基于Java的项目评语分析系统设计与实现
2021-04-13包永强李光荣王一新
夏 飞,包永强,李光荣,王一新
(1. 南京工程学院机械工程学院, 江苏 南京 211167;2. 南京工程学院信息与通信工程学院, 江苏 南京 211167)
近年来,伴随着高校师生数量的逐年增加,申请国家基金项目的人数也在逐年增加.以国家社会科学基金重大项目为例,通过对2004—2015年国家社会科学基金重大项目立项项目的计量分析发现立项项目呈现出稳步增长的趋势[1].
2019年科学基金项目申请量继续大幅增加,全年共接收各类项目申请250 630项,比2018年增加11.22%,其中,在3月1日至3月20日的项目申请集中接收期间,共接收2 364个依托单位提交的16类项目申请计240 711项,同比增加25 844项,增幅为12.03%[2].
高校师生申报国家基金项目后,多位评审专家会分别给出相应的反馈意见.本文设计并实现了一个评语分析系统,通过对评语进行处理分析,挖掘出隐藏信息.帮助申报者根据专家反馈意见精确地分析其能否申请成功.
1 系统的设计及处理流程
系统前端使用React框架,React框架是当今主流的开源JavaScript框架,由于React的设计思想独特、代码逻辑简单且性能出众,成为当今Web开发的主流工具之一[3];后端使用SSM(Spring+SpringMVC+MyBatis)框架,Spring是一个分层的JavaSE/EE应用轻量级开发框架,SpringMVC是一种基于MVC的设计模式,MyBatis是apace的一个基于Java的开源持久层框架[4].
系统的处理流程为:
1) 通过预处理将所有申报项目的专家反馈意见(简称评语)源文件分为两大类,如图1所示,结论明确指所有专家情感态度为一致同意或否定,结论模糊指所有专家情感态度中有肯定、否定、不定;

图1 预处理流程
2) 将结论模糊的评语根据情感态度的模糊程度划分为三类,利用NLP工具包下的汉语言处理包来训练文本分类及情感分析处理模型,通过模型对无明确态度的评语进行分类和情感分析,处理流程如图2所示;
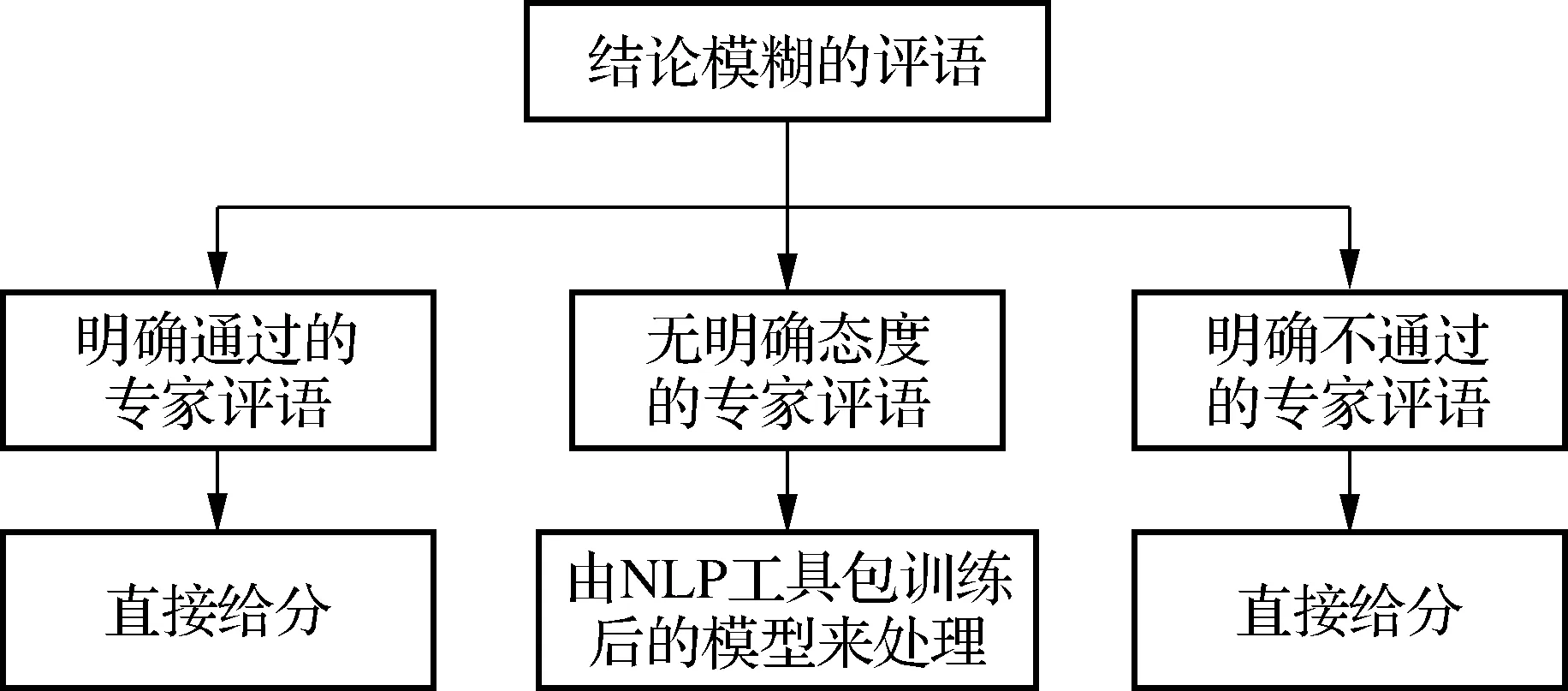
图2 模糊评语处理流程
3) 将每个专家的评语进行语句划分,然后由训练后的模型来进行打分,计算每条专家评语每个语句的得分,将所有语句得分按照一定权重计算得出该专家评语的得分,再将所有专家评语的总分除以专家人数得出项目得分,按照得分范围给出对应结论.
2 评语的分类及处理
每个申请的国家基金项目一般由3—5个专家给出评审意见,并给出是否资助的建议.每个专家的评审意见一般由多个句子组成,句子分为态度明确和态度模糊的两类.
2.1 评语的分类
专家评语按照情感态度是否明确可分为明确赞成立项、明确否定立项、无明确态度三类.对于前两种语义明确的评语,学校相关工作人员或申报人员可以直接得知该项目能否申报成功.对于语义模糊的评语,则无法明确得知该项目能否申报成功.
2.2 评语的预处理
评语的预处理是为了将一些内容残缺的评语、有明确结论的评语、无明确结论的评语区分开来,便于系统进一步处理.
后台根据评语的关键词、句子长度等易识别的特征,将项目评语分为结论明确的项目评语(包括已批准/未批准/格式不规范)和结论模糊的项目评语两大类.以某高校师生国家基金申请的反馈意见为例,预处理结果如图3所示.

图3 评语预处理结果
2.3 模糊评语的处理
数据经预处理后,仅剩下无明确结论的项目评语需要处理.这些结论模糊的项目评语包含3—5条专家评语.处理思路是:先将项目评语切分为一条条专家评语;然后对每条专家评语分别进行打分;最后将该项目中所有专家评语的得分取平均值作为该项目的最终得分.
处理的重点是情感分析,即依据预先训练好的语料库对输入的评语进行文本分类.文本分类的流程主要分为特征提取和分类器处理.在机器学习时,要在部分样本中提取出利于分类的特征便于后续分类器的运行;这些特征在经过数值化之后变成定长的向量,在进行语句库训练时,分类器通过数据集中的向量学习运算出决策边界;在分析预测时,分类器通过分类特征对语句进行分类,即通过输入的向量落在决策边界的位置来判定语句的类别.
2.3.1 模糊评语的划分
系统根据评语前的序号(<1>,<2>,<3>,…)划分评语,即将反馈意见按照专家人数划分.本功能模块中需要将每个专家评语中的语句分类,分为经费情况、立项依据与研究内容、研究方案、特色与创新、研究计划与预期成果、研究基础与工作条件六类.这六类语句按照一定比例分别赋予权值,每个专家评语的得分为各类得分与权值的积的总和.
2.3.2 模糊评语语句库模型的训练
近年来,深度学习算法被普遍应用于情感分析[5].本系统语句分类的处理方法是基于自然语言处理的方法,先根据素材库训练模型,再运用模型解决实际问题.素材库中素材的来源是已分类的评语语句.素材库的建立十分重要,素材库的质量决定了模型的质量,素材库越丰富,模型的通用性越好,识别的准确度越高.
建立素材库具体做法为:将专家评语按照经费情况、立项依据与研究内容、研究方案、特色与创新、研究计划与预期成果、研究基础与工作条件分类,按照类别将每个专家的评语填到对应的单元格内.
素材库建立的原则为:宁缺毋滥,内容少不是问题,但一定保证精准分类;当一个句子中包含多个分组的成分时,需要将其分割开;对句子进行分割时,尽量保证原句不变动,仅必要时对句子进行增删,以保证语句通顺.
系统根据30条专家评语数据初步训练出一个有效模型,分类的准确率较高,对绝大部分语句都能正确分类.部分执行结果如表1所示.

表1 部分语句分类结果
2.3.3 模糊评语的打分
在文本的情感分析和数据处理中,基于词典方法的核心是词典+规则,即以情感词典作为判断情感极性的主要依据,同时兼顾语法结构,设计相应的判断规则[6].通过对大量评语观察发现,在模糊评语中某些专家的评语也给出了明确的结论:不资助、可资助、优先资助.对于这些类型的专家评语,应该进行特殊处理,可以通过关键字识别出来.假设的得分规则:优先资助为100分;可资助为95分;不资助为50分.文本情感分类项目整体流程大致分为数据处理、特征选取、模型的构建、训练与测试[7].
无明确结论的专家评语是最难处理的评语类型.处理思路和打分流程(规则)为:
1) 将专家评语按照“.”、“;”、“?”、“!”的标点符号分解成独立的句子;
2) 经过训练的文本分类持久化模型将这些语句分类,按照语句内容分为研究内容、立项依据与研究意义与研究目的、特色与创新、研究方案、研究基础与工作条件、研究计划与预期成果、经费情况、其他8类;
3) 经过训练的文本情感分析模型对每个句子进行打分(用分类算法打分,和流程2)相同,只是模型不同),按照优秀(90分)、良好(80分)、中等(70分)、及格(60分)、不及格(50分)五档打分;
4) 系统收集描述同一内容的句子,对它们的分数取平均值,作为评语中该部分内容的打分(内容类别为立项依据与研究意义与研究意义、特色与创新、研究方案、研究基础与工作条件、研究计划与预期成果、经费情况的语句参与打分,研究内容和其他不属于以上分类的语句不具有打分意义,不参与打分);
5) 给每项内容分配得分权值,加权后的每项得分之和作为该条专家评语的最终得分;
6) 根据各专家评语得分求均值,作为项目的最终得分,再根据分值自动划分到相应区间并给出对应结论,区间及对应结论如表2所示.

表2 最终得分区间及对应结论
3 系统测试
3.1 系统界面介绍
系统使用IntelliJ IDEA 2018软件进行程序的编写和调试,使用时在浏览器端打开系统主界面.学校界面用于后续接入各高校数据库;项目界面用于选择需要进行评语分析的项目类型.
概况界面如图4所示,用于介绍系统功能及使用要求;评语界面如图5所示,用于导入反馈意见的Excel文件,运行后给出分析结果.
图4 概况界面

图5 评语界面
3.2 系统功能测试
为了较好地测试系统评分的准确性,导入两类不同的数据进行测试:1) 带有一个或多个明显否定(肯定)态度的反馈意见,测试结果如图6所示;2) 否定和肯定态度占比不定或意思模糊的反馈意见,测试结果如图7所示.
4 结语
本系统通过文本分类及情感分析来对申请国家基金项目的反馈意见进行深度分析.不同于个人的主观预测,经过训练后的文本分类及情感分析模型对评语的类型进行划分并依据情感打分,极大地增加了预测结果的准确性,可以帮助申请国家基金项目的高校师生提前知晓其项目能否申请成功.
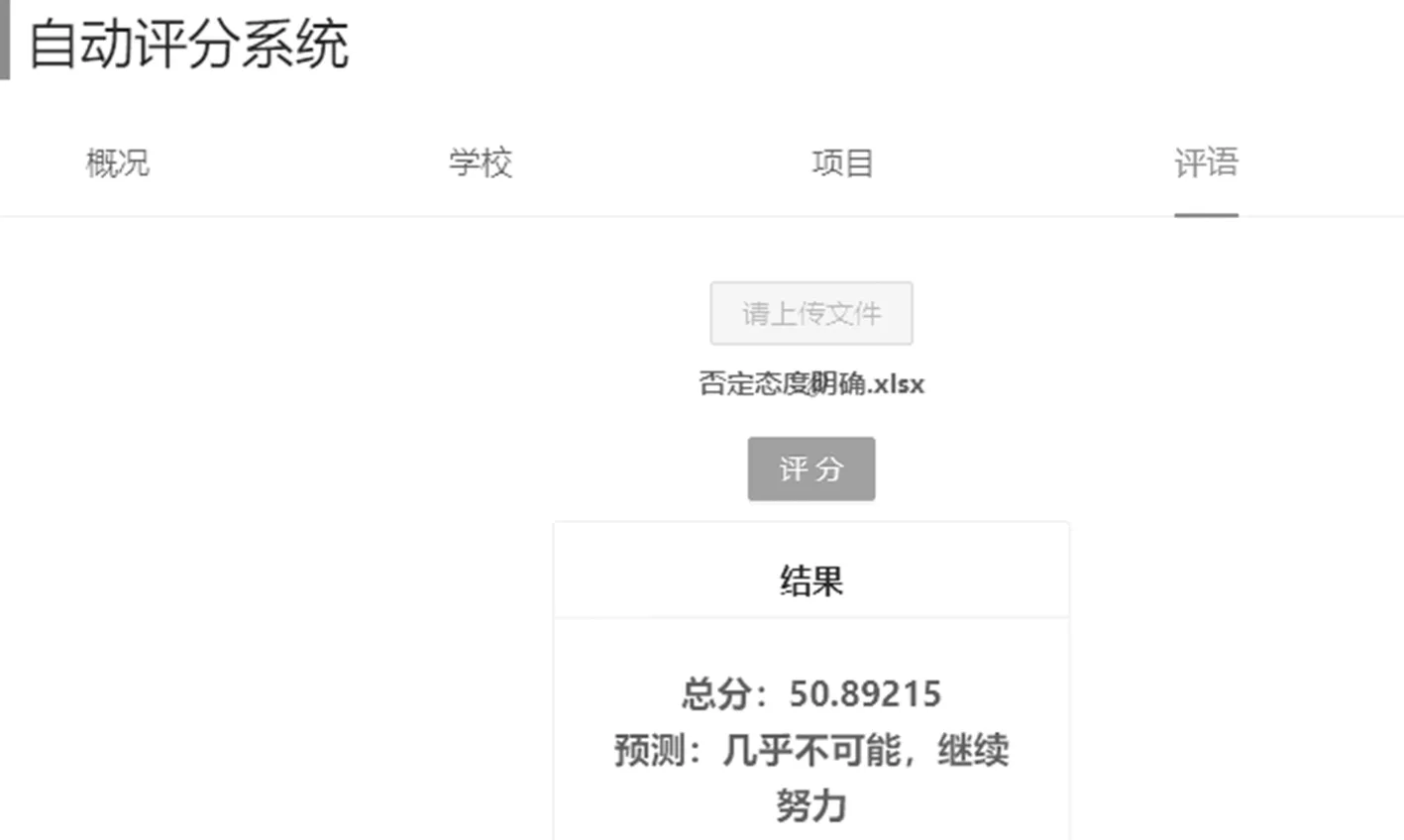
(b) 否定
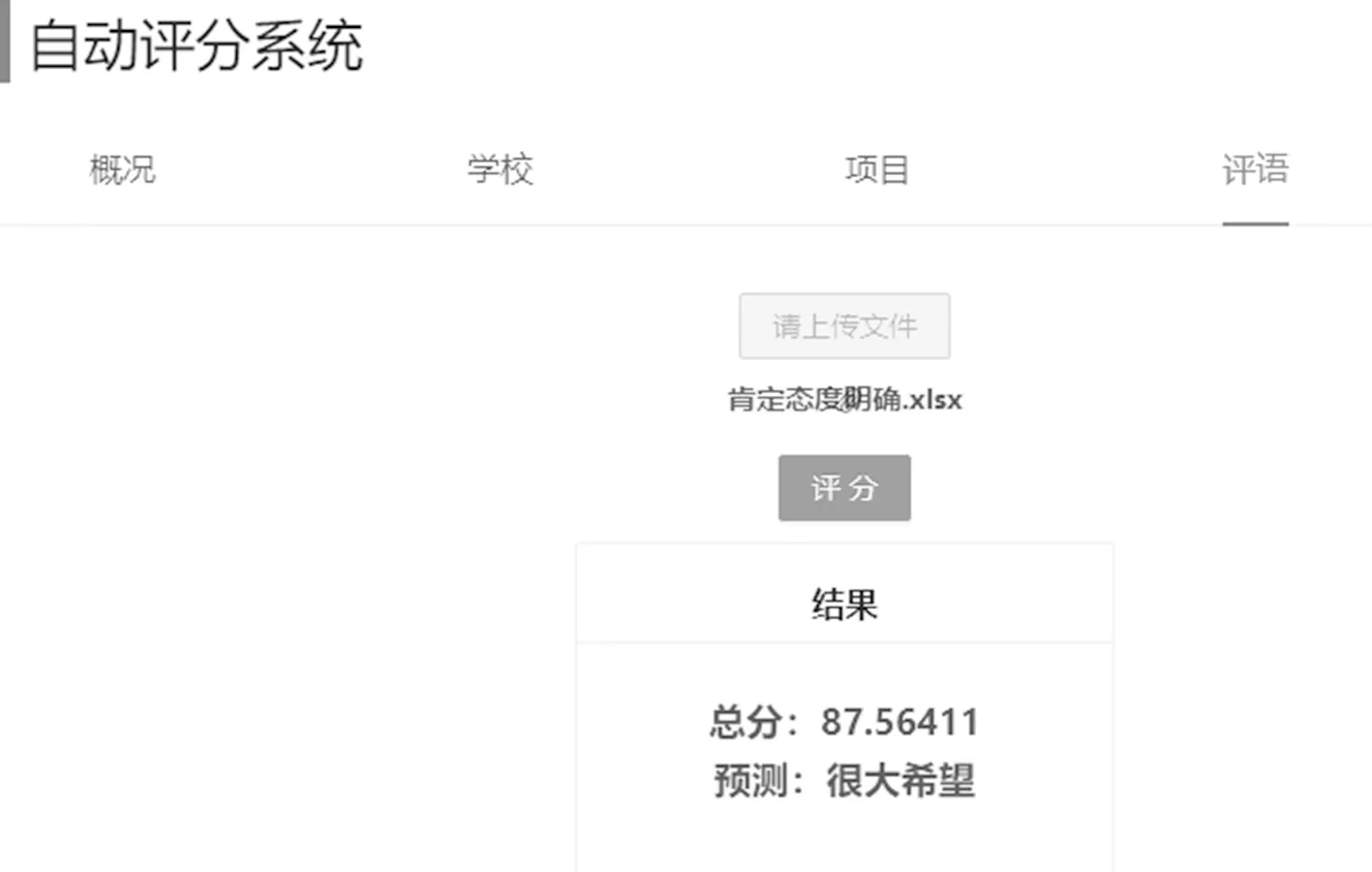
(b) 肯定

图7 类型2测试结果
在后续的开发中,系统可以从以下几个方面改进:1) 扩充语句素材库的样本,样本数量的增加可以极大地提高预测的准确性;2) 接入数据库,提高系统的应用性;3) 增加功能,如实现批量导入及分析的功能.
