改进多尺度CNN网络的运动模糊图像复原算法
2021-04-13王志盛
王志盛

摘要:针对多尺度CNN网络编码过程中存在获取特征信息不足,导致重建的去运动模糊图像质量不佳。该研究提出了一种将明暗通道先验嵌入多尺度网络,并在网络中引入双重注意力机制的解决方法,该方法增强了网络对先验信息的获取能力,加强重点信息获取的同时提高动态去模糊效果。该方法与同类方法相比峰值信噪比(PSNR)和结构相似度(SSIM)均获得了提升。
关键词:多尺度;明、暗通道;注意力机制;运动模糊;卷积神经网络
Abstract: The insufficient feature information obtained in the multi-scale CNN network coding process, which leads to the quality of the reconstructed motion deblur image is poor. A solution is proposed that embeds a priori of light and dark channels in a multi-scale network and introduces a dual attention mechanism into the network. The method enhances the network's ability to acquire prior information, enhances the acquisition of key information, and improves dynamic deblurring effects. Compared with similar methods, this method has improved the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM).
Key words:multi-scale;light、dark channel;attention mechanism;motion blur;convolutional neural network ( CNN)
近年來,动态场景中运动模糊图像复原已成为越来越多研究者关注的领域。运动模糊是图像拍摄中常见问题之一。拍摄设备在成像时受到抖动或者被拍摄物体运动速度过快,散焦等因素影响时,会产生低质量并且模糊的图像。图像去运动模糊技术在交通、军事、医学、工业界具有很高的应用价值。因此,运动模糊图像的复原问题具有重要的现实研究意义。
去运动模糊是从模糊图像中重建出清晰图像。运动模糊的恢复按照是否需要PSF(Point Spread Function)可分为盲去运动模糊和非盲去运动模糊。非盲去运动模糊是在PSF已知的情况下去模糊。然而,真实场景中PSF往往未知,因此,盲去运动模糊成为真实场景中恢复清晰图像的重要方式。图像模糊的数学模型可以看成清晰图像与模糊核的卷积过程,其公式为:
公式中,B为模糊噪声图像;I为原始清晰图像;K和N分别为模糊核和噪声;[?]是卷积运算。因为B为已知的,I与K未知,需要同时恢复I与K,这是严重的病态逆问题。I与K要进行合适的先验信息约束才能得到唯一解,实现图像清晰化。
目前盲去运动模糊方法可分为两类:一类是基于优化的方法,另一类是基于学习的方法。基于优化的方法在盲解模糊时可以灵活运用图像梯度、稀疏性[1]等约束,但是会产生优化耗时和过渡简化假设模糊核(假设运动模糊图像模糊核空间不变,非均匀模糊假设为均匀模糊)问题。基于优化的方法处理自然图像具有很好的优势。但是在特定领域的图像方面存在缺陷。因此,特定领域需要引入特定的先验信息。例如,处理文本图像采用显著强度和梯度的组合优于L0范数作为正则项,复原效果更好。Pan[2]等人利用图像去雾的暗通道先验来增强潜像暗通道的稀疏性,并在一般和特定图像上都取得了良好的效果。但是在处理非暗像素点时,该方法不奏效。随后,Yan[3]等人进一步引入了亮通道先验来解决包含非暗像素的模糊。在各种场景下取得了不错的效果。但是这种方案存在耗时的缺陷。
基于学习的方法通过训练数据学习映射函数,这种方法实质隐式地利用了先验信息。具有快速和灵活处理动态场景中空间变化模糊。由于缺乏真实场景下的模糊清晰图像对,文献[4-6]中的方法通过合成模糊核产生模糊图像进行训练。这些方法不是以端到端的方式,并且仍然需要估计模糊核。因此,这些方法仍然存在模糊核的估计不准确的问题,在真实数据集上的效果比人工生成的模糊效果差。Nah[7]等人采用了端到端的动态去模糊方法,这种方法抛弃了传统方法需要估计模糊核的缺点,提高了去模糊的效果。Tao[8]等人后来采用端到端的深度多尺度卷积网络,在接近真实的数据集上去除动态场景的运动模糊,进一步提升了效果。但是上述方法没有考虑到基于学习的方法是在深度神经网络内部学习盲解模糊的直接映射。以及当前数据集规模小,网络对某些特定先验信息不能获取。存在特征信息不能很好利用的缺陷,最终导致复原图像效果不佳。因此,本文从获取更多先验信息以及自适应学习重点模糊信息角度出发设计了一种改进网络结构。
1 网络结构
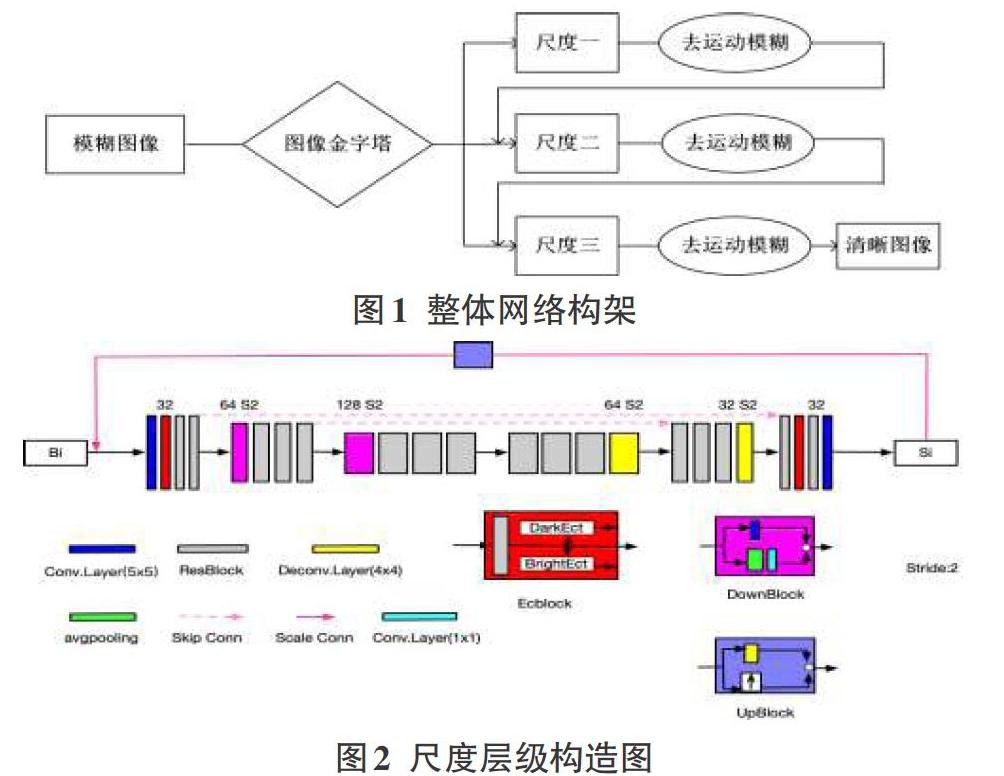
我们的网络由粗糙的低分辨率运动模糊图像逐渐恢复清晰的高分辨率图像。这种网络结构称为“由粗到细”的多尺度结构。各尺度采用相同的网络结构。网络的输入由3个分辨率不同的模糊图像Bi(i=1,2,3),它们由原始模糊图像下采样形成。下标i代表尺度层级,图像的分辨率随着i的增大顺序增加,尺度间隔比率设置为0.5。首先将尺度最小最容易恢复的模糊图像B1输入,恢复出其对应大小估计的清晰图像I1。然后将估计的中间清晰图像上采样到更大的尺度,与模糊图像B2一同作为下一尺度的输入,进一步引导更大尺寸的图像恢复。同理,最终获得最高分辨率的输出图像I3。这种框架结构可以降低网络训练难度,使得运动模糊图像更好的复原。整体网络结构如图1。
图2中尺度层级采用编码-解码网络结构,编码块和解码块的通道数的大小分别为32、64和128。步长为2的卷积层将通道数增加一倍,特征图尺寸变为原来的一半;相反,步长为2的反卷积层则特征图尺寸提升一倍,特征通道数减半。卷积核大小为5x5,下采样中的卷积核为1x1,反卷积核为4x4。编码块进行特征提取,抽象图像内容信息并且消除模糊。解码块具有恢复图像高频细节信息的特性。图像去模糊需要足够大的感受野恢复运动模糊图像。该网络模型在编码器和解码器的相应层之间添加了跳跃连接,从而增加了接受域。
1.1嵌入通道先验模块(EcBlock)
通道先验一般包含暗通道和亮通道,其中暗通道是指自然图像的RGB三个颜色通道中灰度值趋向于0的值,亮通道是指自然图像的RGB三个颜色通道中灰度值趋向于1的值。Yan[3]等人发现形成模糊的过程通常导致图像暗通道和亮通道稀疏性降低,将暗通道和亮通道稀疏性作为一种先验信息可以有效地解决图像盲区模糊问题。即利用L0范数强制提高模糊图像的极端通道的稀疏性来优化模型,从而获得更高质量的清晰图像。很少研究将通道先验嵌入到网络结构中,来提高去模糊网络的性能。本文基于学习的多尺度构架中引入明、暗通道先验,将明、暗通道先验作为图像特征融入网络中重建更加清晰的图像。即通过映射函数学习亮通道特征信息[Ω]和暗通道特征信息[Λ],并分别与图像的浅层(深层)特征[fl]进行级联操作,实现模糊图像的特征與明暗通道信息有效地融合。
公式中,[[Λ,fl,Ω]]表示特征图像的拼接,N表示映射函数,[[γ|D]]和[[δ|B]]表示参数[γ]和[δ]在暗通道和亮通道先验约束下得到的优化参数。EcBlock中DarkEct提取器(简称D([?]))提取暗通道特征信息,BrightEct提取器(简称B([?]))提取亮通道特征信息,利用L1正则化增强训练中的稀疏性。从而实现明暗通道先验嵌入网络中。D([?])通过计算局部图像块中的最小值来提取[Λ]的暗通道信息。B([?])通过计算局部图像块的最大值来提取[Ω]亮通道信息。
公式中,[ιD[h,w]]和[ιB[h,w]]分别记录各分辨率下最小值和最大值的掩码。每个尺度图像块大小设置为{11×11、19×19、31×31}。各通道中的信息分配给不同的输出[D(Λ)[h,w]]和[B(Ω)[h,w]]。
本文提出的Ecblock模块根据提取到的浅层(深层)特征学习模糊图像的暗通道和亮通道信息,通过目标函数使其逐渐逼近清晰图像的暗通道和亮通道信息,即将暗通道和亮通道特征稀疏化。从而将暗通道和亮通道先验信息嵌入到网络中,重建更加清晰的图像。为不增加过多的网络参数,在Ecblock模块中利用6个图像特征去拟合清晰图像的暗通道和亮通道特征。即保证Ecblock模块输出的特征图数不变。
1.2 双重注意力机制模块
注意力机制是在自然语言处理中开发的,后来它被引入计算机视觉中,CNN中的不同注意力机制利用空间信息[9-10]来改善各种视觉任务的性能。通道注意力[11]已被广泛用于自适应地重新校准特征响应,提高通道间相互依赖性。本文在Resblock后面加入注意机制模块(Attention Mechanism Block,AMB)。AMB由通道注意力模块(Channel Attention Block,CA)和空间注意力模块(Spatial Attenton Block,SA)组成。注意力机制的表示为:
1.3 损失函数
本文采用L2损失函数作为图像损失,公式表示为:
2 实验结果与分析
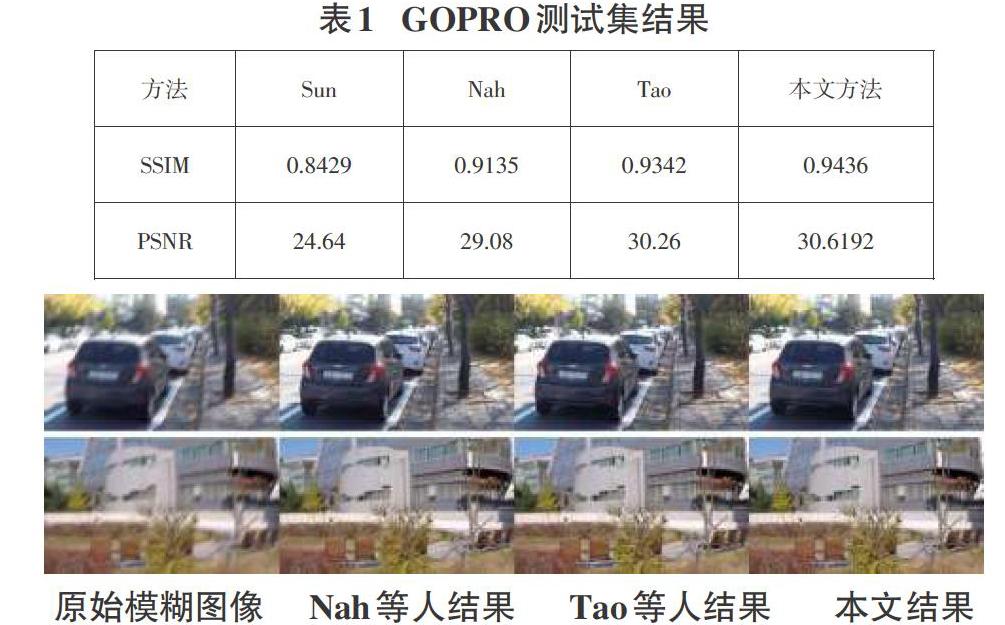
本文采用更接近真实的GOPR0数据集,它能够模拟复杂的相机抖动和目标运动带来的非均匀模糊。GOPRO数据集有3204对模糊-清晰图像,其中2103对数据集用于训练,其余1111对图像用于测试。分辨率为1280X720。实验设备CPU为i5,内存16GB,GPU为NVIDIA1080Ti 的计算机进行实验。训练数据时随机裁剪成256 × 256大小的图像块,测试时保持原来图像大小。初始学习率设置为5E-6,实验中批尺寸设为10,用Adam优化器来优化损失函数,然后使用指数衰减法逐步减小学习率,经过6000轮训练达到最佳的效果。本文采用峰值信噪比(PSNR)和结构相似性(SSIM)作为评价标准。实验结果如表1所示。
表1结果表明,在接近真实的非均匀模糊GOPRO测试集中可以看出Nah等人的实验结果与Sun比较,有了质的提升。Tao等人的评价指标比Nah等人的效果好。本文改进的方法与Tao等人方法相比较PSNR有0.3592的提升,SSIM也得到了提升。
3 结论
本文改进的端到端多尺度网络能够在相同的数据集中获取更多先验特征信息,自适应重点学习模糊图像上下文信息。再不采用叠加更深层次的卷积网络情况下,增强细节信息获取能力。这对于恢复动态场景的运动模糊图像至关重要。
参考文献:
[1] Xu L, Jia J. Two-phase kernel estimation for robust motion deblurring[C]//European conference on computer vision. Springer, Berlin, Heidelberg, 2010: 157-170.
[2] Pan J, Sun D, Pfister H, et al. Blind image deblurring using dark channel prior[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 1628-1636.
[3] Yan Y, Ren W, Guo Y, et al. Image deblurring via extreme channels prior[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 4003-4011.
[4] Chakrabarti A. A neural approach to blind motion deblurring[C]//European conference on computer vision. Springer, Cham, 2016: 221-235.
[5] Schuler C J, Hirsch M, Harmeling S, et al. Learning to Deblur[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(7): 1439-1451.
[6] Sun J, Cao W, Xu Z, et al. Learning a convolutional neural network for non-uniform motion blur removal[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 769-777.
[7] Nah S, Hyun Kim T, Mu Lee K. Deep multi-scale convolutional neural network for dynamic scene deblurring[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3883-3891.
[8] Tao X, Gao H, Shen X, et al. Scale-recurrent network for deep image deblurring[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8174-8182.
[9] Qi Q, Guo J, Jin W. Attention Network for Non-Uniform Deblurring[J]. IEEE Access, 2020.8:100044-100057.
[10] Zagoruyko S, Komodakis N. Paying more attention to attention:Improving the performance of convolutional neural networks via attention transfer[J]. arXiv preprint arXiv:1612. 03928, 2016.
[11] Zhu W, Huang Y, Tang H, et al. Anatomynet: Deep 3d squeeze-and-excitation u-nets for fast and fully automated whole-volume anatomical segmentation[J]. bioRxiv, 2018: 39 2969.
【通聯编辑:唐一东】
