基于Res-Net深度特征的SAR图像目标识别方法
2021-04-09高红艳卫泽刚刘亚军
刘 飞, 高红艳, 卫泽刚, 刘亚军, 钱 郁
(1. 宝鸡文理学院 物理与光电技术学院,陕西 宝鸡 721013;2. 宝鸡文理学院 宝鸡先进钛合金与功能涂层协同创新研发中心,陕西 宝鸡 721013)
1 引 言
通过对合成孔径雷达(Synthetic Aperture Radar,SAR)获得的高分辨率图像进行处理,可实现对聚焦区域或感兴趣目标的分析解译。SAR目标识别技术可用于侦察以及情报解译[1-2]。自20世纪90年代以来,随着模式识别、人工智能技术的发展,SAR目标识别方法不断丰富,取得了长足的进步。主流SAR目标识别方法通常运用特征提取和分类阶段的两级流程实现未知样本的类别确认。SAR图像典型目标特征包括几何形状、投影变换以及电磁散射等类别。以目标轮廓、区域、阴影等为代表性的形状特征,具备区分不同类别的能力[3-6]。投影变换算法包括数学投影和变换域分解等,前者包括矩阵分解、流形学习等[7-9],后者包括小波、单演信号、模态分解等[10-12]。电磁散射特征体现目标的后向散射特性,如峰值、散射中心、极化方式等[13-14]。分类决策阶段与特征提取紧密耦合,利用特征的差异性判定输入样本的所属类别。近邻分类器(最近邻、多近邻等)[15]、支持向量机(Support Vector Machine,SVM)[16]、稀疏表示分类(Sparse Representation based Classification,SRC)[17]是现有SAR目标识别方法运用最为广泛的分类器。随着近年来深度学习技术的迅猛发展,以卷积神经网络(Convolutional Neural Network,CNN)[18-20]为代表的深度学习模型已成为SAR目标识别中的主流算法。
本文在现有研究的基础上提出了结合深度学习模型和传统分类机制的SAR目标识别方法。在特征学习阶段采用深度残差网络(Deep Residual Networks,Res-Net)[21-22]进行目标多层次的特征图学习。相比传统的手工设计特征,基于Res-Net训练得到的特征图具有描述能力更强的优势,可为决策阶段提供更充分的鉴别力信息。考虑到SAR目标识别中广泛存在扩展操作条件(Extended Operating Condition,EOC),即测试样本与训练样本存在较大的差异,待识别样本经过Res-Net获得的多层次特征图中可能存在若干无效成分。剔除这些无效成分有利于提高识别算法的整体效率和精度。为此,本文采用结构相似性准则计算各个特征图与原始样本的相关性[23],并通过门限法提出低相似度的部分。对于判决保留的特征图,基于联合稀疏表示模型[11-12]进行表征分类。在实验中,基于MSTAR数据集设置标准操作条件(Standard Operating Condition,SOC)和扩展操作条件对方法进行测试验证,结果证实了其有效性和稳健性。
2 基于Res-Net的深度特征学习
Res-Net由Kaiming He提出并在多项图像检测、分割等大赛中得到了充分验证[21-22]。随着网络层数的不断增加,其学习得到的特征愈加丰富,更能反映图像中感兴趣目标的多方面特性,但同时也会导致严重的梯度消失问题。为此,Res-Net提出残差学习克服网络优化困难的问题。假设H(x)表示最佳映射,利用堆叠的非线性层获得新的映射F(x)=H(x)-x,进而获得当前最佳映射F(x)=H(x)+x。F(x)+x可在前馈网络增加“快捷连接”操作获得。该操作具有高效稳健的优势,不会带来额外的运算复杂度。
现有研究成果已经验证了Res-Net在图像处理(如目标检测、识别)领域的有效性。为此,本文将其引入SAR目标识别,主要用于多层次深度特征的学习和获取。图1显示了本文应用于SAR图像特征学习的Res-Net结构,共包含20层。相比一般卷积神经网络,Res-Net可实现输入与后续非相邻层的直接连接,从而最大程度减少信息丢失以及损耗等问题。Res-Net简化了网络学习的难度并提高了整体训练效率。基于图1可学习获得SAR图像多层次的特征图。这些深度特征可从不同侧面反映图像中目标的各类特性,可为目标识别提供有效的鉴别力信息。

图1 Res-Net结构示意图Fig.1 Architecture of designed Res-Net
3 深度特征筛选
基于Res-Net学习的SAR图像多层次特征图能够从不同方面反映目标的特性。然而,SAR目标识别中存在多种扩展操作条件,当测试样本与训练集差异较大时,其学习的深度特征可能存在若干无效成分。为此,本文基于结构相似性进行有效深度特征的筛选,并用于后续的分类决策[23]。
记参考图像和输入图像分别为I1和I2,并具有相同尺寸。结构相似性指数(SSIM)从亮度、对比度、结构3个方面评价两幅图像的相关性[23],定义如下:
SSIM(I1,I2)=l(I1,I2)·c(I1,I2)·s(I1,I2),
(1)
式中,l(I1,I2),c(I1,I2),s(I1,I2)分别对应亮度、对比度以及结构比较函数,定义如下:
(2)
(3)
(4)
式中,(μ1,σ1)、(μ2,σ2)分别为I1和I2均值和方差;σ12代表两者之间的协方差;C1、C2和C3均为大于零的常数。
本文基于结构相似性进行Res-Net深度特征的筛选。分别计算各个层次的特征图与输入图像的结构相似性指数。对于相似性较高,认为其能够保持原始图像的特性,予以保留并用于后续的分类;反之,则剔除。本文设置相似性门限T,对于结构相似性大于门限的予以保留。
4 联合多层次特征图的识别算法
4.1 联合稀疏表示
联合稀疏表示模型是传统SRC分类器的拓展延伸,具备同时处理多个稀疏表示问题的能力。假设经过结构相似性准则筛选得到K个深度特征矢量,记为[y(1)y(2)…y(K)],采用稀疏表示对它们进行表征的基础模型如下:
y(k)=A(k)α(k)+ε(k)(k=1,2,…,K),
(5)
式中,A(k)为对应k深度特征的全局字典,通过对所有训练样本的处理获得;α(k)为系数矢量。
联合稀疏表示框架下,采用式(6)对K个稀疏表示问题进行统一考察:
(6)
式中,β=[α(1)α(2)…α(K)]。
不足的是,式(6)的优化过程并没有体现同一SAR图像不同层次深度特征之间的关联,影响系数矢量的求解精度,经典的联合稀疏表示模型调整优化目标函数如下:
(7)
在l1/l2范数的约束下,式(7)中的矩阵β各列中的系数矢量倾向相同的分布规律,体现不同深度特征的内在关联。针对上述问题,较为成熟的求解算法包括多任务贝叶斯压缩感知、同时正交匹配追踪等。根据求解结果,按照式(10)计算不同训练类别对测试样本(相应的深度特征矢量)的重构误差并判定其类别。
(8)
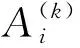
4.2 识别流程
根据前文论述,构设如图2所示的方法流程,描述本文方法的主要步骤。首先,采用所有训练样本对图1所示的Res-Net进行训练,获得可用于特征学习的模型。对于测试样本,将其输入训练后的Res-Net获得多层次深度特征,进而根据结构相似性准则选取若干高鉴别力深度特征(结构相似性门限T设置为0.6)。此时,对训练样本的深度特征进行对应成分选取并分别构建全局字典。最终,在联合稀疏表示模型的处理下,获得各个训练样本对于测试样本的重构误差,进而获得目标类别。

图2 基于结构相似性的深度特征筛选及SAR目标识别流程图Fig.2 Flowchart of SAR target recognition based on selected deep features by structural similarity
5 实验与分析
实验中以MSTAR公开数据集为基础,构设典型测试场景对所提方法进行测试。该数据集包含外形尺寸相近的10类目标(图3)不同条件下获取的数千幅SAR图像。据此,可设置训练和测试样本开展训练和分类。表1给出了基于MSTAR数据集设置的一种代表性测试场景,常视为标准操作条件。其中囊括了全部10类目标,训练样本俯仰角为17°,训练样本俯仰角为15°。除此之外,还可设置扩展操作条件对方法的稳健性进行考察,包括后续实验中的俯仰角差异(测试场景2)和噪声干扰(测试场景3)。
实验过程中,选用当前文献中较为常见的几类方法进行比较,包括SVM[16]、SRC[17]、A-ConvNet[18]以及Res-Net(直接用于分类,不经过特征选取和联合表征)。这几类方法主要是采用了不同的分类机制,其中A-ConvNet和Res-Net采用CNN作为基础分类器,但在网络结构上有所区别。与Res-Net方法比较,本文主要是在特征学习之后进行了筛选,并利用联合稀疏表示进行最终分类。为定量对比不同方法的性能,本文定义平均识别率如下:
(9)
式中,Nc和Nt分别表示正确分类以及全部测试样本数目。


图3 MSTAR目标示意图Fig.3 Illustration of MSTAR targets

表1 场景1~10类目标标准操作条件Tab.1 Scenario 1 ~ 10 targets under SOC
5.1 标准操作条件
基于表1中的测试和训练样本对所提方法在标准操作条件下进行测试。图4显示了所提方法对10类目标的混淆矩阵,其中纵坐标为样本的实际类别,其与横坐标对应类别的元素对应分类精度。因此,图4中的对角线元素反映了不同类别的正确识别率,按照式(9)计算得到10类目标的平均识别率为99.02%,表明了方法的有效性。表2为所有方法在当前场景下的结果统计。4类对比方法的平均识别率依次为98.16%(SVM)、98.32%(SRC)、98.78%(A-ConvNet)和98.80%(Res-Net),均低于所提方法。特别地,与两类基于CNN的方法相比,本文通过有效选取Res-Net多层次深度特征并利用联合稀疏表示进行分类,进一步提升了最终性能。表2同时对比了各类方法的时间消耗。SVM和SRC由于分类器相对简单,其效率处于优势水平。与直接运用Res-Net的方法相比,本文由于进一步引入了深度特征构造和联合稀疏表示,增加了时间消耗。
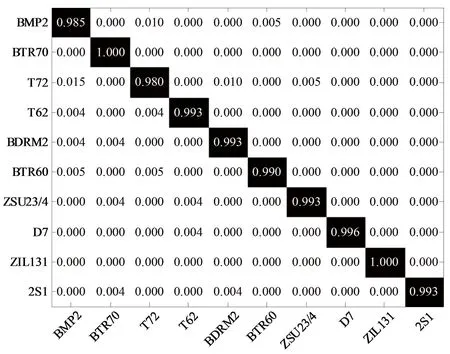
图4 场景1下所提方法对各类别识别结果Fig.4 Recognition results of each class by the proposed method under scenario 1

表2 场景1下结果统计Tab.2 Results under scenario 1
5.2 俯仰角差异
在测试场景1时,设置的测试与训练集俯仰角十分接近。实际过程中,SAR传感器可能工作在不同的高度,这导致待识别样本可能来自于训练样本差异较大的俯仰角。基于MSTAR数据集的SAR图像样本,本实验设置如表3所示的测试场景,包含3类目标。其中,训练样本均为17°俯仰角下的SAR图像;测试样本区分30°和45°两个子集。图5统计了各类方法对两个子集样本的平均识别率。对比而言,在45°俯仰角时,因测试样本与训练样本差异过大,导致各性能显著降低。分别比较两个角度下的结果,可验证所提方法的识别最高,稳健性最强。本文采用结构相似性选择有效选取了对于适宜当前测试条件的深度特征,通过联合稀疏表示得到的识别结果更为可靠,对于俯仰角差异的稳健性更强。
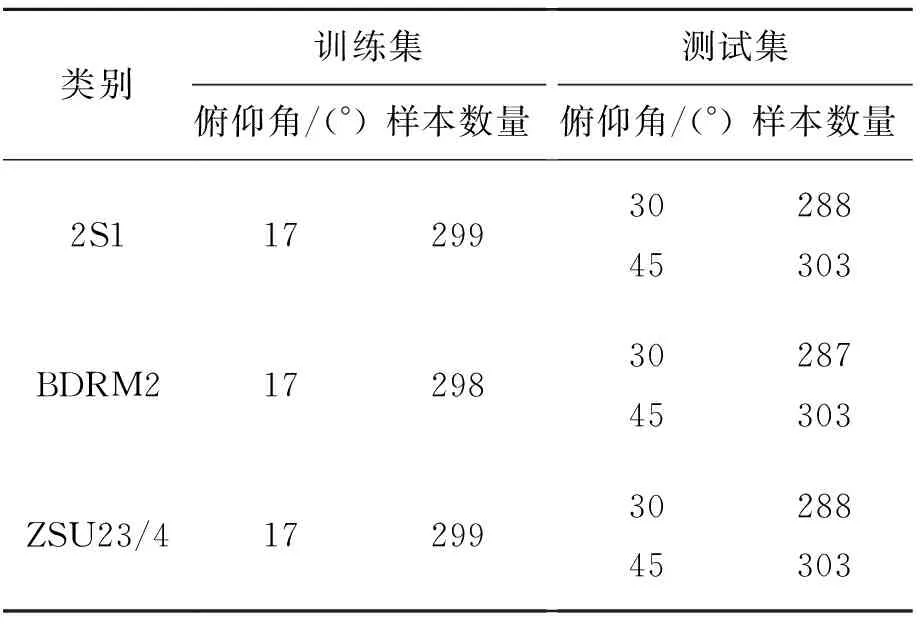
表3 场景2—俯仰角差异Tab.3 Scenario 2 — depression angle variance

图5 场景2下的结果统计Fig.5 Results under scenario 2
5.3 噪声干扰
雷达成像过程中,可能受到自然或人为的干扰,导致最终获得的图像信噪比(Signal-to-Noise Ratio,SNR)降低。此时,正确识别目标类别的难度大大加剧。MSTAR数据集中原始SAR图像均来自合作测试条件,信噪比相对较高,且保持在相近水平。为测试所提方法对于噪声干扰的有效性,本实验对表1中的测试样本按照文献[13]的策略条件不同程度的噪声,进而测试方法在不同信噪比下的平均识别率,并将此条件记为“测试场景3”。如图6所示,所提方法在-10,-5,0,5,10共5个噪声水平下均保持最高的识别率,显示其噪声稳健性。与SVM、A-ConvNet和Res-Net方法相比,SRC方法在低于0 dB的噪声水平时性能更优,表明稀疏表示机制对于噪声为适应性。本文通过有效的特征筛选并结合联合稀疏表示对于噪声干扰的适应性进一步提升了方法的整体性能。
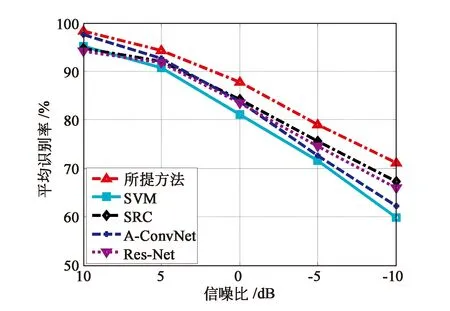
图6 场景3下的结果统计Fig.6 Results under scenario 3
6 结 论
本文基于Res-Net和联合稀疏表示设计SAR图像目标识别方法。对于测试样本,采用Res-Net选取其多层次深度特征,并基于结构相似性准则选取其中的高鉴别力成分。通过联合稀疏表示进行表征及分类。实验在MSTAR数据集上设置并开展,综合分析识别效率、识别精度和识别稳健性,结果证明了所提方法的有效性。后续研究中,本文将从Res-Net的结构优化以及深度特征的选取策略方面进一步深化成果。
