TID2013数据库上的实验结果进一步表明,使用浅层网络特征会明显改善噪声失真的图像质量评估效果。
1.2 多输出卷积神经网络模型
受到目标检测网络SSD[6]汇集多尺度特征的启发,本文提出了一个端到端的多输出卷积神经网络模型,设计了三个输出,将浅层特征和高层特征分别回归到主观质量评分上,最后平均多个输出的分数作为最终质量得分,该网络结构如图2所示。网络输入的是经过预处理的32×32大小的无重叠图像块,卷积层采用5×5大小的卷积核,池化层采用最大池化来降低卷积层提取的特征图维度,池化大小均为2×2。该网络在结构上可以看作是三个卷积神经网络简单的拼接,因为它有三个全连接层分别用于回归映射到主观质量评分上。然而,该网络不仅可以端到端进行训练,而且将低层特征和高层特征联系了起来。
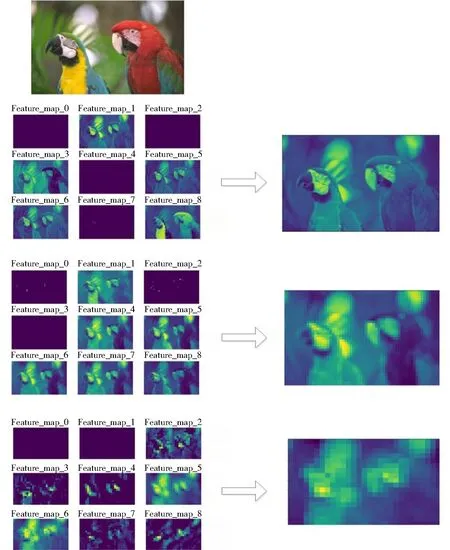
图1 不同卷积层的特征可视化Fig.1 Visualization of characteristics of different convolution layers
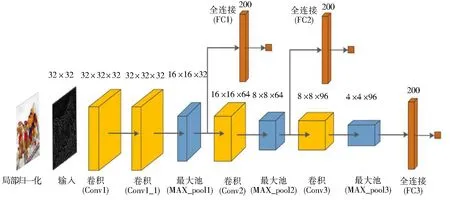
图2 多输出卷积神经网络结构Fig.2 Structure of multi-output convolutional neural network
2 多输出卷积神经网络算法实现
2.1 图像预处理
对所有训练图像和测试图像进行局部归一化,包括简单的空间带通操作和简单的除法归一化。该处理步骤参考文献[2,7-8]。Ruderman发现对失真图像进行局部归一化后,其直方图会趋于正态高斯分布,从而使网络在亮度和对比度变化方面具有鲁棒性[9]。Mittal等研究表明当图像产生失真时,其局部归一化后的统计特性也发生改变,且该改变是可预测的[8]。局部归一化处理方法如下,假设图像像素点(i,j)上的亮度值为I~(i,j),则局部归一化公式为:

式中:i=1,2,…,M;j=1,2,…,N;M和N分别为图像的高度和宽度;I(i,j)和μ(i,j)分别表示像素的局部均值和方差;C是常数,以防止分母为0;P和Q是归一化窗口大小。文献[8]表明,较小的归一化窗口可以提高性能,所以选择P=Q=3,使得窗口大小比图像块小得多。
LIVE库中的图像局部归一化后的概率密度图如图3和图4所示。可以看出,对图像进行局部归一化后,其概率密度趋于正态高斯分布。不同类型或不同等级的失真所对应的概率密度分布是不相同的,模型通过自适应学习失真引起的不同统计分布来学习质量预测。


图3 参考图像和不同失真类型图像的局部归一化图及其概率密度分布图Fig.3 Local normalization map and probability density distribution of reference image and images with different distortion types

图4 参考图像和不同等级的Blur失真图像局部归一化图及其概率密度分布图Fig.4 Local normalization map and probability density distribution of reference image and Blur distortion images with different levels
2.2.1 网络的调整与学习
网络的训练有两个阶段:前向传播阶段和反向传播阶段。

在第一阶段中,首先初始化权重参数w和偏置b。输入经过预处理的图像块,经过卷积层、池化层向前传播逐层提取特征。计算公式为:式中:Zl为l层的输出且为l+1层的输入;ul+1为l+1层的输出;f为ReLU激活函数;wl+1和bl+1分别为l+1层的权重和偏置。
在第二阶段中,通过损失函数计算预测值与真实主观评分之间的误差。本文网络采用的损失函数为欧氏距离损失函数,其定义为:

式中:E为损失值;Yn为预测值;yn为样本标签,即主观评价分数;N表示图片数。
由于本文的网络有三个输出,因此在每次池化后都会应用非线性回归在池化层计算多个损失,如式(7)所示。然后将池化层的误差通过反向传播的方式直接传递给卷积层来更新权重,计算公式为:


2.2.2 网络参数设置
从预处理的图像中采样32×32大小的非重叠图像块得到训练数据。由于数据库中的失真图像都是均匀失真,所以每个图像小块的实际主观评分都采用该图像的主观分数。在测试时,通过平均图像块的预测质量分数来计算图像的质量得分。
本文采用Nesterov加速梯度下降的方法来优化损失函数[10],该方法可以使网络快速收敛。为避免梯度消失问题,在两个全连接层中使用ReLU激活函数。为防止过拟合,在全连接层中使用了Dropout技术[11],概率设置为0.5。
其他参数设置如下:动量(Momentum)设置为0.9,批量大小(Batchsize)设置为64,初始化学习率设置为0.01,重量衰减(Weight decay)设置为0.0005,学习率更新方式如下:
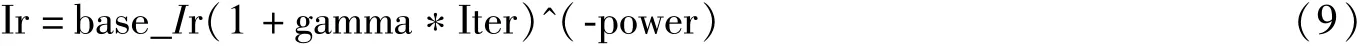
式中:base_Ir是初始化学习率;Iter为当前迭代次数;Gamma是学习速率变化因子,设置为0.000 1,指数power设置为0.75。
网络每一层的参数如表1所示,输入和输出参数。其中:k代表卷积核大小或局部窗口大小;m为卷积核个数(通道数);s表示步长;p表示扩充边缘大小。
3 实验结果
3.1 实验结果与分析
本文在LIVE图像库、TID2013图像库和LIVE MD图像库上进行了实验。为了减小数据分布差异,将图像数据库中的标签归一化在(0~1)。每个图像库都被分为训练集、验证集和测试集三个数据集,分别占图像库中图片数量的80%、10%和10%。这三个数据集中的数据相互独立,互不重叠,保证了实验的公平性。将LIVE图像库上的实验结果与三种有效的全参考方法(SSIM[12]、PSNR[13]和FSIM[14])和五种近期的无参考方法(M3[15]、HOSA[16]、FRIQUEE[17]、BPRI(p)[18]和DB-CNN[19])进行比较,如表1所示。
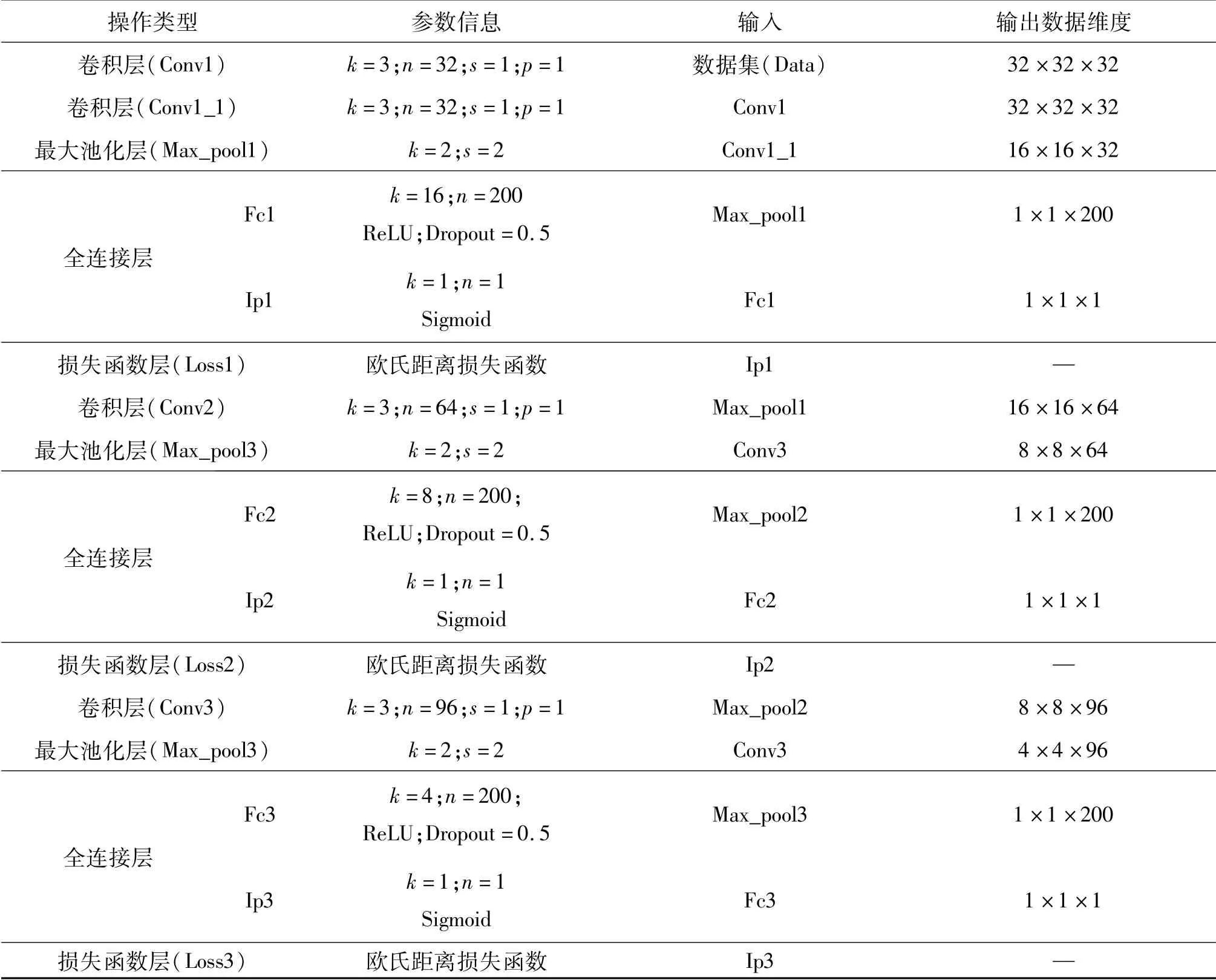
表1 网络结构参数Table 1 Network structure parameters
LIVE图像库上实验获得的评价指标如表2和表3所示。本文所提出的方法与对比方法存在竞争性。虽然在预测JP2K和FF失真时,本文方法得到的SROCC值低于全参考方法SSIM,但是在预测WN和Blur失真时,本文实验结果极其接近真实值。在总体失真上,本文方法获得了较为优异的结果。

表2 不同方法在LIVE图像库上获得的PLCC值Table 2 PLCC values obtained by different methods in LIVE image library
LIVE图像库中随机抽取的三张失真图像如图5所示,其中标注了失真类型、预测分数与实际分数。可以看出,使用本文模型得出的预测分数非常接近人为打分。不同失真类型的预测值和DMOS的散点图如图6所示,其中横坐标是图像标签,纵坐标是预测分数。可以看出,散点分布集中且呈线性分布,说明所提出的方法与人类主观评分一致。

表3 不同方法在LIVE图像库上获得的SROCC值Table 3 SROCC values obtained by different methods in LIVE image library

图5 LIVE图像库中部分失真图像的预测分数Fig.5 Prediction of partial distortion images in LIVE image library
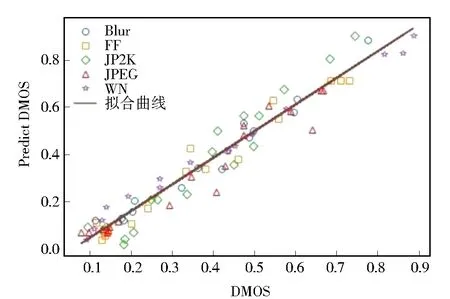
图6 LIVE图像库中的预测值与DMOS值的散点图Fig.6 Scatter plots of predicted values and DMOSvalues in LIVE image library
本文方法与对比方法在TID2013图像库上获得的SROCC值如表4所示。TID2013图像库是最具挑战性的合成数据库。在总体失真上,本文方法略低于DB-CNN方法所获得的结果,相差0.5%左右;然而大部分单失真类型上,本文方法获得了优异的结果,表现出了对单失真预测的优越性能,尤其是对噪声失真图像的预测能力更强。在NEPN、LBD、CC、CCS和MS失真上,对比方法的SROCC值都在0.63以下。不同失真类型的预测值和MOS值的散点图如图7所示。可以看出,绝大多数散点围绕在拟合曲线周围,分布集中,说明本文模型具有良好的性能。

图7 TID2013图像库中的预测值与MOS值的散点图Fig.7 Scatter plots of predicted values and MOS values in TID2013 image library

表4 不同方法在TID2013图像库上获得的SROCC值Table 4 SROCC values obtained by different methods in TID2013 image library
本文方法与对比方法在LIVEMD图像库上获得的PLCC值和SROCC值如表5所示。LIVEMD库上的预测值与DMOS值的散点图如图8所示。实验数据表明,该方法在评价混合图像上也展现了良好的性能,进一步证实了本文方法的有效性。

表5 不同方法在LIVEMD图像库上获得的PLCC和SROCC值Table 5 PLCC and SROCC values obtained by different methods in LIVEMD image library

图8 LIVEMD图像库上的预测值与DMOS值的散点图Fig.8 Scatter plots of predicted values and DMOS values in LIVEMD image library
3.2 单输出网络的实验对比
实验使用了与本文模型相同的参数设置来训练三个单独的单输出网络。它们是三个简单的卷积神经网络,将其分别命名为N1、N2和N3。N1包括两个卷积层、一个池化层和两个全连接层;N2包括三个卷积层、两个池化层和两个全连接层;N3包括四个卷积层、三个池化层和两个全连接层。不同方法在LIVE库上的实验结果如表6所示,其中“Average”的含义是每张图像的质量得分为N1、N2和N3网络的预测得分的平均值。可以看出,本文提出的多输出模型提升了图像质量评估的性能,优于多个单输出网络预测分数的平均值。原因是较深层的权重调整受到共享浅层的定向训练的影响,反之亦然。实验结果进一步证实了多输出网络的鲁棒性。

表6 对比方法在LIVE图像库上获得的结果Table 6 Results of comparison methods in LIVE image library
3.3 模型参数比较与分析
3.3.1 图像块大小的影响
为了满足网络的训练需求,本文采用非重叠采样的数据增强方式扩充数据集。图像的预测得分为每个图像小块预测分数的和的均值,所以图像块大小可能会对实验结果产生影响。本文在训练阶段使用了6种大小的图像块。不同图像块大小在LIVE库上的实验结果如表7所示,最优结果在表格中显示。为了直观地显示预测结果的趋势,用折线图予以展示。由表7和图9的结果可知,图像块大小对实验结果的影响并不是很大。虽然小尺寸的图像块能够极大地增加数据量,但是其包含较少的失真特征信息,效果较差,例如24×24的图像块;而大尺寸的图像块会导致训练参数增多,训练时间加长。综合考虑,选择了36×36的图像块。

表7 不同大小的图像块在LIVE图像块上获得的结果Table 7 Results of different size image blocks on LIVE image blocks

图9 图像块大小和预测结果的关系图Fig.9 Relationship between image block sizes and prediction results
3.3.2 卷积核大小的影响
卷积操作是通过卷积核作用于局部图像提取图像信息的一种局部操作。本文测试了卷积核大小对模型的影响,不同卷积核大小在LIVE库上的实验结果如表8所示,表格中的符号“/”表示模型未收敛。使用四种尺寸卷积核时,网络训练的损失曲线图如图10所示。可以看出,使用3×3、5×5和7×7大小的卷积核的模型均能够达到收敛状态;使用9×9大小的卷积核时,损失曲线上下振荡,网络不收敛。虽然卷积核尺寸越大,感受也越大,但是大卷积核在训练时会导致参数增多,从而需要更多的样本。考虑到这种在计算复杂性和性能之间的平衡,本文将卷积核大小定为5×5。

表8 不同卷积核大小在LIVE图像库上的结果Table 8 Results of different convolution kernel sizes in LIVE image library

图10 使用不同大小卷积核模型的损失曲线Fig.10 Loss curves of convolution kernel models with different sizes
4 池化类型的影响
研究了两种池化类型对模型的影响,即最大池化和均值池化。使用最大池化、均值池化和组合池化策略时模型的预测结果如表9所示。表格中,Max_pool表示最大池化,Avg_pool表示均值池化。最大池化能够更多地保留图像的纹理信息,而均值池化保留了更多的图像背景信息[20]。由表中数据可知,使用均值池化效果较差,使用最大池化具有优势,所以选择采用最大池化。

表9 不同池化类型在LIVE图像库上获得的结果Table 9 Results of different pooling types on LIVE image database
5 结 论
大多数基于深度学习的图像质量评价工作使用单输出的深度网络。本文提出了一种基于卷积神经网络的多输出图像质量评价模型,可以同时学习浅层特征和高层特征,分别回归到主观评分上,最后平均多个输出的分数作为最终质量得分。这种多输出模型的一种优势是,兼顾了不同层卷积特征,具备了集成学习的特点,使模型的性能更加鲁棒。实验结果表明,本文模型具有优异的性能,与人类主观感受保持较高的一致性。
