基于中心点的多类别车辆检测算法
2021-04-13梁礼明彭仁杰蓝智敏
梁礼明, 熊 文, 彭仁杰, 蓝智敏
(江西理工大学电气工程与自动化学院, 赣州 341000)
随着中国经济的飞速发展,机动车数量逐年递增,每年发生的交通事故不计其数,如何通过先进的车辆检测技术减少交通事故的发生已成为城市交通管理的一项重要工作[1]。
车辆检测作为目标检测领域的重要研究内容,在智能交通、车辆跟踪、无人驾驶等领域具有广泛的应用需求和重要的研究价值[2]。自深度学习在图像分类任务[3-4]中取得巨大成功后,基于深度学习的方法被广泛用于目标检测任务中,诸如Faster R-CNN[5]、SSD[6]、YOLO[7]等通用目标检测算法均取得了不错的效果。上述方法均采用了目标检测领域流行的锚框机制来遍历特征图生成目标的候选区域,但是锚框的长宽比和尺度需要根据特定的数据集预先设计,常用的方法为采用K-means算法[8]或K-means++算法[9]通过特定数据集的真实边界框进行聚类,从而得到初始锚框的参数,聚类值的选择对最终生成的锚框参数影响较大,从而产生不同的聚类偏差,并最终影响到模型的综合性能。
针对此问题,有关学者尝试采用关键点的方法来对目标定位和分类。Law等[10]提出通过计算目标的一对左上角点和右下角点来回归出目标的位置,但是在海量的角点信息中分辨出属于具体的目标时存在精确度差和耗时过久的问题,从而导致大量不正确的检测框产生。Duan等[11]提出在一对角点中增加一个中心点,形成的关键点三元组(左上角点、中心点、右下角点)可以更准确地定位检测框位置。Zhou等[12]提出用4个极值点来和1个中心点来生成目标的真值热图[10],并以此预测出目标的位置。上述三种方法采用的关键点个数较多,在后续步骤中需要额外对关键点进行分组,检测效率不高。
为了提高检测效率,现借鉴Centernet算法[13]设计思路,采用中心点检测的方法回归车辆的边界框和类别信息。
1 算法原理
1.1 算法流程
本文算法流程如图1所示。具体地,首先将输入图像大小调整为512×512像素,并采用两次步长为2的卷积操作将图像分辨率缩小4倍;然后通过特征提取网络Hourglass反复提取车辆特征,得到车辆不同层次的特征信息;车辆特征信息经预测模块处理后输出3个预测分支,分别预测车辆中心点位置、车辆检测框尺度和车辆中心点位置偏移;最后基于预测信息回归出车辆检测框,完成最终的车辆检测任务。

图1 算法流程Fig.1 Algorithm process
1.2 车辆特征提取网络
采用堆叠沙漏网络Hourglass[14]车辆特征提取网络,网络结构如图2所示。Hourglass网络采用2个堆叠的沙漏网络模块构成,每个沙漏网络模块中除中间过渡层外分别进行了5次降采样和5次上采样操作,并不断提取各层次车辆特征信息,低层的卷积层可提取到各种类别车辆的边缘、线条等局部细节信息,高层的卷积层可从低层获取的局部细节信息中学习到更为复杂的语义信息。由于深层网络可能会存在随着网络的加深出现梯度消失和梯度爆炸的现象,从而导致网络性能退化的问题[15]。通过在Hourglass网络中引入残差网络[16]较好地避免了此类问题的发生。由于在Hourglass网络中反复对输入图像进行降采样和上采样操作,可能会存在车辆有效特征信息丢失的情况,从而导致最终的检测模型出现车辆漏检和误检现象发生,通过融合通道数与尺度相同的各层特征图,保证层与层之间的最大信息流。

图2 Hourglass网络结构Fig.2 Hourglass network structure
1.2.1 可变形卷积
在多类别的车辆检测任务中,常受车辆种类、大小、视觉变化以及非刚体形变等因素的影响,从而导致车辆检测精度低的问题。传统卷积模型受其自身固定的几何结构限制,缺乏几何形变建模能力,不利于网络训练时损失函数的拟合从而导致建模的失败。为克服上述问题,引入可变形卷积[17]辆特征提取网络重建,以此提高网络中各卷积层的车辆特征表达能力。传统卷积和可变形卷积在车辆检测中的示意图如图3所示,其中采样点为3×3,可以看出可变形卷积在采样时更能适应多类别车辆的形状与尺寸。假设一个3×3卷积k定义为

图3 传统卷积与可变形卷积Fig.3 Traditional convolution and deformable convolution
k={(-1,1),(0,1),(1,1),(-1,0),(0,0),(1,0),(-1,-1),(0,-1),(1,-1)}
(1)
对输入特征图f(*)采用传统卷积操作后,在局部位置αλ处的特征映射T可定义为
(2)
式(2)中:w()为采样点权重值;αn为k的局部位置,n=1,2,…,|k|。在可变形卷积中加入偏移量Δαn的学习之后,可根据不同种类、形状、尺寸的车辆目标动态调整可变形卷积核的大小和位置,从而高效完成多类别车辆检测任务。可变形卷积定义为
(3)
1.3 预测模块与损失函数的设计
在CenterNet算法中预测模块分为三个预测分支,即中心点位置(x,y)预测、车辆检测框尺度(w,h)预测、中心点位置偏移(offset)预测。三个预测分支的总输出可作为车辆检测框回归的重要依据。
针对中心点位置采用带有惩罚项的逻辑回归损失[18],即
(4)

针对车辆检测框和中心点位置偏移分别采用L1距离损失函数
(5)
(6)
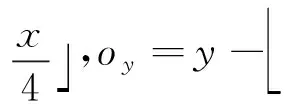
车辆检测框和中心点位置偏移均采用L1距离损失函数,但是评价模型性能的重要参考指标是真实框A与预测框B的IoU(intersection over union)。在模型训练时,L1距离损失函数值通过不断迭代达到最优时,并不能代表预测框与真实框的重合程度达到最大。若将IoU引入损失函数中,当真实框与检测框无交集时,无论两者距离如何变化,IoU始终为零,最终导致模型性能无法进行优化。针对此问题,引入GIoU[19](generalized intersection over union)实框与检测框重合程度的新标准,GIoU可定义为
(7)
(8)
式中:T表示包含真实框与检测框的最小封闭框;T(A∪B) 表示最小封闭框区域T不包含A与B的部分。A、B和T的关系如图4所示。GIoU可作为一种距离度量指标,当A与B无交集时,GIoU可表示为
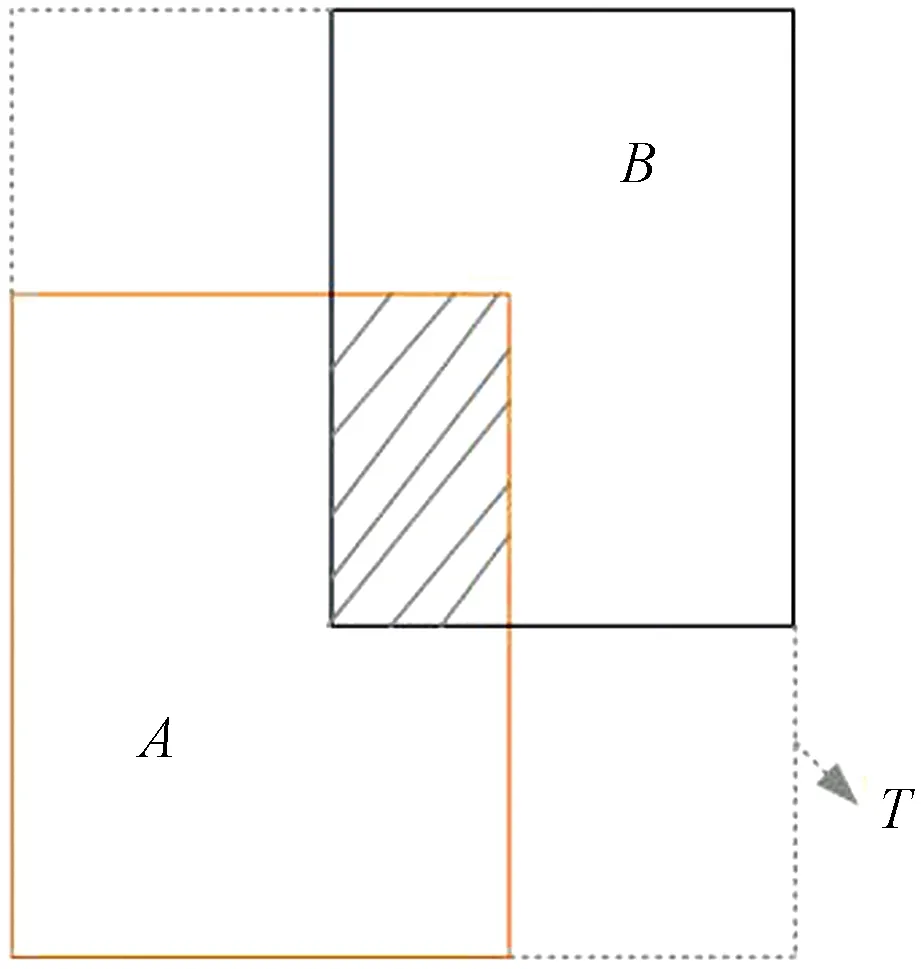
图4 A、B和T的关系Fig.4 Eelationship of A, B and T
(9)
当A∪B为定值时,T不断减小,A与B将不断向有交集的情况进行优化。
为解决评价指标IoU与目标函数不统一的问题,本文在原有损失函数的基础上增加一项衡量预测框(Pre)与真实框(Tru)的距离损失,即
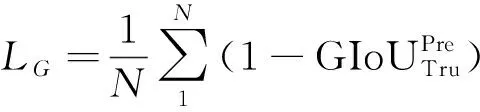
(10)
新的组合损失函数为
L=Lc+γ1Loffset+γ2Lwh+LG
(11)
式(11)中:γ1、γ2为损失权重系数,设为0.1和1。
2 实验分析
2.1 数据集和实验平台
本次实验选用国际公开的KITTI库[20]和自制数据库对模型进行训练和评估,根据实验要求,将两数据库标注格式均转化为VOC2007数据集格式,保留实验需要的4个类别标签(Car、Van、Truck和Tram),并从中筛选出高质量的车辆图像,最终得到公开数据库中的7 000张图像,自制数据库中的3 000张图像,训练集和测试集按3∶1比例划分。为了有效降低模型过拟合的风险,此次实验还采用随机缩放、水平翻转以及对比度变换等数据增强方法来提高模型的泛化能力。
本次实验的仿真平台是PyCharm,使用PyTorch深度学习框架,计算机配置为Intel©CoreTMi7-6700H CPU,16 G内存,Nvidia GeForce GTX 2070 GPU,操作系统为Ubuntu16.04.2。网络参数配置如下:最大迭代次数为500次;批量大小设置为8;采用学习率衰减的方式训练,初始学习率为0.000 25,网络每迭代100次,学习率下调10倍。
2.2 公开数据库测试结果
实验采用均值平均精度(mean average precision,mAP)与传输速率来评估本文模型的综合性能,并与目标检测通用算法Faster R-CNN[5]、SSD[6]、 CornerNet[10]、CenterNet[13]以及YOLOv3[21]对比实验,所有算法均在公开数据库上训练和测试。表1显示本文算法与其他算法的实验对比结果。
如表1所示,本文算法在公开数据库上取得了93.42%的mAP,精度优于其他算法,并以49 f/s的检测速度达到了实时检测的要求。表1中前三种算法皆采用锚框机制来遍历特征图生成车辆的候选区域,并以此回归出车辆检测框信息,其中YOLOv3在精度和检测速度上都要优于其他两种算法。后三种算法均采用关键点检测方法回归车辆类别和位置信息,摆脱了锚框的依赖性,3种关键点检测方法在精度方面好于锚框机制方法。CornerNet算法由于采用目标左上角点和右下角点定位目标检测框,在目标车辆预测中存在对角点分组的步骤,此步骤增加了网络计算的复杂度,极大地降低了算法的检测速度。

表1 不同算法在公开数据库上对比结果Table 1 The comparison results of different algorithms on public database
2.2.1 不同改进模块对模型性能的影响
为了验证本文算法引进的可变形卷积模块和GIoU损失模块对模型性能产生的影响,采用控制变量法,在原CenterNet算法基础上依次加入以上所提改进模块,实验结果如表2所示。
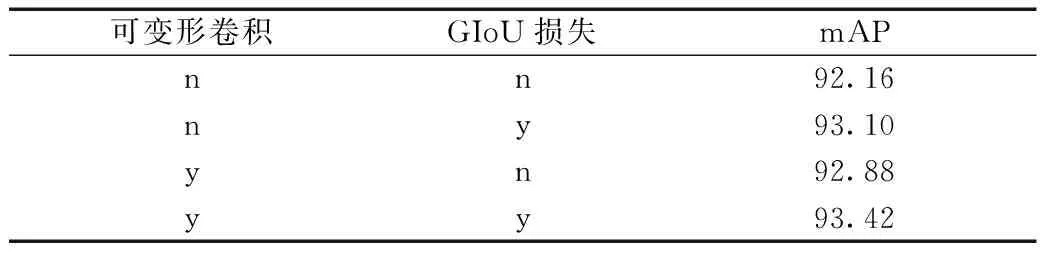
表2 不同模块对本文模型性能的影响Table 2 The impact of different modules on the performance of the model
当只引入可变形卷积后,模型测试精度相对CenterNet算法只有0.72个百分点的提高;损失函数加入GIoU损失项时,精度提高了0.94个百分点;当同时引入可变形卷积和GIoU损失项时,模型精度得到最大提升。
2.3 自制数据库测试结果
为了验证本文算法在其他车辆数据集上的检测性能,在自制数据库上对本文算法和CenterNet算法进行训练和测试,其中测试集有图像1 000张,图像中总共含有车辆数目为3 253辆。通过比较两种算法在车辆检测时出现漏检和误检的情况,得到测试结果如表3所示。

表3 原算法和本文算法对比结果Table 3 The comparison results of the original algorithm and our algorithm
本文算法相比原算法在自制数据库上也具有一定的优势性,不仅减少了车辆漏检情况的发生,同时也降低了车辆误检数。本文算法相比原算法精确率和召回率分别提高了2.7%和5.6%,这充分说明本文算法可适应不同场景下的车辆检测任务。
2.4 本文算法在公开数据库和自制数据库的检测效果
将两种数据库中的图像输入到本文模型中测试,得出部分图像检测效果如图5所示,其中检测框左上角为目标车辆类别和score,IoU阈值设置为0.7,score阈值设置为0.3,每张图像的下方显示了从图像最左端到最右端依次检测出的目标类别及score。图5中前3张图像来源于公开数据库,后3张图像来源于自制数据库,公开数据库中目标车辆个数较多,背景中非检测目标对待检测目标车辆的分类和定位产生一定的干扰。从图5中可以看出本文方法在多类别车辆检测中,检测框与目标车辆重合程度大,误检、漏检和重复检测现象较少。

图5 两种数据库中的部分图像检测效果Fig.5 Partial image detection effect in two databases
3 结论
借鉴通用目标检测算法CenterNet思路,将其应用到多类别车辆检测任务中。针对车辆类别多及形状大小各异等检测难点,引进可变形卷积对CenterNet网络重建,提高网络对各种车辆特征提取能力。考虑到CenterNet损失函数的局部最优时不等价于模型评价指标IoU的局部最优,通过引进GIoU损失使原损失函数更为合理。在公开数据库和自制数据库上的仿真实验结果表明,本文算法的综合性能要优于其他算法。在后续工作中,将对算法流程进行简化,使车辆检测速度与精度得到更大的提升。
