基于协同过滤算法的中医智能问诊系统研究*
2021-04-12迪盼祺夏春明王忆勤许朝霞
迪盼祺,夏春明,2**,王忆勤,高 慧,许朝霞
(1. 华东理工大学机械与动力工程学院 上海 200237;2. 上海工程技术大学机械与汽车工程学院 上海 201620;3. 上海中医药大学上海市健康辨识与评估实验室 上海 201203)
问诊作为传统中医“望、闻、问、切”四诊的重要诊断方式之一,通常指医生通过与患者或陪诊者直接进行有目的的对话以获取信息,在临床病症诊断中起着非常重要的作用,被视为“诊病之要领,临证之首务”。富有经验的医生往往通过几个简单的问题,可以对疾病做出初步判断甚至准确诊断,而初级医师则需要结合更多的信息才可以做出比较合理的判断。与其他诊法相比,运用人工智能技术对传统中医问诊进行系统化、智能化、规范化的研究具有更高的可行性和重要应用价值。
相对于易受环境因素及医生主观臆断和临床思维定势影响的望、闻、切三诊,问诊所获得的信息在形式上相对客观[1]。但由于问诊内容易受医患双方的影响,具有一定的主观性,医师若要提高问诊效率,需要额外掌握丰富的问诊方法和沟通技巧[2],使得临床诊断的门槛增高,因此需要进行问诊规范化采集及建模方法的研究。目前,大量的科研工作者在规范化问诊量表及问诊辨证模型研究中做了大量的工作[3]。刘国萍等[4]对心系病证进行大量的文献调研,经过与专家多次研讨以及反复临床验证,研制了中医心系病症的问诊信息采集量表。王哲等[5]通过对抑郁症病证信息进行临床调查、条目分析及经验性筛选,研制了简明抑郁症中医证候自评量表。许朝霞等[6]建立了基于隐结构的心血管疾病中医问诊证候分类模型,该模型在定性与定量层面与中医临床实践具有较好的一致性。一些学者应用基于概率图模型的机器学习算法,如贝叶斯网络、条件随机场,对慢性胃炎问诊数据进行建模,研究结果与中医理论基本一致[7,8]。文献[9,10]利用基于统计学习的方法,如逻辑回归和最大熵模型,进行肝硬化症状组合规律的研究和中医证候的分类研究,对临床疾病诊断具有一定的辅助作用。文献[11,12]采用基于随机森林、深度森林算法对慢性胃炎问诊数据进行建模,能够较好地解决多证候相兼的中医辨证问题。
在中医问诊客观化研究中,对于基于症状特征的证候分类研究已经有了非常明显的进展,但对于症状采集过程的研究进展仍比较缓慢,尤其是中医问诊过程中“问什么、怎么问”两个核心问题的智能化研究。本文致力于解决问诊过程智能化的两个核心问题,构建了基于物品协同过滤推荐算法的中医智能问诊系统,对由心系问诊量表采集的心系病证数据进行建模,将症状看作物品,问诊过程看作物品推荐过程,实现从症状到症状的智能化问诊。本系统根据从患者方得到的已知症状,针对性地对患者的潜在症状进行提问,通过几轮简单的问答,即可大致获取该患者所患病证的核心症状,从而避开依据问诊量表逐条记录的繁琐过程,提高问诊效率,为中医问诊客观化研究提供新的思路。
1 资料与方法
1.1 实验数据
本课题的实验数据采用上海中医药大学中医四诊综合实验室提供的通过问诊量表采集的心系疾病中医问诊数据。问诊量表是在参考主流期刊杂志上心系疾病相关文献的基础上制作的[13]。数据采集时间为2015年9月-2017年3月,数 据 来 源 包 括 上 海 中 医药大学附属龙华医院、曙光医院和岳阳医院等临床病例,共收集1014 条数据。其中单证候病例261 例,双证候病例359 例,两个以上兼证病例394 例;其中患有心气虚证候的病例数794 例,占总病例的78.3%,患有心阳虚的病例数222 例,患有心阴虚392 例,患有痰浊的病例数399 例,患有血瘀的病例数284 例。病例数据由具有中级职称以上(或具有博士学位)的医师根据量表进行症状的收集,记录了包括寒热、饮食口味等8 个维度的症状共计111 个特征,删除一些个例特征之后剩余80个特征,并相应的标出每个病例对应的证型。问诊量表中症状和证型的有、无分别用1 和0表示,并将主要的心系疾病分为6个证型,分别为心气虚、心阳虚、心阴虚、痰浊、血瘀、气滞。采用词袋模型对所有病例进行编码,即首先根据所有症状和证候生成长度为117维的词袋,当某一症状或证候出现时,对应位置为1,否则为0。例如病例甲患有心悸、咳痰等临床症状,则病例甲在这些症状下的值为1,未出现心烦、畏寒等,则这些症状下的值为0;最终由医师诊断该患者属于心气虚、痰浊、血瘀证型,则这些证型对应的值为1;未出现的其他证型的值为0(表1),所有病例数据经过处理后作为证候分类模型的症状-证型输入向量。

表1 心系疾病数据格式
1.2 中医智能问诊系统概述
本文提出的智能问诊系统整体流程(图1):首先基于原始数据训练证候分类模型,然后将系统获取到的症状输入到分类模型中即可输出诊断结果,在获取症状时,本系统将已有的问诊数据作为先验知识对患者进行针对性的提问。

图1 问诊系统流程图
1.3 基于物品的协同过滤推荐算法
推荐系统是一项个性化信息过滤技术,其本身就是为了解决互联网大数据背景下的信息过载问题而提出来的一种方法。推荐系统的关键在于推荐算法,目前推荐算法主要分为2 大块,传统推荐算法和基于深度学习技术的推荐算法[14]。传统推荐算法主要分为以下3类:基于内容的推荐算法、基于图模型和基于邻域的推荐算法。其中基于邻域的推荐算法又分为基于用户的协同过滤(User-Based Collaborative Filtering,UserCF)推荐算法[15]和基于物品的协同过滤(Item-Based Collaborative Filtering,ItemCF)推荐算法[16]。基于物品的协同过滤推荐算法是目前研究和使用最广泛的推荐算法之一[17]。依据神经网络基于深度学习的推荐方法主要分为4 类:基于深度神经网络的推荐方法、基于卷积神经网络的推荐方法、基于循环神经网络和长短期记忆神经网络的推荐方法、基于图神经网络的推荐方法。深度学习技术具有较强的表征能力,抗噪能力等,但是由于问诊客观化前期积累的大量数据为量表化数据,不利于深度学习模型建模,而传统推荐系统是基于商场购物推荐发展起来的,因此对结构化的数据能够起到更好的拟合效果。比如,ItemCF是用于解决商场物品推荐所提出来的算法,而这类数据是由用户-物品矩阵组成的购物篮数据(表2)。本文用于分析建模的中医问诊数据与购物篮数据形式上基本一致(后文中有数据样式展示)。因此,采用相似的思想来分析中医问诊中的潜在症状。由于患者就诊时,通过问诊最初仅可以获取到较少初始症状,无法根据有限的信息衡量患者之间的相似度,因此,本文采用基于物品的协同过滤推荐算法,将患者的症状看作物品,根据已有的问诊数据计算症状之间的相似度,相似度的大小表征了症状关联性的强弱,当新患者问诊时,即可根据其最初问答获得的少数症状推断可能的相似症状。
相似度计算是ItemCF 推荐算法实施过程中最关键的环节[18,19],常用的相似度计算方法有Pearson 相关系数和余弦相似性等。刘国萍等[20]在分析冠心病患者症状之间的关联性时,提出了症状间关联密度的概念,以此度量症状之间相关性符合中医传统理论和临床实践。其用症状共同出现的次数/单个症状在样本中出现的次数,用PFiFj表示症状Fi与Fj的关联密度其采用如下公式计算:
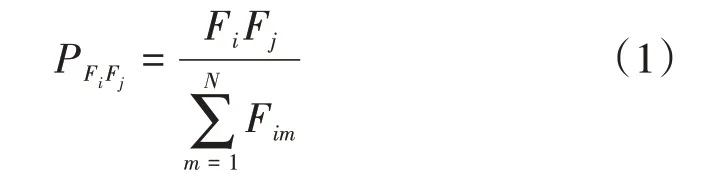
但是该种计算方法会出现高频症状与任何症状的关联密度都很高,因此本文在分母中增加了对高频症状的惩罚项,采用如下公式计算症状之间的关联度(本文中症状相似度即为症状关联度),其中α的取值通过遗传算法寻优得到。

其中,α∈[0.5,1],通过提高α惩罚高频症状Fj,特别地,α取1时,即为公式(1)。
ItemCF 根据以往用户-物品矩阵计算物品之间的相似度,在得到物品之间的相似度后,通过如下公式计算将物品j推荐给用户u的推荐指数:
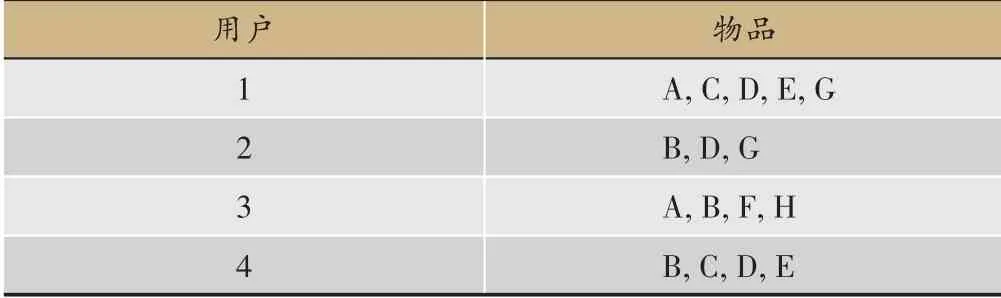
表2 用户物品矩阵

公式中,N(u)是用户购买的物品集合,S(i,k)是和物品j最相似的K个物品的集合,Wji是物品j和i的相似度,rui是用户u对物品i的兴趣,通常用户对物品的兴趣采用用户对物品的评分,但对于购物篮式的没有评分的隐反馈数据,一般根据用户是否购买过某物品将其设为1或0。
1.4 遗传算法寻优原理介绍
遗传算法(Genetic Algorithm,GA)是模拟生物进化优化种群的思想而设计出来求解优化问题的一种启发式算法,非常适用于解决优化目标不可微时的优化问题。遗传算法首先将待优化参数进行随机初始化得到问题初始解——初始种群,然后进行不断进化迭代搜索。种群中每个个体都为问题的一个解,每个个体表示为遗传染色体,它们在随后的迭代中不断进行遗传进化,不断生成新一代的染色体,每一代都通过计算根据问题抽象出的适应度函数来衡量每个个体对环境的适应度,通过对染色体进行选择得到适应度较好的个体,通过交叉和变异来产生新的个体,父代种群经过选择、交叉和变异之后得到子代种群,然后在子代种群中寻找优秀个体,最终求得问题的最优解。
基础完整的GA运行流程(图2)。
遗传算法中主要的运行参数有:个体编码串长度l、种群规模M、交叉概率Pc、变异概率Pm、终止代数T。遗传算法在寻优过程中通常要对这些参数进行合理的选择才能取得问题最优解。本文在求解优化问题时直接调用了Jazzbin 等人开发的遗传算法工具箱Geatpy[21]。该工具箱利用“定义问题类+调用算法模板”的模式来进行进化优化。该工具箱实现了对变量自动编码,预设好了Pc、Pm并且嵌入了一些常用的遗传算法改进方法,保证了遗传算法运行的鲁棒性。在使用过程中,可以实现只修改适应度函数和设置变量个数、变量取值范围、种群规模及终止代数T来定义问题类,然后调用算法模版完成优化,大大简化了遗传算法优化过程。
1.5 基于ItemCF的中医智能问诊系统
ItemCF 在计算物品相似度时默认一个假设,即假设用户的兴趣可以分成几个隐含类,当几个物品同时多次出现在不同用户的兴趣列表时,那么可以认为这几个物品很可能属于同一个隐含兴趣类,即它们之间有很大的相似性。因此基于ItemCF 的中医问诊系统在运行过程中有如下假设:
①如果几个症状同时出现在多个患者的症状列表中,那么可以认为这几种症状同属于某一隐含类。②每个证候可以通过几个症状确定,而且这几个症状是相互关联的。③当症状作为辨证因素时,不同症状的重要程度不同,核心症状应该具有更高的权重。
基于上述假设,问诊系统的工作原理可以描述为:若患者表述其患有的某几个症状,那么该患者很可能同时患有这几个症状的部分关联症状。另外,在潜在症状中,患者更可能同时患有核心症状的关联症状。
ItemCF 计算物品推荐指数时,会考虑用户对以往物品的评价rui,而在问诊过程中,无法依靠患者过去的某个症状做判断,因此,本文结合问诊特点对ItemCF 物品推荐指数的计算公式进行改进。在问诊过程中,系统通过如下公式计算患者可能患有的兼症的患症指数:

其中,N(u)为已知患者u所患的症状,S(i,k)表示与症状i相似度最高的k个症状,Wji是症状j和症状i的相似度,ri表示症状i为核心症状的权重,根据前文的假设,ri的大小影响推荐结果中某一类症状推荐的可能性,也就间接反应某一证候出现的可能性。ri可以根据中医师经验定义,本文通过遗传算法来寻找每个症状最优的ri值,使得对大多数患者进行提问的症状能够尽可能的准确。
基于ItemCF 进行症状获取的过程可以通过图3进行说明。图3 中假设患者初始症状为心悸和盗汗,推荐系统根据历史数据计算所得的症状关联性即症状相似度,筛选出分别与心悸和盗汗关联性较强的症状作为候选症状,此处各选择两个相似症状作为说明,系统实际运作时会选择8-10 个相似症状作为候选症状,胸闷和心烦是与心悸较为相似的症状,潮热和手足心热是与盗汗较为相似的症状。然后根据公式(3)计算患者对每个候选症状的患症指数,最后根据患症指数排序输出所要提问的症状。
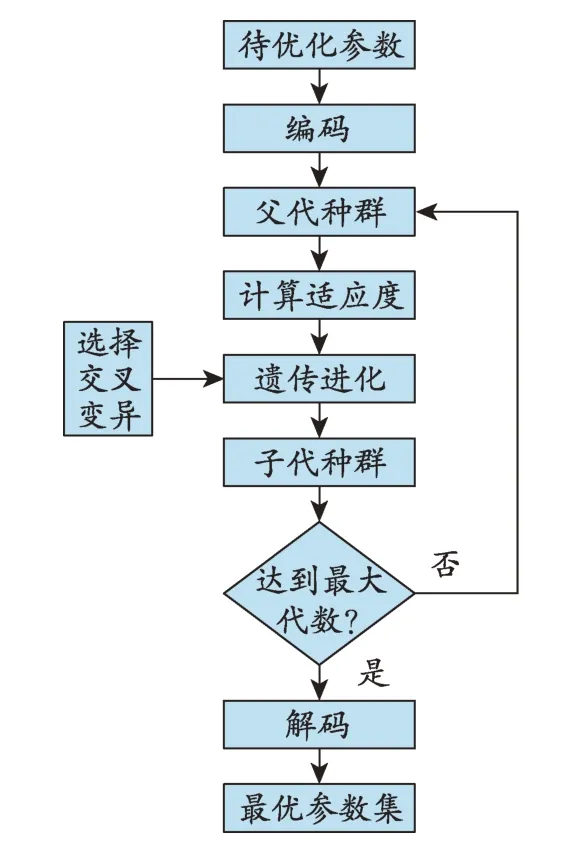
图2 遗传算法运行流程图

图3 ItemCF症状获取示例
为了抽象出优化症状权重的适应度函数,本文根据患者实际就医过程设计了一种问诊系统测试方法,对每一条问诊数据进行模拟问诊再现(图4)。首先将每条原始问诊数据分割成由初始症状和后续问诊症状组成的问诊数据,初始症状从原始数据中随机选择一条主症(例如:对于心系疾病,主症为:心悸、胸闷、胸痛、气短/气急/憋气),后续症状即为原数据中剩余的症状。然后根据初始症状及症状相似度列表选择潜在症状列表,按照该列表顺序对当前这条问诊数据进行检索,如果包含某一症状,将该症状存入已知症状列表中并重新计算候选症状列表,否则存入无效症状列表中,并继续按照潜在症状列表顺序提问。本文设定循环提问终止条件为提问10 次或者问到的症状数达到原始症状数的95%以上,在实际临床应用时,则可以提问患者是否还有其他不适症状作为停止条件。这样经过多次循环提问之后就可以得到每条问诊数据基于本问诊系统所得到的症状列表。
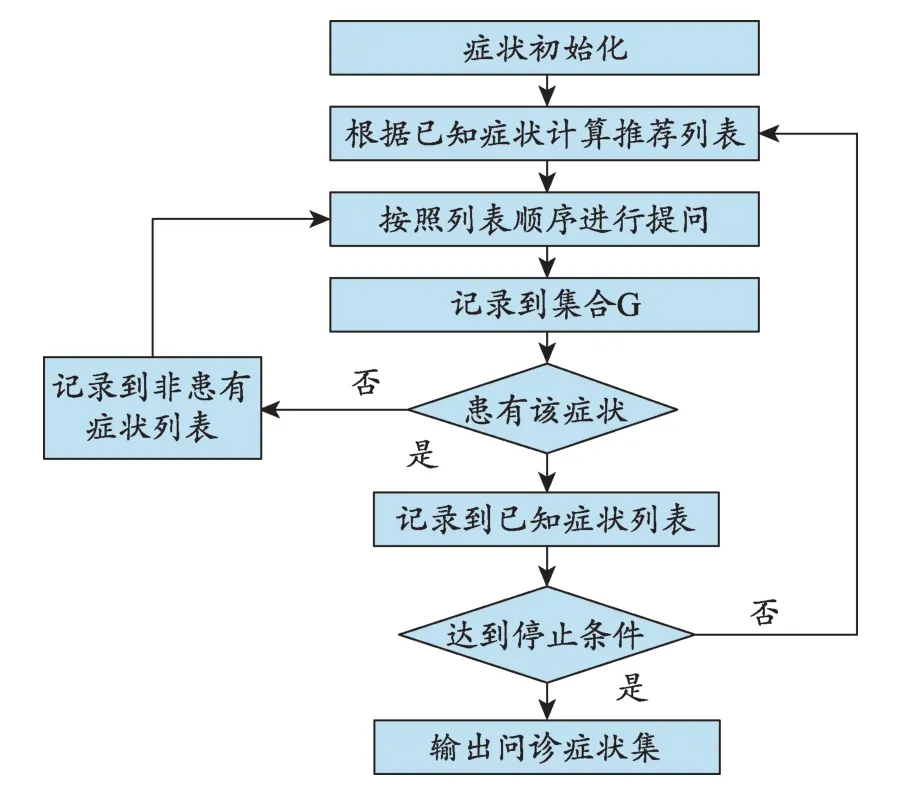
图4 问诊测试流程图
本文将所得到的症状列表与原始症状列表进行对比,基于分类问题中召回率计算方法,定义了问诊系统提问有效性指标,计算公式如下:

其中,EQ表示每次提问症状时刚好问到患有该症状的问题次数,TQ表示对一个患者的总提问次数。本文将Eff作为遗传算法的适应度函数,通过遗传算法来优化症状权重的流程图(图5)。

图5 遗传算法优化症状权重流程图
在遗传算法优化症状权重过程中,首先初始化一组症状权重及α,然后通过公式(2)计算各个症状间的相似度,得到症状相似度表,接着将症状相似度表及权重代入到ItemCF 算法中进行问诊测试,进行完一轮问诊测试后计算Eff,筛选出子代种群,然后进行不断寻优,直到进化代数达到预设进化代数,优化结束并输出最优权重。
2 结果
本文提出的中医智能问诊系统由两大部分组成,一是问症状,二是根据问得的症状进行辨证。系统实施流程包含4 步:①遗传算法优化症状权重及症状关联密度惩罚系数α;②计算症状之间的相似度;③训练问诊分类模型;④利用问诊分类模型对提问到的症状做证候分类预测。
首先是通过遗传算法优化症状权重及症状关联密度惩罚项系数α。本文使用geatpy 遗传算法工具箱对症状权重进行了寻优,设定适应度函数为前文定义的Eff,取变量个数为症状个数80,另外加一维惩罚项系数α,共81 维。表征症状的变量取值范围[0-5],表征α的变量取值范围[0.5-1],设置种群大小为50,进化代数为500,可以得到进化曲线(图6)。从图中可以看出种群进化到400 代时,目标函数已经收敛到0.42,此时最优个体即最优权重及α值示例(表3)。
通过遗传算法得到最优α= 0.58,根据公式2计算得到的症状相似度为(表4)。
本问诊系统的最终目标是辅助中医师完成辨证,为了验证基于ItemCF 的症状提问系统的有效性,本文基于原始问诊数据对每个单一证候训练了随机森林二分类模型,然后将六个输出结果拼接起来作为多证候诊断输出,选取四个指标来评价分类模型:平均召回率(avg_Rec)、平均特异度(avg_Spe)、平均精确率(avg_Pre)和G均值(G-mean),分别定义为:
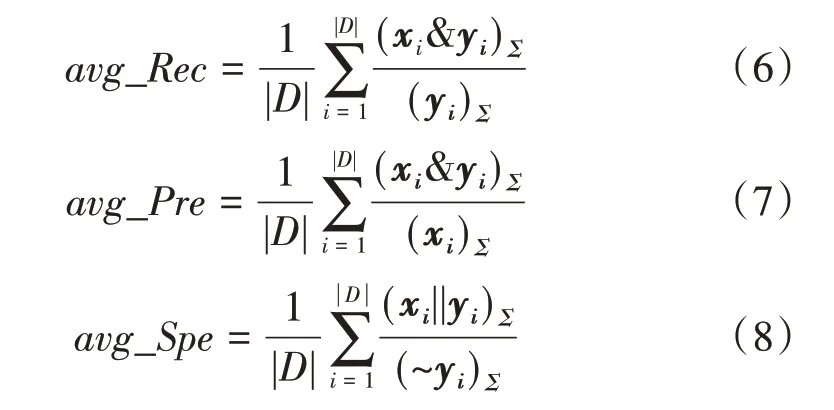

表3 症状权重示例

表4 症状相似度示例

图6 症状权重优化对应的提问效率进化曲线
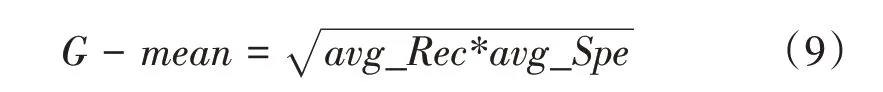
注:(∙)Σ表示二进制各位求和;&表示与运算;||表示或运算;~表示非运算
本文根据随机森林生成的特征重要性对原始数据的症状数量做了不同程度的筛选,选取30%的样本作为测试集,比较了症状为80 个、52 个和27 个时分类器在测试集上的表现性能。从图7 可以看出,在三组不同症状特征数量下,分类器所表现出的性能基本一致,从而可以反映出原始80个特征里有一半以上的特征都是冗余特征,因此,在问诊过程中可以针对性的从这27个症状中进行提问。

图7 不同症状特征下分类器表现性能
为了验证上述结论的有效性,本文分别采取从27及80个症状中进行提问,将不同提问次数下获取到的症状输入训练好的分类器,这里选择由80个症状训练所得的分类器,选取分类器性能指标avg_Rec、avg_Pre、G-mean,比较了两种提问方式在分类器上的预测表现,这里将预测结果的指标数值与原始分类器在原始样本上预测的指标数值作对比,着重比较提问系统所能得到原始分类效果的百分比。随着提问次数的增加,两种提问方式的预测表现都在逐渐上升,在进行到25次提问时,都可以得到原始分类器90%以上的预测表现,说明基于ItemCF 的提问是有效的。同时可以看出,不同指标下虚线总是高于实线(图8)。可以得出结论:从27 个症状中提问的效果(如虚线所示),要好于从80个症状中提问的效果(如实线所示),并且从27 个症状中进行25 次提问可以还原原始分类器95%以上预测效果。

图8 不同提问次数下问诊系统性能表现
由于主症对于心系疾病的六种证候没有特异性,因此主症所能提供的信息量对于消除证候的不确定性是远远不够的,而在实际中医诊断中,问诊会结合其它三诊所提供的信息去问,从而取得一个比较合理的问诊结果。因此,本文通过固定问诊系统第一个问题来额外增加一个症状的方式,验证了在问诊开始输入更多的信息量时本系统的问诊效果。这个固定的问题是从一个小症状集中去提问,从而获取到原始问诊数据中包含在这个小症状集中的一个症状,而这个小症状集是基于单证候分类重要性生成的,并通过中医师筛选最后确定,其中共包含8 个症状,分别是自汗、乏力懒言、畏寒、肢冷、眩晕/头晕目眩、盗汗、潮热、周身酸痛/身重。这个固定的问题就是模拟实际临床上其它三诊所得到的信息,从而模拟在四诊合参时,本问诊系统的问诊效果。
首先验证了提问时的提问效率(图9),改变提问方式之后,本系统基于27 个症状和基于80 个症状的提问效率均提升了10%以上。从27 个症状中提问可以达到52%的准确性,与先前的假设基本一致,在输入更多的信息时,由于证候不确定性下降,从而使得提问的准确率有了很大提升。随后,本文验证了在改进提问之后,问诊系统的诊断效果(图10、图11),图中虚线代表改进前,实线代表改进后。图10 是基于27个特征分类器,改进前后的预测效果对比图,图11 是基于80 个症状分类器改进前后预测效果对比结果。从预测的3个指标来看,在不同提问次数下,实现始终高于虚线,即增加信息的问诊系统的表现始终比单一信息的问诊系统表现要好。

图9 不同症状数下改进前后Eff值对比
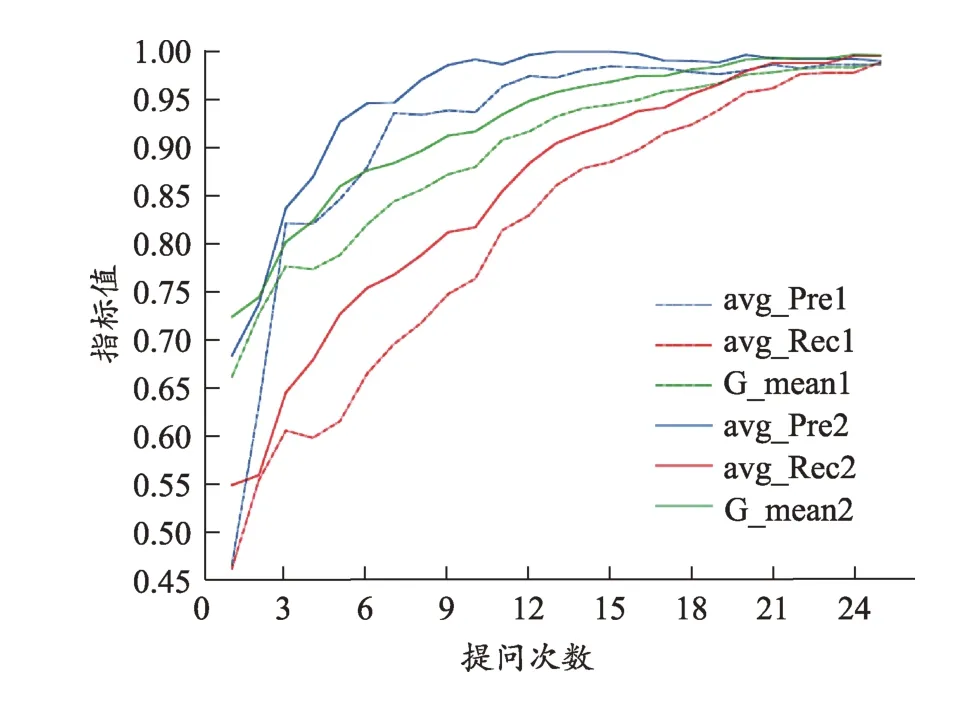
图10 基于27个症状的系统改进前后性能对比图

图11 基于80个症状的系统改进前后性能对比图
最后对比了增加信息量后从27 个症状中提问和从80个症状中提问两种问诊方式的性能表现(图12),前者的表现效果明显好于后者,从27 个症状中提问,并增加信息量之后,只需要提问13个问题就可达到原始分类器90%以上的分类效果。

图12 改进后基于27个症状与基于80个症状提问的系统性能对比图
3 结论
依据问诊量表逐条获取患者症状可以解决中医问诊中“问什么,怎么问”两大核心问题,但过程往往比较繁琐,本文利用基于协同过滤的推荐系统来解决中医问诊客观化、智能化问题,并取得了良好的效果,为中医问诊客观化、智能化提供了一种思路。本文基于ItemCF 推荐算法构建症状提问系统,基于该提问系统对原始结构化问诊数据进行问诊复现式获取症状,将抽取得到的症状输入到用结构化问诊数据训练的证候分类模型中,由证候分类模型给出证候诊断结果。将此诊断结果与原始测试数据在证候分类模型上的预测结果做比较,量化本系统的问诊效果。实验结果表明,系统只需要进行13次提问,就可以获得较好的诊断结果,相比于当前基于量表获取症状可以获得更高的效率,为中医问诊客观化发展提供条新的思路。未来的工作中,将在本问诊系统的基础上,进一步融合四诊数据,提高问诊系统的提问效率和诊断准确性。
