融合语义结构的注意力文本摘要模型
2021-04-12滕少华
滕少华,董 谱,张 巍
(广东工业大学 计算机学院,广东 广州 510006)
随着互联网的迅猛发展,互联网信息的数量也有了爆发量的增长,如何从互联网上的海量信息中获取有价值的信息成为了当前一个至关重要的问题。文本摘要技术作为能够通过理解长文本(例如新闻、微博、文章等)的内容信息,概括出相对简短的短文本,同时保留出长文本中的重要信息,成为解决该问题的一个关键技术。如何分析得到长文本中的重要信息以及如何将其中的重要信息组合得到人类语言习惯的短文本是文本摘要技术所要关注的重要问题。
文本摘要技术按照生成方式不同分为抽取式文本摘要和生成式文本摘要[1]。其中抽取式文本摘要是从原始文本中判断重要的句子或者词语,抽取这些句子和单词,并将这些句子和单词进行组合,使其能够概括原文本的短文本,生成式文本摘要一般主要用于长文本的摘要生成中。生成式文本摘要是通过转述、同义替换、句子缩写等方法,按照原文本的语义信息生成间接凝练的摘要,并使其符合人类的语言习惯。由于神经网络在自然语言处理领域的成功应用,结合神经网络的生成式文本摘要技术成为了当前的研究热点。
当前,主流的生成式文本摘要模型主要使用包含注意力机制的序列到序列模型,由于序列到序列(Sequence-to-Sequence, Seq2Seq)模型[2]在文本摘要领域的成功应用,使得生成式文本摘要的实现有了更有效的途径,最新的生成式文本摘要一般都是采用包含注意力机制的序列到序列模型为基础。该模型的基本思想是利用输入序列的全局信息推断出与之相对应的输出序列,由编码器(Encoder, en)和解码器(Decoder, de)构成。在序列到序列生成模型中,编码器一般都是基于循环神经网络(Recurrent Neural Network, RNN)[3],通过在传统RNN结构上的优化,现有的长短期记忆网络(Long Short-Term Memory,LSTM)[4]能够通过结构中输入门、输出门、遗忘门克服文本中上下文的长短期依赖问题,解决了长文本序列训练过程中的梯度消失和梯度爆炸问题。然而在实际上,LSTM需要一步步地去捕捉序列信息,在长文本上不能有效地对其进行编码,并且只能学习文本上下文的线性结构信息,对文本词语之间长期依赖没有有效的利用,忽略了上下文词与词之间的依赖关系,对文本句法结构信息的利用尚不够充分。而人类语言在语义结构上有很大的相关性,文本与文本、词语与词语之间相互具有依赖与修饰关系,因此,对语义结构层次的研究能够提高编码器对文本内容的理解能力,进一步缓解传统长短期记忆网络在长文本前后依赖关系上编码的性能缺陷。
针对上述问题,本文对当前主流的基于序列到序列模型的生成式文本摘要模型进行了如下改进:(1) 对文本中词语之间的依赖关系进行文本结构编码。文本结构编码旨在获取文档中词与词之间的前后依存关系,根据语言学关系,文本中词语之间具有依存句法关系,通过循环神经网络,对单词的依存关系进行训练,构造单词依存关系的结构嵌入。(2) 提出了一种注意力融合单元对语义信息和结构信息进行结合,得到同时包含语义信息和结构信息的全局注意力表示,并将其用于判断从词汇表中选择单词的概率指导摘要生成。
1 相关工作
生成式文本摘要是一种利用对文本中句子或者单词进行转述或者替换等方法来生成文本摘要的方法,随着深度学习在自然语言处理领域的应用,生成式文本摘要得到了迅猛发展。Seq2Seq模型最初被应用于机器翻译任务中,Rush等[5]首次将该模型应用于生成式文本摘要任务中,与之前的生成式方法相比,该模型利用了神经网络的特点在“理解”文本语义的基础上在编码器端对输入进行编码,然后利用注意力机制利用上下文在解码器端生成摘要。而后,Chopra等[6]在此基础上,使用RNN作为编码器,在相同数据集上取得了良好的效果。Nallapati等[7]进而将解码器换成RNN,从而构建了基于RNN的序列到序列模型。在此之外,他们还对传统编码器进行了拓展,在编码器端增加了命名实体识别和词性标注等元素。
在进行文本摘要任务前,需要建立固定大小的词汇表(Vocabulary),在处理文本时将文本的每个单词用其在词汇表中的索引代替。但是文章中会出现Vocabulary中未出现的词(Out of Vocabulary, OOV),常规Seq2Seq模型只能将其视为不认识的未登录词(Unknown Word, UNK)[8]。为了减少生成摘要中出现UNK的情况,Gu等[9]提出的CopyNet模型引入了拷贝机制,使得模型在必要时可以直接从输入中复制单词作为输出。与此同时,在摘要生成过程中会出现生成文本重复、曝光偏差等问题。See等[10]提出了指针生成网络(Pointer-Generator Networks, PGN)模型,通过概率来确定是从词汇表中生成一个词还是从源文本中复制一个词。同时加入覆盖机制(Coverage)强制每个时间步的输出注意力分散,在一定程度上解决了重复句子的问题。Liu等[11]增加判别网络来评估生成的摘要,达到了识别重复句子的效果。Zhang等[12]提出了一种结合双注意力和指针覆盖的模型用来解决摘要的句内重复和未登录词等问题。Dang等[13]提出一种由存储注意力和解码注意力构成的混合注意力解决文本重复问题,使用强化学习来训练模型解决曝光偏差问题。
然而,在文本摘要领域,当前很少有方法在序列到序列生成模型中结合文本的语义结构以及文本的词与词之间的依赖关系。Li等[14]首先在机器翻译中将源文本的语法结合到神经机器翻译中,在编码器端合并源本文语法结构树,学习文本的顺序结构和树结构,显著提高了机器翻译的翻译精度。Cao等[15]利用OpenIE和文本依赖解析从源文本中提取事实元组(Fact Tuples),根据提取的事实元组来提高生成摘要的置信度。Tan等[16]提出了一种短文本特征组合加权方法,根据文本不同特征的贡献程度确定权重进行特征选择并应用在文本情感分析领域。本文提出的融合语义结构的注意力文本摘要模型在上述工作的基础上,在序列到序列文本摘要生成模型中加入源本文的语法结构信息,帮助模型识别出具有摘要价值的内容,同时在注意力机制中,利用语义信息注意力和语义结构注意力,获得同时具有两种信息的文本特征,生成保持源文本关键信息和必要结构的摘要。
2 融合语义结构的注意力文本摘要模型
本文提出了一种融合语义结构的注意力文本摘要模型(Structure Based Attention Sequence to Sequence Model, SBA),图1为SBA全局模型示意图。模型的整体结构根据功能可以分解为3个部分:基于门控循环单元(Gated Recurrent Unit, GRU)[17]的双向循环神经网络、基于注意力机制的编码器-解码器结构和语义结构注意力融合模块。
2.1 问题定义
在本文中,定义源文本序列为S =(s1,s2,···,sm),将源文本作为输入,通过模型对源文本进行分析理解,生成一个简短的能概括源文本的摘要,生成的目标文本序列表示为 T =(t1,t2,···,tn),其中每个单词tn来自于固定大小的包含常用词汇的词汇表V ,其中m和 n 分别表示输入文本序列和输出文本序列的长度,且m >n。

图1 融合语义结构的注意力文本摘要全局模型Fig.1 Overall model of structure-based attention text summarization
2.2 双向循环神经网络




2.3 基于注意力机制的编码器-解码器结构

其中,上标 en 和d e分别表示编码器(Encoder)端和解码器(Decoder)端。
解码器根据编码器得到的源文本隐藏状态来预测下一个单词来生成摘要。通过结合注意力机制,解码器生成摘要T中的每一个词Tt(t=1,2,···,n)都有对应的上下文向量 ct(t=1,2,···,n),该上下文向量是对编码器中的所有隐藏状态信息的加权,用于引入源文本中每一个词的信息。见式(7)。
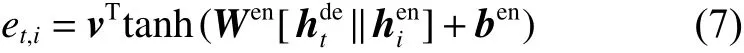


根据上下文信息来预测每一个词的生成概率Pvocab(w), 表示为从词汇表V 中取得概率值最高的单词作为下一个生成的单词的候选词,e xp(·)为自然常数的幂级数。
2.4 语义结构注意力融合模块
模型SBA的语义结构注意力融合模块的功能是引入文本的句法结构同文本的语义信息进行结合,提高模型对文本的理解能力。在文本摘要任务中,常采用word2vec来得到文本的词嵌入表示,该词嵌入模型注重词语间在向量表示空间的相对位置,即词语之间的语义相似关系。然而,当文本中词语的顺序及位置发生细微变化,词嵌入模型往往不能产生明显的感知,但是在实际语义上却千差万别,例如:“我爱你”和“你爱我”这两个句子中,句子的主宾位置发生变化,句子原本所要表达的意思也发生了变化,从而对最终生成的摘要准确性产生巨大的影响。
在编码器端,通过双向门控循环神经网络得到的源文本的隐藏状态信息包含了文本上下文的长短期记忆,由于对于过长的句子和具有过多段落的句子,词语的前后依赖关系变得更弱,容易丢失句子中的重要信息。为了解决这个问题,本文应用文本的依存分析来判断前后词语之间的依赖程度和相互联系程度。在一般情况下,生成的摘要句子仅使用主要语法成分(如主语、谓语、宾语),用词简练,无关修饰词较少,利用句法树对句子主要成分之间的依赖关系可以提高生成的摘要的质量。在本文中,使用斯坦福句法分析工具(Stanford CoreNLP)对句子成分进行分析。根据Rui等[18]的研究,在本文中将句子结构的依存结构中词与词的关系用三元组表示出来。使用双向循环神经网络对单词进行编码,得到依存树中每个词的句法结构嵌入,具体模型如图2所示。
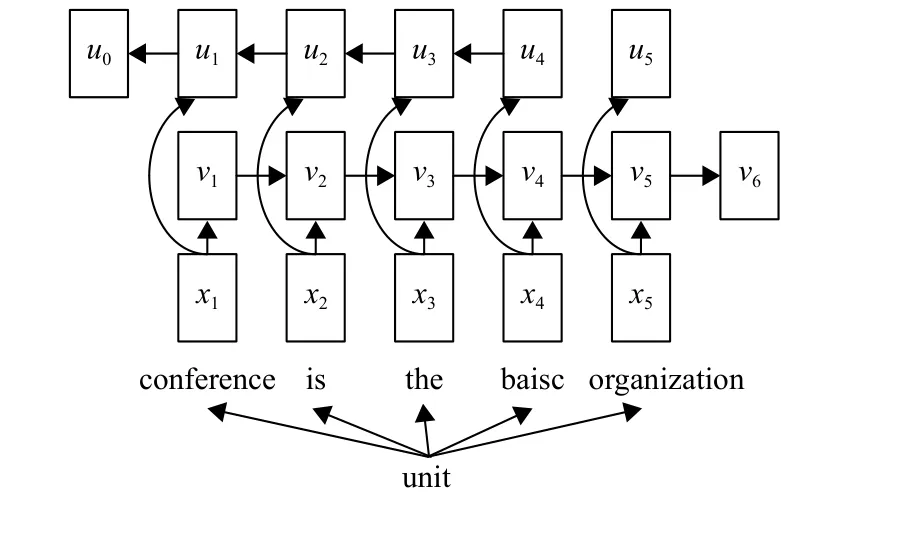
图2 句法结构嵌入模型样例Fig.2 An example of syntactic structure embedding model
如图2、3所示,以“This conference is the basic unit of organization”为例,上面5个单词为“unit”的依存节点,为了得到“unit”的句法结构嵌入,可以通过将其依存节点的词嵌入向量通过双向循环神经网络后隐藏状态信息拼接起来,用来表示为“unit”的句法结构嵌入向量。其中, xi为单词的词嵌入向量,vi为正向循环神经网络得到的隐藏状态信息, ui为反向循环神经网络得到的隐藏状态信息。将两者拼接起来,(u0||v6)即为最终的句法结构嵌入向量。
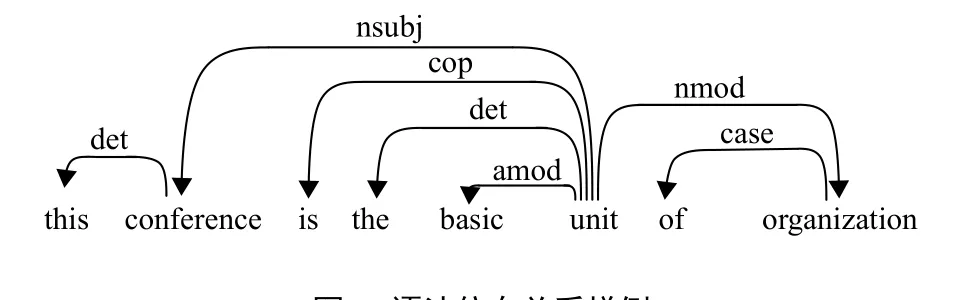
图3 语法依存关系样例Fig.3 An example of dependency parse tree
如图1所示,编码器依次读取源文本 S中的每一个词 si(i=1,2,···,m) ,生成对应隐藏状态信息hetn(i=1,2,···,m),该隐藏状态信息仅仅包含该单词的前词、后词的语义信息,没有包含文本的整体含义,通过引入每个词的结构嵌入,可以依靠结构嵌入中含有的单词之间句法结构上的依赖性来引入文本的整体含义。


在对整个文本理解中,语义信息与句法结构信息侧重程度不同,在生成摘要的过程中的贡献也不同,为了平衡两者的贡献,引入可训练的参数ε,如式(15)所示。
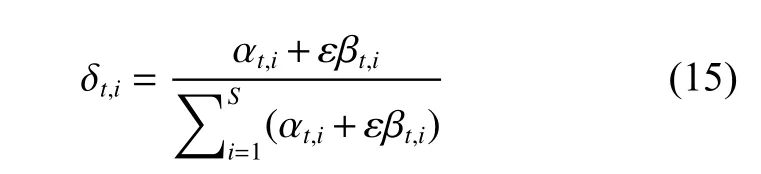
此时,δt,i成为为新的注意力权重,并根据其来计算上下文向量ct, 从而根据 ct来预测下一个生成的单词。

其中S 为输入源文本的长度。
在模型训练时,为了减少误差的累积,在解码器端,使用导师驱动(Teacher Forcing)算法[19]依次输入参考摘要中的每一个词,生成对应的隐藏状态,用于计算损失。
此时,对于给定的文档D,通过最小化最终生成摘要的负对数似然估计来训练模型参数。损失函数L表示如式(17)所示。

在模型测试时,使用集束搜索(Bean Search)算法[20]来生成摘要序列,该算法是一种启发式图搜索算法,使用广度优先策略建立搜索树,在树的每一层按照一定的评价代价对节点进行排序,保留预先设定集束宽度的节点,仅在这些节点上进行下一层的拓展,即在生成摘要前检索出大量的词汇,从中得到最优的选择。
3 实验数据与实验设置
3.1 数据集
本文实验采用的数据集是Gigaword数据集,该数据集收集来自New York Times等多个新闻源的新闻语料,每条数据包含新闻源原始文章内容以及其对应的标题,标题即对应参考摘要。Gigaword数据集规模如表1所示。

表1 实验数据集Table 1 The statistical data of dataset
3.2 评价指标
ROUGE[21]评估标准(Recall-Oriented Understudy for Gisting Evaluation, ROUGE)是在文本摘要领域被广泛使用评估方法。ROUGE是基于摘要与原文中n元词(n-gram)的共现信息来评价生成摘要的质量的方法。一般情况下,常使用ROUGE-1、ROUGE-2和ROUGE-L来对生成的摘要进行评估。ROUGE-N的定义如下所示。

其中,分母是n-gram的个数,分子是参考摘要和文本摘要共有的n-gram的个数,R为参考摘要。
ROUGE-L指标中L为参考文本和生成摘要的最长公共子序列,ROUGE-L的计算方式如式(19)~(21)所示。
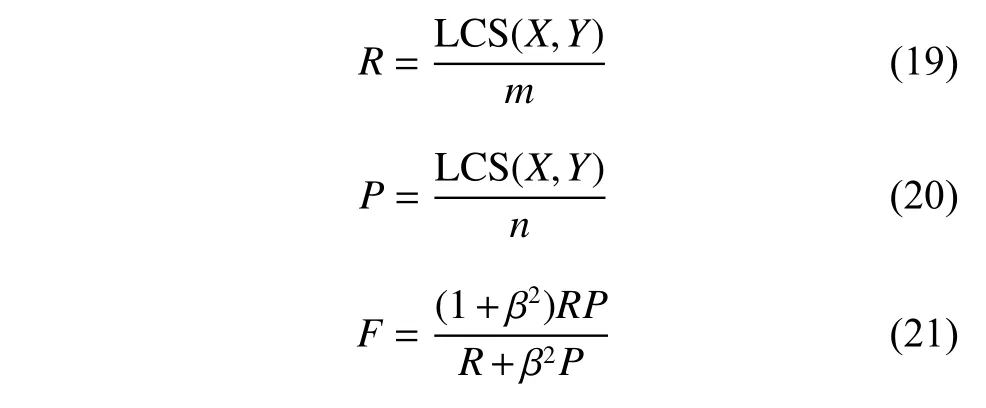
其中,L CS(X,Y)为参考摘要X和生成摘要Y的最长公共子序列的长度,m 、n 分别表示参考摘要和摘要的长度,R、P分别表示生成摘要的召回率(Recall)和准确率(Precision)。最终得到的F即为ROUGE-L。在实验中使用ROUGE-1和ROUGE-2表示生成摘要信息的丰富性,使用ROUGE-L则表示生成摘要的流畅性。
3.3 实验参数设置
在本文中,实验使用PyTorch深度学习框架编写代码并在一块NVIDIA 1080Ti GPU上进行实验。在本文中,选取源文本及其摘要中出现频率最高的70 000个单词作为输入字典词汇表,输出字典词汇表则包含默认的5 000个单词。在训练阶段,批量大小为64,模型使用Adam[22]优化器,参数设置分别为α=0.000 4 , β1=0.9 , β2=0.999,ε =1×10-8;encoder和decoder的隐藏层节点的个数为256;decoder采用集束宽度为5的集束搜索来生成更好的摘要内容。
所有超参数都根据验证集进行调整,并在测试集上测试其性能。
3.4 模型说明
为了评估本文提出的模型在文本摘要任务中的性能,本文以结合注意力机制的Seq2Seq模型ABS+为基准模型,同时选取在文本摘要生成领域中效果较好的模型作为对比模型。在实验中,将本文提出的模型性能与对比模型性能进行了验证与比较。
3.4.1 对比模型
(1) ABS+[5]:ABS+是一种包含注意力机制的encoder-decoder模型。编码器将输入序列转化为输入序列的隐藏状态向量,解码器再将此向量状态转换成目标序列,注意力机制将根据解码器先前的输出序列给予编码器输入序列不同的关注程度。
(2) RAS-Elman[6]:RAS-Elman是一种包含注意力机制的编码器-解码器(encoder-decoder)模型。编码器将输入单词的位置关系考虑在内,且采用卷积神经网络进行编码。解码器采用循环神经网络。
(3) PGN[10]:指针生成网络(Pointer-Generator Networks, PGN)模型在包含注意力的encoder-decoder模型基础上,增加 Pgen参数,判断是否从源文本中复制单词,解决了OOV问题。
(4) DRGD[23]:DRGD模型通过分析文本句子中的一些固定结构,将潜在结构信息融入到生成模型中,从而提高生成文本的质量。
3.4.2 本文提出的模型
(1) PGN-S:模型以包含注意力的PGN模型为基础,编码器仅使用句法结构嵌入,提取出文本中词语间的依赖关系来指导文本摘要生成。
(2) PGN-SS:模型在PGN-S模型的基础上,编码器同时使用文本的语义信息词嵌入和句法结构嵌入,分别计算语义信息注意力权重和句法结构注意力权重,根据平均注意力权重获取文本信息的深层特征和结构特征,生成具有句法结构信息的文本摘要。
(3) SBA:模型在PGN-SS模型基础上进行优化,按照对摘要生成准确性的贡献程度,对文本的语义信息和句法结构信息赋予不同的权重,综合考虑语义信息和句法结构信息的模型性能的影响,细化模型对深层隐藏特征的理解能力。
3.5 实验结果及分析
3.5.1 ROUGE指标评估结果
表2对比了上述几种文本摘要模型在Gigaword数据集上的实验结果,每个单元的数据分别对应各个模型生成摘要准确度的评估值,R-1、R-2和R-L分别表示ROUGE-1、ROUGE-2和ROUGE-L指标。通过对上表分析得知,本文提出的模型同对比模型相比,融合句法结构的文本摘要模型SBA在ROUGE评价指标上的得分表明其文本摘要生成的性能得到了明显提升。同提出Gigaword数据集的基准模型ABS+相比,在ROUGE-1、ROUGE-2和ROUGE-L的值分别提升了6.42%、5.23%和5.89%。同DRGD模型相比,分别提升了1.15%、0.31%和0.61%。
将SBA模型同PGN-S、PGN-SS模型相比较,PGN-S模型在编码器端仅使用文本句法结构信息作为词嵌入信息,损失了文本语义信息,对文本整体信息理解不足,同基准模型在ROUGE指标上提升较小。PGN-SS模型在PGN-S模型的基础上,结合文本的语义信息和句法结构信息,同ABS+基准模型相比,ROUGE-1、ROUGE-2和ROUGE-L的指标分别提升了5.87%、4.38%和5.21%。在文本信息理解上更深入,文本摘要性能有较大提升。SBA模型则进一步根据语义信息与句法结构对文本理解的贡献度的差异,训练得到语义信息与句法结构信息的权重比例,在生成摘要的准确性上有了进一步提升。
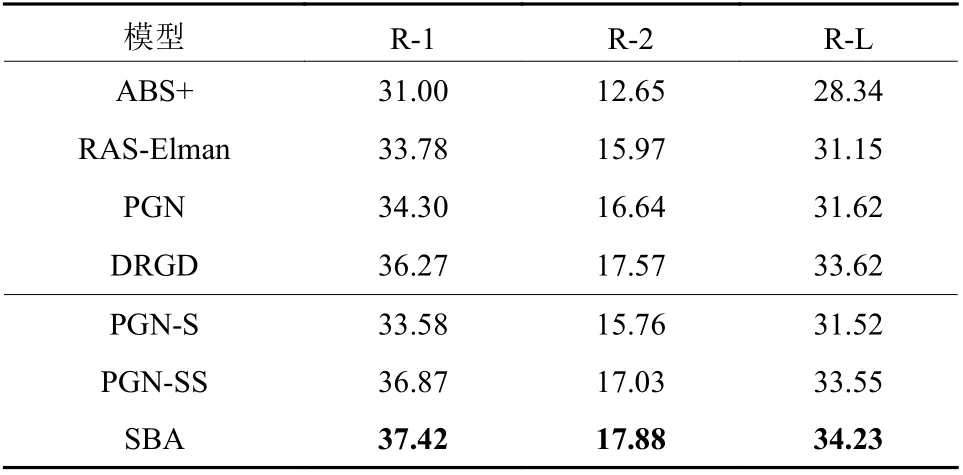
表2 各模型在Gigaword数据集上的实验结果Table 2 The results of models on Gigaword dataset
3.5.2 案例展示
为了进一步直观地评估本文提出的模型的摘要生成能力,表3中展示了从最终生成的摘要中选择的样例。
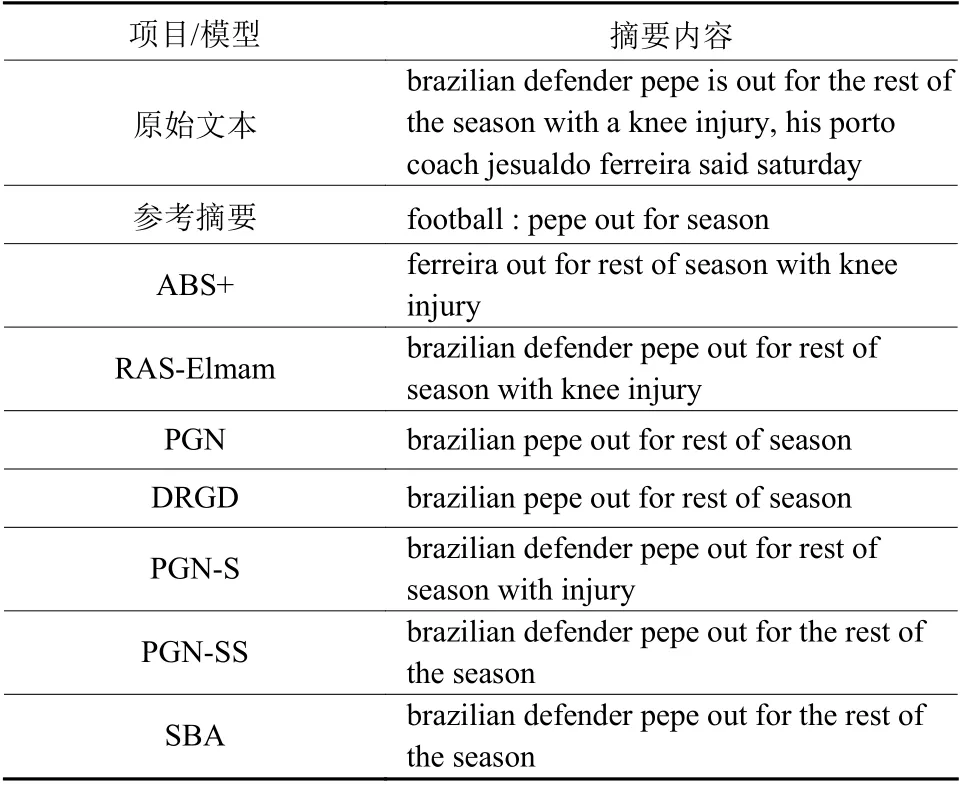
表3 生成摘要案例Table 3 The examples of generated summary
从表3中可以看出,同其他几种模型相比。本文提出的融合语义结构的注意力文本摘要模型SBA在保证文本信息保留的准确度的情况下,通过在编码器端添加文本的结构嵌入,能够准确地捕获原始文本中的词语依赖关系。例如,同PGN模型和DRGD模型生成的摘要相比,SBA模型生成的摘要中保留了“brazilian pepe”形容词修饰名词和“defender pepe”名词组合形式,语义信息保留的更加完整具体,关键信息得以保留。最终生成的摘要文本句法结构和语义信息保留最为完整,能够准确概括原始文本的主要含义。
4 结束语
通过分析文本的句法结构以及结合注意力机制,本文提出了一种基于序列到序列模型的文本摘要生成模型,在实验中取得了较好的结果。首先,模型通过双向门控神经网络获取源文本的隐藏信息,其次,采用基于句法分析的文本嵌入得到文本的语义结构信息,最后将源文本隐藏状态信息的注意力权重与语义结构的注意力权重结合得到最终控制编码器生成摘要文本的注意力权重。通过对比本文提出的模型与对比模型生成的摘要文本在ROUGE-1、ROUGE-2、ROUGE-L评估指标的得分,验证本模型在Gigaword数据集上进行文本摘要任务,取得了良好的效果,生成了准确概括源文本的含义且具有良好语法可读性的摘要。在下一步可以考虑在现有模型的基础上结合更多特征并在中文数据集上测试本模型的效果以验证其对多种语言的适用性。
