一种时空特征聚合的水下珊瑚礁鱼检测方法
2021-04-13陈智能史存存李轩涯贾彩燕黄磊
陈智能,史存存,李轩涯,贾彩燕,黄磊
(1.中国科学院自动化研究所 数字内容技术与服务研究中心,北京100190;2.北京交通大学 计算机与信息技术学院,北京100044;3.百度公司,北京100085; 4.中国海洋大学 信息科学与工程学院,青岛266100)
珊瑚礁鱼泛指生活在热带海洋珊瑚丛中的各种鱼,它们种类繁多、形态各异、色彩斑斓,是最富活力和观赏性的海洋生物群体之一。研究表明,珊瑚礁鱼的种类、数量和活动痕迹是否丰富,直接反映了珊瑚礁生态系统的健康状态和海洋生物多样性丰富程度[1]。珊瑚礁鱼活动的显著变化,则往往与温度剧变、水域污染和过度人类活动等事件紧密联系[2]。通过监测分析珊瑚礁鱼的活动,可以快速、准确、精细地掌握海洋生态系统的健康状况。此外,珊瑚礁鱼的分析研究还将有助于帮助海洋生物学家研究不同海洋动物的行为及其之间的相互作用[3]。目前,随着全球大多数珊瑚礁生态系统呈退化趋势,这一研究已经得到了广泛重视。
在海洋科学领域,最初人们主要采取人工撒网法[4]和潜水调查法[5]开展珊瑚礁鱼活动调查。人工撒网法先由人在珊瑚礁水域撒网捞鱼,再经过海洋生物学家整理得到分析结果。潜水调查法由专业潜水员手持水下摄像机穿越珊瑚礁水域,通过对所拍摄影像进行事后分析,得到调查范围内的珊瑚和珊瑚礁鱼情况。虽然已被沿用很多年,它们的缺点也很明显:执行一次调查不仅消耗大量人力物力,而且会对鱼类活动产生一定影响,此外还难以获得大面积连续的监测数据。随着水下成像技术的发展,在珊瑚礁水域特定位置安装水下摄像机,采集珊瑚礁鱼活动影像并进行分析正在成为一种普遍接受的做法。相比于传统调查方法,水下摄像既不影响珊瑚礁鱼行为,同时也为后续分析提供了大量素材。目前,全球多个国家和地区的珊瑚礁水域都部署了水下摄像系统并产生了大量珊瑚礁鱼监控影像。对这些影像的分析催生了跨学科交叉研究需求:海洋生物学家手动分析每天产生的大量影像数据是不切实际的,迫切需要智能化的珊瑚礁鱼分析技术,能够从真实水下环境采集的影像中,自动得到珊瑚礁鱼的出现位置、种类、数量等信息。
在信息科学领域,视频大数据智能分析是一个广受关注的研究课题。特别是近年来,基于深度学习的视频分析与理解取得了显著突破,在大规模视频分类与检测[6-10]、细粒度图像分类[11-12]等任务上,深度学习相比于传统方法性能取得了大幅提升。但是,目前多以消费类视频图像及安防、交通等领域的监控视频为研究对象,对水下影像的分析相对较少。水下影像具有成像质量不高、水下环境复杂等分析难点,此外具体到珊瑚礁鱼检测上,还存在视觉多样性高、标注数据有限等挑战,这些困难决定了直接应用其他领域成熟的分析方法并不是最优方案,需要专门研究珊瑚礁鱼的有效检测方法。
目前,已经有一些针对珊瑚礁鱼检测分析的研究工作。早期研究多在受限情况下开展。例如,文献[13]提出了一种基于轮廓匹配的鱼识别方法,文献[14]提出了一种基于特征变换和支持向量机的罗非鱼自动分类方法,他们的实验都是在已捕捞、拍照时摆放较规则的鱼的图像上开展。针对水下自然环境中生活的鱼,文献[15-16]从不同角度提出了联合形状和纹理特征的鱼分类方法,结果表明,水下环境鱼检测分类的难度明显大于之前的受限环境。面对水下珊瑚礁鱼成像分辨率低的问题,Wei等[17]提出了一种利用互联网高分辨率鱼图像进行数据增强的珊瑚礁鱼分类方法。围绕真实水下监控视频珊瑚礁鱼检测的Sea-CLEF系列国际竞赛[18],来自韩国首尔大学[19]、德国耶拿大学[20]的团队采用了运动前景提取与基于深度学习分类相结合的解决方案,取得了较好成绩。近期相关工作更倾向于利用深度学习目标检测模型来解决珊瑚礁鱼检测问题。例如,文献[21]提出了一个相邻层特征融合的全卷积网络进行珊瑚礁鱼检测。为更好应对水下复杂环境,Zhuang等[22]提出了先用SSD模型[23]检测珊瑚礁鱼,再用ResNet网络[24]对检测前景进行分类的方法。印度韦洛尔技术大学的研究团队[25]评估了不同主干网Faster R-CNN模型[26]在该竞赛上的检测性能。德国杜塞尔多夫大学的学者[27]提出了一种基于YOLO模型[28]的改进方法,取得了较好的检测效果。
上述研究虽然显著推动了珊瑚礁鱼自动检测技术的发展,但仍存在一些不足:将珊瑚礁鱼检测视为一个前景提取及分类的任务,或将其视为一个图像目标检测加上时序后处理的任务。前者虽然前景提取时能一定程度利用视频时序信息抑制水下复杂环境造成的负面影响,但其将检测过程切分成了前景提取和分类2个独立的子任务,二者无法相互促进和增强,检测性能受到限制。对于后者,由于检测时忽视了时序维度,且受目标大小有限、环境复杂等的影响,深度模型难以提取高质量检测特征,易造成误检和漏检,虽然时序后处理可消除一部分错误,但这也很难称之为视频时序信息的深入利用。
认识到特征辨识力不足是制约当前检测精度提升的关键因素,本文提出了一种时空特征聚合的水下珊瑚礁鱼检测方法。具体地,设计了一个新颖的卷积网络结构以提取更具辨识力的时空联合特征。该网络从SSD模型发展而来。同时,其包含一个多层视觉特征聚合模块,以提取更丰富的视觉特征,以及一个时序特征聚合模块,可结合运动目标生成时序强化的特征表示。通过以上2个模块实现对空间和时间2个维度特征的聚合,得到了可有效表征水下视觉目标的时空联合特征。公开数据集上的实验表明,本文方法可提升真实水下环境珊瑚礁鱼检测的精度。
本文的主要贡献如下:
1)提出了一个多层视觉特征聚合的深度网络模块,设计了自顶向下的切分和自底向上的归并,可实现不同分辨率多层卷积特征图的聚合。
2)提出了一个时序特征聚合的深度网络模块,可结合运动目标融合相邻帧的卷积特征图,从时序维度强化所提取特征。
3)通过集成以上2个模块,提出了一个时空特征聚合的深度目标检测网络,可实现对视频目标特征的有效提取及检测。
4)公开数据集的实验表明,本文方法可以有效检测真实水下环境中的珊瑚礁鱼,相比于传统方法和模型取得了更好的检测精度。
1 相关技术
本节对珊瑚礁鱼检测方法中涉及或相关的技术进行简要介绍,具体包括前景提取及分类、图像目标检测和视频目标检测3个方面。
1.1 前景提取及分类
前景提取及分类方法将珊瑚礁鱼检测视为一个前景目标提取及分类问题。由于当前水下摄像采集的都是固定场景视频,借鉴安防、交通监控等领域的分析经验,利用多帧图像平均、高斯混合模型[29]等方法可以对这类视频进行背景建模,进而可以通过背景差减和适当后处理,提取当前帧中的运动区域。将这些区域视为前景目标从图像中截取出来并归一化到特定大小,即可作为深度神经网络或其他机器学习模型的输入,构建相应分类模型实 现 珊 瑚 礁 鱼 检 测。AlexNet[30]、GoogleNet[31]、ResNet[24]都是现有文献中用到的分类网络。
前景提取的效果是这类方法能否取得好的结果的关键。由于珊瑚礁鱼在图像中通常只是一小部分,且受到影像分辨率低,以及水流、背景目标运动(如珊瑚摆动)等的影响,所提取的前景通常会有较多噪声。分类网络虽然可以滤除其中一部分,但因前景目标提取不完整、提取冗余等因素,不可避免会对分类精度造成一定影响。
1.2 图像目标检测
图像目标检测方法将珊瑚礁鱼检测视为一个基于单帧图像的目标检测问题。图像目标检测是随着深度学习技术发展性能得到显著提升的领域之一。根据检测原理的不同,现有检测方法主要分为两阶段方法和一阶段方法两大类。
两阶段方法一般包含2个网络:候选区域生成网络和检测网络。首先,使用候选区域生成网络在图像特征图上生成目标候选框;然后,使用检测网络对生成的目标候选框进行中心位置和长宽的回归,并进行分类。典型的两阶段方法包括Faster R-CNN[26]、Cascade R-CNN[32]等。
一阶段方法通过对目标位置、大小和长宽比进行密集的采样来检测目标。这类方法先在特征图的每个位置根据不同的大小和长宽比预定义固定数量的默认框,再对默认框的中心位置和长宽进行回归,并对其包含的物体进行分类判别。典型的一阶段方法有YOLO[28]、SSD[23]等。
除以上方法,近年来也有一些考虑目标定位损失[33]和无需预定义默认框[34]的方法被提出来并取得良好检测性能。此外,强化网络所提取特征的辨识力也是提升目标检测性能的重要方向。这方面代表性工作有特征金字塔网络FPN[35]、默认框可适配学习的RefineDet[36]等。
具体到珊瑚礁鱼检测方面,目前有文献用到Faster R-CNN[26]、SSD[23]和YOLO[28]。因视频帧分辨率低、水下环境复杂、鱼体态呈多维变化等特点,所提取特征质量不可避免受到影响,制约了以上方法的精度。为此,文献[22,27]提出利用额外分类器来强化检测结果,这一做法的效果主要体现在减少误判上,对漏判则作用不大。
1.3 视频目标检测
视频目标检测泛指同时利用图像静态特征和视频运动信息实现检测的各种方法。目前,主要有2类视频目标检测方法:第1类是图像目标检测及后处理。先在多帧图像上进行目标检测,再采取适当后处理,得到视频级检测结果。这类方法是图像目标检测方法的简单延伸,其存在难以充分利用检测结果的时序相关性等不足。第2类方法利用可同时接受视觉和时序信息作为输入的深度模型进行检测。目前,已经有一些相关的网络结构被提出来。例如,利用2个卷积神经网络分别处理视觉和运动信息的双流神经网络[6],利用卷积神经网络提取单帧图像视觉特征,进而用长短时记忆神经网络建模相邻帧之间相关性的CNN-LSTM结构[7],利用3D卷积提取时空联合特征的三维卷积神经网络[9]。这些方法统筹考虑了时空域,因而可以提取到更为强大的特征,从而提升行为识别、视频分类等多个视频任务的分析精度。
由于珊瑚礁鱼通常只占视频帧的一小块区域,且其位置随着时间变化,构建有效的局部视觉和时序特征表示是视频目标检测的关键。这方面典型工作有光流引导特征聚合网络[10],依据光流方向聚合相邻帧特征图以强化对当前帧目标的表示,可适当缓解目标因运动模糊、面积过小、罕见姿态等问题导致的检测困难。此外,也有学者研究了同时进行目标检测和跟踪的网络[37],通过二者的互补提升检测性能。
2 本文方法
2.1 整体网络结构
本节介绍提出的时空特征聚合水下珊瑚礁鱼检测方法。图1给出了时空特征聚合神经网络的整体结构。可以看到,该网络接受当前视频帧及前后相邻帧作为输入。当前帧通过图中c1~cf组成的视觉特征聚合模块(Visual Feature Aggregation,VFA),生成一个融合了多层卷积特征图、信息更丰富的新视觉特征图。同时,对于其中参与目标预测的特征图(cf,c15~c19),通过图中实线框表示的时序特征聚合模块(Temporal Feature Aggregation,TFA)对当前帧及相邻帧特征图予以聚合,从而生成具备更强表示能力的时空聚合特征(Visual-Temporal Feature Aggregation,VTFA)。珊瑚礁鱼检测将在空间分辨率逐步降低的多个聚合特征图上进行。

图1 本文时空特征聚合神经网络的整体结构Fig.1 Overall architecture of the proposed spatio-temporal features aggregation neural network
本文网络可视为一种从SSD模型[23]发展而来的复合结构,在其单帧图像处理通道中(见图1中虚线框),类似于 SSD 利用卷积神经网络VGG16[38]作为特征提取主干网,其中基本卷积层c1~c13与VGG16一致,最后2个全连接层和分类层被截断,予以替换的是6个空间分辨率逐步降低的新增卷积层(c14~c19)。在SSD中,目标检测将在c10、c15~c19这6个不同尺度的卷积特征图上进行。
损失函数方面,本文网络与SSD的形式相同,整个网络的损失函数定义为

式中:x为记录预测框和标注框匹配情况的矩阵;c为当前样本的预测置信度向量;l和g分别为预测框和标注框的坐标信息;N为当前帧预测框数量;Lconf和Lloc分别为类别损失和定位损失;a为一个用于平衡2类损失的参数,本文设置为1。以上损失项的计算公式可参见文献[23]。
不同于SSD,本文网络的目标预测是在经过单帧图像多层特征图聚合与/或相邻帧同层特征图聚合后生成的时空强化特征图上进行,这2个聚合模块正是本文的创新之处。
2.2 视觉特征聚合模块
源自VGG16的基本卷积层中,SSD仅用c10进行预测,忽视了其他层信息。水下监控视频由于质量低、成像环境复杂且珊瑚礁鱼目标通常较小,基本卷积层特征图上的信息对于检测来说尤其重要。基于此,本文设计了一个视觉特征聚合模块对基本卷积层进行更有效的利用,以提高水下复杂环境中的珊瑚礁鱼检测性能。
视觉特征聚合模块由一个自顶向下的切分和一个自底向上的归并操作组成。切分过程迭代地将卷积层分成不同的组,形成了一个自顶向下的切分结构。在这个结构的最顶层,所有卷积层都在同一组。当卷积层数量n是偶数时,在下一层它们将从中间切分,分成2个各含有n/2个层的组;当卷积层的数量n是奇数时,在下一层最中间的卷积层将被视为一个单独的组,其左右两边的卷积层被分为另外2个组,各含有(n-1)/2个层。基于这一原则,卷积层可以不断被切分,直至每个组中卷积层的数量小于等于2,此时切分过程停止。图2(a)的上半部分给出了一个切分的例子。
基于以上切分结果,自底向上的归并从下往上不断合并每个组中的特征图,最终形成了一个聚合了所有卷积特征图的特征。具体地,卷积层归并时涉及对2个或3个分辨率和通道数可能不同的特征图融合。由于卷积神经网络特征图从浅层到深层满足分辨率不变或递减的规律,对于2个特征图融合的情况:若分辨率不同,将低分辨率特征图上采样到与高分辨率特征图具有相同大小,再进行融合;若分辨率相同则直接融合。对于3个特征图融合的情况,先保持中间层特征图的分辨率不变,若其浅层方向特征图分辨率大于中间层,则通过下采样将其降采样到与中间层特征图相同分辨率再融合;若其深层方向特征图分辨率小于中间层,则将其上采样到与中间层特征图一样大小再进行融合;若浅层和/或深层方向特征图分辨率与中间层的一致,则直接融合。通过迭代进行融合操作,最终所有特征图将会被融合成一个具有适中分辨率的聚合特征图,如图2(a)下半部分所示,该特征图将会替换c10进行预测。

图2 本文提出的视觉特征聚合模块和时序特征聚合模块Fig.2 The proposed visual feature aggregation module and temporal feature aggregation module
对于融合过程中的特征图通道数可能不一致的情况,以(三层融合的)中间层或(两层融合中)浅层方向的特征图为基准,融合前先通过1×1的卷积将其他层特征图的通道数予以对齐。注意到,该特征聚合模块不仅适用于VGG16主干网,也可以推广到其他卷积主干网。相比于仅利用c10进行预测,以及文献[21]仅融合相邻预测层的方案,本文视觉特征聚合模块以一种合理且可扩展的方式聚合了多个基本卷积层的特征图,提供了更丰富的局部细节和上下文信息,有利于更好刻画视频帧中的珊瑚礁鱼目标。
2.3 时序特征聚合模块
珊瑚礁鱼在水下游动时体态呈多维变化,当其部分遮挡或以罕见体态出现时,不可避免会带来检测困难。融合相邻帧特征显然有利于缓解该问题。基于此,本文设计了时序特征聚合模块在相邻帧上融合运动目标相关的特征图,以生成更强化的特征表示。
时序特征聚合模块的示意图如图2(b)所示。对于输入到网络的当前视频帧及其前后相邻帧,利用图1所示的主干网结构提取每帧图像各个卷积层的特征图,这些特征图记录了目标在当前图像上的卷积响应值。基于此,在特征图上计算当前帧与每个相邻帧的帧差图,对帧差图进行灰度化和二值化并结合适当后处理,如图2(b)所示,记录了当前帧与其相邻帧之间运动信息的二值帧差图。
对于网络中参与目标预测的特征图,通过以下公式对其进行时序聚合:

式中:fj,n为视频帧Ij聚合前的第n层特征图;f′i,n为视频帧Ii聚合后的第n层特征图;Bi,j为Ii与Ij的二值帧差图,当i=j时,Bi,j为值全为1的矩阵;“⊗”为对应相乘操作;Si=(Ii-k,Ii-k+1,…,Ii+k)为Ii及其相邻帧集合,k为邻域边界;wj为Ij对应的权重,即
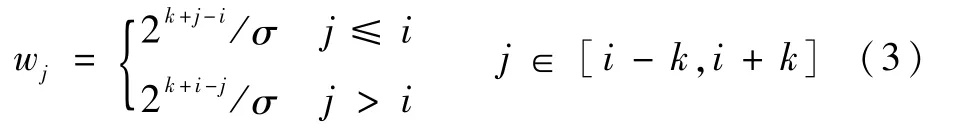
其中:σ为归一化因子,以确保所有权重之和为1。

式(2)以线性加权的方式,将相邻帧特征图中对应帧差运动区域的特征融合到当前帧同层特征图中。这一做法可以生成一个以当前帧运动目标为中心,适当囊括其周边区域,时序强化的特征。由于珊瑚礁鱼是视频中的运动主体,这一做法可有效缓解当前帧珊瑚礁鱼目标因运动模糊、罕见姿态等带来的特征表示困难。
以上时序融合在所有6个参与目标预测的卷积特征图上都将进行,其中包括了一个通过视觉特征聚合模块生成的预测层。因此,网络可提取到时空联合的强化特征更好地进行目标检测。注意到,文献[10]也提出了一种光流引导的相邻帧特征图融合方法。本文与其有2点区别:①在融合区域确定上,文献[10]先计算两帧之间的光流,再依此将每帧光流前景对应的特征图位移后再与当前帧相应位置叠加融合。与之对应,本文采用了计算代价显著降低的帧差运算,融合区域也是相对更宽泛的帧差前景区域。采用这一做法主要是考虑到低质量视频中光流计算误差较大,容易导致位移估计不准确。此外,认为鱼周边区域的特征也有助于检测。②在相邻帧融合的权重上,文献[10]用余弦相似度动态计算当前帧与相邻帧的权重,而本文采用的是一个以当前帧为中心的类高斯分布权重,直接赋予与当前帧更邻近的相邻帧更大权重。这一做法在降低计算量的同时,也一定程度避免了相似度计算对噪声敏感的影响。
上述融合中,时序聚合的邻域k是一个重要参数。大的k值融合的相邻帧多,但网络结构更复杂,计算代价更高;小的k值则有时序信息融合不充分的隐患。此外,选定k值后,邻域中图像分析的采样间隔也是一个需要明确的细节。将在消融实验中论证不同做法的区别。
2.4 后处理
基于帧级检测结果及置信度,本文先利用非极大值抑制消除单帧图像上的冗余检测框,再提出了一个时序后处理以提升珊瑚礁鱼检测精度。该后处理旨在改善部分情况下珊瑚礁鱼检测得分置信度过低,易造成漏检和误检的现象。具体地,在得到单帧检测结果后,先将相邻帧中满足检测类别相同且IoU>0.5的检测框标记成检测对,再将检测对中检测框得分统一为置信度高的得分。通过这种方式,一定程度利用了目标的时序互补性强化了检测得分,使检测结果更稳定。上述非极大值抑制和时序后处理如图3所示。

图3 非极大值抑制和本文提出的时序后处理Fig.3 Non-maximum suppression and the proposed temporal post-processing
本文网络实现时,由于当前帧预测需要利用前后相邻帧特征图,为避免重复提取图像特征,在确定邻域参数k及其采样间隔后,将申请一个公共缓存空间存储以当前帧为中心,邻域内所有采样图像参与预测的卷积特征图。这样,每帧检测时,只需计算当前帧的时空联合聚合特征图以开展以当前帧为中心的目标检测。对一个视频帧序列,则只需按时序对所有采样帧重复以上过程,相应调整缓存空间内容,即可依次计算所有采样帧上的检测结果。
3 实验与结果
3.1 数据集
用SeaCLEF国际竞赛[18]数据作为本文实验数据集。该数据集提供了5个不同场景和日期的93个水下监控视频,给出了其中出现的15种珊瑚礁鱼的逐帧标注,包括鱼的类别和矩形框形式的位置信息,共有21 396个标注样例。该数据集涵盖了图像分辨率低、水下环境复杂、鱼体态变化大等一系列真实水下监控视频包含的检测难点。
竞赛将数据集分成了训练集和测试集,分别包含20个和73个视频的13 882个和7 514个标注实例。训练集和测试集都涵盖了全部的5个场景。但是,不同鱼在数据集中的分布并不均匀,出现次数最多的网纹宅泥鱼在训练集和测试集上分别出现了3165和5 046次,15种鱼中黑缘单鳍鱼在测试集中仅出现了8次,甚至镜斑蝴蝶鱼和黑鳍粗唇鱼在测试集没有出现。因此参考文献[21],本文将上述3类鱼从检测任务中去除,构成了一个包含12种珊瑚礁鱼的目标检测任务。表1给出了这些鱼的名称,以及它们在训练集和测试集中的数量分布情况。

表1 SeaCLEF数据集中不同类别鱼的数量Table 1 Numbers of different fish species on SeaCLEF dataset
3.2 实验设置及评价指标
本文采用一个两步训练过程来训练网络。第1步基于单帧图像训练一个仅包含视觉特征聚合模块的目标检测网络:先读取ImageNet数据集的预训练参数,再采用批量随机梯度下降方法进行训练,批的大小为32张图像。设置网络总共迭代训练120 000次。先将学习率设置为0.000 1进行1 000次迭代的热身训练,完成热身训练以后将学习率升至0.001,迭代训练40 000次和80 000次之后,分别将学习率降低为0.000 1和0.000 01,以使网络更好地收敛。梯度更新动量值为0.9。第2步训练基于第1步得到的参数训练整个网络结构。由于特征图相加操作的可导性,整个网络是端到端可训练的。第2步同样采用批量随机梯度下降的精调训练,批的大小为1张图像,迭代轮数设置为60000次,其中前40000次与后20000次的学习率分别为0.000 1和0.000 01。采用了随机剪裁和调整图像对比度的数据增强方式。图像在输入网络之前先将大小调整为300×400。全部训练在一个GTX Titan X GPU上完成,基于TensorFlow平台完成整个模型训练需要约34 h。
推理阶段,本文网络接受当前帧及其前后多个相邻帧作为输入,输出当前帧的检测结果。检测结果经过2.4节的后处理,可得到视频级检测结果。评价指标上,本文用目标检测领域广泛使用的平均精度均值mAP,其定义为

式中:APi为第i个目标类别通过改变阈值得到的不同召回率下的平均精度;n为目标类别个数。
3.3 消融实验
通过消融实验来验证视觉特征聚合模块和时序特征聚合模块中特征图的具体融合方式,以及时序融合时当前帧的邻域及采样间隔。
融合方式方面,验证视觉特征聚合模块时,将网络结构设置为仅输入当前帧Ii的情况,此时网络仅包含图1中虚线框的部分。对比了对应相加、取最大值和取平均值3种特征图融合策略。表2给出了相应的mAP值。可以看到,对应相加取得了更好的性能。
验证不同融合方式对时序特征聚合模块的影响。先将网络固定为输入{Ii-4,Ii,Ii+4}3帧图像的情况。为简化起见,去除了网络中的视觉特征聚合模块。表2给出了上述3种情况下的mAP值。结果表明,取最大值进行融合更有利于进行珊瑚礁鱼检测。
分析采样邻域及间隔对结果的影响。受限于计算资源,仅考虑了输入不超过5个视频帧的情况。结合不同采样间隔,将其分成了如表3和表4所示的11种情况,其中2表示考虑{Ii-2,Ii,Ii+2}3帧图像的情况,46表示考虑{Ii-6,Ii-4,Ii,Ii+4,Ii+6}5帧图像的情况,其余依此类推。实验中网络都未包括视觉特征聚合模块。
可以看到,输入5帧图像可以取得比3帧图像更好的检测结果。这一点是符合预期的,因为聚合更多相邻帧有利于提取更具辨识力的特征。此外,注意到与当前帧间隔为6(3帧情况),以及4和8(5帧情况)时,相比于其他间隔情况下取得了更好的结果。帧数间隔大一般关联着更大的运动区域,对应到本文网络则是更大范围的特征融合。当间隔相对适中时,可使得相邻特征图中目标及合适范围的周边上下文得到更强化的刻画,但若间隔过大,则容易融合到更多的噪声而起到负面作用。基于以上结果,本文网络结构最终确定为接受{Ii-8,Ii-4,Ii,Ii+4,Ii+8}5帧图像作为输入,并将对应相加和取最大值分别作为视觉特征聚合和时序特征聚合中多个特征图的融合方式。

表2 不同融合方式及性能Table 2 Different fusion methods and their performance

表3 输入为3帧图像时不同参数下的网络性能Table 3 Network perfor mance under different parameters when three-frame images are input

表4 输入为5帧图像时不同参数下的网络性能Table 4 Network perfor mance under different parameters when five-frame images are input
3.4 实验结果及对比分析
为评估检测性能,将本文网络及其衍生结构和几种主流方法与模型进行了实验比较。
BS+GoogleNet[20]:德国耶拿大学提出的基于前景提取及分类的珊瑚礁鱼检测方法。
Faster R-CNN[26]、YOLOv3[28]和SSD[23]:采用这3个主流目标检测模型进行珊瑚礁鱼检测。
FFDet[21]:基于相邻卷积层特征融合的珊瑚礁鱼检测方法。
FGFA[10]:光流引导的相邻帧特征图融合的检测方法。
Ours-VTFA、Ours-VFA 和Ours-TFA:本 文 网络,以及本文网络分别去除时序特征聚合模块和视觉特征聚合模块后对应的珊瑚礁鱼检测方法。
表5给出了以上方法的图像级和视频级实验结果及时间消耗。可以看到,Ours-VTFA方法相比于传统基于前景提取及分类、主流目标检测模型取得了8.8% ~16.8%的相对性能提升,表明本文时空特征聚合网络能更好地检测水下珊瑚礁鱼。同时,该方法也取得了比仅考虑其中一种模态聚合的Ours-VFA和Ours-TFA更好的效果,说明从时间和空间2个维度强化特征提取的互补性和必要性。
视觉特征聚合方面,对比于没有特征融合的SSD和采用相邻层视觉特征融合的FFDet,Ours-VFA方法取得了更好的检测性能,说明基本卷积层聚合生成的特征图可以更好地描述珊瑚礁鱼的类别和位置信息,挖掘利用基本卷积层特征对低质量水下视频中珊瑚礁鱼检测具有重要价值。此外,注意到Ours-VFA方法的检测速度显著快于FGFA等高精度方法,仅略逊于精度不如它的SSD和FFDet。Ours-VFA方法不失为一种速度和精度得到较好折中的检测方案。

表5 不同方法的检测性能Table 5 Detection perfor mance of differ ent methods
时序特征聚合方面,Ours-TFA方法与SSD的区别在于:前者在网络中聚合了相邻帧对应运动区域的特征图,即获得了6.3%的mAP相对提升,验证了时序维度的挖掘利用有助于提升检测性能。本文基于帧差的相邻帧聚合方法可以融合相邻帧目标周边的上下文区域,有助于提取更加有效的特征。该方法虽然检测性能低于FGFA,但时间消耗减少了2倍以上,主要是帧差计算的代价显著低于光流计算。在Ours-VFA方法的基础上进一步融入时序特征聚合模块,可继续提升检测性能,再次说明了本文网络可以互补地聚合时间和空间维度的特征。注意到,Ours-VTFA方法可以取得优于FGFA的实验结果,且检测时间也缩短了2倍以上,这也再一次凸显了聚合基本卷积层特征的重要性。此外,所有方法采用了本文后处理技术后,检测精度均有一定提升,表明网络内外挖掘的时序信息具有一定互补性,在不同层次利用它们可进一步提升检测精度。
图4给出了各种检测模型在不同珊瑚礁鱼类别上的检测结果。其中,每种鱼的8个检测结果从左到右分别是Faster R-CNN、YOLOv3、SSD、FFDet、FGFA、Ours-VFA、Ours-TFA 和 Ours-VTFA 8种方法取得的。可以看到,不同类型鱼的检测结果差异巨大。即使性能最好的方法,在褐斑刺尾鲷上的AP值也不超过0.1。与之对应,无论是哪种方法,在宅泥鱼、克氏双锯鱼和月斑蝴蝶鱼上都取得了较高AP值。从两方面解释造成以上显著类间差异的原因:①珊瑚礁鱼样本数量在类别上分布不均。结合表1可看到,AP值高的鱼类别样本较多,而AP低的鱼类别样本较少,训练数据是否丰富,一定程度上影响了所构建模型的检测精度。②不同类型鱼的视觉辨识难度各不相同,导致检测难度不一。水下低质量视频中鱼的检测主要依赖对鱼颜色和形态轮廓等的刻画,在训练数据相对充足的情况下,部分颜色和形态易于辨识,区分度较大的鱼可以被高精度的检测,宅泥鱼和月斑蝴蝶鱼均属于此类。但是,当训练数据较少,且鱼的区分性特征在低质量视频中不突出,易与其他目标混淆时,如褐斑刺尾鲷,检测精度则受到严重影响。以上实验表明,水下监控视频中珊瑚礁鱼的高精度检测仍然是一个极具挑战的技术难点。

图4 各种检测模型在不同珊瑚礁鱼类别上的检测结果Fig.4 Detection results of different coral reef fish species by various detection models
4 结束语
认识到从充满挑战的水下监控视频中检测珊瑚礁鱼的重要价值,本文提出了一种时空特征聚合的水下珊瑚礁鱼检测方法。该方法从时间和空间2个维度出发,分别设计了一个视觉特征聚合模块以融合多层不同分辨率的卷积特征图,以及一个时序特征聚合模块以实现帧差引导的相邻帧卷积特征图融合。SeaCLEF数据集上的实验基本验证了以上2个特征聚合模块的有效性。本文基于以上聚合模块提出的检测模型相比于多个典型方法和模型,可以取得更好的检测精度。
检测性能的提升主要归功于提取了更具表征力的时空联合特征。除了特征,数据和模型也是影响检测精度的关键因素。在下一步工作中,一方面将探索如何利用互联网上公开的珊瑚礁鱼视频图像,进一步提升低质量水下视频中珊瑚礁鱼的检测精度。另一方面,还将关注如何利用生成对抗网络等技术,生成更多高质量和多样化的珊瑚礁鱼训练样本,从而构建更加鲁棒有效的珊瑚礁鱼检测模型。此外,还计划在开源深度学习平台飞桨上复现该方法。
